一、LVS 简介
LVS 是 Linux Virtual Server 的简称,也就是 Linux 虚拟服务器,是一个由章文嵩博士发起的自由软件项目,官方站点是:http://www.linuxvirtualserver.org。现在 LVS 已经是 Linux 标准内核的一部分,在 Linux2.4 内核以前,使用 LVS 时必须重新编译内核以支持 LVS 功能模块,但是从 Linux2.4 内核心之后,已经完全内置了 LVS 的各个功能模块,无需给内核打任何补丁,可以直接使用 LVS 提供的各种功能。
使用 LVS 技术要达到的目标是:通过 LVS 提供的负载均衡技术和 Linux 操作系统实现一个高性能,高可用的服务器群集,它具有良好的可靠性、可扩展性和可操作性。从而以低廉的成本实现最优的服务性能。
LVS自从1998年开始,发展到现在已经是一个比较成熟的技术项目了。可以利用LVS技术实现高可伸缩的、高可用的网络服务,例如WWW服务、Cache服务、DNS服务、FTP服务、MAIL服务、视频/音频点播服务等等,有许多比较著名网站和组织都在使用LVS架设的集群系统,例如:Linux的门户网站(www.linux.com)、向RealPlayer提供音频视频服务而闻名的Real公司(www.real.com)、全球最大的开源网站(sourceforge.net)等
LVS软件作用:通过LVS提供的负载均衡技术和Linux操作系统实现一个高性能、高可用的服务器群集,它具有良好可靠性、可扩展性和可操作性。从而以低廉的成本实现最优的服务性能。
1)优势
- 高并发连接
LVS基于内核网络层面工作,有超强的承载能力和并发处理能力。单台LVS负载均衡器,可支持上万并发连接
- 稳定性强
是工作在网络4层之上仅作分发之用,这个特点也决定了它在负载均衡软件里的性能最强,稳定 性好,对内存和cpu资源消耗极低。
- 成本低廉
硬件负载均衡器少则十几万,多则几十万上百万,LVS只需一台服务器和就能免费部署使用,性价比极高。
- 配置简单
LVS配置非常简单,仅需几行命令即可完成配置,也可写成脚本进行管理。
- 支持多种算法
支持多种论调算法,可根:据业务场景灵活调配进行使用
- 支持多种工作模型
可根据业务场景,使用不同的工作模式来解决生产环境请求处理问题。
- 应用范围广
因为LVS工作在4层,所以它几乎可以对所有应用做负载均衡,包括http、数据库、DNS、ftp服 务等等
2)不足
工作在4层,不支持7层规则修改,机制过于庞大,不适合小规模应用。
二、LVS 体系架构
使用 LVS 架设的服务器集群系统有三个部分组成:最前端的负载均衡层(Loader Balancer),中间的服务器群组层,用 Server Array 表示,最底层的数据共享存储层,用 Shared Storage 表示。在用户看来所有的应用都是透明的,用户只是在使用一个虚拟服务器提供的高性能服务。
LVS 的体系架构如图:
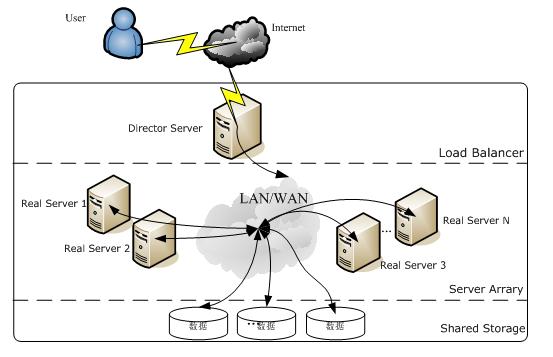
LVS 的各个层次的详细介绍:
