join认为是关联/连接,一个意思。
关联静态表很好理解
- Join类型
- INNER JOIN, [LEFT, RIGHT, FULL] OUTER JOIN, CROSS JOIN
- 连接谓词
- 相等
- 不等
- 算法
- 循环
- 归并
- 哈希
- 处理关联时,静态表完全可用
流 vs 批
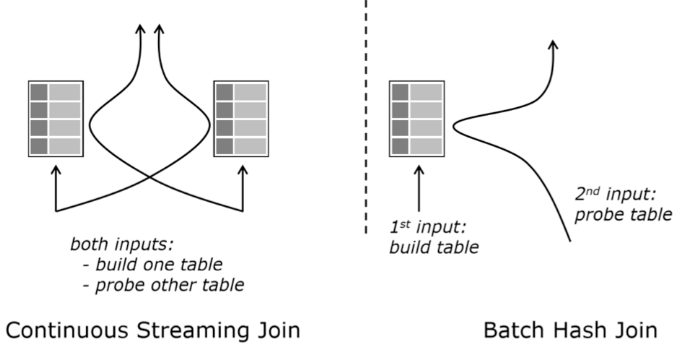
计算连接的传统算法是此处所示的一种算法,如右图所示:取出较小的表并将其加载到哈希表中,并根据正在执行的连接适当地keyed。这称为连接的“构建端”。然后对另一个表进行排序——“探测端”——在构建端找到匹配的记录。
这并不能完全满足我们对流式传输的需求,因为我们正在逐步计算结果——连接两侧的两个表都在不断地附加到。所以相反,我们为连接的两边建立一个哈希查找表。当我们收到 A 的记录时,我们将其添加到 A 的哈希表中,然后探测 B 以找到匹配的记录。对于 B,反之亦然。 这可行,但需要在 Flink 状态下保存潜在的大型且不断增长的哈希映射。
连接动态表更复杂
- 动态表总在变化
- 不同的要求和术语
- 在谈论流关联时,人们可能会想到不同的语义
- 连接流有不同的使用场景
- Flink SQL支持多种方式来关联动态表
- 区间连接
- 与时态表连接
- 查找连接(从外部数据库获取数据)
- 常规/默认连接
- 其他:CROSS JOIN UNNEST(array)等
由于需要将两个表都保留在状态中,因此常规的流式连接可能会非常昂贵,因此 Flink 社区已经为无需无限制状态保留即可处理的情况实施了许多特殊的优化连接。我们现在来看看这些优化的连接。在每种情况下,如果 Flink 的查询计划器能够将您的查询识别为这些特殊连接之一,那么它将使用有效的执行计划。
间隔连接
查找广告投放后 5 秒内点击的 URL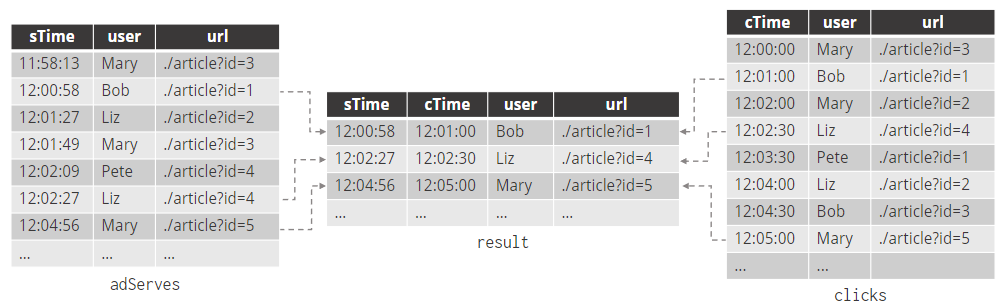
间隔连接是具有附加时间窗口约束的常规连接。
间隔连接:要求和语法
间隔连接连接两个仅附加表的记录,其中
连接记录的时间属性相隔不超过指定的时间间隔
SELECT url FROM clicks c, serves sWHERE-- equality predicatess.url = c.url AND s.user = c.user AND-- window using time attributesc.cTime BETWEEN s.sTime AND s.sTime + INTERVAL ‘5’ SECOND;
- 表必须是仅追加的(没有更新的行!)
