在此系列文章中,我们将深入研究如何构建健壮的、有状态的流处理应用程序。但首先,我们需要了解Flink应用程序的基础知识。
有状态流处理
传统系统应用
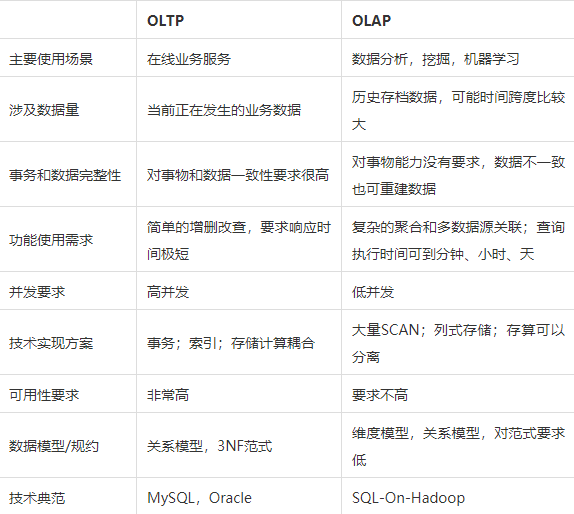
事务型应用(OLTP)
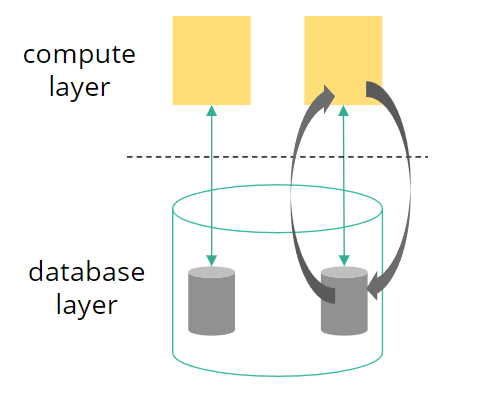
特点:
- 通常是Request/Response模式
- 两层结构+事务型数据库
- 每次请求通常只涉及有限的记录数(几行等)
举例
- 会议预定系统
- 电商
- 客户关系管理系统CRM
- Web应用
分析型应用(OLAP)
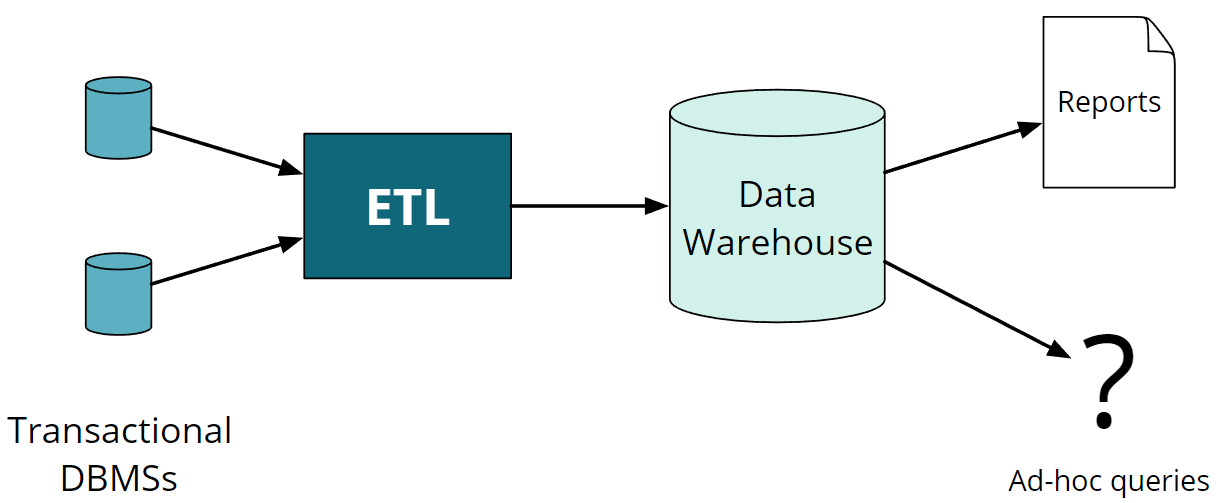
事务型应用和分析型应用一般是分开建设的:
- 面向行访问和面向列访问;
- 事务型应用通常要求低延迟,分析型通常对延迟相对不敏感。
分析型应用的访问方式一般有2种:
- 报表
- 即席查询
