为了快速实现原型,安装flink-faker插件。
- 使用SQL->Connectors菜单访问连接器页面。
- 点击Create Connector按钮
- 使用此URL上传Flink-Faker Jar
- 接受默认值并完成创建连接器
- 现在将看到“ Faker”已添加到连接器列表中(它不会列出任何格式;这是正常的)
Exercise #0
使用Faker连接器创建点击表
可以尝试一个简单的查询(例如, SELECT * FROM clicks),直观看到数据内容,发生了什么。CREATE TABLE `vvp`.`default`.`clicks` (`user` STRING,`url` STRING,`cTime` TIMESTAMP(3),WATERMARK FOR `cTime` AS cTime - INTERVAL '5' SECOND)WITH ('connector' = 'faker','rows-per-second' = '10000','fields.user.expression' = '#{name.firstName}','fields.url.expression' = '#{regexify ''/product/[0-9]{2}''}','fields.cTime.expression' = '#{date.past ''5'',''1'',''SECONDS''}');
Exercise #1
没有时间属性的窗口。
执行以下案例,运行一小会
SELECTFLOOR(cTime TO SECOND) AS window_start,count(url) as cntFROM clicksGROUP BY FLOOR(cTime TO SECOND);
由于与浏览器进行通信的开销,结果将显得比实际更新缓慢。
请确保查看结果窗格中的Changelog选项卡。你会看到很少的插入(+I)和大量的撤销:-U(之前更新)和+U(之后更新)
Exercise #2
使用GROUP BY windows
尝试这种窗口样式
- 在你看之前,你能预测你现在会在Changelog标签中看到什么吗?
与前面的例子相比,变更日志现在完全由插入(+I)事件组成。这是因为GROUP BY windows分组窗口聚合函数只在窗口完成时产生结果。SELECTTUMBLE_START(cTime, INTERVAL '1' SECOND) AS window_start,COUNT(url) AS cntFROM clicksGROUP BY TUMBLE(cTime, INTERVAL '1' SECOND);
Exercise #3
使用一个window table-valued function(tvf)。
SELECTwindow_start, count(url) AS cntFROM TABLE(TUMBLE(TABLE clicks, DESCRIPTOR(cTime), INTERVAL '1' SECOND))GROUP BY window_start, window_end;
注意:这是最有效的方法,但在这里不能确定,因为浏览器预览本身就是瓶颈。这个示例的结果与Exer2一样。
Exercise #4
比较 job graphs和state的大小。
- 为这些不同的打开窗口的方法创建部署(一次一个)
- 使用blackhole黑洞接收器连接器,类似前面的示例。
- 资源有限,所以一次只运行一个应用
- 检查它们各自的作业图和状态大小,看看能否解释它们之间的差异 | type of window | topology | state size | | —- | —- | —- | | 1: GROUP BY FLOOR(…) | 2 stages | unbounded | | 2: GROUP BY TUMBLE(…) | 2 stages | bounded (2KB) | | 3: Window TVF | 3 stages | bounded (2KB) |
版本1正在使用物化聚合,并且永远不会使状态过期。它不理解分组键的时态特性。
版本2正在进行时间聚合,在窗口完成时丢弃它们。
版本3有这些优化:
- 一个本地聚合器(链接到源)对每个键的批进行累积,然后一个全局聚合器组合这些累加器(docs)
- 本地和全局聚合器都使用小批量(mini-batches)来避免为每条记录更新状态
Exercise #5
添加一个时间约束,将此查询转换为interval join(间隔关联)。
SELECTp.number AS PR,TIMESTAMPDIFF(DAY, p.createdAt, c.commitDate) AS daysUntilCommitted,c.shortInfoFROM flink_pulls pJOIN flink_commits cON p.mergeCommit = c.sha1;
| TIMESTAMPDIFF(timepointunit, timepoint1, timepoint2) | INT | 返回timepoint1和timepoint2相差的时间单元数量 timepointunit表示时间单元,应该是SECOND、MINUTE、HOUR、DAY、MONTH或YEAR 例如: TIMESTAMPDIFF(DAY, TIMESTAMP ‘2003-01-02 10:00:00’, TIMESTAMP ‘2003-01-03 10:00:00’) 返回1 |
|---|---|---|
TODO上面这个关联语句state是无限存储?然后只要有一条流更新了一条记录,那么会去另一条流中找所有满足关联条件的?
