编目
- 保存有关的元数据
- 数据库、表、函数、视图
- 实现
- PostgresCatalog
- HiveCatalog
- Ververica Platform Built-in Catalog
- Pulsar Catalog
编目并不是必须的
在默认编目的默认数据库中创建 Orders 表
- 全表名字为
. .Orders - docs
请注意,此表不包含任何数据;数据位于支持此表的 Kafka 主题中。
列类型
- 物理(常规)列
- 元数据列
- 这些允许访问每行连接器和/或格式元数据
计算列
- 可以引用常量、内置函数和其他列的虚拟列
- 计算列不能使用子查询或引用其他计算列
上面表包含上述3种类型列CREATE TABLE Orders (`order_id` BIGINT,`order_time` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp', -- read/write metadata`offset` BIGINT METADATA VIRTUAL, -- read-only metadata`price` DECIMAL(32, 2),`quantity` INT,`cost` AS price * quanitity -- computed column) WITH ('connector' = 'kafka', ...)
order_time 来自kafka头的时间戳
- VIRTUAL 关键字将此偏移量 METADATA 列标记为只读
- 在这种情况下,Kafka 偏移量是 SELECT 查询中可用,但是 INSERT INTO不可用
- 这个cost列不会被物理存储,它的类型是自动派生的
持续的表类型
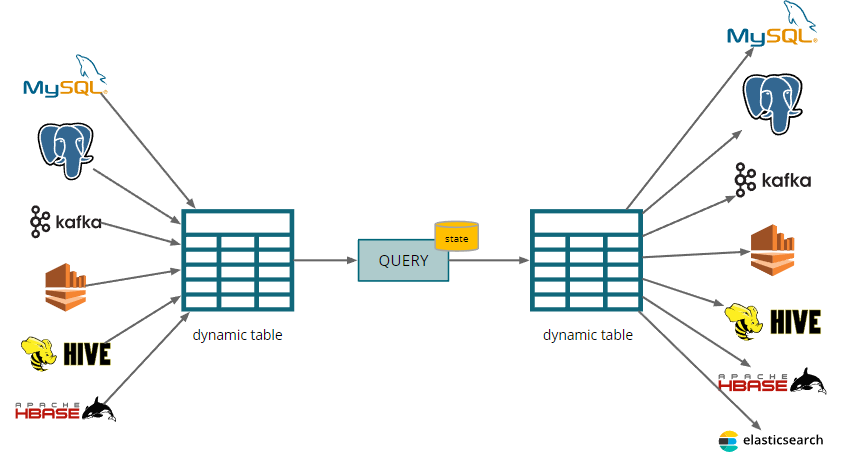
流→ 动态表转换
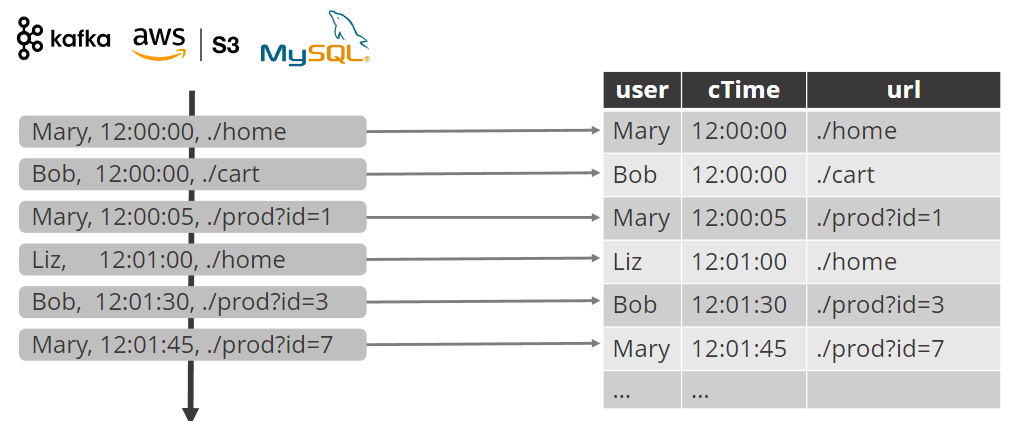
查询动态表
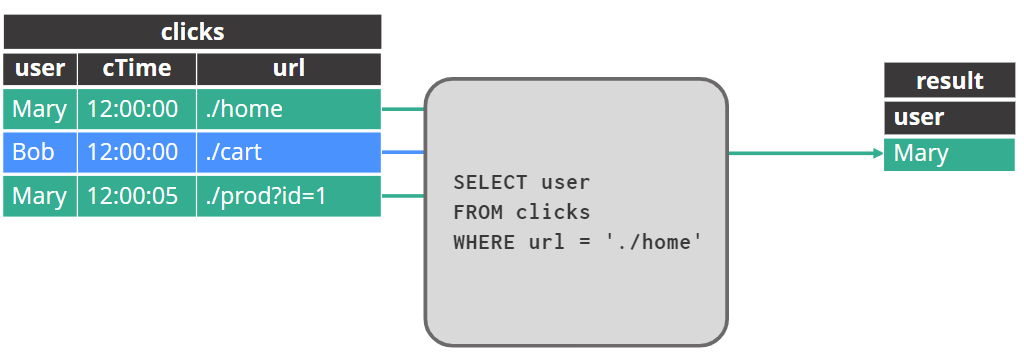