流式应用
无状态流计算
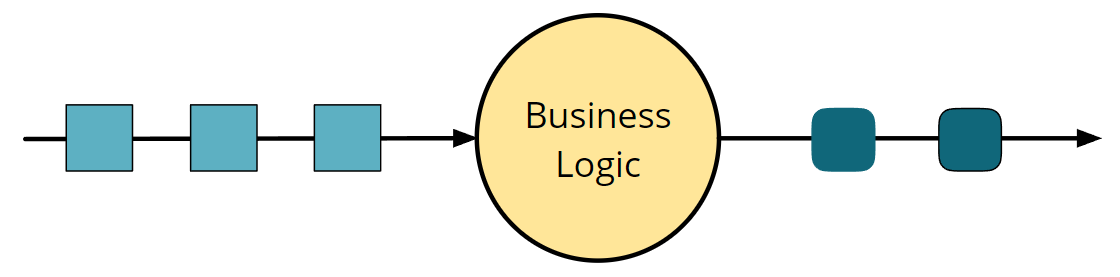
有状态流计算
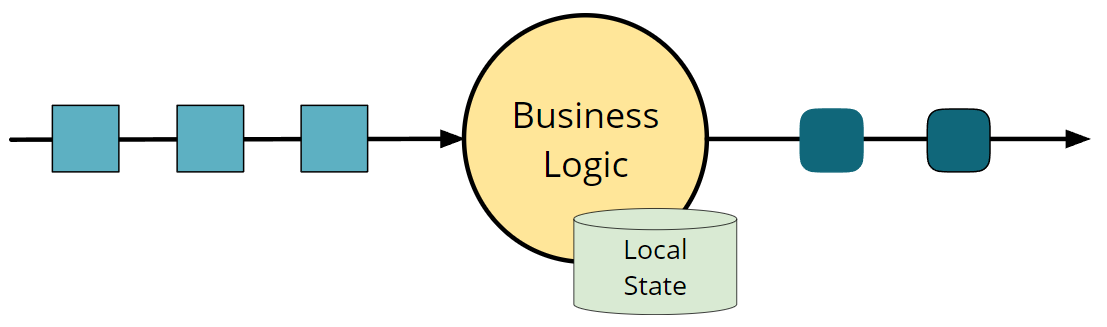
一般来说,大部分的应用都是需要保持状态的。比如计数器、1分钟窗口内的最高max、最低值min。还有些更复杂的情况,状态用来计算一些异常检测、欺诈检测模型中的特征。FLink采用本地化保存状态模式,即保存在消息/事件被处理的机器上。这个状态存储在本地内存或者嵌入式数据库中。
应用案例
streaming ETL
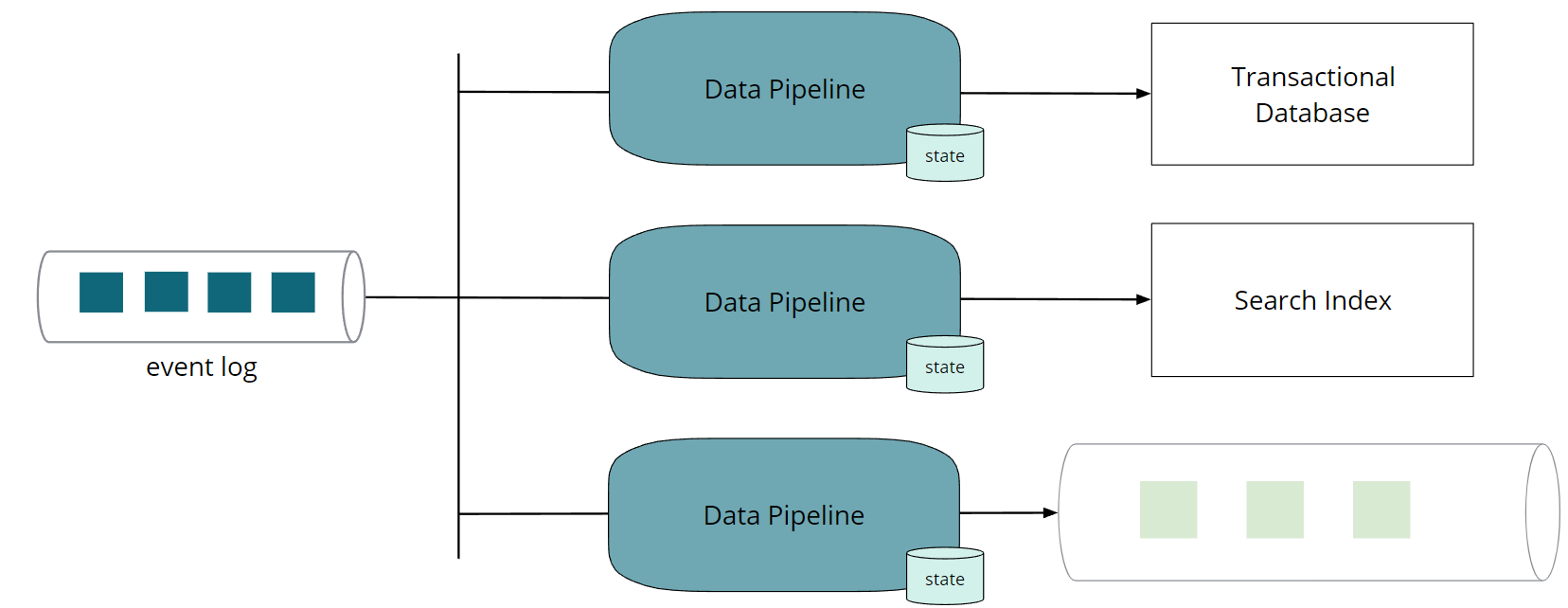
流式数据经过流式ETL从一个位置搬到另一个位置,是一个非常典型的应用。
streaming analytics
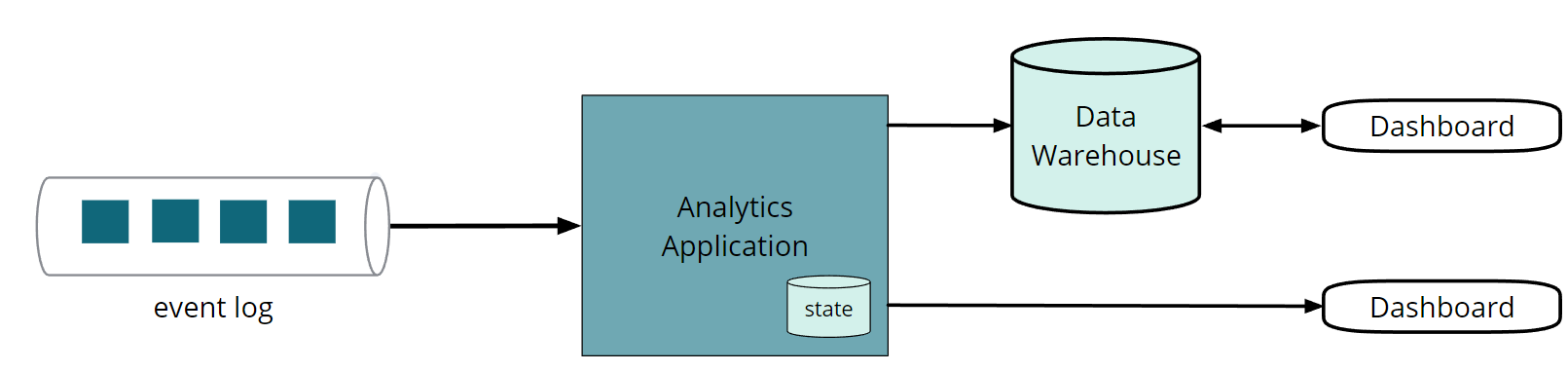
流式分析应用也是一个典型的应用场景,前提是需要对状态管理和时间管理有比较好的抽象。