- 通过将其更改为间隔联接,将更改查询语义;
- 当EXPLAIN间隔联接时,可以看到该计划包括一个IntervalJoin。
例如
EXPLAINSELECTp.number AS PR,TIMESTAMPDIFF(DAY, p.createdAt, c.commitDate)AS daysUntilCommitted,c.shortInfoFROM flink_pulls pJOIN flink_commits cON p.mergeCommit = c.sha1WHERE c.commitDate BETWEEN p.createdAt ANDp.createdAt + INTERVAL '30' DAY
产生
== Optimized Execution Plan ==Calc(...)+- IntervalJoin(...):- Exchange(distribution=[hash[mergeCommit]]): +- Calc(select=[createdAt, mergeCommit, number]): +- TableSourceScan(table=[[vvp, default, flink_pulls, watermark=[-($2, 604800000:INTERVAL DAY)]]], fields=[closedAt, commentsCount, createdAt, creator, creatorEmail, description, labels, mergeCommit, mergedAt, number, state, title, updatedAt])+- Exchange(distribution=[hash[sha1]])+- Calc(select=[commitDate, sha1, shortInfo])+- TableSourceScan(table=[[vvp, default, flink_commits, watermark=[-($3, 86400000:INTERVAL DAY)]]], fields=[author, authorDate, authorEmail, commitDate, committer, committerEmail, filesChanged, sha1, shortInfo])
Exercise #6
为什么不能将其作为间隔关联执行?
SELECTp.number AS PR,TIMESTAMPDIFF(DAY, p.createdAt, p.mergedAt) AS daysOpen,c.shortInfoFROM flink_pulls pJOIN flink_commits cON p.mergeCommit = c.sha1WHERE p.mergedAt = c.commitDate;
这个连接被解释为常规连接,因为p.mergedAt不是时间属性。查看了mergedAt 类型为TIMESTAMP(3)。commitDate也是TIMESTAMP(3)。
TIMESTAMP(3) 时间戳格式1997-04-25T13:14:15 TIMESTAMP
- 功能描述将时间字符串转换为时间戳,时间字符串格式为:”yyyy-MM-dd HH:mm:ss[.fff]“,以TIMESTAMP(3)类型返回。
- 语法说明TIMESTAMP(3) TIMESTAMP string
Exercise #7
- 这个MATCH_RECOGNIZE 正则查询匹配所有pr数量当周相比上周下降的情况。
- 你能扩展这个模式,使它与PRs的数量连续3周下降时相匹配吗?
