统一运维监控平台设计思路
构建一个智能的运维监控平台,必须以运行监控和故障报警这两个方面为重点,将所有业务系统中所涉及的网络资源、硬件资源、软件资源、数据库资源等纳入统一的运维监控平台中,并通过消除管理软件的差别,数据采集手段的差别,对各种不同的数据来源实现统一I管理、统一规范、统一处理、统一展现、统一用户登录、统一权限控制,最终实现运维规范化、自动化、智能化的大运维管理。
智能的运维监控平台,设计架构从低到高可以分为6层,三大模块,如下图: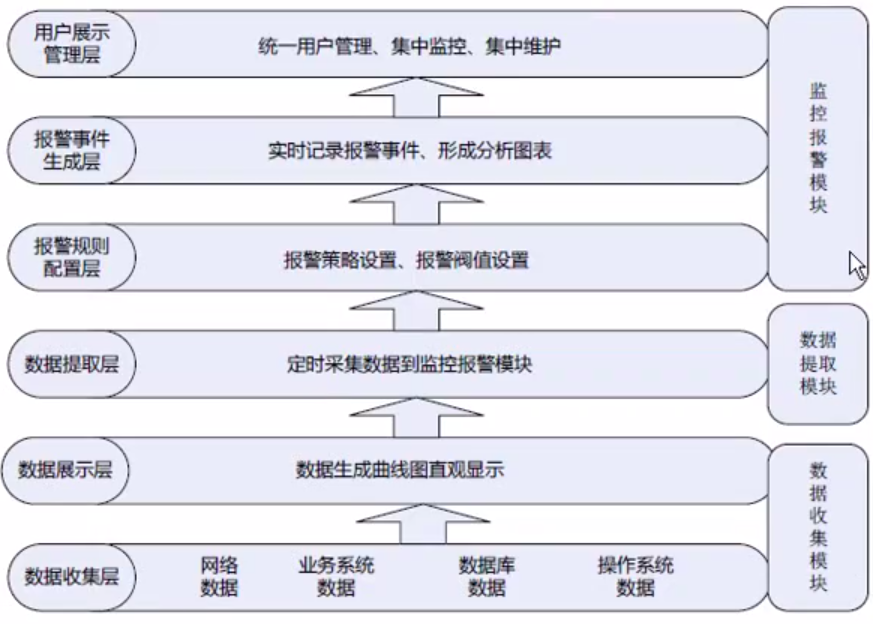
运维监控平台实现拓扑图,请看下图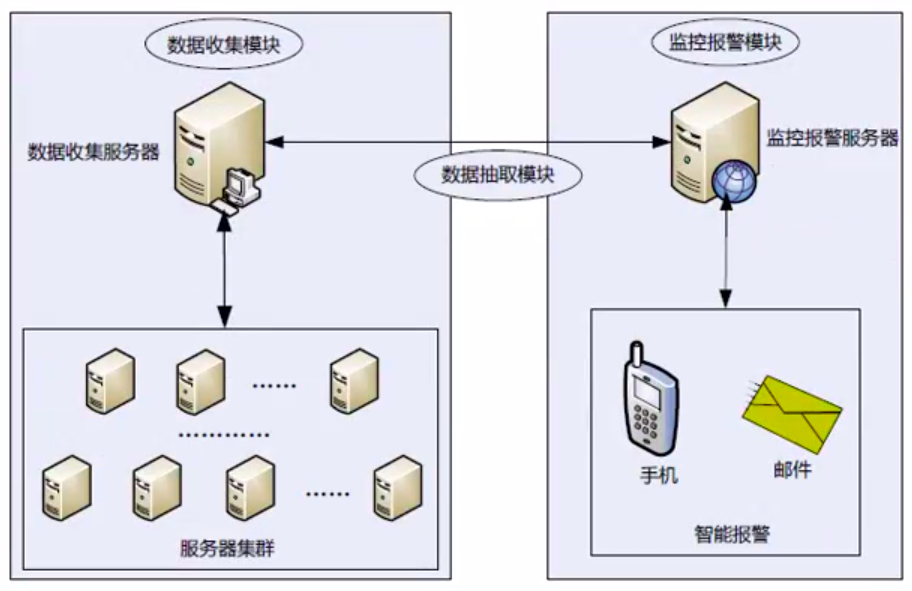
Ganglia安装
1、gnaglia的常用架构
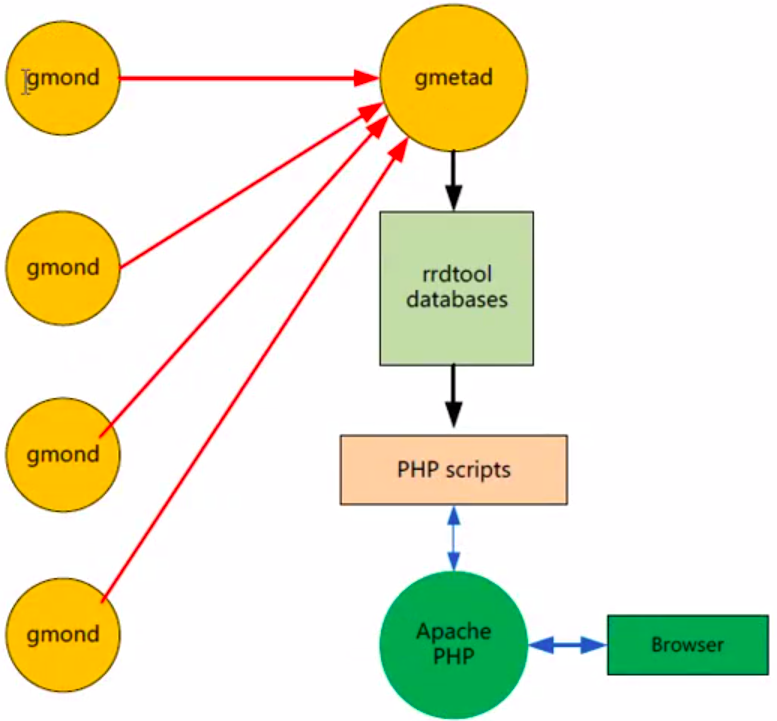
ganlia监控系统有三部分组成,分别是gmod、gnetad、、webforonted如下图所示:
同时,Ganglia支持多种监控架构,这是由gmetad的特性决定的,gmetad可以周期性地去多个gmond节点收集数据,这就是ganglia的两层架构。同时,gmetad不但可以从gmond
收集数据,也可以从其他的gmetad得到数据, 这就形成了Gnaglia的三层架构。多种架构
方式也体现了Ganglia作为分布式监控系统的灵活性和扩展性。
同时,Ganglia支持多种监控架构,这是由gmetad的特性决定的,gmetad可以周期性地去多个gmond节点收集据,这就是ganglia的两层架构。同时,gmetad不但可以从gmond收集数据,也可以从其他的gmetad得到数据, 这就形成了Gnaglia的三层架构。多种架构方式也体现了Ganglia作为分布式监控系统的灵活性和扩展性。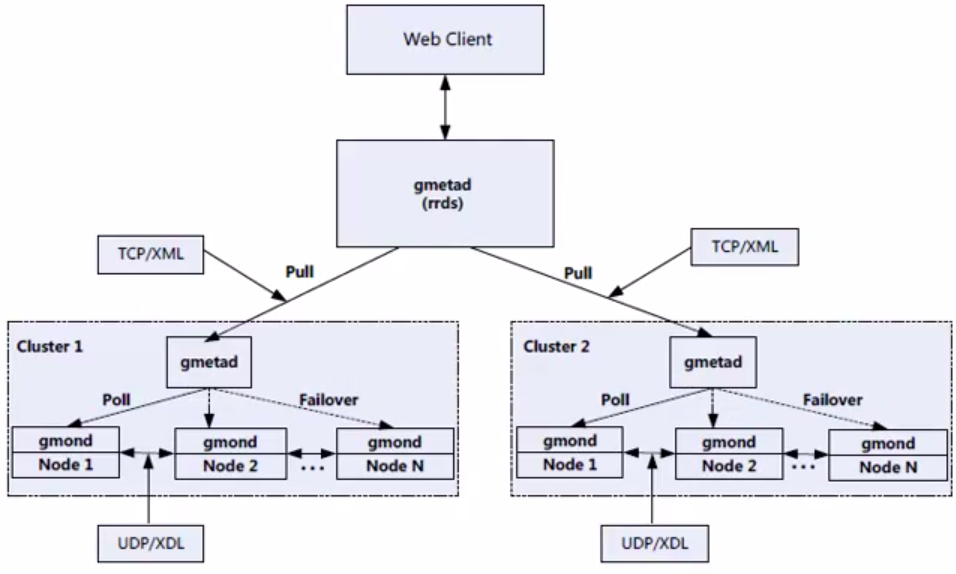
分布式架构流向图
2、yum安装ganglia
CentOS系统中默认的yum源并没有包含Ganglia,所以我们必须安装扩展的yum源。从下面这个地址下载Linux附加软件包(EPEL),然后安装扩展yum源:
[root@node1~]#wget http://dl.fedoraproject.org/pub/epel,/5/i386/epel-release-5-4.noarch.rpm [root@node1~]#rpm Jivhepel-release-5- 4.noarch.rpm
完成yum源安装,就可以直接通过yum方式安装Ganglia了。
Ganglia的安装分为两个部分,分别是gmetad和gmond,gmetad安装在监控管理端,
gmond安装在需要监控的客户端主机,对应的yum包名称分别为ganglia-gmetad和
ganglia-gmond。
下面介绍通过yum方式安装Ganglia的过程。
以下操作是在监控管理端进行的,首先通过yum命令查看下可用的Ganglia安装信息:
[root@monitor ~]#yum list ganglia*
安装gmetad需要rrdtool的支持,而通过yum方式,会自动查找gmetad依赖的安装包,
