Flink关系型API
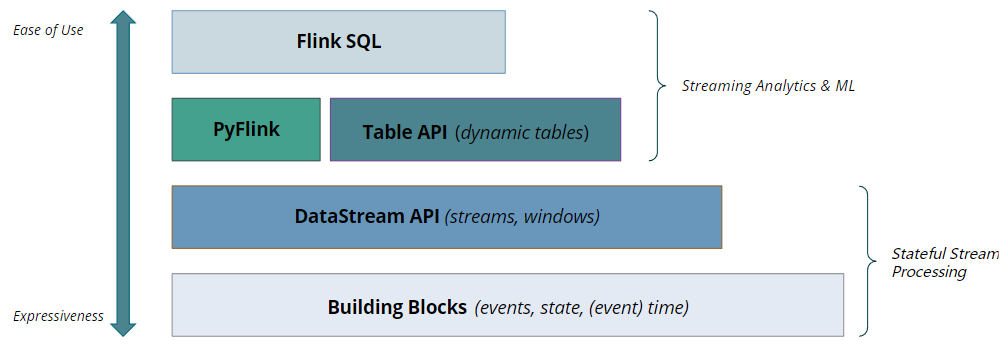
Flink各种层次的API,在成本和易用性之间权衡。应用可以自行搭配API。
一句话介绍Flink SQL
符合标准 SQL的 服务,可查询静态和流数据,它利用了Apache Flink的性能、可扩展性和一致性
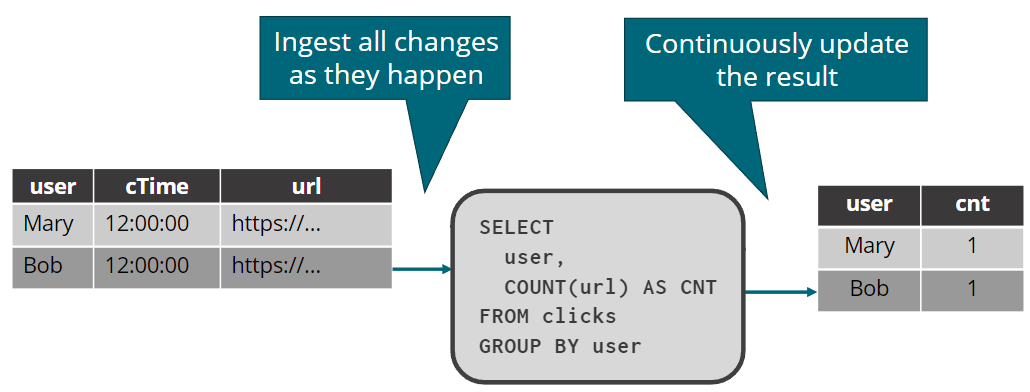
对静态表快照的一次性查询
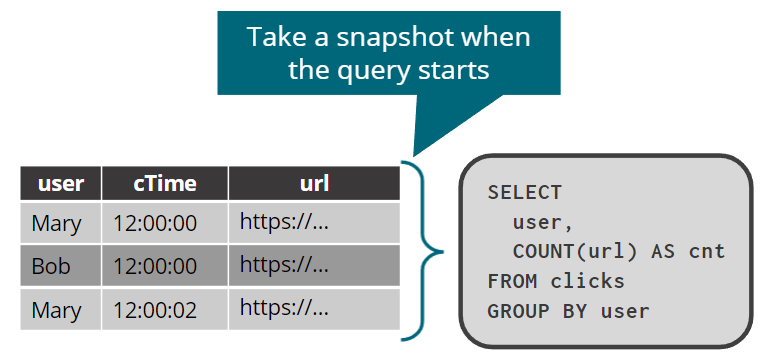
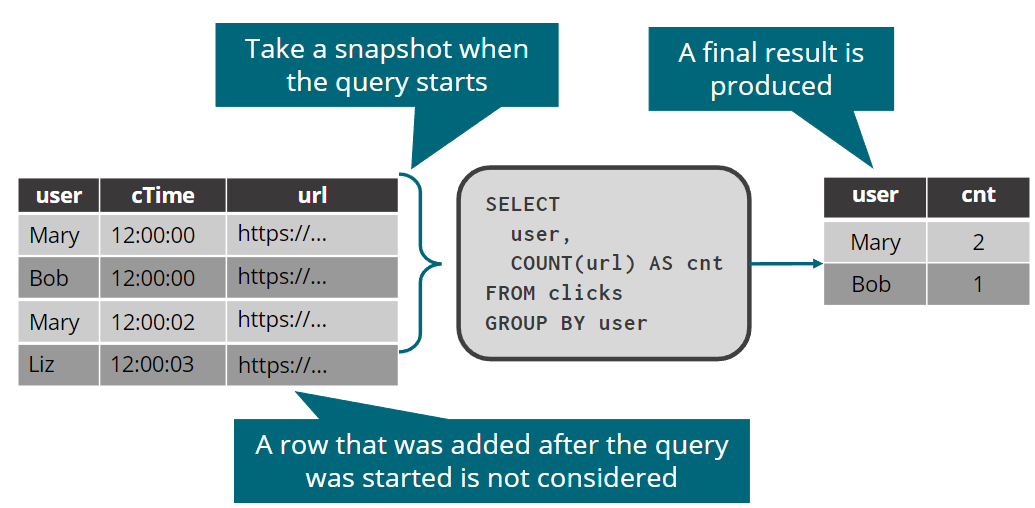
注意发起查询后,新加的数据不在统计范围内。
SQL 的语义
- 标准 SQL 语义
- Table随时间变化
- 针对表的静态快照运行查询
- 查询输入是有限的,结果也是有限的和确定的
对动态表的连续查询
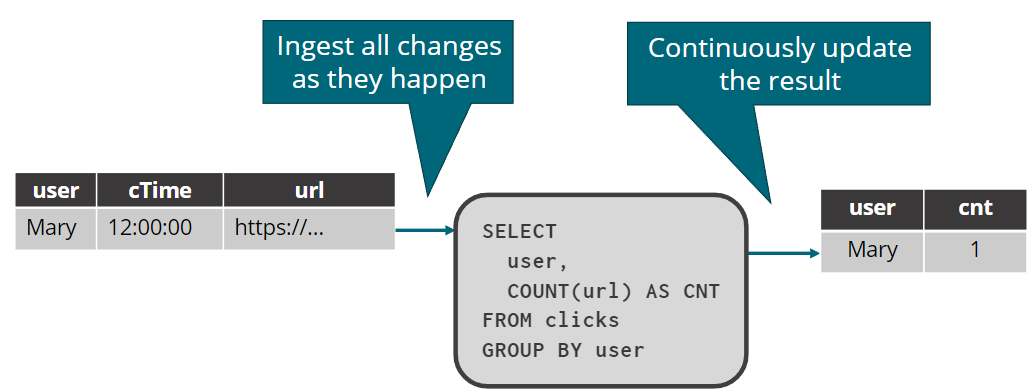
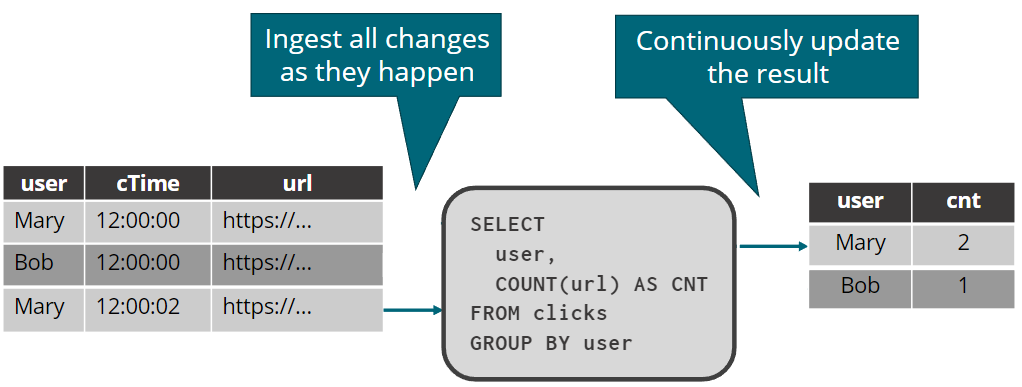
streaming SQL的语义
Streaming SQL
可用性
- ANSI SQL语法:没有自定义的”StreamSQL”语法
