作业图和函数序列化
作业图及其函数必须是可序列化的。
Exception in thread "main" **org.apache.flink.api.common.InvalidProgramException: Task not serializable at**org.apache.flink.api.scala.ClosureCleaner$.ensureSerializable(ClosureCleaner.scala:172)Caused by: java.io.NotSerializableException: org.apache.flink.streaming.api.scala.DataStream
Caused by: org.apache.flink.api.common.InvalidProgramException:The implementation of the ProcessFunction is not serializable.The object probably contains or references non serializable fields.
实现分布式功能的最佳实践:
- 使它们独立于外部变量/对象
- 可以将配置信息传递给构造函数
- 使用在open方法中初始化的暂态变量(而不是在构造函数中)
因为作业将在分布式集群中执行,所以作业图及其调用的函数必须是可序列化的。如果失败,您将看到类似如上所显示的错误。
这里的最佳实践是实现函数,使它们不包含对外部变量或对象的引用。
如果函数确实包含对自身外部对象的引用,Flink将不得不尝试序列化所有相关的传递闭包。这通常会引入一些无法序列化的内容。
举个例子
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.fromSource(...)....sinkTo(new MyCustomSink()); // this sink has to be serializedenv.execute();}
// don't do thispublic class MyCustomSink<T> extends RichSinkFunction<T> {private final Connection connection;MyCustomSink() {this.connection = ...}}
// do this insteadpublic class MyCustomSink<T> extends RichSinkFunction<T> {private transient Connection connection;@Overridepublic void open() {this.connection = ...}}
当主方法被执行时,MyCustomSink的一个实例被创建。这个实例将被序列化。通过左侧显示的接收器的实现,序列化的接收器对象将必须包括Connection对象。但是,它可能包含对某些不可序列化的对象的引用,例如HttpRequestExecutor。右边显示的实现通过让接收器的每个并行实例独立创建自己的Connection对象来避免这个问题。
数据序列化

数据序列化可能发生在三个不同的地方。这些位置中的每一个都可以独立调整。
- 输入序列化
- 与外部系统(例如Kafka)的读写交互消息序列化/反序列化
- 用户定义的格式(来源和水槽中)
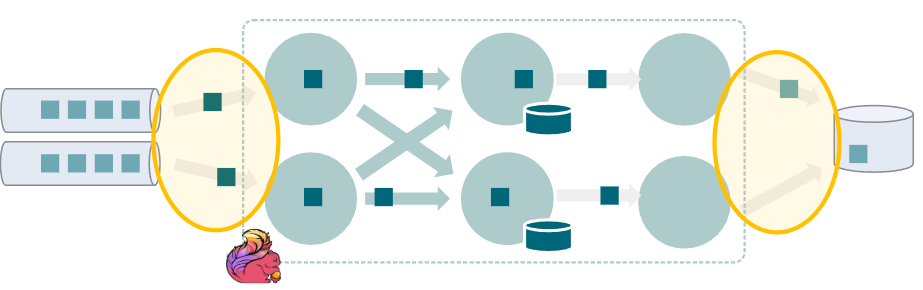
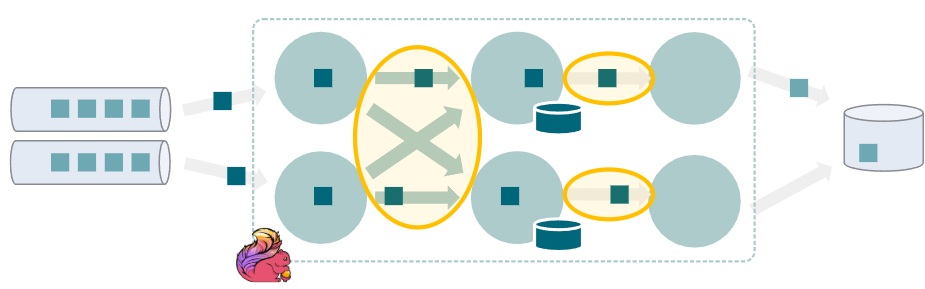
- 数据处理链路序列化
- flink任务之间交换的记录的序列化
- 在一个链的操作符之间使用TypeSerializer#copy()
- 状态序列化
- 状态对象的序列化/反序列化
- RocksDB:每个状态都接触
- 基于堆栈的状态后端:on checkpoint
- 与带状态描述符的有数据处理链路列化器一样
- new ValueStateDescriptor<>(“myState”, MyState.class)
- 状态对象的序列化/反序列化
在处理Flink管理(键控/非键控)状态时,无论是在访问还是在检查点上。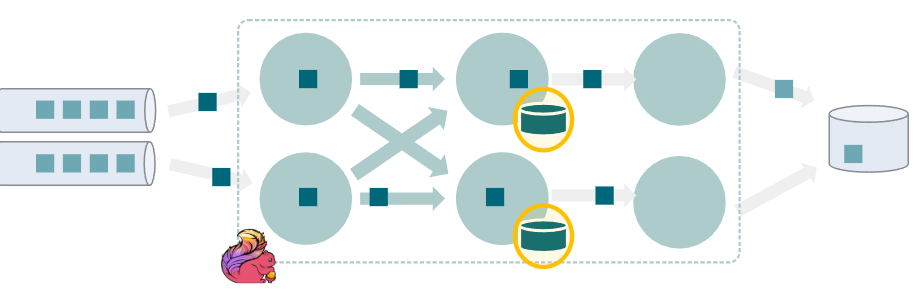
数据处理链路和状态序列化
Flink的目标是能够自动处理任何类型的数据。
输入/出序列化是由用户手动定义的(在创建源和接收时),链路和状态序列化是由Flink控制的。通常情况下,数据类型由Flink自动处理,大多数用例应该可以开箱即用。但是,对于故障排除或性能调优,我们将在本会话的其余部分研究Flink的类型系统的细节。
