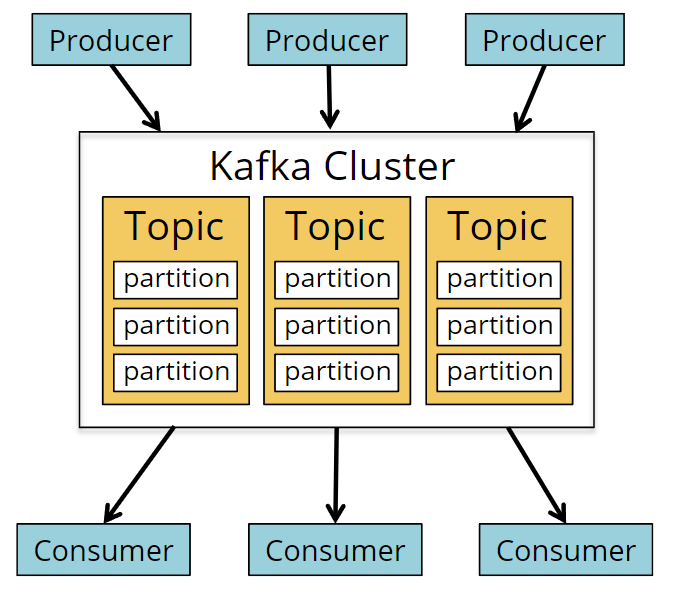
Kafka 概览
kafka分区
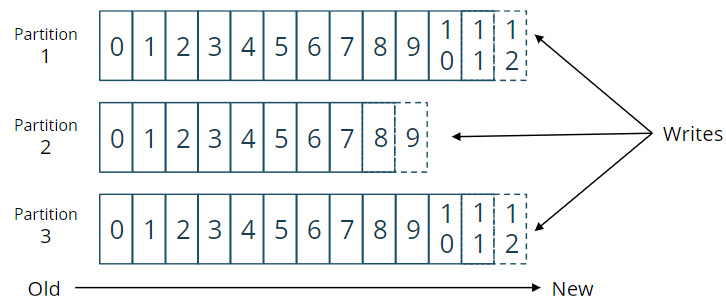
kafka偏移量
- Kafka 补偿是指消费者在特定分区中的当前位置
- 通常,当Kafka客户端在出现故障后不再希望重新使用该数据时,它们会提交其偏移量
- Flink的Kafka消费者将其偏移量作为检查点的一部分提交回Kafka,但不使用这些偏移量进行恢复。
Flink快照包括每个源的偏移量,以及从输入流读取到该点所导致的整个作业图的状态。在恢复期间,输入回滚到这些偏移量,作业状态回滚到快照中记录的状态。
如果禁用检查点,则根据Kafka自动提交间隔将偏移量提交给Kafka。
Flink的KafkaSource连接器
- 此连接器的每个子任务从一个或多个分区读取
- 分区的数量限制了最大的并行性
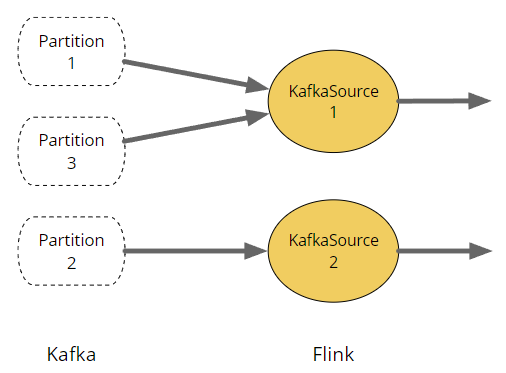
分区以循环方式分配给子任务(这就是子任务1显示为连接到分区1和3的原因)。它以这种方式实现,以使分区发现更加简单。
使用KafkaSource读取Kafka
final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers(...).setGroupId(...).setTopics(...).setDeserializer(...) // or setValueOnlyDeserializer.setStartingOffsets(...).setBounded(...) // or setUnbounded.build();env.fromSource(source, WatermarkStrategy.forMonotonousTimestamps(), "Kafka Source"));
这是取代Flink KafkaConsumer的新Kafka源。
它可用于批处理或流处理。
其中许多属性是可选的,但您必须指定服务器、主题和反序列化程序。支持通配符主题(用于主题发现)。
SetBound(…)和setUnbound(…)控制源是以Boundedness.CONTINUOUS_UNBOUNDED(默认设置)还是Boundedness.BOUNDED运行。
这里,setBound用于指示源在使用完最新偏移量之前的所有数据后应该停止。
SetUnbound可以用来指示虽然源不应该读取超过指定偏移量的任何数据,但它应该保持运行。例如,如果以流模式运行,这将允许源参与检查点设置。
设置反序列化程序
示例:JSON到POJO
public class EventDeserializationSchema extends AbstractDeserializationSchema<Event> {private transient ObjectMapper objectMapper;@Overridepublic void open(InitializationContext context) throws Exception {super.open(context);objectMapper = JsonMapper.builder().build();}@Overridepublic Event deserialize(byte[] message) throws IOException {return objectMapper.readValue(message, Event.class);}}
在只需要Kafka消费者记录的值的情况下,可以使用仅限值的反序列化程序—如本例所示。这意味着向反序列化方法传递的是一个字节数组,而不是ConsumerRecord。
要为特定类型编写反序列化模式,扩展 AbstractDeserializationSchema 并在类签名中声明类型就足够了。Flink 将反射性地确定类型并创建适当的 TypeInformation。
如果你想创建一个适用于不同类型的更通用的 DeserializationSchema,你需要将 TypeInformation (或者一个等价的提示)传递给构造函数:
public class MyGenericSchema<T> extends AbstractDeserializationSchema<T> {public MyGenericSchema(Class<T> type) {super(type);}...}
反序列化模式
- SimpleStringSchema
- returns the payload as a String
- DeserializationSchema
- can create app-specific objects from a byte[]
- KafkaDeserializationSchema
- can create app-specific objects from a Kafka ConsumerRecord
- JSONKeyValueDeserializationSchema
- uses an ObjectMapper to produce Jackson ObjectNode instances
- TypeInformationSerializationSchema
- deserializes with a schema based on a Flink’s TypeInformation
- AvroDeserializationSchema
- can infer the schema from Avro generated classes
- can also work with GenericRecord instances
- ConfluentRegistryAvroDeserializationSchema
- fetches the schema from the schema registry
这些是内置的反序列化程序,可以与Kafka一起使用。
SimpleStringSchema:使用它,然后使用map操作符将字符串解析为对象,这是一种常见的反模式。最好是实现一个适当的反序列化程序。