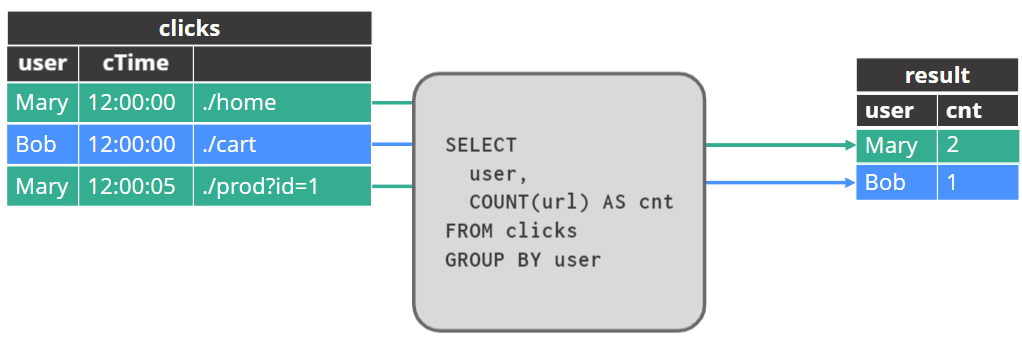
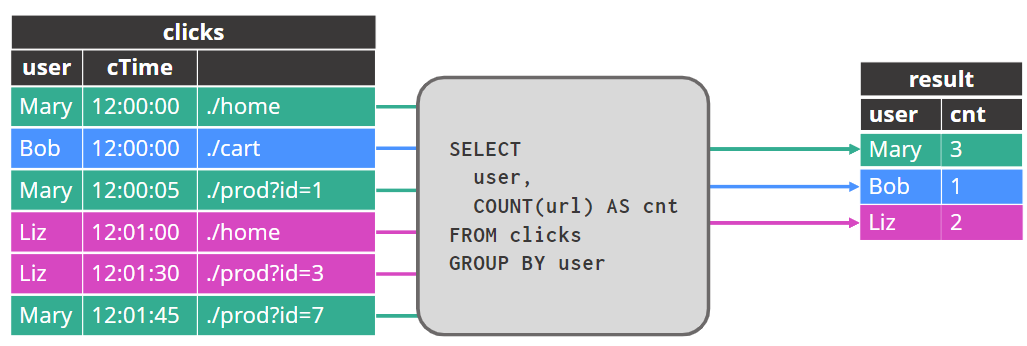
追加结果表的行(append)
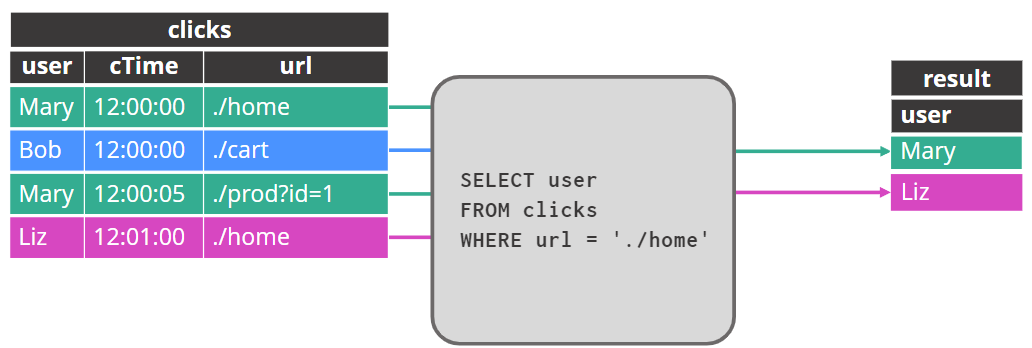
更新结果表的行updated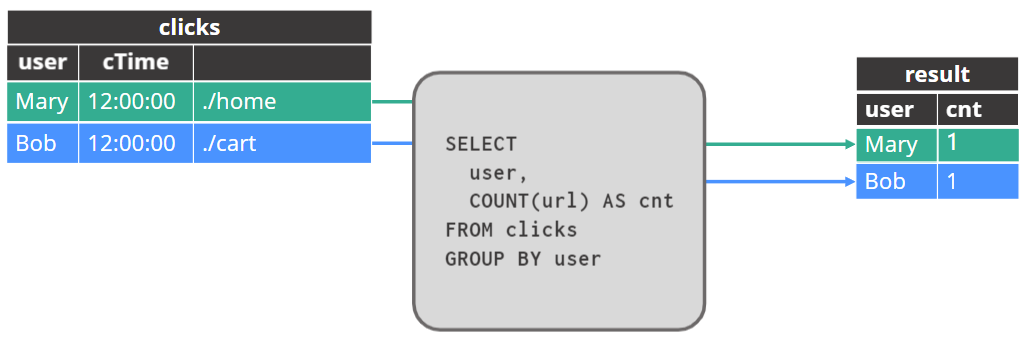
动态表→ 流转换
追加模式
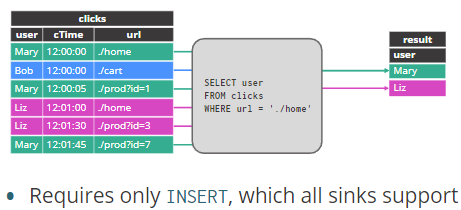
只需要insert,所有sink都支持
回缩(更新)模式
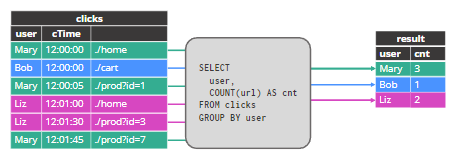
- 部分接收器不支持撤回
- 例如,FileSink 仅支持 CDC 格式的撤回
- 部分实施撤回: INSERT + DELETE
- JDBC, Elasticsearch
- 部分实施撤回:UPSERT + DELETE
- JDBC, Elasticsearch, Upsert Kafka
有两种样式的动态表到流转换。一些操作符会产生一个 APPEND 流——例如,如果您只进行投影和过滤,则生成的流不需要进行任何撤回,而只需要对 sink 进行 INSERT。所有接收器都支持这一点。
另一种动态表到流转换的样式涉及更新先前发出的结果。有些接收器根本无法处理这个问题,或者只能以某些格式处理它。
一些接收器通过删除先前发出的行,然后插入新结果来实现更新,而其他接收器可以执行 UPSERT。此外,一些接收器,如 JDBC 数据库,支持这两种实现撤回的方案。
算子和状态
算子类型
- 无状态类型
- 投影(select)
- 过滤(where)
- 物化(有状态)算子:最终可能会使用无界状态。
- Aggregation (GROUP BY)
- Joins
- 时态算子
- 窗口聚合(GROUP BY, OVER,window table-valued functions)
