Flink部署的基础组件
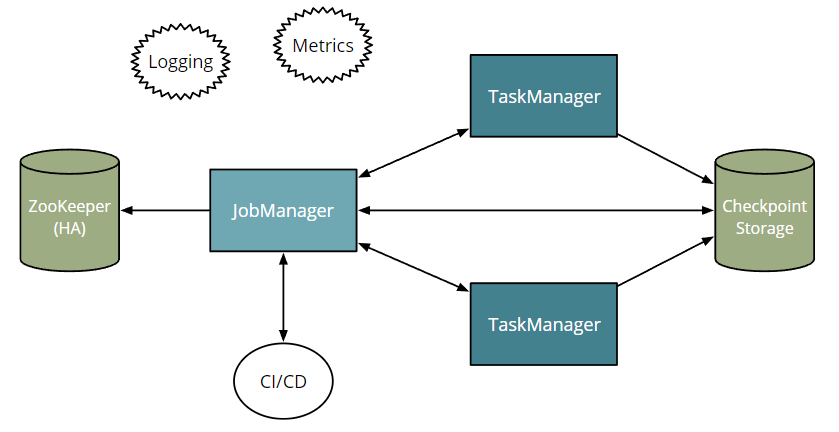
- JobManager
- 集群管理者
- TaskManagers
- worker进程(运行用户代码)
- 检查点存储
- 分布式文件系统,S3 or HDFS
- JobManager故障恢复
- Zookeeper
- JobManager存储checkpoint
- Ververica Platform 在 K8s 上实现 JobManager 故障转移,不需要 ZooKeeper
- Metrics, Logging, CI/CD
- 可选组件
- 用户可配置1个或多个MetricsReporters来连接到监控系统中,如
- Prometheus, JMX, Graphite, StatsD, etc.
- 有了logging and metrics,就可以做很多东西
Attention:所有数据流:即source、sink和流数据,在task manager之间进行数据交换。
Distributed runtime
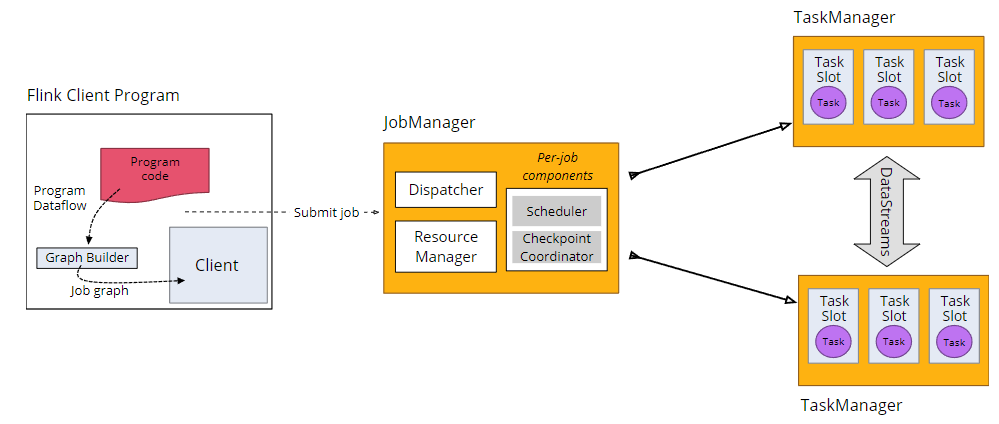
当应用的main()方法运行时,用户进行的API调用会在内存中构建一个数据流图,叫做 job graph。
在某些部署模式下(session模式和per-job模式),main() 方法在Flink外运行,在独立client进程中运行。在这些模式里,job graph和相关的用户代码被提交到Flink cluster执行。
