Data types
序列化在分布式系统中至关重要;这是不同机器上的进程能够相互共享数据的基础。
- DataSet 和 DataStream API 共享相同的类型系统
- Flink 有自己的序列化器,主要用于
- 基础类型
- String, Long, Integer, Boolean, …
- Arrays
- 复合类型
- Tuples
- POJOs
- Scala Case Classes
- 基础类型
- 其他情况下,否则 Flink 回退到 Kryo 进行 ser/de.
- 也可以采用其他Flink的序列化器,如Avro。
Tuples
Scala: 采用默认的Scala tuples (1 to 22 fields)
Java: Flink实现了Tuple1到Tuple25 ```java Tuple2
// zero based index! String name = person.f0; Integer age = person.f1;
<a name="S3SCR"></a>## POJOs任意一个Java类,满足:- 有一个空的构造函数- 可被公开访问的属性(public 属性或者默认的getter/setter)```javapublic class Person {public String name;public Integer age;public Person() {};public Person(String name, Integer age) {…};}DataStream<Person> p = env.fromElements(new Person("Bob", 65));
从 Flink 1.8 开始,Flink 将负责schema演变和state迁移,以便对使用 Flink 内置序列化器序列化的 POJO 进行直接更改。
Case classes (Scala)
Scala case classes是原生支持的
case class Person(name: String, age: Int)d: DataStream[Person] =env.fromElements(Person("Bob", 65))`
目前(尚)不支持 Scala case class的状态演化。见 FLINK-10896, 目前技术可行性还待验证。
DataStream API: 基础算子
Stream Processing
在无界流上持续运行的计算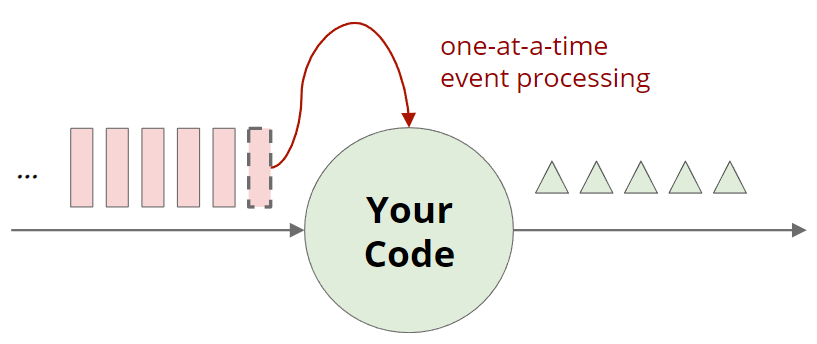
在Flink流式计算简介一节中,提到 Flink 提供了一次一个事件的流处理。
现在具体看看:在“your code”的地方可以做什么?
总结来说,就是filtering和transforming。
Transformations: Filter
public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();DataStream<Integer> integers = env.fromElements(1, 2, 3, 4, 5);DataStream<Integer> odds = integers.filter(new FilterFunction<Integer>() {@Overridepublic boolean filter(Integer value) {return ((value % 2) == 1);}});odds.print();env.execute();}> 1, 3, 5
以上是一个完整的Flink应用的实际例子,除了filter以外,还可以关注下
StreamingExecutionEnvironment envprint()execute()
Transformations: Map
DataStream<Integer> integers = env.fromElements(1, 2, 3, 4, 5);DataStream<Integer> doubleOdds = integers.filter(new FilterFunction<Integer>() {@Overridepublic boolean filter(Integer value) {return ((value % 2) == 1);}}).map(new MapFunction<Integer, Integer>() {@Overridepublic Integer map(Integer value) {return value * 2;}});doubleOdds.print();> 2, 6, 10
注意FilterFunction和MapFunction的接口声明,参数不同。虽然都是对单元素处理,MapFunction中第1个接受输入、第2个接受输出。
Transformations: FlatMap
DataStream<Integer> integers = env.fromElements(1, 2, 3, 4, 5);DataStream<Integer> doubleOdds = integers.flatMap(new FlatMapFunction<Integer, Integer>() {@Overridepublic void flatMap(Integer value, Collector<Integer> out) {if ((value % 2) == 1) {out.collect(value * 2);}}});doubleOdds.print();
注意,这里FlatMapFunction interface也是接收2个参数,一个是输入类型,一个是输出类型。里面flatMap函数返回类型为void,同时值得注意的是函数的第2个参数是Collector类型。
flatMap 在函数必须处理无法解析的输入或其他错误情况时很有用。或者当单个输入记录可能产生多个输出记录时,例如,如果它需要解包打平一个数组。
Distributed stream processing: keyBy
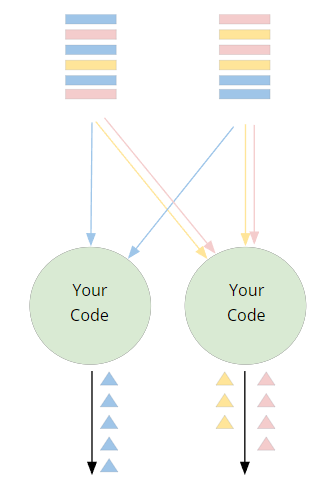
- 跨多个实例分布计算
- 键是根据每个流元素计算的
- 对数据进行分区——具有相同键的所有元素将由相同的算子实例处理
- 特定算子是key-aware感知的,例如 reduce 和 window
- Flink 管理每个key的state和timers。
某个具体key相关的所有数据在同一个worker实例被处理。keys并不被附加到流记录里,而是在 KeySelector 需要时重新计算。 所以 KeySelector 函数需要快速执行且具有确定性。
实现一个KeySelector
Java7的风格
keyedSensorReadings = sensorReadings.keyBy(new KeySelector<Sensor, String>() {@Overridepublic String getKey(Sensor reading) throws Exception {return reading.id;}})
Java8的风格
keyedSensorReadings = sensorReadings.keyBy(r -> r.id)
基于数字字段位置(元组内)和字段名称(用于 POJO 和案例类)的key selectors在 Flink 1.11 中已弃用。详见https://nightlies.apache.org/flink/flink-docs-release-1.11/api/java/org/apache/flink/streaming/api/datastream/DataStream.html#keyBy-int…-
有效的key类型
- key由KeySelector方法从每一个stream消息中计算而来。
- KeySelector必须是确定性的
- 它计算的key必须具有 hashCode() 和 equals() 的有效实现
- 数组和枚举类型不能作为key。因为它们的 hashCode() 实现在 JVM 之间不是确定性的
复合类型也可以作为key
使用 env.fromElements(…) 或 env.fromCollection(…) 快速创建 DataStream 以进行试验
- 使用 print() 打印数据流
- Lazy execution会使调试变得棘手,但可以在 IDE 中使用断点

若有收获,就点个赞吧
0 人点赞