- ANSI SQL语义:没有stream-specific的结果语义
- 可移植性
- 对有界或无界数据运行相同的查询
- 对被记录下来的或实时数据运行相同的查询
- 从历史数据引导查询状态或回填结果

查询是并行执行的
INSERT INTO sinkSELECT user, COUNT(URL) as cntFROM clicksGROUP BY user
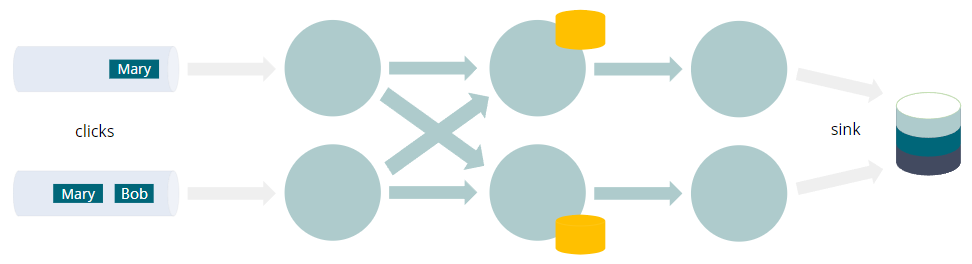
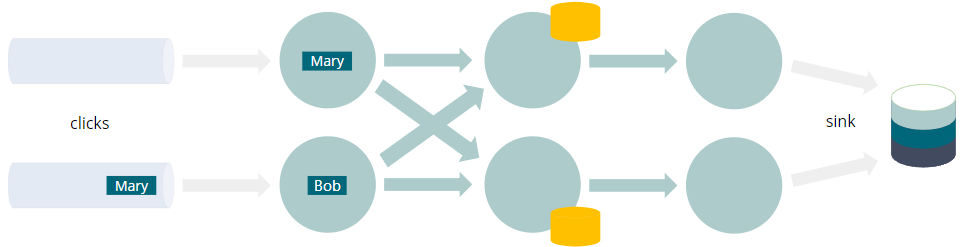
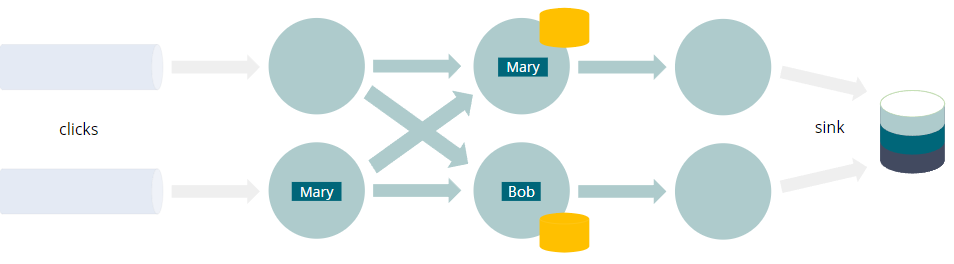

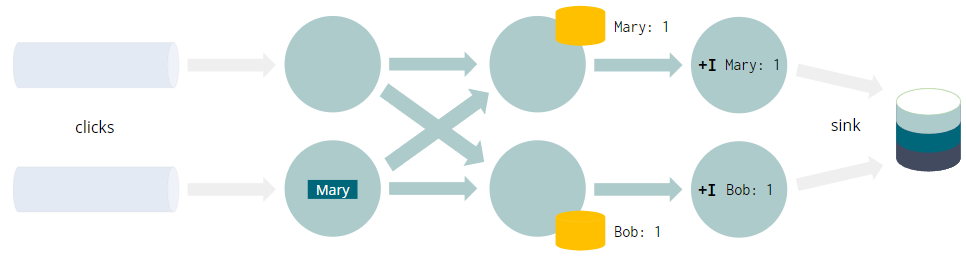
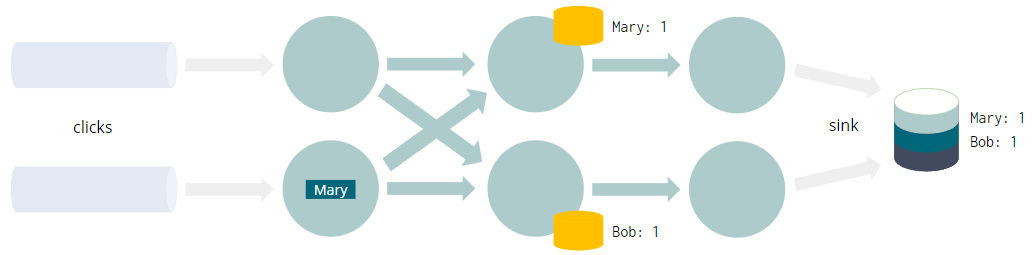
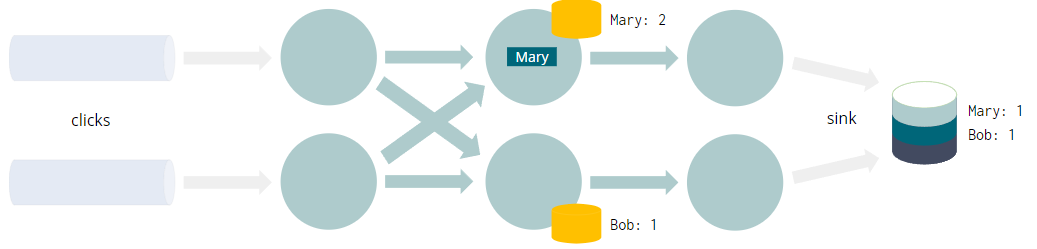
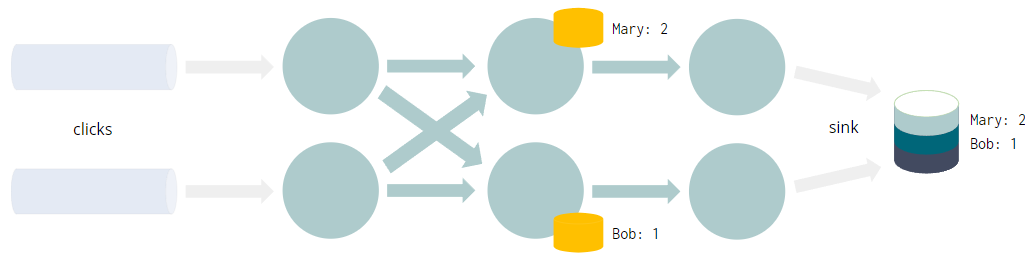
- 每个查询都编译成一个 Flink 作业
- 数据流经有向无环图,叫做Job Graph
- GROUP BY触发网络shuffle
- 将具有相同分组key(例如user)的每个事件带到同一个实例