application模式下,应用的main()方法在JobManager中执行,而不是在client或者是一些三方部署进程中。这种模式下,client或者其他部署进程不需要拉取和上传所有job的依赖包。
JobManager有许多内部组件。
- Dispatcher
- 集群的rest访问地址
- 从Clients接收job,为每个job启动各种per-job components
- scheduler
- 将 job graph分割成并行任务,并安排执行
- 从ResourceManager获取资源
- checkpoint coordinator
- 触发checkpoint
- 跟踪worker的心跳
- 根据需要重启
Task Managers
- 用户代码实际运行处
- Task Slot
- scheduling/调度的单元
- 为运行应用程序的一个并行切片提供资源
- 1个/多个core,一些内存
部署模式
- Mini cluster(开发/测试阶段,非生产)
- 单个JVM,包括client, job manager, and task managers
- 方便测试与在ide中调试
- Session cluster
- 长期运行集群,多个job
- 作业之间没有隔离(TaskManagers是共享)
- 非常适合运行短期作业(例如,ad-hoc即席查询)
- 一个不规范的作业可能导致整个集群崩溃,或者访问到集群中的某个存在的安全认证
- Job cluster
- 单个作业,集群与该作业同生周
- 非常适合连续运行作业
- Job cluster非常适合长期作业的容器化部署
- Application cluster(new in Flink 1.11)