自动完成安装,这也是yum方式安装的优势。
最后在需要监控的所有客户端主机上安装gmond服务:
[root@node1~]#yum-yinstall ganglia- gmond.x86_64
这样,Ganglia监控系统就安装完成了。通过yum方式安装的Ganglia默认配置文件位
于/etc/ganglia中。
3、Gannglia 监控管理端配置
监控管理端的配置文件是gmetad.conf,这个配置文件内容比较多,但是需要修改的配 置仅有如下几个:
data_source”Cluster1”cloud0cloud2
gridname”IIVEYGrid”
xml_port8651
interactive_port 8652
rrd_rootdir”/var/lib/ganglia/rrds”
data_source:此参数定义了集群名字, 以及集群中的节点。Cluster1就是这个集群的名称,cloud0和cloud2指明了从这两个节点收集数据,Custer1后面指定的节点名可以是IP地址,也可以是主机名,由于采用了multicast模式,每个gmond节点都有本Cluster1集群节点所有监控数据,因此不需要把所有节点都写入data_source中。但是建议写入不低于2个,这样,在cloudo节点出现故障的时候,gmetad会自动到cloud2节点采集数据,这样就保证了Ganglia监控系统的高可用性。
上面通过data_source参数定义了一个服务器集群Quster1,对于要监控多个应用系统的情况,还可以对不同用途的主机进行分组,定义多个服务器集群,分组方式可以通过下面的方法定义:
data_source”my cluster” 10localhost my.machine.edu:8649 1.2.3.5:8655
data_source “my grid” 50 1.3.4.7:8655 grid.org:8651 grid-backup.org:8651
data_source”another source”1.3.4.7:8655 1.3.4.8
可以通过定义多个data_source来实现监控多个服务器集群,而每个服务器集群在定义集群节点的时候,可以采用主机名或IP地址等形式,也可以加端口,如果不加端口,默认端口是8649,同时可以设定采集数据的频率,如上面的“10localhost、501.3.4.7:8655”等,分别表示每隔10秒钟、50秒钟采集一次数据。
gridname:此参数是定义一个网格名称。一个网格有多个服务器集群组成,每个服务器集群由“data_source”选项来定义。
xml_port:此参数定义了一个收集数据汇总的交互端口,如果不指定,默认是8651,可以通过telnet这个端口得到监控管理端收集到的客户端的所有数据。
interactive_port:此参数定义了Web端获取数据的端口,这个端口在配置Ganglia的Web监控界面时需要指定。
rrd_rootdir: 此参数定义了rd数据库的存放路径,gmetad在收集到监控数据后会将其更新到该目录下的对应的rrd据库中。
4、Ganglia的客户端配置
