使用vvp平台
开始
- 登录 Ververica 平台
- 进入 SQL 编辑器
- 尝试对现有表之一进行简单查询
- 系统将提示您创建预览会话集群
- 单击创建会话集群
- 保持默认配置,保存
- 集群将自动启动
- 几个小时不活动后,会话集群将被关闭
- 集群启动后,返回 SQL 编辑器并开始探索数据
此培训中的所有部署,包括此预览会话集群,将在几个小时不活动后自动暂停。准备好根据需要手动重新启动它。
数据集
这五个表都已创建并填充了数据。每个都由具有单个分区的 Kafka 主题支持:
Flink 邮件列表
- flink_ml_dev
- flink_ml_user
- flink_ml_user_zh
- 来自github的数据
- flink_commits
- flink_pulls
使用SQL编辑器
DESCRIBE flink_ml_dev;

使用临时视图
```plsql — extract the JIRA ticket number from the commit info CREATE TEMPORARY VIEW commitsWithTickets AS SELECT commitDate, author, REGEXP_EXTRACT(shortInfo, ‘(FLINK-[0-9])’, 1) AS ticket, shortInfo FROM flink_commits WHERE REGEXP_EXTRACT(shortInfo, ‘(FLINK-[0-9])’) IS NOT NULL;
SELECT * FROM commitsWithTickets;
- 请记住,临时视图的生命周期是有限的- 除了定义一个临时视图,还需要一个使用它的查询<a name="EU3qO"></a>## 使用like通过LIKE一张新表,创建一张表```plsqlCREATE TABLE flink_commits_with_tickets (ticket AS REGEXP_EXTRACT(shortInfo, '(FLINK-[0-9]*)', 1))LIKE flink_commits;
这个看起来感觉开销比较大,其实不是。该表由与 flink_commits 表相同的 Kafka 主题支持。
使用EXPLAIN
- 使用窗口TVF
EXPLAINSELECTwindow_start, count(*) AS cntFROM TABLE(TUMBLE(TABLE flink_commits, DESCRIPTOR(commitDate), INTERVAL '1' HOUR))GROUP BYwindow_start, window_end;
== Optimized Execution Plan ==Calc(select=[window_start, cnt])+- GlobalWindowAggregate(window=[TUMBLE(slice_end=[$slice_end], size=[1 h])], select=[COUNT(count1$0) AS cnt, start('w$) AS window_start, end('w$) AS window_end])+- Exchange(distribution=[single])+- LocalWindowAggregate(window=[TUMBLE(time_col=[commitDate], size=[1 h])], select=[COUNT(*) AS count1$0, slice_end('w$) AS $slice_end])+- Calc(select=[commitDate])+- TableSourceScan(table=[[vvp, default, flink_commits, watermark=[-($3, 86400000:INTERVAL DAY)]]], fields=[author, authorDate, authorEmail, commitDate, committer, committerEmail, filesChanged, sha1, shortInfo])