- 聚合需要(容错)状态
- 这不是整个“动态表”的物化视图
- 而只是计算结果所需的最小值
动态表描述了一个逻辑概念。我们实际上并没有将整个表存储在状态中,而是仅存储计算所需结果所必需的。稍后我们将看到如何利用时间约束来避免保持不再影响结果的状态。
例如,当按照一小时的基于时间的窗口聚合时,一旦我们完成了从 10 点到 11 点之间的数据处理并发出了它的结果,我们就不再需要保留有关该小时的任何信息。我们已经(或相信我们已经)处理了所有可能影响这些结果的事件,并且这些结果是最终的。
关于时间
- 在许多连续查询中,适当的时间处理非常重要
- 对时间相关的行进行Group或join
- 语义与在快照上运行查询相同
- Flink SQL 支持带有水印的复杂事件时间处理
- 及时跟踪进度可有效执行连续查询
- 确定计算输入何时完成
- 确定何时不再需要行数据并清理状态
- 定期触发计算并更新结果
- 这些对流的优化不会影响查询语义
Flink 1.14 中的 SQL 功能集
流& 批
- SELECT FROM WHERE
- GROUP BY [HAVING]
- 非窗口的
- 滚动、跳跃、session窗口
- JOIN
- 基于时间窗口的 INNER + OUTER JOIN
- 非窗口的INNER + OUTER JOIN
- Set Operations
用户自定义函数
Window Table-Valued Functions
- 滚动、跳跃、session窗口
- OVER / WINDOW
- 无界+有界前置
- INNER JOIN
- 临时表
- 外部查找表
MATCH_RECOGNIZE
标量:返回单个值
- 聚合函数:多行输入到单个输出
- 表函数:返回一张表,包含一行或多行,而不是单个值
- 表聚合函数:从多行聚合输入,返回一张表
- 异步表函数执行外部查找
- 矢量化函数从(python)pandas.Series 对象中获取输入
参考文献
- Examples
- Flink Forward Videos
- Ververica Blog
- Documentation
物化视图是将查询结果预先计算并存储的一张特殊的表。”物化”(Materialized) 这个词是相对于普通视图而言。普通视图较普通的表提供了易用性和灵活性,但无法加快数据访问的速度。物化视图像是视图的缓存,它不是在运行时构建和计算数据集,而是在创建的时候预先计算、存储和优化数据访问,并自动刷新来保证数据的实时性。

若有收获,就点个赞吧
0 人点赞