查看下结果,我把window_start, window_end, window_time同时打出来看看。SELECT * FROM ( -- pull requests per weekSELECT window_time, window_start, count(1) AS cntFROM TABLE(TUMBLE(TABLE flink_pulls, DESCRIPTOR(createdAt), INTERVAL '7' DAY))GROUP BY window_start, window_end, window_time) MATCH_RECOGNIZE (ORDER BY window_timeMEASURESw1.window_start AS `start`,w1.cnt AS week1,w2.cnt AS week2PATTERN (w1 w2)DEFINEw1 AS true,w2 AS w2.cnt < w1.cnt);
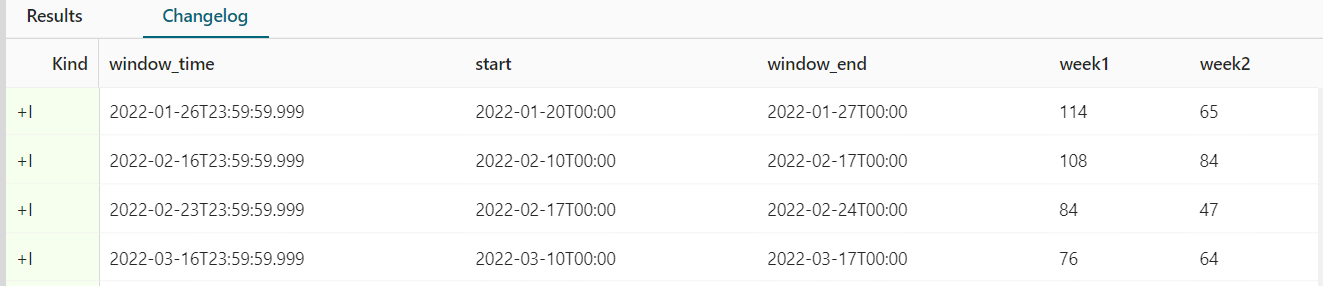
连续3周下降扩展SELECT * FROM ( -- pull requests per weekSELECT window_time, window_start, count(1) AS cntFROM TABLE(TUMBLE(TABLE flink_pulls, DESCRIPTOR(createdAt), INTERVAL '7' DAY))GROUP BY window_start, window_end, window_time) MATCH_RECOGNIZE (ORDER BY window_timeMEASURESw1.window_start AS `start`,w1.cnt AS week1,w2.cnt AS week2,w3.cnt AS week3,w4.cnt AS week4PATTERN (w1 w2 w3 w4)DEFINEw1 AS true,w2 AS w2.cnt < w1.cnt,w3 AS w3.cnt < w2.cnt,w4 AS w4.cnt < w3.cnt);
Exercise #8
去重举例
CREATE TEMPORARY VIEW first_commits_from_new_contributors ASSELECT author, committer, commitDate, shortInfo, sha1, filesChangedFROM (SELECT *,ROW_NUMBER() OVER (PARTITION BY author ORDER BY commitDate) AS rownumFROM flink_commits)WHERE rownum = 1;SELECT author, committer, commitDate FROM first_commits_from_new_contributors;
- 此查询返回每个新参与者创建的第一个提交,以及审查其贡献的提交者
- 我们如何从这个练习中学到Flink新贡献者的一些有价值的东西呢?
- 更多请看deduplication queries in the docs
Exercise #9
flink提交有一个filesChanged列,该列包含一个ROWs数组
CREATE TABLE `vvp`.`default`.`flink_commits` (`author` VARCHAR(2147483647),`authorDate` TIMESTAMP(3),`authorEmail` VARCHAR(2147483647),`commitDate` TIMESTAMP(3),`committer` VARCHAR(2147483647),`committerEmail` VARCHAR(2147483647),`filesChanged` ARRAY<ROW<`filename` VARCHAR(2147483647), `linesAdded` INT, `linesChanged` INT, `linesRemoved` INT>>,`sha1` VARCHAR(2147483647),`shortInfo` VARCHAR(2147483647),WATERMARK FOR `commitDate` AS `commitDate` - INTERVAL '1' DAY)COMMENT 'Commits on the master branch of github.com/apache/flink'WITH ('connector' = 'kafka',...);