机器学习模型服务
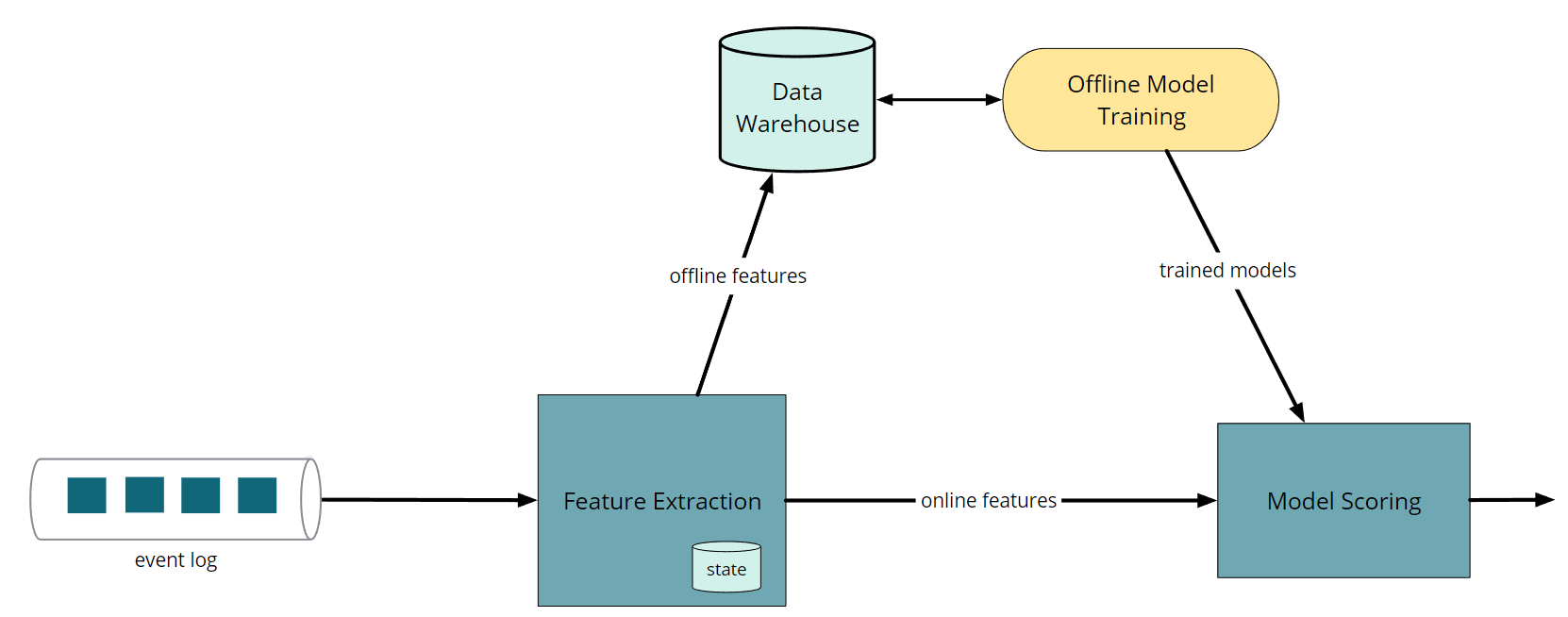
Flink 还经常用于将机器学习模型(例如分类器)应用于实时事件流的应用程序中。如上图,我们沿着横轴来看,实时流消息被接收、特征被计算、模型被用来做预测。同时,离线批处理过程会根据数据仓库中收集的数据定期重新训练模型。
常见应用场景
供应链管理
个性化推荐
异常检测、欺诈检测
时间响应
Flink项目简介
Flink是一个开源的流处理器
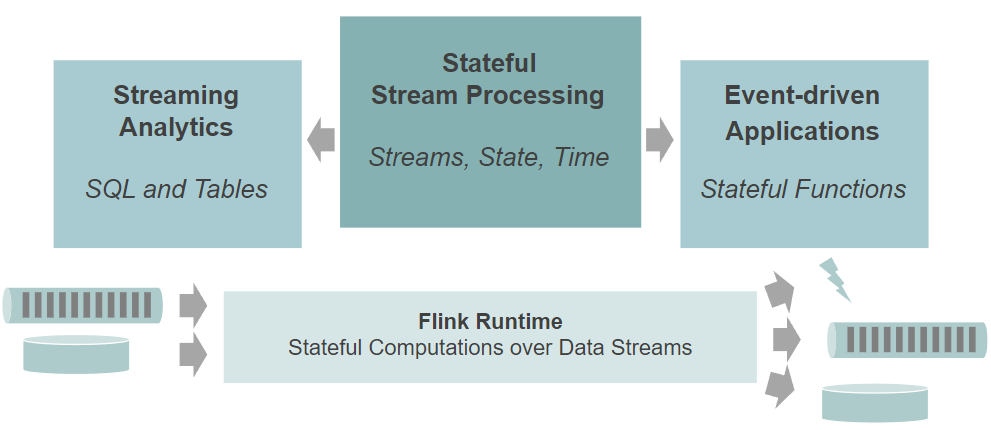
Flink的运行时(runtime)是分布式数据流的计算引擎,支持对数据流的有状态计算。
Flink不是流存储应用提供者。
Flink支持一系列输入、输出连接器(connectors)。连接器包括消息队列、文件系统、数据库。除了最通用的流应用,低阶的Data Stream API以外,针对2种常见应用场景,我们开发出专属API(高阶API):