- 仅从一个 Flink 应用程序执行job
- main() 运行在cluster,而不是client
- application jar和dependencies (including Flink itself) 可以被提前上传
- 可以部署Flink应用到yarn,像其他基于YARN的应用一样。
实际生产直接用Application模式即可,其他模式不用关注,慢慢会被替代掉。直接对标spark on yarn即可。
yarn模式下。
DataStream API and execution
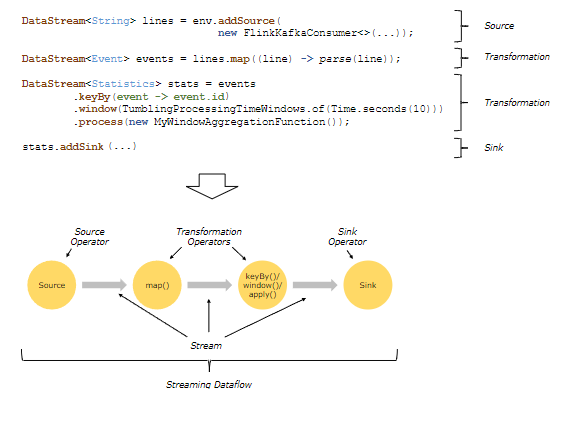
The JobGraph(逻辑图)
The ExecutionGraph(物理图)
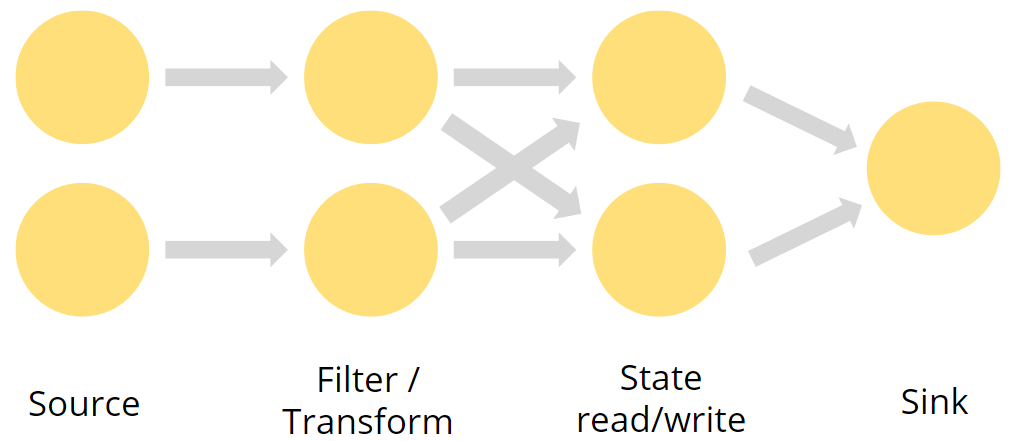
事件保持他们的相对顺序
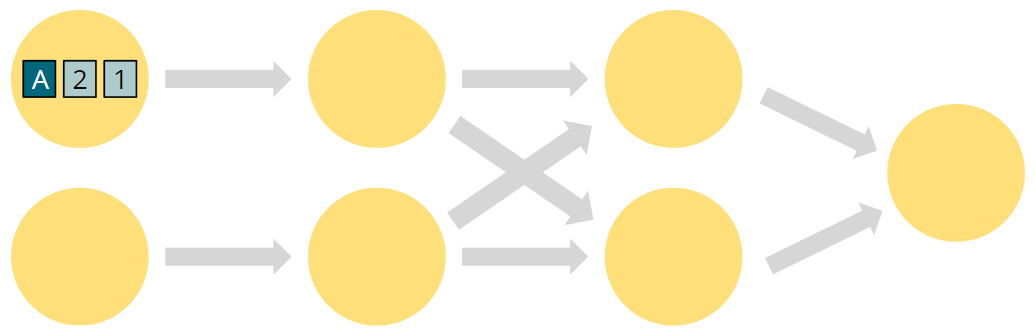
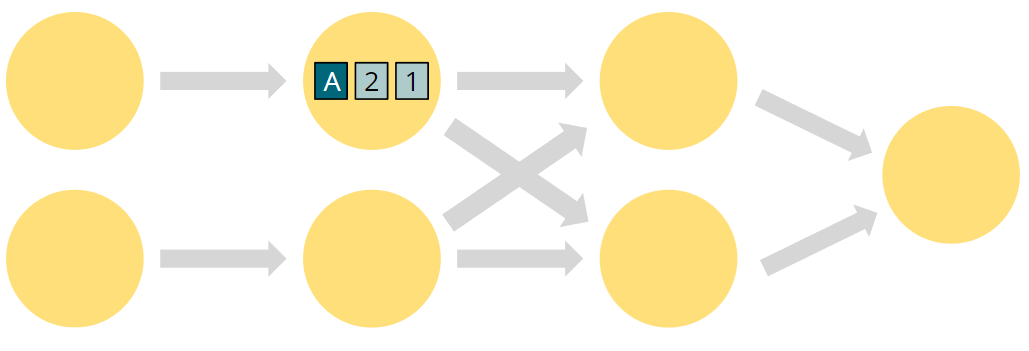

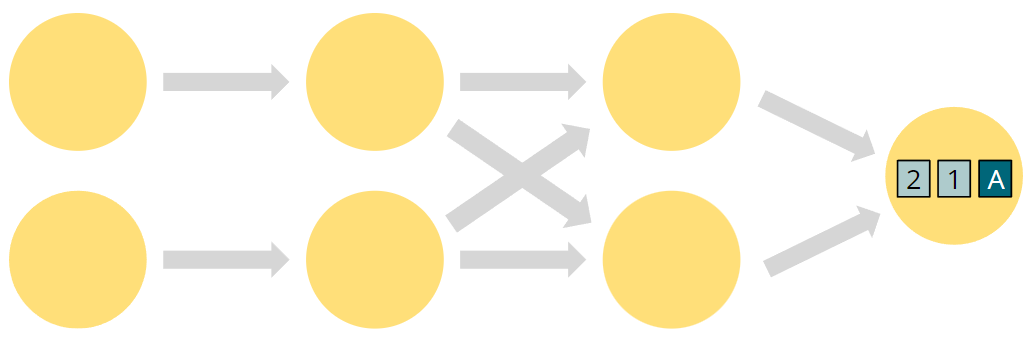
注意观察A和(1,2)经过了不同的路径,发生了什么?原先的顺序是A21,现在是21A。同一个partition的顺序是一直保持的。
数据交换的策略
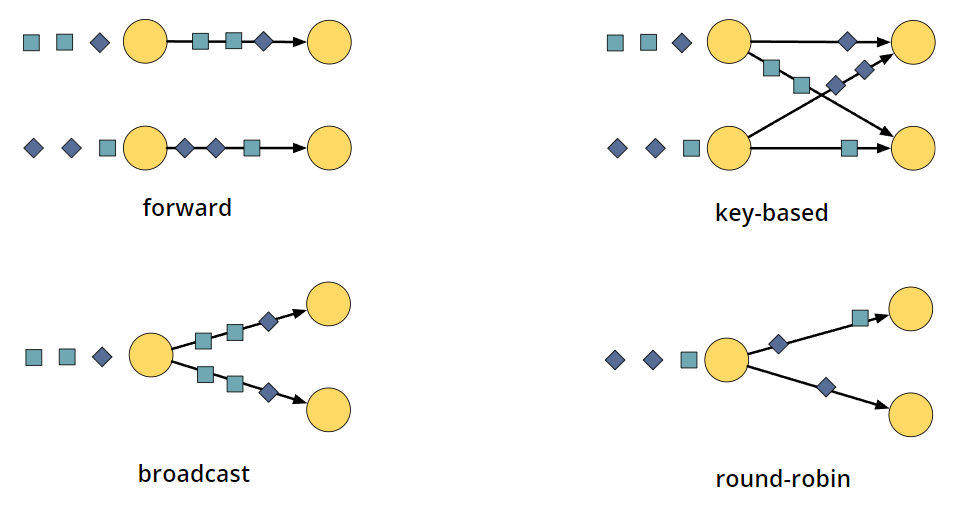
- Forward
- 当前的partition保持不变,每个记录还在原来的并行分支上
- Key-based
- 记录按照某个key来进行分区,key是根据某种业务逻辑或算法来计算出来的