- Time-based joins (interval joins, temporal table joins)
- 模式匹配 (MATCH_RECOGNIZE)
时态算子能够利用时间约束来限制他们保留的状态量。
物化视图
结果表的行存储在 Flink 状态,并随着新数据的到来而更新。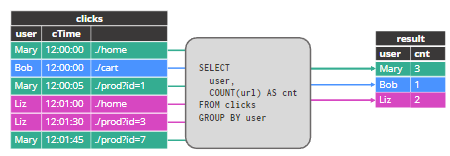
- 聚合需要永远为每个用户维护一个计数
- 每个用户都可以随时点击
- 聚合状态随着每个新用户而增长
- 对于某些聚合函数,状态随着每个新的输入行而增长
状态算子
- 物化算子
- 计算不受时间条件的限制,并且永远不会完成
- 输入和输出记录可以更新或删除
- 永久保存记录和/或结果
- 状态可以随时间增长(取决于查询和数据)
- 时态算子
- 每条记录都与一个时态条件相关联
- 只接收新输入
- 以前添加的记录无法更新或删除
- 将记录和/或结果保持在状态,不再需要后就不存了
详细关于时态算子的细节,参考time and windows and joins
管理物化算子的状态大小
- 查询状态可能无限增长
- 取决于查询和输入表
- 可以通过扩展集群来解决缓慢增长的状态
- SELECT user, COUNT(*) FROM logins GROUP BY user;
状态可以自动修剪
配置 Flink 自动移除 一段 时间未访问的状态
- 移除状态时查询结果不更新
- 如果被移除的状态不再需要,查询结果保持一致
- 如果查询需要被删除的状态,查询结果将变得不一致
- 需要权衡准确性和状态大小
总结
- 流被解释为表的变更日志
- 对动态表的 SQL 查询产生另一个动态表
- 生成的动态表可能是仅追加或更新的,具体取决于输入和查询
- 动态表可以转换回流
- INSERT-only, INSERT+DELETE, UPSERT+DELETE
- 注意你的查询状态不会无限增长
- 您可以使用 RocksDB 状态后端来管理非常大的状态
- 时态算子将自动使不再有用的状态过期
- 但是我们可能需要设置一个空闲状态保留间隔

若有收获,就点个赞吧
0 人点赞