- streaming analytics:Flink关系型API,Flink SQL/Table API
- event-driven applications:状态函数API
Flink核心概念
Streaming的基石
- 事件流(event streams)
- 实时、事后聪明
- 事件
- 考虑无序和晚到数据下的一致性
- 状态
- 复杂业务逻辑
- 快照
- 容错
- 版本管理
- 时点数据(time-travel)
上面是Flink的核心概念。掌握了上面这些核心概念,就会很容易理解当前的API设计。
一切皆流
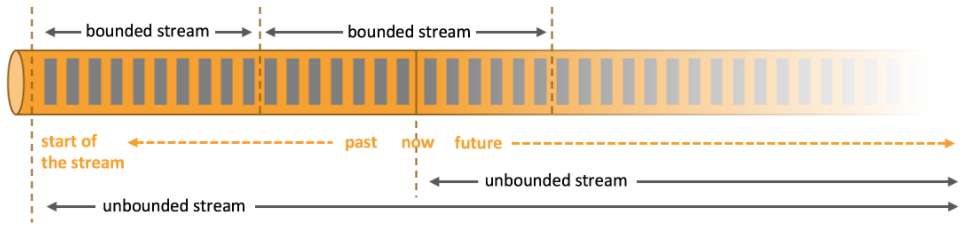
在Flink社区,一直有个说法,就是批是流的一种特殊形式。数据源本质上是无界的。我们将有限数据集看做是我们选择了一些原本无序的数据集进行分析。
查询和数据,哪一个变化更快?