尝试使用CROSS JOIN UNNEST
SELECTsha1, filename, added, changed, removedFROMflink_commitsCROSS JOIN UNNEST(filesChanged) AS files (filename, added, changed, removed);
Exercise #10
安装UDF包
From the SQL Functions page click on “Register UDF Artifact” click on “Use URL” use this URL: https://github.com/ververica/lab-flink-repository-analytics/releases/download/release-2.1.60-ffg21-1/flink-repository-analytics-sql-functions-2.1.60-ffg21-1.jar and supply a name, such as “community-udfs” submit the form click on “Create Functions” Return to the SQL Editor
这些udf来自 https://github.com/ververica/lab-flink-repository-analytics ,包含一些用于处理Flink社区数据的有用函数,包括
- NormalizeEmailThread(subject): STRING
- 从邮件列表表中获取主题字段,并返回规范化的电子邮件线程名称,例如,去除Re:并删除空白。
- GetSourceComponent(filename): STRING
- 接受一个文件名(相对于Flink代码仓库),并返回与之关联的Flink源代码组件。
- IsJiraTicket(fromRaw): BOOLEAN
- 从DEV邮件列表表中获取FromRaw字段,并返回消息是否源自镜像的JIRA交互(而不是来自用户/开发人员)。
- GetJiraTicketComponents(textBody): ARRAY
- 解析开发邮件列表表中的textBody字段,并搜索来自已创建的Jira票据的电子邮件中的组件列表。如果textBody是NULL,结果也将是NULL,如果没有找到匹配,结果将是一个空数组。为了减少负载和假阳性匹配的机会,我们建议使用上面的IsJiraTicket函数过滤掉非jira消息。
- NormalizeEmailThread(subject): STRING
- 更多查看 Simplifying Ververica Platform SQL Analytics with UDFs
使用udf示例
SELECT *FROM (SELECT *, ROW_NUMBER() OVER (ORDER BY cnt DESC) AS row_numFROM (SELECT NormalizeEmailThread(subject), count(*) AS cntFROM flink_ml_devGROUP BY NormalizeEmailThread(subject)))WHERE row_num <= 10;
- 安装了这些udf,可以尝试这个查询来找到10个最流行的电子邮件线程。
- 更多查看 top-n queries in the docs
从changelog来看看效果,是有回撤的。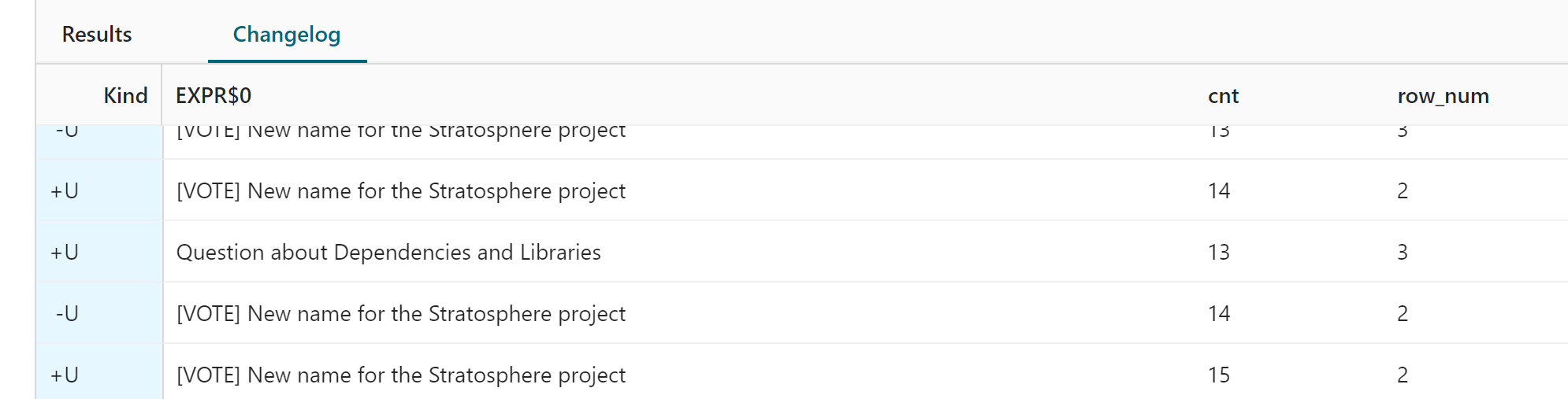
更多

若有收获,就点个赞吧
0 人点赞
