StreamElement
Streams由StreamElements组成,有许多不同的类型
- StreamRecord: 对应用事件/消息的封装
- Watermark
- StreamStatus-IDLE vs. ACTIVE
- LatencyMarker-可以用于计算延迟度量
StreamRecord
包含:
- 用户消息/事件
事件时间戳
@Internalpublic final class StreamRecord<T> extends StreamElement {/** The actual value held by this record. */private T value;/** The timestamp of the record. */private long timestamp;...}
每个应用事件记录都包装在一个包括时间戳的 StreamRecord 中。每当 Flink 需要event time时间戳时,它都会在此字段中查找。
Watermark
Watermark也是一个包含时间戳的StreamElement。
@PublicEvolvingpublic final class Watermark extends StreamElement {/** The timestamp of the watermark in milliseconds. */private final long timestamp;...}
如何测量事件时间?时间戳和水印是long型的,它们必须具有可比性,并且测量相同的内容。按照惯例,它们以自纪元以来的毫秒为单位测量时间,在事件时间窗口计算的的Data Stream和 SQL API 中假定如此。但在 Flink 的较低级别,事件时间是一个纯粹的抽象,例如,
- 事件时间可以用纳秒而不是毫秒来测量
- 事件时间可以表示为单调递增的序列号
Watermark如何传播
Watermark生成器的每个并行实例都基于它观察到的事件独立运行。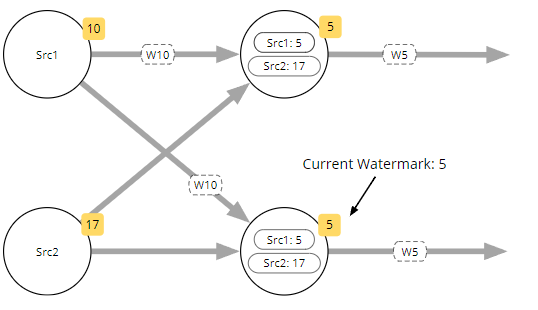
具有多个输入的任务的当前Watermark是来自其所有输入的当前Watermark的最小值。在这个例子中Watermark由sources生成。这种Watermark如何并行工作的定义是有意义的,因为Watermark是关于流完整性的声明。从具有多个输入的运算符的角度来看,它只能与最落后的传入流一样完整。 将注意力集中在右下角的任务上,到目前为止,它已收到来自 Source1 的带有时间戳 5(W5)和来自 Source2 的 W17 的Watermark,它即将收到来自 Source 1 的 W10。
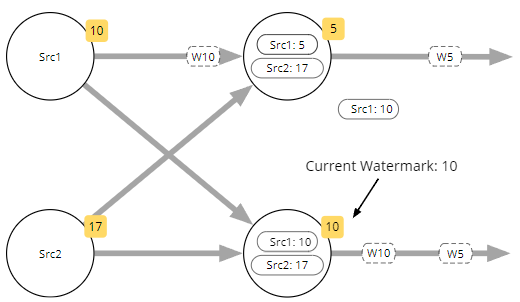
一旦 W10 被此任务处理,它会将当前Watermark的本地版本更新为 10,然后继续传递 W10。
Timestamps和Watermarks怎么来
Watermark strategies
Since Flink 1.11
- 对于事件时间处理,Flink需要
- 事件时间戳
- Watermark
- WatermarkStrategy 可以同时满足这两个需求
- WatermarkStrategy 可以应用于
- sources之后
- sources中(首选,但并非总能达到)
WatermarkStrategy创建timestamp assigner和watermark generator。
- The timestamp assigner
- 在每个 StreamRecord 中设置时间戳字段