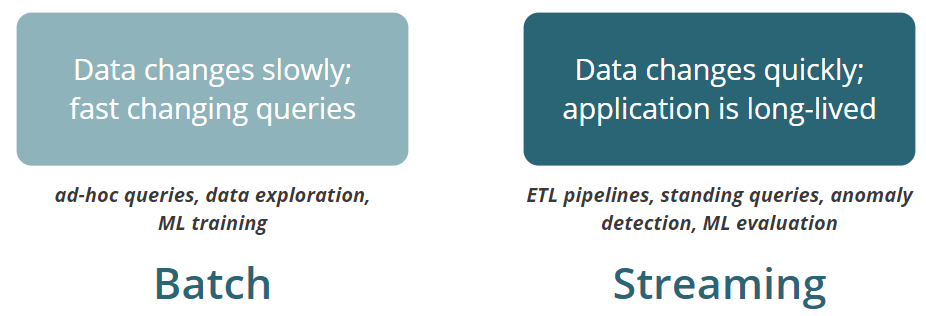
批(Batch)
- 快速扫描数月/数年的历史
- 使用大规模并行无序读取优化处理
- 吞吐量最重要
流(Streaming)
- 保持实时处理,并且具备流发生中断后能继续追赶上的能力
- 大致按生产顺序接收数据
- 延迟敏感
JobGraph
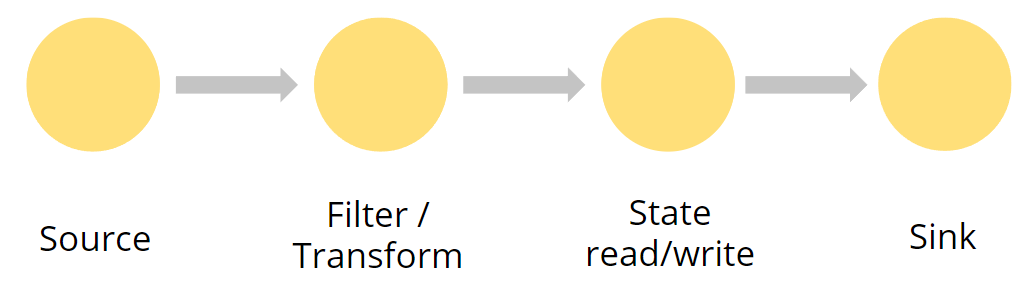
事件流在JobGraph的各个node间流动。
我们管这些图节点叫算子(operators)。一个运行的应用程序对应的节点集合就是一个JobGraph。
ExecutionGraph

这些 JobGraph 是并行运行的。我们来看下Job的Physical Graph或 ExecutionGraph。
Flink 对并行度提供了非常精细的控制,可以为整个Job设置,也可以为每个operator设置。
上图展示了这个Job中大部分operator都是2个并行度,但是sink是单线程的。
这个ExecutionGraph的第2层(filter)和第3层(read/write)算子是完全连接的。在这里,我们在worker之间执行一种完全连接的数据交换,有时称为network shuffle。数据会围绕着某种规则重新分区,分区后将同一个key的数据拉到同一个状态节点进行处理。例如,我们可能正在处理来自某移动端程序的事件流,我们可能会按用户 ID 对流进行分区或键控,以便我们可以在一个节点上收集有关每个用户的统计信息。
Event time vs. processing time
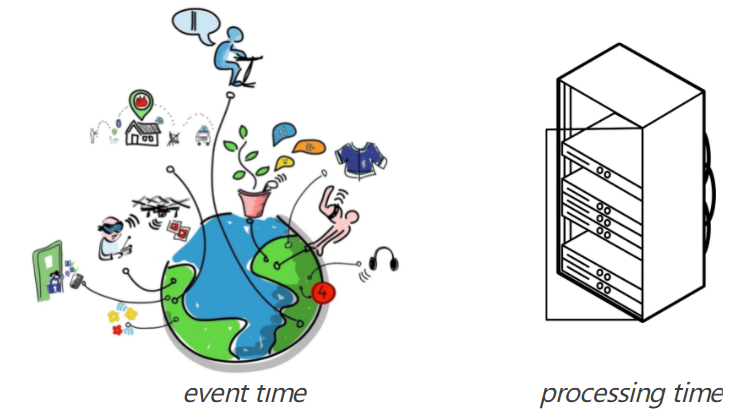
Flink 包含强大的 API 支持不同模式的时间管理(time management)。事件时间戳是由事件携带的,描述事件发生的时间,而处理处理时间描述事件被处理的时刻,一般相对是延后一点的,可能在数据中心处理。请注意,事件时间是事件的不可变特征,而处理时间是由处理事件的行为产生的非确定性、不可重现的副作用。如果重新处理一个事件,事件时间将相同,但处理时间不会!