Ganglia监控客户端gmond安装完成后,配置文件位于Ganglia安装路径的etc目录下,名称为gmond.conf,这个配置文件稍微复杂,如下所示:
globals{daemonize=yes #是否后台运行,这里表示以后台的方式运行setuid =yes #是否设置运行用户,在Windows中需要设置为falseuser = nobody #设置运行的用户名称,必须是操作系统已经存在的用户,默认是nobodydebug_level=0 #调试级别,默认是0, 表示不输出任何日志,数字越大表示输出的日志越多max_udp_msg_len=1472mute=no #是否发送监控数据到其他节点,no表示本节点将不再广播任何自己收集到的数据到络上deaf=no #是否接受其他节点发送过来的监控数据,no表示本节点将不再接收其他节点广播的数据包allow_extra_data=yes #是否发送扩展数据host_dmax =0/*secs */ #是否删除一个节点,0代表永远不删除,0之外的整数代表节点的不响应时间,超过这个时间后,Ganglia就会刷新集群节点信息进而删除此节点cleanup_threshold = 300 / *secs */ #gmond清理过期数据的时间gexec=no #是否使用gexec来告知主机是否可用,这里不启用send_metadata_interval=0 #在单播协议中,新添加的节点在多长时间内响应一 下以表示自己的存在,0代表仅在gmond启动时通知一次,单位秒}cluster{name ="Cluster1" #集群的名称,是区分此节点属于某个集群的标志,必须和监控服务端data_source中的某一项名称匹配owner="junfeng" #节点的拥有者,也就是节点的管理员latlong="unspecified" #节点的坐标,经度、 纬度等,一般无需指定url = "unspecified" #节点的URL地址,一般无需指定}host{location="unspecified" #节点的物理位置, 一般无需指定}udp_send_channel{ #udp包的发送通道mcast_join = 239.2.11.71 #指定发送的多播地址,其中239.2.11.71是一个D类地址。如果使用单播模式,则要写host=host1,在单播模式下也可以配置多个udp_send_channelport=8649 #监听端口ttl=1}udp_recv_channel{ #接收udp包配置mcast_join=239.2.11.71 #指定接收的多播地址,同样也是239.2.11.71这个D类地址port=8649 #监听端口bind=239.2.171 #绑定地址}tcp_accept_channel{port=8649 #通过tcp协议监听的端口,在远端可以通过连接到8649端口得到监控数据}在一个集群内,所有客户端的配置是一样的。完成一一个客户端配置后,将配置文件复制到此集群内的所有客户端主机上即可完成客户端主机的配置。
5、Ganglia web端配置