有趣的是输出中使用了两阶段窗口聚合优化,在键控数据交换之前使用 LocalWindowAggregate,然后是 GlobalWindowAggregate。
- 使用GROUP BY
EXPLAINSELECTTUMBLE_END(commitDate, INTERVAL '1' HOUR) AS endT,COUNT(*) AS cntFROM flink_commitsGROUP BYTUMBLE(commitDate, INTERVAL '1' HOUR);
这是一个更简单的,更少优化的GROUP BY 窗口运算执行计划。== Optimized Execution Plan ==Calc(select=[w$end AS endT, cnt])+- GroupWindowAggregate(window=[TumblingGroupWindow('w$, commitDate, 3600000)], properties=[w$start, w$end, w$rowtime, w$proctime], select=[COUNT(*) AS cnt, start('w$) AS w$start, end('w$) AS w$end, rowtime('w$) AS w$rowtime, proctime('w$) AS w$proctime])+- Exchange(distribution=[single])+- Calc(select=[commitDate])+- TableSourceScan(table=[[vvp, default, flink_commits, watermark=[-($3, 86400000:INTERVAL DAY)]]], fields=[author, authorDate, authorEmail, commitDate, committer, committerEmail, filesChanged, sha1, shortInfo])
创建表
如果尝试向一个不存在的表进行INSERT INTO
INSERT INTO bottomlessPitSELECT window_start, count(*) AS cntFROM TABLE(TUMBLE(TABLE flink_commits, DESCRIPTOR(commitDate), INTERVAL '1' HOUR))GROUP BY window_start, window_end;
编辑器将自动创建合适的 DDL
CREATE TABLE bottomlessPit (`window_start` TIMESTAMP(3) NOT NULL,`cnt` BIGINT NOT NULL)WITH ('connector' = 'blackhole');
创建应用
以这种方式创建应用将设置一个无限期运行查询的新 Flink 集群。该集群将配置专用资源、日志记录、指标等。 还可以使用其共享资源创建在会话集群上运行的应用。
- 需要为每个应用指定一个唯一名称。
- 除此之外,采用默认值。
创建完成后,点击开始按钮
应用配额限制一次只能运行 1 个应用
- 不再需要时立即取消(并删除)创建的任何应用
- 尝试运行更多将失败(但不会有明确的解释)
检查吞吐量和状态大小
应用运行时,job gragh 标签页显示作业的拓扑,以及每个任务的吞吐量和状态大小。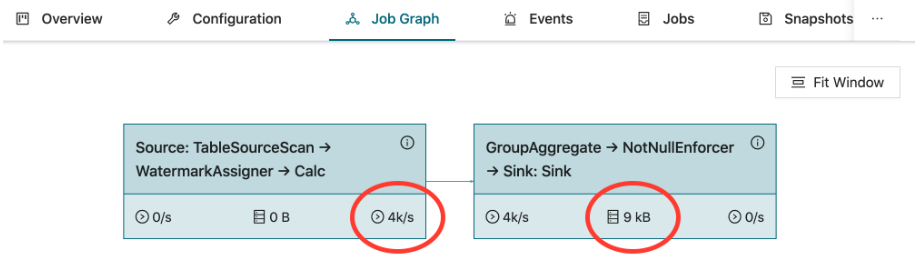
Flink UI, 运行指标和日志
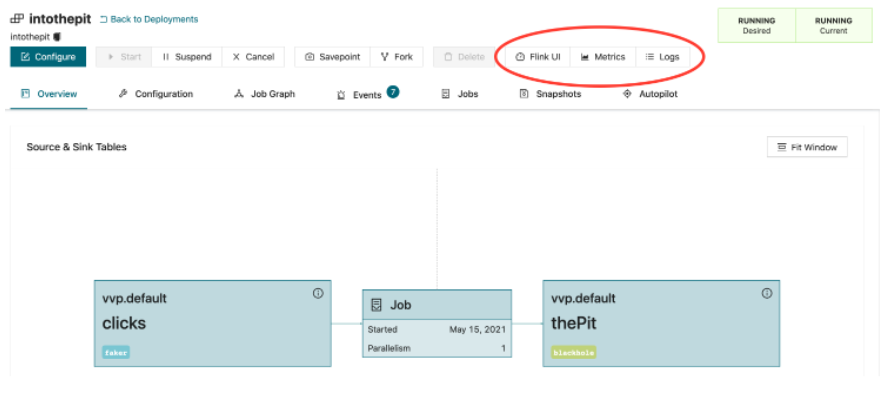
查看checkpoint指标
检查点大小逐渐增加:这个作业正在使用越来越多的状态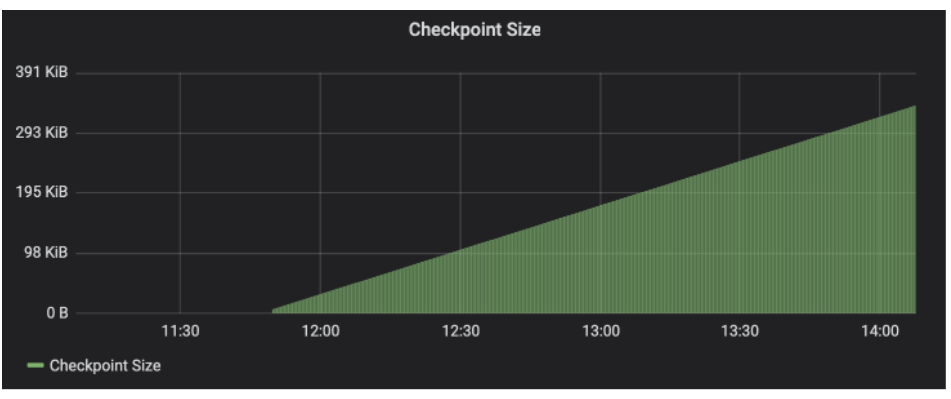

若有收获,就点个赞吧
0 人点赞