(Stateful) stream processing
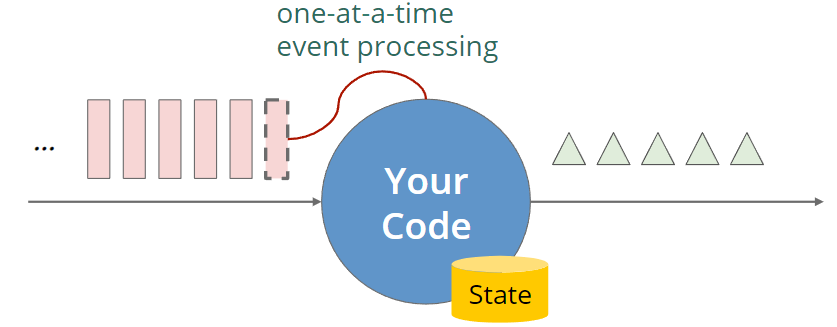
Flink 的一些算子,比如做过滤和转换的算子,希望你以用户函数的形式提供业务逻辑。其中一些用户函数是有状态的。整个流计算应用都是在处理每一个到来的事件。这也意味着有时候我们需要记录一些事件的信息,他可能会影响后面结果的产生。
Stateful streaming snapshots
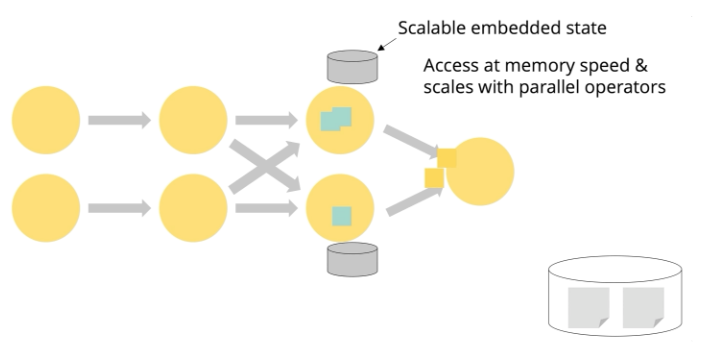
Flink是一个分布式系统,可以支持扩展到1000个节点,7*24运转。在这个规模上,发生局部故障是并不少见,所以必须有一个容错和恢复的解决方案。
每个key(e.g. user)的状态是存储到接收这个key对应的消息的node本地。你可以将此keyed state视为分片键值存储。这种设计对于 Flink 能够扩展到数千个节点并同时实现低延迟和高吞吐量的能力起着至关重要的作用。Flink 会定期扫描整个集群,并将所有这些checkpoints到一个持久的分布式文件系统。checkpoint工作会在后台完成,不会中断正在进行的流处理。
Recover by rolling back
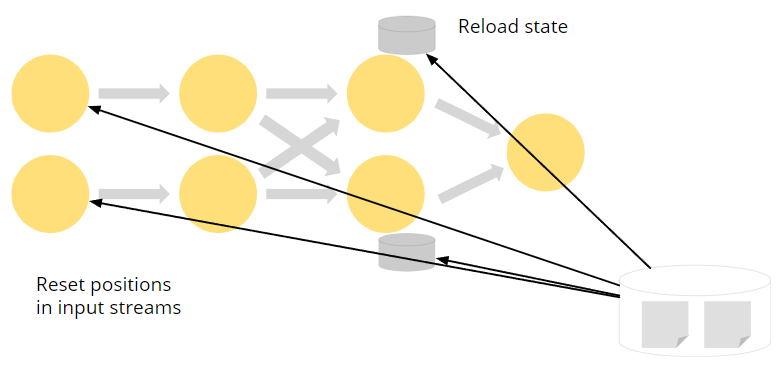
如果发生故障,Flink 通过从最近的checkpoints重新加载状态来恢复。同时,输入流被重置为与checkpoints对应的偏移量,并继续处理。这是整个集群的全局回滚。
举个例子:某视频网站
- 视频开始播放前,用户可能已经评论或点赞过了
- ML 模型需要导致播放事件的评价事件相关的信息
- 这种场景下的流式应用join需要事件时间和状态。
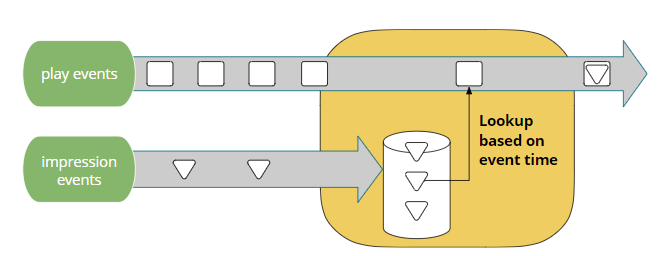