Ganglia的web监控界面是基于PHP的,因此需要安装PHP环境。有两种方式安装Ganglia的web监控界面,一种是yum直接安装,另一种是通过源码安装。PHP环境的安装这里不做介绍,大家可以http://sourceforge.net/projects/ganglia/files/下载ganglia-web的最新版本,然后将ganglia-web程序放到Apche Web的根目录即可,这里我们下载的版本是ganglia-web-3.7.1。
配置Ganglia的Web界面比较简单,只需要修改几个php文件即可。首先是confdefault.php,可以将conf_default.php重命名为conf.php,也可以保持不变, Ganglia的Web默认先找conf.php,找不到会继续找conf default.php,需要修改的内容如下:
$conf[“gwebconfdir]= “/var/www/htm//ganglia”; #gangliaweb的根目录
Sconf[“gmetad_root”] = “/opt/app/ganglia”;# ganglia程序安装目录
Sconf[“rrds”] = “S{conf[“gmetad_root”]}/rrds”; #ganglia web读取rrd数据库的路径,这里是/opt/app/ganglia/rrds
Sconf[“dwoo_compiled_dir”] = “S{conf[“gweb confdir”]}/dwoo/compiled”; #需要“777”权限
Sconf[“dwoocache_dir”] = “S{conf[“gweb confdir”]}/dwoo/cache”;#需要“777”权限
Sconf[“rrdtool”] = “/opt/rrdtool/bin/rrdtool”; #指定rrdtool的路径
Sconf[“graphdir”]=Sconf[“gwebroot]. “/graph.d”; #生成图形模板目录
Sconf[“ganglia_ip”] =”127.0.0.1”; #gmetad服务所在服务器的地址
Sconf[“ganglia_port”] =8652; #gmetad服务器的交互式提供监控数据端口发布
这里需要说明的是:“Sconf[“dwoo_compiled dir]”和“Sconf[“dwoo_cache_di门”指定的路径在默认情况下可能不存在,因此需要手动建立compiled和cache目录,并授予Linux下“777”的权限。另外,rrd数据库的存储目录/opt/app/ganglia/rrds一定要保证rrdtool可写,因此需要执行授权命令:
Chown -R nobody:nobody /opt/app/ganglia/rrds
这样 rrdtool 才能正常读取rrd数据库,进而将数据通过 Web 界面展示出来。其实ganglia-web的配置还是比较单的, 一旦配置出错会给出提示,根据错误提示进行问题排查,一般都能找到解决方法。
扩展Ganglia监控功能
1、通过gmetric接口扩展Ganglia监控
1、通过gmetric接口扩展Ganglia监控gmetric是Ganglia的一个命令行工具它可以将数据直接发送到负责收集数据的gmond节点,或者广播给所有gmond节点。