Load Balancer 层:位于整个集群系统的最前端,有一台或者多台负载调度器(Director Server)组成,LVS 模块就安装在 Director Server 上,而 Director 的主要作用类似于一个路由器,它含有完成 LVS 功能所设定的路由表,通过这些路由表把用户的请求分发给 Server Array 层的应用服务器(Real Server)上。同时,在 Director Server 上还要安装对 Real Server 服务的监控模块 Ldirectord,此模块用于监测各个 Real Server 服务的健康状况。在 Real Server 不可用时把它从 LVS 路由表中剔除,恢复时重新加入。
Server Array 层:由一组实际运行应用服务的机器组成,Real Server 可以是 WEB 服务器、MAIL 服务器、FTP 服务器、DNS 服务器、视频服务器中的一个或者多个,每个 Real Server 之间通过高速的 LAN 或分布在各地的 WAN 相连接。在实际的应用中,Director Server 也可以同时兼任 Real Server 的角色。
Shared Storage 层:是为所有 Real Server 提供共享存储空间和内容一致性的存储区域,在物理上,一般有磁盘阵列设备组成,为了提供内容的一致性,一般可以通过 NFS 网络文件系统共享数 据,但是 NFS 在繁忙的业务系统中,性能并不是很好,此时可以采用集群文件系统,例如 Red hat 的 GFS 文件系统,oracle 提供的 OCFS2 文件系统等。
从整个 LVS 结构可以看出,Director Server 是整个 LVS 的核心,目前,用于 Director Server 的操作系统只能是 Linux 和 FreeBSD,linux2.6 内核不用任何设置就可以支持 LVS 功能,而 FreeBSD 作为 Director Server 的应用还不是很多,性能也不是很好。对于 Real Server,几乎可以是所有的系统平台,Linux、windows、Solaris、AIX、BSD 系列都能很好的支持。
三、LVS 基本工作原理
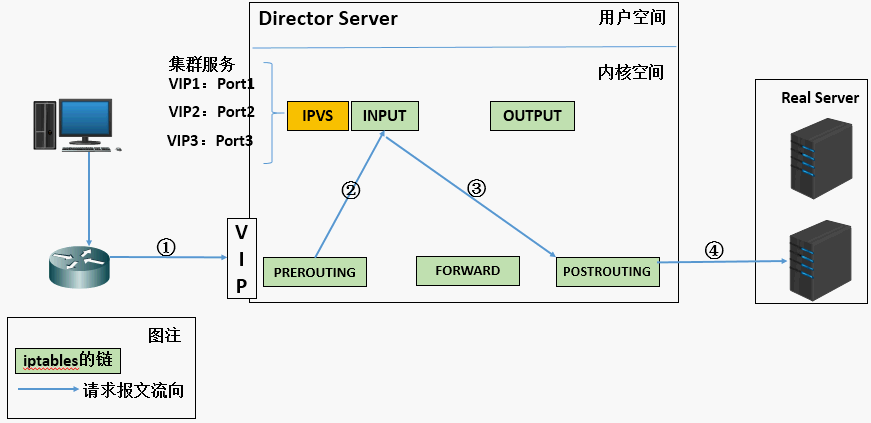
1、当用户向负载均衡调度器(Director Server)发起请求,调度器将请求发往至内核空间
2、 PREROUTING 链首先会接收到用户请求,判断目标 IP 确定是本机 IP,将数据包发往 INPUT 链
3、 IPVS 是工作在 INPUT 链上的,当用户请求到达 INPUT 时,IPVS 会将用户请求和自己已定义好的集群服务进行比对,如果用户请求的就是定义的集群服务,那么此时 IPVS 会强行修改数据包里的目标 IP 地址及端口,并将新的数据包发往 POSTROUTING 链
4、 POSTROUTING 链接收数据包后发现目标 IP 地址刚好是自己的后端服务器,那么此时通过选路,将数据包最终发送给后端的服务器
四、LVS 相关术语
1、 DS:Director Server。指的是前端负载均衡器节点。
2、 RS:Real Server。后端真实的工作服务器。
3、 VIP:Virstual IP,向外部直接面向用户请求,作为用户请求的目标的 IP 地址。
4、 DIP:Director Server IP,主要用于和内部主机通讯的 IP 地址。