上述视频网站例子是一个综合了事件流、事件时间、状态等的实际应用场景。该场景希望能join播放事件流和在此之前的评价,而不是之后的评价。因此需要将每部电影的评价存储起来,以userId和movieId为索引,方便播放事件发生时来查找这些评价。同时,需要注意在关联使用时需关注两个事件流中的时间戳的处理方式。
传统分层架构和本地状态(local state)
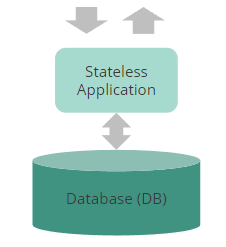
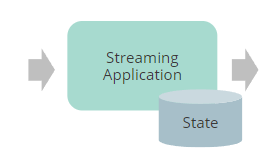
Flink 管理和扩展状态的方法与传统的应用系统中管理和扩展状态的差异:
- 可扩展性
- DB可能成为瓶颈,需要随着应用做扩展
- 计算和存储协同共存,并行扩展
- 性能
- 跨层边界读写
- 本地状态,加上大块的异步写入以实现持久性
- 操作简便
- 部署新服务时需要考虑管理另一个数据库
- 只需要额外的备份存储
- 一致性
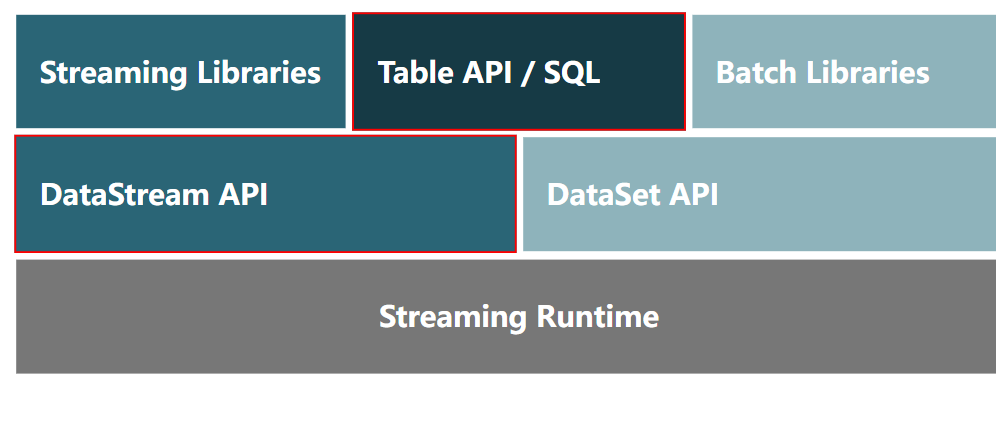
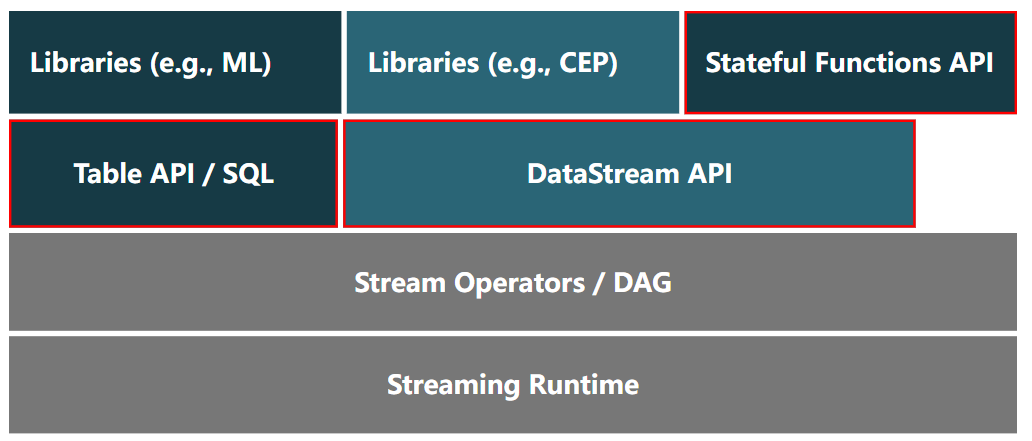
从用户的角度来看,DataStream 和 Table/SQL API 基本上与以前一样。并且它们都继续在系统中发挥相同的作用,即描述和生成数据流图。然而,关系 API 已经使用更强大、更低级别的抽象进行了重建,这使得实现更多优化成为可能。请注意,DataSet API 不再出现在此图中。最终,DataSet API 提供的所有操作和优化都将可用于使用 DataStream API 的有界流,并且 Flink 将不再需要单独的 API 来进行批处理。
在 Flink 1.11 中,两个 Table/SQL 运行时仍然可用,但此处描述的版本(“blink”规划器)现在是默认版本。一旦对有界流的支持完全与 DataSet API 一样强大,关系 API 的旧运行时将被删除。
至于 stateful functions API,这个 API 95% 左右的实现使用了 public DataStream API;它仅有限地使用内部操作。