Flink的类型系统
- Flink有其自己的序列化器,用于
- 基本类型
- 字符串,长,整型,布尔型
- 数组
- 复合类型
- 元组
- pojo
- Scala Case类
- 基本类型
- 如果使用flink-avro,AVRO类Flink原生支持序列化/反序列化
- 否则Flink落回Kryo ser / de
- 也可以使用Apache Thrift和谷歌Protobuf类型
Avro: 对 org.apache.flink: flink-Avro 的依赖项应该添加到作业的 pom.xml 文件中。
您也可以使用 Row 或 BinaryRowData,但是这些更常用于 Table 和 SQLAPI。
Flink 如何确定要使用的序列化程序
隐式地ーー从用户函数的输入/输出中的类型
env.fromElements(1, 2, 3, 4) // out: Integer.map(x -> 2L * x) // in: Integer, out: Long.print(); // in: Long
显式-在实现ResultTypeQueryable时通过getProducedType()
public class MyRichMapFunction extends RichMapFunction<Integer, Long> implements ResultTypeQueryable<Long> {@Override public Long map(Integer x) { return 2L * x; }@Override public TypeInformation<Long> getProducedType() { return Types.LONG; }}
显式-通过SingleOutputStreamOperator#Returns()
env.fromElements(1, 2, 3, 4).returns(Types.Integer).map(x -> 2L * x).returns(Types.LONG).print();
Flink会尽最大努力识别用户作业给出的任何类型。
但有时,由于Java类型擦除(后面会讲),无法为其内部序列化程序提取适当的TypeInformation。在这种情况下,您可以通过以下方式手动提供类型:
- 正在实现ResultTypeQueryable,或…
- 调用SingleOutputStreamOperator#Returns()
- 请注意,这提供了一些方便的重载,可以将它们的参数包装到TypeInformation实例中。
Flink状态序列化
序列化信息通过状态描述符显式提供。
ValueStateDescriptor<Integer> stateDescriptor =new ValueStateDescriptor<>("value", Types.INT); // TypeInformation<Integer>myState = getRuntimeContext().getState(stateDescriptor);
通常有三个重载使用:
指定序列化器
public ValueStateDescriptor(String name, TypeSerializer<T> typeSerializer) { /* ... */ }
TypeInformation 实例
public ValueStateDescriptor(String name, TypeInformation<T> typeInfo) { /* ... */ }
Flink对给定类实例的类型推断
public ValueStateDescriptor(String name, Class<T> typeClass) { /* ... */ }
类型推断的限制
尝试这个写法 ```java env.fromElements(1, 2, 3, 4) .map(x -> new MyEvent<>(2L * x)) .print();
env.execute();
```javapublic class MyEvent<T> {public T value;public MyEvent() { }public MyEvent(T x) { this.value = x; }}
失败的原因是:
Exception in thread "main" ...InvalidTypesException:The return type of function '...' could not be determined automatically, due to type erasure...