- 必须有一个相等谓词
- 两个表的时间属性之间必须有时间约束
间隔连接:执行
- 两个 append-only 表的相关尾部都保持在 Flink 状态
- 这对应于他们的活跃窗口
- 一旦不能再被关联,就会立即从状态中删除
- 流之间的事件时间倾斜增加了状态大小
时态连接
- 使用时态(版本化)表
- 使用时态表函数
Flink 支持两种不同的时间连接方法。从语义上讲,这两种方法提供了或多或少相同的功能,但它们在某些细节上确实不同。
但在进入之前,让我们先看一个例子。
Part 1 时态表连接
- 假设
- 带有点击事件的仅追加型的点击表:用户、点击时间、网址
- 包含用户信息的更新 userHistory 表:id、subscription、versionTime
- 这个版本化的表必须有一个主键
- 此版本化表仅保留其历史的相关部分
- 用适用版本的用户信息补充每一次点击的信息

在此示例中,我们将每次单击与单击时有效的用户订阅信息相结合。例如,当 Mary 在 12:00:00 点击时,她有一个免费帐户,而当她在 15:00 点击时,她已升级为付费帐户。
时态表
临时表可以访问其历史记录。
仅追加表的每条记录都与对应于该记录的时间戳的临时表。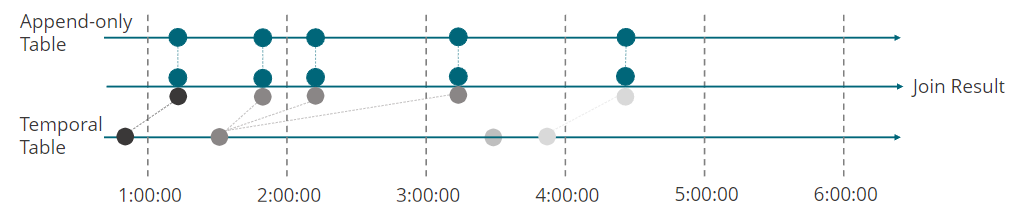
SELECT c.url, c.cTime, u.id, u.subscriptionFROM clicks cJOIN userHistory u FOR SYSTEM_TIME AS OF c.cTimeON c.user = u.id
- 需要版本化表的主键上的相等谓词
- 必须有时间属性
- 随着时间的推移,不再需要的版本会从状态中删除
TemporalProcessTimeJoinOperator支持处理时间的时态表连接。连接处理不会等待时态表的完整快照,因此可能会产生令人困惑的结果。
part2: 时态表函数
从概念上讲,它们提供了非常相似的功能,但是这些功能
- 专为仅插入流而设计(而 AS OF 连接专为更新流而设计)
- 将主键作为函数的属性(而不是表)
- 函数本身只能用 Table API 定义
与时态表函数的连接可以用 SQL 表示,但函数本身不能。
总结:时态连接的状态保留
Event time
Temporal table
for each unique key at least one row with the latest version is kept in state
possibly more versions depending on event time skew
Append-only table
rows with timestamps later than the current event-time are temporarily buffered in state
Event-time skew between tables increases state size
- 事件时间
- 时态表
- 对于每一个唯一的key而言,至少有一行最新的版本数据保持在状态中。
- 有可能更多版本,取决于是否事件时间倾斜
- 只追加表
- 晚于当前事件时间的带时间戳的行记录被时态缓存在state中
- 流之间的事件时间倾斜增加了状态大小
- 时态表
- 处理时间
- 时态表
- 对于每一个唯一的key而言,仅有精准的一行版本数据保持在状态中。
- 只追加表
- 所有行都立即连接而不缓冲
- 如果两个流没有很好地对齐,会产生意想不到的结果
- 时态表
这些存储要求适用于 AS OF 连接和时态表函数。与事件时间时态连接不同,处理时间时态连接不是确定性的。版本化表的每一行的最新接收版本在其事件到达时与左侧表连接,产生一种“尽力而为”的结果。
查找连接
使用外部表中的数据丰富仅插入的动态表。
举例:采用用户信息来补充每个click。
CREATE TEMPORARY TABLE users (id STRING,subscription STRING) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://mysqlhost:3306/userdb','table-name' = 'users');SELECT c.user, c.cTime, c.url, u.subscriptionFROM clicks cJOIN users u FOR SYSTEM_TIME AS OF c.proc_timeON c.user = u.id;
查找连接:必要和可选
- 查找连接必须:
- 使用查找源连接器,即 JDBC、HBase 或 Hive
- 有一个等于连接谓词
- 使用处理时间属性,结合FOR SYSTEM_TIME AS OF(防止需要更新连接结果)
- 查找是惰性完成的,获取适当的行
- 当作业运行时,外部表可以更新
- JDBC 支持一个可选的lookup cache (默认禁用)
- lookup.cache.max-rows
- lookup.cache.ttl
我们可以实现自己的自定义查找源,例如,它可以查询 REST API 而不是数据库。
常规/默认连接
常规连接:要求和语法
没有时态条件的连接通常认为是常规连接
SELECT *FROM A, BWHERE A.id = B.id
连接条件必须至少包含一个相等谓词
- 表A和B可以更新,也可以追加
-
常规连接:执行
连接算子将两个输入表完全具体化为状态
- 新记录可以与另一个表的任何记录连接
- 仅当两个输入表都没有变得太大时,常规连接才能正常工作
-
注意
常规连接的结果中不能有时间属性
- 输出结果行的顺序是未定义的
- 常规连接的结果可以包含时间戳,但是没有事件属性
- 在 Flink 1.14 之前,常规连接的输入中不能有时间属性
- 这是实现上的限制
- 时间属性必须被筛选出去,或者 CAST 为 TIMESTAMP
常规连接不会产生形成时间连贯流的结果。尝试在常规连接的结果中包含时间属性是没有意义的。如果在输出中包含时间属性,它们将作为普通时间戳被包含。