在Ganglia安装完成后,会在bin目录下生成gmetric命令。下面通过一个实例介绍一下
gmetric的使用方法:
[root@cloud1~]#/opt/app/ganglia/bin/gmetric > -n disk_used -v 40-t int32 -u ’% test‘-d 50 -S ‘8.8.8:cloud1‘
其中:
-n,表示要监控的指标名。
-v,表示写入的监控指标值。
-t,表示写入监控数据的类型。
-u,表示监控数据的单位。
-d,表示监控指标的存活时间。
-c,用于指定ganglia配置文件的位置。
-s,表示伪装客户端信息,8.8.8.8代表伪装的客户端地址,doud1代表被监控主机的主机名。
2、python扩展插件现成可用扩展插件:
https://github.com/ganglia/gmond_python_modules
Ganglia的优势与注意事项
1、可以轻松监控上万台服务器,数据延时在10s以内。
2、分布式架构,扩展方面,非常适合多地跨机房部署。
3、与centrenon无缝整合,实现监控、报警一体化。
4、数据存储磁盘10可能成为瓶颈,需要高性能磁盘做支撑。
Centreon 的结构
一个典型的Centreon监控系统- 一般有四大部分组成,分别是nagios、centstorage、T
centcore和ndoutils,简单介绍如下:
- nagios是Centreon的底层监控引擎,主要完成监控报警系统所需的各项功能,是Centreon监控系统的核心。另外, Centreon还支持Centreon Engine、 lcinga等监控引擎。本章采用nagios监控引擎进行介绍。
- centstorage是一个数据存储模块,它主要用于将日志数据及RRDtool生成的数据存储到数据库中,以供用户查询日志数据并快速生成曲线图,更主要的是nagios可以随时通过查看数据库中的记录更新监控状态。
- centoore主要用于centreon的分布式监控系统中,在系统中centcore是一个基于perl的守护进程, 主要负责中心服务器(central server)和扩展节点(pollers)间的通信和数据同步等操作,例如centcore可以在中心服务器上执行对远程扩展节点上nagios服务的启动、关闭和重启操作,还可以运行、更新扩展节点上nagios的配置文件。
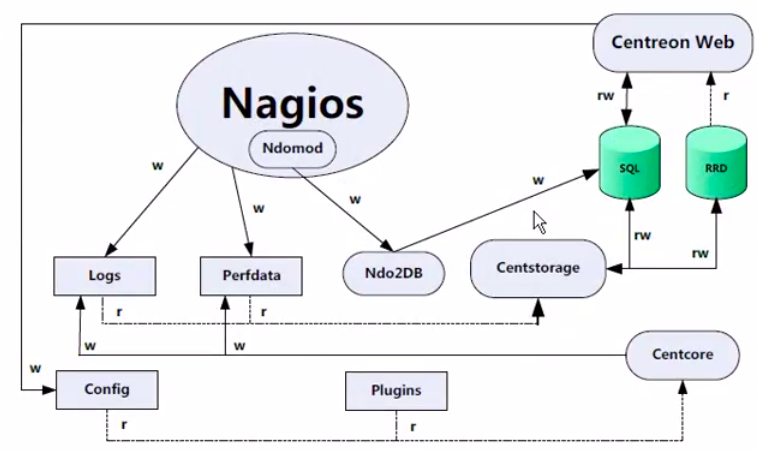
上图主要展示了Centreon每个组成部分是如何工作的,在组织结构上,一 般情况下,Centreon WebCentrstorage、Centcore和Ndo2DB 位于中心服务器上,而Nagios和Ndomod可以位于一台独立的扩展节点(pollers) 上,也可以位于中心服务器上。在分布式监控环境中,Nagios和Ndomod都位于远程的一个扩展节点上。
为了能使大家快速了解Centreon的内部工作原理,我们将图分为三条线来介绍,