曾经有一个JSONDisializationSchema;在Flink 1.8中删除了它。如果您使用的是JSON,并且不能使用JSONKeyValueDisializationSchema,那么可以使用asiializationSchema
TypeInformationSerializationSchema是特定于Flink的选项。如果您既要通过Flink向Kafka写入内容,也要从Kafka中读取内容,这是更通用选项的最佳替代方案。
使用 Confluent 模式注册表
- 格式看起来是这样 | Bytes | Content | | —- | —- | | 0 | Magic Byte | | 1-4 | Schema ID | | 5-… | Data |
这样的错误表明反序列化器并不期望Magic Byte。
Protocol message contained an invalid tag (zero)
在 Confluent Schema Registry 中使用 Avro 时,Flink 提供序列化和反序列化,但是在协议缓存中不提供。
KafkaSource 如何找到它的起始位置
- 如果从检查点或保存点重新启动,那么它将使用存储在快照中的偏移量
- 否则,将使用指定的起始偏移量(如果有的话)
- .setStartingOffsets(OffsetsInitializer.earliest())
- 默认
- setStartingOffsets(OffsetsInitializer.latest())
- setStartingOffsets(OffsetsInitializer.committedOffsets())
- 如果没有找到提交的偏移量,则抛出异常,除非指定 OffsetResetStrategy
- setStartingOffsets(OffsetsInitializer.offsets(…))
- 如果找不到指定的偏移量,请使用指定的 OffsetResetStrategy 或回退到最早的
- setStartingOffsets(OffsetsInitializer.timestamp(…))
- 如果找不到,退回到最新的补偿
- .setStartingOffsets(OffsetsInitializer.earliest())
- 否则,它使用最早的偏移量
注意: consumer 属性 auto.offset.reset 被 OffsetResetStrategy 覆盖(如果存在)
下面是一个仅读取2021年10月的数据的示例:
.setStartingOffsets(OffsetsInitializer.timestamp(Instant.parse("2021-10-01T00:00:00.000Z").toEpochMilli())).setBounded(OffsetsInitializer.timestamp(Instant.parse("2021-10-31T23:59:59.999Z").toEpochMilli()))
用KafkaSink写入Kafka
KafkaSink<T> sink =KafkaSink.<T>builder().setBootstrapServers(...).setKafkaProducerConfig(...).setRecordSerializer(...).setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE).setTransactionalIdPrefix("unique-id-for-your-app").build();stream.sinkTo(sink);
注意: 对于精准一次,必须在运行于相同 Kafka 集群的所有应用程序中提供唯一的 TransactionalIdPrefix。
您可以直接通过 KafkaRecordSerializationSchema 提供序列化器,也可以使用覆盖大多数常见情况的 KafkaRecordSerializationSchemaBuilder。
Kafka事务
为了实现精准一次性的端到端保证:
- Flink job作业内部
- Enable Flink checkpointing
- Enable Job Manager HA
- Set DeliveryGuarantee.EXACTLY_ONCE
- Set a transational id prefix
- Kafka层面
- 考虑在其默认值之外增大Transaction.Max.timeout.ms和Transaction.timeout.ms
- 将下游使用者中的 isolation.level 设置为read_committed、
如果 Kafka 事务确实超时了,Flink 就没有办法可靠地知道已经发生了这种情况,而且涉及的数据将会丢失。
使用READ_COMMITTED,下游Kafka 消费者将体验到与检查点间隔相当的延迟
为了增大事务超时,你需要改变代理中的 transaction.max.timeout.ms (默认值为15分钟)和生产者中的 transaction.timeout.ms (默认值为1小时)。
因此,请考虑增大这些超时时间,以应对任何可能的停机——比如,多个小时,甚至可能数天。
然而,设置较长的事务超时间隔有一个缺点:当您有多个作业向同一主题生成消息时,如果另一个作业的较早事务处于停滞状态(正在等待事务超时),则当前作业的提交消息对该主题的消费者是不可见的。
这是一个复杂的话题。详情请看 Best Practices for Using Kafka Sources/Sinks in Flink Jobs
SQL/Table API 的 Kafka 连接器
- Flink SQL和Table API提供了一种简单的方式来读取和写入Kafka,并内置了对许多流行格式(CSV、JSON、Avro、Debezium等)的支持。
- Kafka记录的(可选)键和值部分都可以读写。
- 使用kafka事务,支持精准一次
- 可以读写更新日志流(使用 upsert-kafka 连接器)
- 同时支持
- 主题和分区发现
- 每分区水印
- 不同的启动模式(用于指定启动偏移量)
即使您没有以其他方式使用关系API,您也可能会发现使用这些SQL连接器很方便。
参考文章

若有收获,就点个赞吧
0 人点赞