- 收集生成Watermark所需的信息
- The watermark generator生成watermarks
- 按需(定期,基于 ExecutionConfig#getAutoWatermarkInterval,默认AutoWatermarkInterval为200ms),和/或
- 作为处理每个事件的一部分
原生支持的strategies
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofMillis(10))
- 典型用法:约束无序延迟
WatermarkStrategy.forMonotonousTimestamps()
- 特殊情况:升序时间戳
- 当事件完全有序时使用
- Watermark不会延迟
- 没有迟到的事件
WatermarkStrategy.noWatermarks()
- 特殊情况:在不需要Watermark的应用中使用新的统一源接口时(例如,有界/批处理、基于处理时间的应用)
在source后使用WatermarkStrategy
- 使用原生支持的BoundedOutOfOrderness作为Watermark生成器
- 使用一个lamba语句assigns timestamps
```java
DataStream
events = env.addSource(…);
DataStream
<a name="j90Ky"></a>### 在kafka sources后应用有界无序watermarking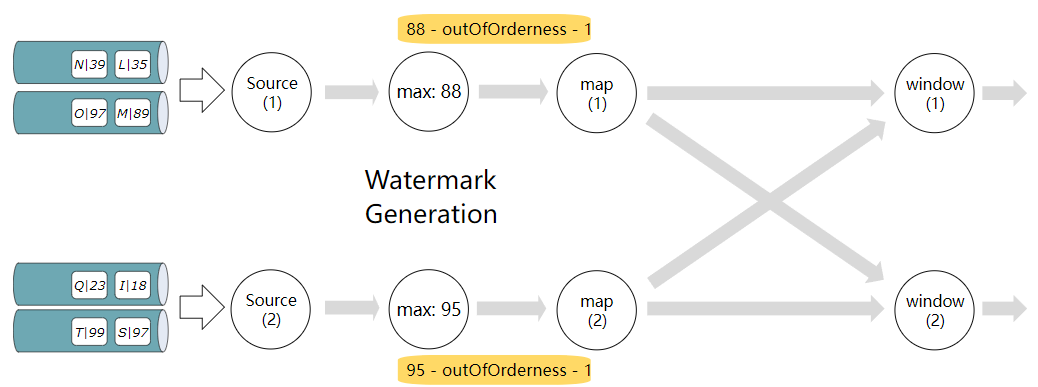- 蓝色圆柱表示kafka partition。- Source(1) and Source(2) 每个消费2个kafka partitions。- watermark是在位于source之后的单独watermark运算符中生成的。- watermark operator 的每个实例都在跟踪它迄今为止看到的最大时间戳,并产生等于 maxTimestamp - outOfOrdernessMillis - 1的watermark.说明:- 白色矩形中带着N|39 文本表示 key N的一个事件,事件戳是39- 黄色矩形中有一个数字,表示该work instance当前的watermark- 圆圈中的数字,例如the (1) or (2) 在source、map、window下,表示当前并行的实例编号<a name="Gtfwt"></a>### 在source (Kafka)中应用有界无序watermarking```javaFlinkKafkaConsumer<MyType> kafkaSource = new FlinkKafkaConsumer<>("myTopic", schema, props);kafkaSource.assignTimestampsAndWatermarks(WatermarkStrategy.forMonotonousTimestamps());DataStream<MyType> stream = env.addSource(kafkaSource);
- Kafka source实现每个partition watermark
- FlinkKafkaConsumer跟踪每个partition的最大时间戳
- 根据the min of these maximums,生成watermark
- forMonotonousTimestamps 只需要每个partition中有序的时间戳
- 如果源是kafka,timestamp assigner不是必须的