- 第一条线:Centreon Web—->Centcore—>Centstorage—>db—> Centreon Web, Centreon Web就是Centreon的Web配置管理界面, 在Web配置管理界面中配置好主机和服务后,会生成相应的配置文件,然后Centcore会去读取这些配置文件并结合相关Nagios插件将数据发送到Nagios监控引擎,并生成相关日志文件和rds文件,而Centstorage模块会及时收集这些日志信息及rrds数据并最终将这些数据存入数据库中,以供CentreonWeb展示调用。
- 接着是第二条线:Nagios—> Centstorage—>db—>Centreon Web,在本地或远程的扩展节点中Nagios监控引擎会产生日志文件和rrds文件,这些文件定期被Centstorage读取并最终存储在数据库中,以供Centreon Web读取。
- 最后一条线:Nagios(Ndomod)—>Ndo2DB- —>db—>Centreon Web,这一条线将Nagios实时监控状态写入数据库,首先由在本地或远程扩展节点上的Ndomod进程将Nagios监控状态通过Ndo2DB模块写入数据库,最后Centreon Web会定期调用此db库,这样监控系统中各个主机或服务的监控状态就被实时展示出来了。
通过对这三条线的描述,Centreon内部工作过程就变得非常清晰了!
安装Centreon监控系统
Centreon的安装有一定的复杂性,对操作系统库依赖较多,在安装方式上有iso镜像安装和yum源安装两种,依次介绍:
1、ISO镜像安装
centreon ISO镜像安装:
https://download.centreon.com/?action=download&id=5284
从此地址下载centreon-21.04-1.el7.x86_64.iso文件,此文件是包含了centos系统和centreon软件,然后将此ISO刻录成u盘或者光盘,或者直接在虚拟机加载ISO文件,然后安装系统即可完成centreon的安装。
此方法安装简单,推荐大家使用。
2、yum安装方式
https://blog.csdn.net/pythonyzh2019/article/details/116670041
安装yum源:http://yum.centreon.com/standard/
yum install -y https://yum.centreon.com/standard/21.04/el7/stable/noarch/RPMS/centreon-release-21.04-2.el7.centos.noarch.rpm
2.2版本是centos5.x版本下的包,3.0/3.4版本是centos6.x版本下的包,18.0+是版本时centos7.x和centos8.x版本下的包
安装命令
yum install centreon
启动
/etc/init.d/centengine start
/etc/init.d/centcore start
/etc/init.d/centreontrapd start
/etc/init.d/cbd start # ndoutills 新版本改名成了cdb
/etc/init.d/httpd start
安装mariadb并启动服务
