时间在流处理中无处不在
带时间戳的数据集
我们所做的查询通常有一个时态组件。这些例子是用时间来
- 平滑和聚合数据
- 从其他来源查找相关的丰富数据
- 用于监控、模式匹配和警报的表达条件
时间属性和时态算子
Flink SQL中的时间
事件时间属性
CREATE TABLE clicks (user STRING,url STRING,cTime TIMESTAMP_LTZ(3),WATERMARK FOR cTime AS cTime – INTERVAL ‘2’ MINUTE)
事件时间属性是带有关联watermark的 TIMESTAMP 或 TIMESTAMP_LTZ。
watermark使用有界无序watermark策略。
处理时间属性
CREATE TABLE clicks (user STRING,url STRING,cTime AS PROCTIME())
处理时间属性是计算列,不保存数据。
每当访问属性时都会查询本地机器时间
处理时间属性可以像常规 TIMESTAMP_LTZ 一样使用。
- Flink SQL 同时支持事件时间和处理时间
- 通过使用表模式声明的时间属性
- 时间属性类似于常规时间戳,但附加了特殊的元数据
- 事件时间属性可以是 TIMESTAMP 或 TIMESTAMP_LTZ
- 处理时间属性始终是 TIMESTAMP_LTZ
- Flink 1.13 增加了 TIMESTAMP_LTZ 类型;以前所有时间属性都是 TIMESTAMP
时间戳 vs 时间属性
- 时间戳
- 时间戳列中的值固定到特定时刻
- 不能保证该列是(甚至粗略地)按时间排序的
- 时间属性
- 一个时间属性列连接到时间的前向进展
- 处理时间属性通过 PROCTIME() 连接到系统时钟
- 事件时间属性连接到watermark
- 一个时间属性列连接到时间的前向进展
时间往前,状态可以过期
1小时窗口每个用户点击数
- 事件时间窗口
- 点击次数计入它们发生的小时内
- water触发关闭窗口并丢弃它们的状态
- 处理时间窗口
- 按处理时间所在的那个小时窗口来统计
- 本地系统时钟触发关闭窗口并丢弃它们的状态
如果输入表中没有时间属性,则窗口运算符
时态运算符使用时间属性将记录相互关联
- 窗口
- 按窗口分组
- OVER windows过窗
- 窗口表值函数(自 Flink 1.13 起)
- 关联
- 间隔关联
- 加入时态表(版本化连接)
- 模式匹配(带有 MATCH_RECOGNIZE 的 CEP)
- 窗口
- 时态算子及时跟踪进度以确定输入何时完成
- 输出结果,不再更新
- 他们能够丢弃不再需要的状态(记录和结果)
窗口算子是时态算子之一。
所有时态算子都依赖于时间属性,这些属性必须在特定子句中使用(取决于查询类型)。否则,查询的执行计划将不会使用时态算子,并且不会优化其执行以减少状态保留。
关联后面单独讲。
模式匹配要求能够对输入流进行时间排序,以便匹配“A后跟B”等模式。
时间属性的有效性
- 所有时态算子都需要具有时间属性的输入
- 如果处理完后生成了一个没有时间属性列的结果表,那么对这些结果不能再使用时态算子。
- 一些带有时间属性输入的算子产生带有时间属性的结果
- 但是其他算子会产生带有时间戳的结果,这些时间戳已经失去了时间属性
- 处理时间属性在他们被访问时物化
- 当不能再保证watermark有意义时,事件时间属性失去其时间属性属性
- 有问题的算子示例
窗口聚合类型
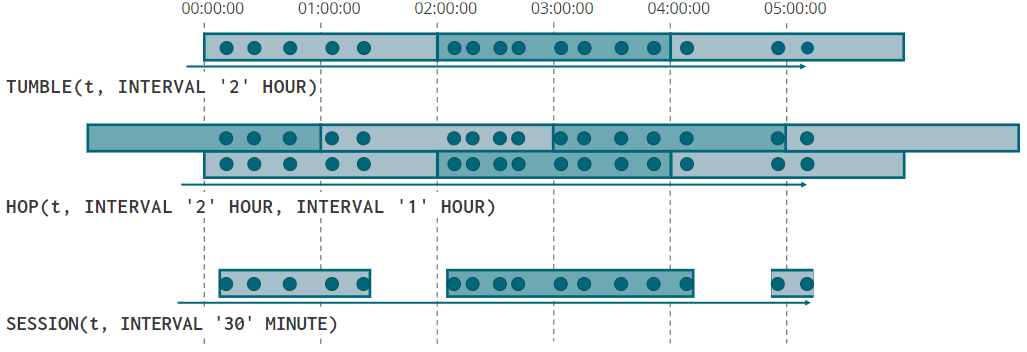
选择窗口边界
- 这些函数返回TIMESTAMPs ```plsql TUMBLE_START(time_attr, interval) HOP_START(time_attr, interval, interval) SESSION_START(time_attr, interval)
TUMBLE_END(time_attr, interval) HOP_END(time_attr, interval, interval) SESSION_END(time_attr, interval)
这些时间戳在报告结果时中很有用,但不能用作其他时态算子的输入,因为它们不是时间属性。- 这些函数返回 time attributes```plsqlTUMBLE_ROWTIME(time_attr, interval)HOP_ROWTIME(time_attr, interval, interval)SESSION_ROWTIME(time_attr, interval)TUMBLE_PROCTIME(time_attr, interval)HOP_PROCTIME(time_attr, interval, interval)SESSION_PROCTIME(time_attr, interval)