- 同一个key一定被分到同一个partition
- Broadcast
- 每个partition都得到全部
- Round-robin
- 当前记录会被轮流发送到下一个算子的各个partition
- 在进行重新平衡以影响并行度的变化时使用
Job components and operator chaining
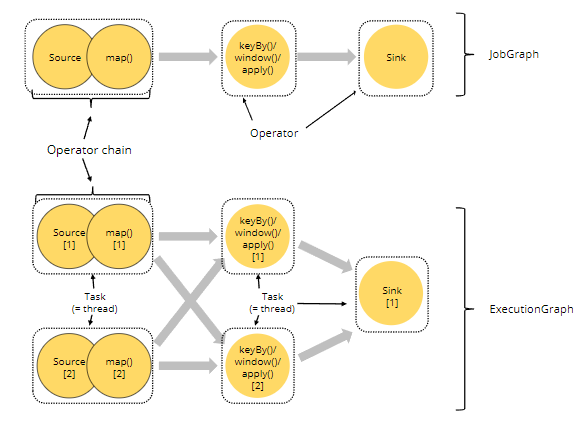
Chaining
- 记录从一个用户定义的函数传递到另一个,而不涉及 Flink 的任何较低层转换(de/ser,网络堆栈)
- 增加吞吐量,不涉及序列化及网络传输转换
- 仅仅适用于forward类型数据传输
- chaining也可以被禁用。通常我们只在调试的时候采取禁用策略,比如我们在2个算子间强制通过网络传输,为了看清两个算子之间的通信。
- 一个算子链中的一个并行实例叫做task(某些地方也叫subtask)
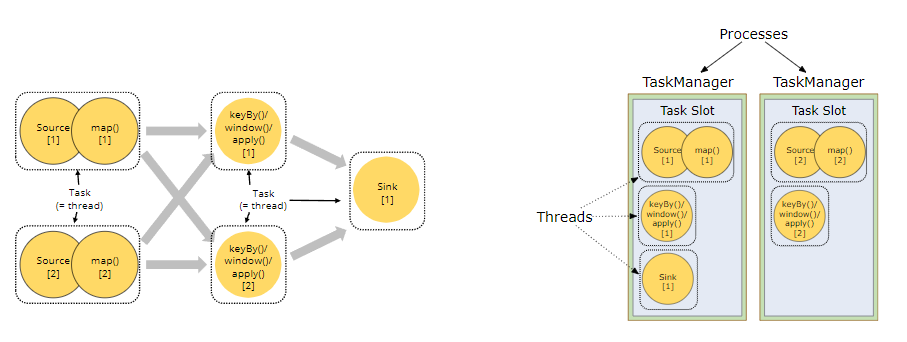
- 上图示例的作业中除了sink外,其他算子的并行度都是2。
- 每个task manager中包含一个task slot。每个task slot会被分配2-3个task去执行。
- 每个task对应java的一个线程
- 每个task slot的2-3个task共享这个slot的资源
- task slot只是用于调度的抽象(逻辑概念):它们不对应于任何物理含义。
- Task Manager刚好拥有的所有资源都被该 TM 中运行的task slot使用。

若有收获,就点个赞吧
0 人点赞