以前的实现无法处理常规连接的输入关系中的时间属性。使用这些早期版本,您可以使用嵌套的 SELECT 或在视图中投射时间属性(或将其作为 TIMESTAMP 投射)。
原型与调试
案例:使用datagen表源
CREATE TABLE orders (id INT,order_time AS TIMESTAMPADD(DAY,CAST(FLOOR(RAND()*(1-5+1)+5)*(-1) AS INT),CURRENT_TIMESTAMP))WITH ('connector' = 'datagen','rows-per-second'='10','fields.id.kind'='sequence','fields.id.start'='1','fields.id.end'='1000');
CREATE TABLE shipments (id INT,order_id INT,shipment_time AS TIMESTAMPADD(DAY,CAST(FLOOR(RAND()*(1-5+1)) AS INT),CURRENT_TIMESTAMP))WITH ('connector' = 'datagen','rows-per-second'='5','fields.id.kind'='random','fields.id.min'='0','fields.order_id.kind'='sequence','fields.order_id.start'='1','fields.order_id.end'='1000');
使用datagen表源可以很方便的快速开发和调试一个原型。这个例子来自Flink SQL Cookbook。
使用explain调试一个query
EXPLAIN-- Find orders that ship within 3 daysSELECTo.id AS order_id,o.order_time,s.shipment_timeFROM orders oJOIN shipments s ON o.id = s.order_idWHEREo.order_time BETWEEN s.shipment_time - INTERVAL '3' DAY AND s.shipment_time;
EXPLAIN-- Find orders that ship within 3 daysSELECTo.id AS order_id,o.order_time,s.shipment_timeFROM orders oJOIN shipments s ON o.id = s.order_idWHEREo.order_time BETWEEN s.shipment_time - INTERVAL '3' DAY AND s.shipment_time;
LogicalFilter(condition=[AND(>=($1, -($4, 259200000:INTERVAL DAY)), <=($1, $4))])+- LogicalJoin(condition=[=($0, $3)], joinType=[inner]):- LogicalProject(id=[$0], order_time=[+(CURRENT_TIMESTAMP, *(86400000:INTERVAL DAY,CAST(*(FLOOR(+(*(RAND(), +(-(1, 5), 1)), 5)), -1)):INTEGER NOT NULL))]): +- LogicalTableScan(table=[[vvp, default, orders]])+- LogicalProject(id=[$0], order_id=[$1], shipment_time=[+(CURRENT_TIMESTAMP,*(86400000:INTERVAL DAY, CAST(FLOOR(*(RAND(), +(-(1, 5), 1)))):INTEGER NOT NULL))])+- LogicalTableScan(table=[[vvp, default, shipments]])== Optimized Execution Plan ==Calc(select=[id AS order_id, order_time, shipment_time])+- Join(joinType=[InnerJoin], where=[((id = order_id) AND (order_time >= (shipment_time- 259200000:INTERVAL DAY)) AND (order_time <= shipment_time))], select=[id, order_time,order_id, shipment_time], leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey]):- Exchange(distribution=[hash[id]]): +- Calc(select=[id, (CURRENT_TIMESTAMP() + (86400000:INTERVAL DAY * CAST((FLOOR(((RAND()* -3) + 5)) * -1)))) AS order_time]): +- TableSourceScan(table=[[vvp, default, orders]], fields=[id])+- Exchange(distribution=[hash[order_id]])+- Calc(select=[order_id, (CURRENT_TIMESTAMP() +(86400000:INTERVAL DAY * CAST(FLOOR((RAND() * -3))))) AS shipment_time])+- TableSourceScan(table=[[vvp, default, shipments]], fields=[id, order_id])
总结
- 流式连接可能存在与状态和时间相关的问题
- 使用间隔连接和使用时态表连接,时间属性用于限制状态保留
- 常规连接可以无限期地建立状态并且不接受时间属性
- 查找联接可让您访问外部数据库以丰富数据

若有收获,就点个赞吧
0 人点赞