- Kafka 源将使用 Kafka 消费者记录的header中的时间戳
- 你可以提供你自己的timestamp assigner来覆盖它
- 要在 Kafka 源中执行此覆盖操作,必须为源提供一个反序列化模式,该模式生成可以从中提取(或计算)时间戳的对象。如果使用 SimpleStringSchema,则不行。
当使用支持in source的源时,例如 Kafka,最好让源应用 WatermarkStrategy。如果 Kafka 配置了 LogAppendTime,那么时间戳将在每个分区中按顺序排列。但是在源之后添加watermark,实际上不可能利用这一特性。这是因为timestamp assigner将对来自多个 Kafka 分区的事件进行操作,因此将在具有一些乱序的流上进行操作。
但是,如果 Kafka 源进行watermark,它可以进行每个分区的watermark,并使用单调(升序)时间戳策略生成正确的watermark。
Per-partition watermarking
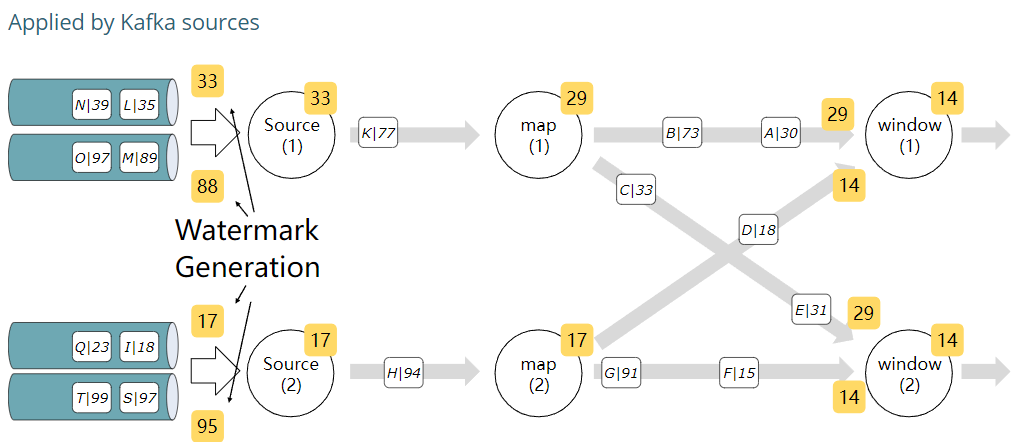
空闲源
当源(分区/分片/拆分)不产生任何数据时——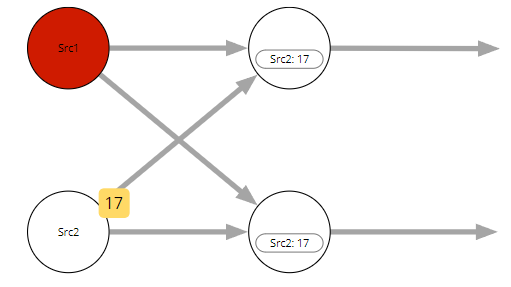
因为要比较多个源的max timestamp,在没有事件到达的情况下,WatermarkGenerator 没有推进当前watermark的基础,空闲源可能导致整个pipeline停止工作。
空闲源问题的解决方案
融合潜在地空闲流和非空闲流,例如rebalance()
- 引起网络shuffle
将近似空闲的stream的watermark设置为Watermark.MAX_WATERMARK
- 例如很少改变的metadata流信息
使用withIdleness(duration) (new in Flink 1.11)
- 在没有事件的一段时间后将流标记为空闲
- 空闲流不会阻止来自活动流的watermark
- FLINK-18934 有两个输入流运算符的某些极端情况,这种机制不能正确传播空闲
WatermarkStrategy.<MyType>forBoundedOutOfOrderness(Duration.ofSeconds(20)).withIdleness(Duration.ofMinutes(1));
如果所有的都是空闲流呢?
没有事件—>没有watermark —>计时器不会被触发、窗口不会关闭
解决方案:
- 如果空闲是暂时的,那么这是一个需要被解决的问题吗?
- 从源安排保持活动的事件
实现watermark,用于检测空闲,并人为推进watermark
- example
总结
在完整性和延迟之间掌握平衡
- example
不同的场景有不同的需求
- 对延迟敏感的应用可能必须尽早添加watermark,或者
- 承受不得不根据不完整信息采取行动的后果
- 或在提供初步的早期结果后,在迟到的数据到来时提供更新的结果
- 对延迟相对不敏感的应用可以为无序事件等待更长的时间
考虑需要提供这种灵活性,所以Flink 没有为使用事件时间数据流所产生的乱序数据问题提供开箱即用的万能统一的解决方案。
回顾
- 在这节中我们了解到什么是Watermark,他们如何被创建
- Watermark策略:bounded-out-of-order vs. monotonous watermarking
- Watermark如何流经execution graph
- 单分区的watermarking
- 空闲数据源问题
资源

若有收获,就点个赞吧
0 人点赞