Ganglia与Centreon的无缝整合
Nagios和Ganglia都是很好的数据中心监控工具, 虽然它们的功能有重叠部分,但是两者对监控的侧重点并不相同:Ganglia侧重于收集数据,并随时跟踪数据状态,通过Ganglia不但可以看到数据的历史状态,也可以预计数据的未来发展趋势,为我们的应用程序修正和硬件采购提供决策。而Nagios更侧重与监控数据:并进行过载报警,综合Ganglia和Nagios的优缺点,同时运行这两个工具可以相互弥补它们的不足:
- Ganglia暂时没有内置报警通知机制,而Nagios这方面是强项。
- Nagios没有内置代理和分布式监控机制,而Ganglia设计之初就考虑到了这些。
- Nagios没有直观的报表展示(虽然可通过PNP插件:实现),而Ganglia报表功能很强大。
- Ganglia内置了基于很多开发接口,通过这些接口,可以将Ganglia统计到的数据纳入Nagios监控之下。
确定了以Ganglia作为数据收集模块, Centreon作为监控报警模块的方案,这样,一个智能监控报警平台两大主要功能模块已经基本实现了,但现在的问题是,如何将收集到的数据传送给监控报警模块呢,这就是数据抽取模块要完成的功能。
从数据抽取模块完成的功能可以看出,此模块主要,用来衔接数据收集模块和监控报警模块,进而完成Ganglia和Centreon的无缝整合。
要实现数据抽取模块的功能,没有现成的方法可用,需要在ganglia基础上做二次开发,较简单的方法是在通过程序在ganglia.上开发一个数据提取接口,然后将数据抽取到nagios中,初步方案是通过python程序来实现。
当然也有现成的方案,推荐两个现成的数据提取脚本:
- php版本: http://www.iivey.com/ganglia/check_ganglia_metric.php.txt
- Python版本: http://www.iivey.com/ganglia/check_ganglia_metric.py.txt
统一监控系统加构图
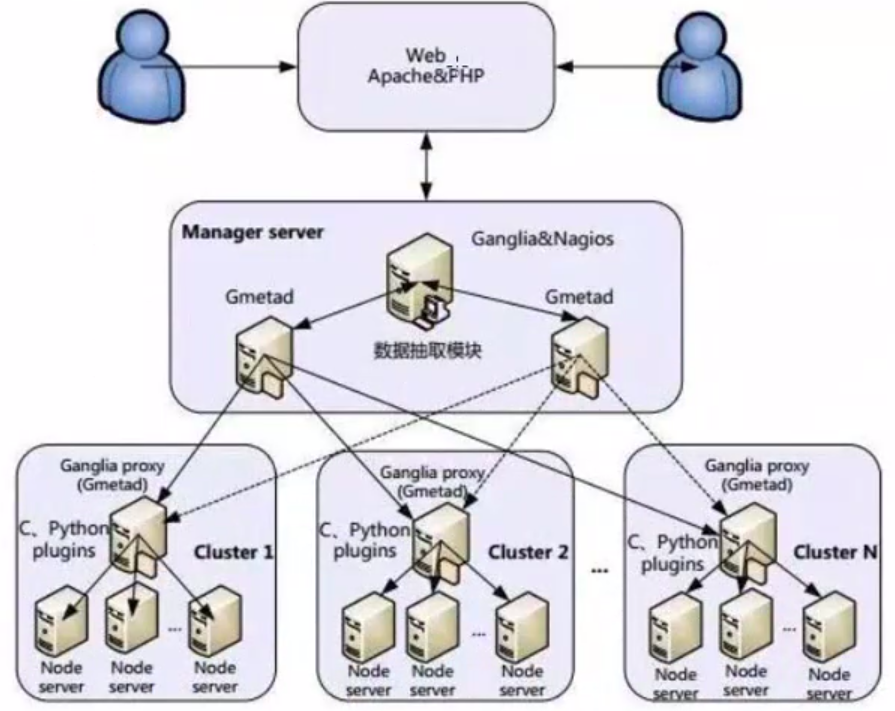
Cluster1-N均为一个分布式集群,也可以认为是一个机房数据中心。每个数据中心的Node server都运行一Gmond守护进程, 进行数据收集,将收集到的数据汇总到Gangliaproxy主机,Gangliaproxy主机上运行着Gmetad守护进程。同时Ganglia proxy和Node server都加载通过C或者Python编写的Ganglia插件, 扩展Ganglia监控功能。
Managerserver是一个管理主机, 主要用于收集从各个机房数据中心的监控数据,通过数据抽取模块将Nagjos和Ganglia整合到一起, 考虑到数据的安全性,Manager server建议做一个备机,平时主机和备机同时工作,进行数据收集,主机故障时,自动切换到备机,保证管理主机高可用。
监控数据和报表通过Web方式展示出来,将Nagios和Ganglia的web进行整合, 并作二次开发,通过一个统一的界面展示监控状态和报表信息。

若有收获,就点个赞吧
0 人点赞