这些时间属性可以在需要时间属性的任何地方使用,例如, GROUP BY 窗口、OVER 窗口、窗口表值函数 间隔连接,时间连接。
窗口表值函数(TVFs)
概念例子
SELECT * FROM TABLE(TUMBLE(TABLE clicks, DESCRIPTOR(cTime), INTERVAL '1' HOUR));
| user | cTime | url | window_start | window_end | window_time |
|---|---|---|---|---|---|
| Mary | 12:00:00 | ./home | 12:00:00.000 | 13:00:00.000 | 12:59:59.999 |
| Bob | 12:00:00 | ./cart | 12:00:00.000 | 13:00:00.000 | 12:59:59.999 |
| Mary | 12:02:00 | ./prod?id=2 | 12:00:00.000 | 13:00:00.000 | 12:59:59.999 |
| Mary | 12:55:00 | ./home | 12:00:00.000 | 13:00:00.000 | 12:59:59.999 |
| Bob | 13:01:00 | ./prod?id=4 | 13:00:00.000 | 14:00:00.000 | 13:59:59.999 |
| … | … | … | … | … | … |
注意:Flink 实际上并不支持像这样评估窗口表值函数;它们只能与聚合操作一起使用。
对窗口,在tvf上应用聚合
SELECTuser, window_start, window_end, count(url) AS cntFROM TABLE(TUMBLE(TABLE clicks, DESCRIPTOR(cTime), INTERVAL '1' HOUR))GROUP BYuser, window_start, window_end;
| user | window_start | window_end | cnt |
|---|---|---|---|
| Mary | 12:00:00.000 | 13:00:00.000 | 3 |
| Bob | 12:00:00.000 | 13:00:00.000 | 1 |
| … | … | … | … |
支持tvf的窗口类型
- TUMBLE(TABLE data, DESCRIPTOR(timecol), size)
- HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
- CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
- Session windows暂不支持(FLINK-24024)
累积窗口聚合直到达到指定大小,但每一步都显示它们的进度。例如,24 小时长的窗口,每小时显示一天的结果。
使用窗口 TVF 的优势
相对于 GROUP BY windows
- 窗口 TVF 更好的被优化了,他们使用
- mini-batch聚合
- 两阶段(本地-全局)聚合
- 窗口tvf支持grouping by GROUPING SETS, ROLLUP, and CUBE
- 可以对结果使用Window Top-N
- 每个小时里点击数最多的3个用户
- docs
小批量聚合减少了状态更新,这对 RocksDB 尤其有用。
两阶段聚合首先在链接到源的算子链中进行本地聚合,然后再进行基于key的shuffle。与 MapReduce 中的 Combine + Reduce 类似。这种优化依赖于小批量,因为在将结果发送到下游进行全局keyed聚合器之前,本地已经聚合小批量。
总结
- 大多数流应用程序在问题陈述和输入数据中的事件时间中都有时间约束
- 时间属性对于使 SQL 在流式上下文中可行性至关重要
- 时间属性在表模式中定义
- 同时支持事件时间和处理时间属性
- 时态算子依赖时间属性来关联相关的输入行
- 他们的结果是最终的,即,输出的结果行永远不会更新
- 他们的状态是自动管理的
- 带有窗口 TVF 的窗口聚合比 GROUP BY 窗口更强大(已弃用)
#

若有收获,就点个赞吧
0 人点赞