如需深入了解 Flink 2.0 中批处理和流式处理的统一,请参阅 Aljoscha Krettek 在 Flink Forward Europe 2019 上的Towards Flink 2.0: Unified Batch&Stream Processing
DataStream API and execution
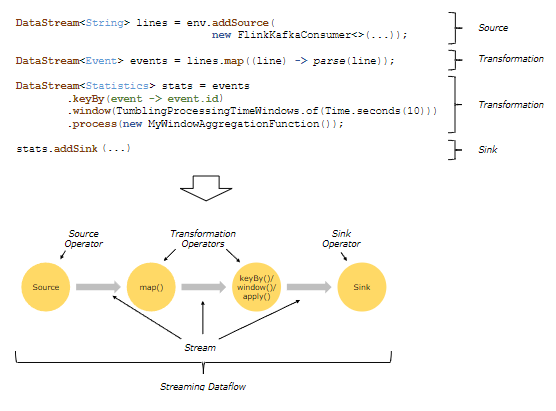
要点:当使用 DataStream API 时,编写的代码描述了一个流式数据流作业图dataflow job graph。当应用程序的 main() 方法运行时,它会构建 job graph,然后由 Flink 集群执行。上图说明了代码的不同部分如何描述处理Data Pipeline的不同阶段。
Apache Flink’s Relational APIs
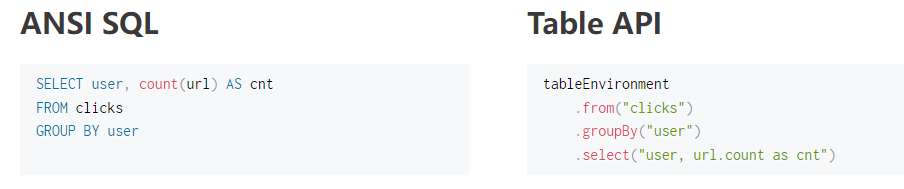
- 对批和流而言统一的API
对于一个查询而言,无论输入静态的批数据还是流数据,都产生一样的结果。
Flink’s Stateful Functions API
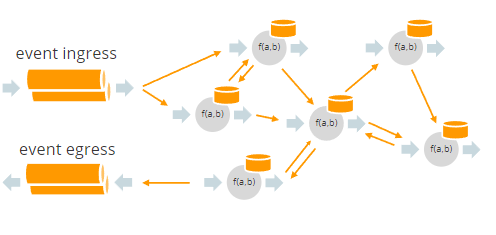
状态API使得构建分布式有状态应用变得容易很多。云原生
- 专为无服务器架构设计的运行时/内核
- 构建块:远程函数
- 表示实体的小块逻辑
- 多语言支持
- 可以用任何处理 HTTP 请求的语言来实现
- 动态消息
- 函数间随意通信
一致性状态,不需要数据库
容错的、精准一次的状态算子
- 实时和历史数据的基于事件时间的处理
- 高可扩展性和能快速处理的内核
- 各层次的API(表达能力与易用性)
- 丰富的连接器生态
- 灵活的部署模式
- 易于管理的有状态应用程序升级
- 高效运行批处理作业的能力

若有收获,就点个赞吧
0 人点赞