上面示了一个例子,其中用户需要手动提供类型信息,以便使作业运行。
原因是 Java 只在编译时检查类型约束,在运行时从元素中丢弃特定的类型信息: 在这种情况下,在运行时,只能看到 MyEvent < object > ,我们需要通过手动告诉 Flink 细节,通过:
- ResultTypeQueryable#getProducedType() or
SingleOutputStreamOperator#returns()
手动提供 TypeInformation
来自classes类的 flink 类型推断
ValueStateDescriptor<Long> stateDescriptor = new ValueStateDescriptor<>("value", TypeInformation.of(Long.class))
用于捕获泛型类型的 TypeHint
stream.map(x -> new MyEvent<>(2L * x)).returns(TypeInformation.of(new TypeHint<MyEvent<Long>>(){}))
Types 类中带有内置序列化程序的常见类型
Types.LONG Types.LIST Types.LOCAL_DATE_TIME // ...
还提供了对复合类型的更多控制,例如:
env.fromElements(Row.of(1, "first"), Row.of(2, "second")).returns(Types.ROW_NAMED(new String[] { "id", "txt" }, Types.INT, Types.STRING));
如果您需要(或想要)手动提供类型信息,您可以用几种不同的格式提供它。所有这些最终都将包装在一个TypeInformation
中,它将公开Flink的所有类型详细信息。 Class< T > ,如果类型信息可以从中推断出来
- (在上一节的场景中,这不会有任何帮助!)
- 这通常在状态描述符中使用。
- 您还可以提供一个特定的类,否则 flink 只能看到基类。
TypeHint < t > 匿名类
- 这样,flink 的类型推断也可以捕获泛型参数!
TypeInformation信< T> 子类型
- 您可以使用 Types 类中的方便类型定义。、
- 复合类型可以通过所有细节指定,例如在与 Table API 交互时。这些代码嵌入如下代码:
您还可以创建自己的自定义子类型(后面将作为序列化性能调优的一部分介绍)。Table table = tEnv.fromDataStream(env.fromElements(Row.of(1, "first"), Row.of(2, "second")).returns(Types.ROW_NAMED(new String[] { "id", "txt" },Types.INT,Types.STRING)),Schema.newBuilder().column("id", DataTypes.INT()).column("payload", DataTypes.STRING()).build());
Avro序列化
- SpecificRecord
- 自动检测是否在使用或扩展SpecificRecordBase
GenericRecord
- 如果提供了模式(手动),则可以使用,例如
如果你在 Flink 中使用 SpecificRecord 而不是 SpecificRecordBase,它将不会标识为 Avro 类型,而 Flink 将使用 Kryo 进行反/序列化。详情请参阅 FLINK-12577。Schema schema = ...DataStream<GenericRecord> sourceStream = env.addSource(new AvroGenericSource()).returns(new GenericRecordAvroTypeInfo(schema));
注意 Avro 的 Schema 类是不可序列化的,这在这里显示的代码中不是问题,但是如果通过 getProducedType ()处理,可能会有所不同。但是,您可以在 Schema 和 String 之间来回转换,并且只在初始化时进行一次转换。
- 如果提供了模式(手动),则可以使用,例如
将 flink 的 PojoSerializer 交换为 Avro 的基于反射的序列化
env.getConfig().enableForceAvro();
强制 Flink 对 pojo 使用 Avro 的基于反射的序列化器通常是一个遗留选项,在 Avro 序列化没有得到很好集成时添加了这个选项。目前,似乎只有强制使用 Avro 增强的模式演化功能才有意义(见下一节) ,但是会带来严重的性能损失。
状态模式演化研究现状
- Avro 类型的模式演进
- 可以根据 Avro 规范进化模式
- 可以在 GenericRecord 和代码生成的 SpecificRecords 之间进行交换
- 不能更改生成的 SpecificRecord 类的命名空间
- POJO 模式演进
- 可以添加/删除字段,但不能更改类型
- 如果想要状态的可进化模式,请避免使用 Kryo
- env.getConfig().disableGenericTypes() 将禁用 Kryo 回退
- 尚不支持: Rows (用于表)
- 不支持: Scala case classes
状态迁移是从一个版本的快照迁移状态,并在数据模式更改后将该状态加载到下一个版本的过程。使用内置的序列化器,状态迁移将被自动处理。
如果状态迁移失败,那么模式更改就是不兼容的,并且作业也会失败。
请参阅 FLINK-10896 了解将模式演化支持扩展到其他类型的状态。对于 Scala case classes,还不清楚这是否可行。Avro 的特性:
http://avro.apache.org/docs/1.8.2/spec.html#Schema+Resolution

若有收获,就点个赞吧
0 人点赞