5、 RIP:Real Server IP,后端服务器的 IP 地址。
6、 CIP:Client IP,访问客户端的 IP 地址
五、三种模式及原理
1、LVS-NAT 原理和特点
Network Address Translation
多目标 IP 的 DNAT,通过将请求报文中的目标地址和目标端口修改为某挑出的 RS 的 RIP 和 PORT 实现转发
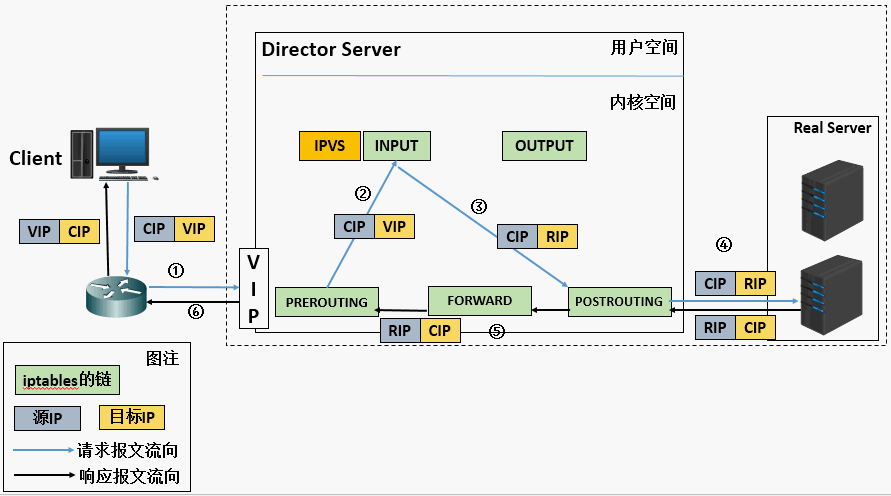
当用户请求到达 Director Server,此时请求的数据报文会先到内核空间的 PREROUTING 链。 此时报文的源 IP 为 CIP,目标 IP 为 VIP
PREROUTING 检查发现数据包的目标 IP 是本机,将数据包送至 INPUT 链
- IPVS 比对数据包请求的服务是否为集群服务,若是,修改数据包的目标 IP 地址为后端服务器 IP,后将数据包发至 POSTROUTING 链。 此时报文的源 IP 为 CIP,目标 IP 为 RIP
- POSTROUTING 链通过选路,将数据包发送给 Real Server
- Real Server 比对发现目标为自己的 IP,开始构建响应报文发回给 Director Server。 此时报文的源 IP 为 RIP,目标 IP 为 CIP
- Director Server 在响应客户端前,此时会将源 IP 地址修改为自己的 VIP 地址,然后响应给客户端。 此时报文的源 IP 为 VIP,目标 IP 为 CIP
LVS-NAT 模式的特性
(1) RS 应该和 DIP 应该使用私网地址,且 RS 的网关要指向 DIP;
(2) 请求和响应报文都要经由 director 转发;极高负载的场景中,director 可能会成为系统瓶颈;
(3) 支持端口映射;
(4) RS 可以使用任意 OS;
(5) RS 的 RIP 和 Director 的 DIP 必须在同一 IP 网络;
缺陷:对 Director Server 压力会比较大,请求和响应都需经过 director server
2、LVS-DR 原理和特点
Direct Routing
通过为请求报文重新封装一个 MAC 首部进行转发,源 MAC 是 DIP 所在的接口的 MAC,目标 MAC 是某挑选出的 RS 的 RIP 所在接口的 MAC 地址;源 IP/PORT,以及目标 IP/PORT 均保持不变;
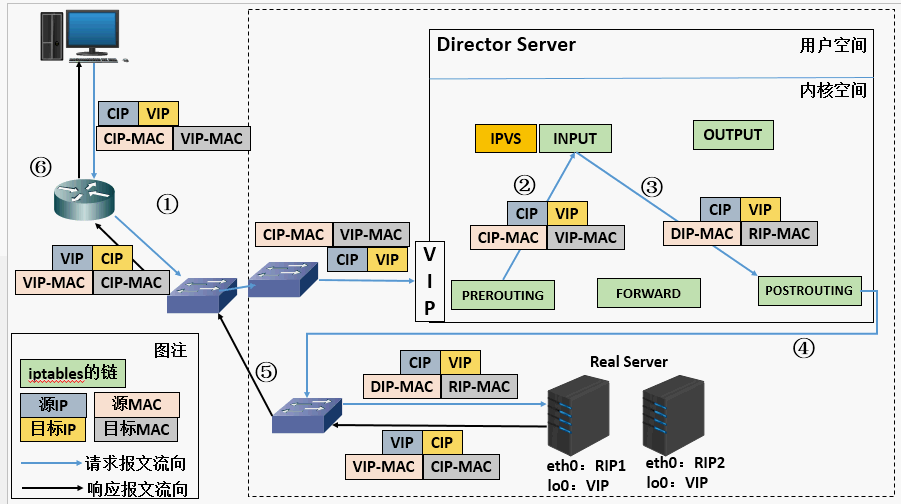
1、当用户请求到达 Director Server,此时请求的数据报文会先到内核空间的 PREROUTING 链。 此时报文的源 IP 为 CIP,目标 IP 为 VIP
2、PREROUTING 检查发现数据包的目标 IP 是本机,将数据包送至 INPUT 链
3、 IPVS 比对数据包请求的服务是否为集群服务,若是,将请求报文中的源 MAC 地址修改为 DIP 的 MAC 地址,将目标 MAC 地址修改 RIP 的 MAC 地址,然后将数据包发至 POSTROUTING 链。 此时的源 IP 和目的 IP 均未修改,仅修改了源 MAC 地址为 DIP 的 MAC 地址,目标 MAC 地址为 RIP 的 MAC 地址
4、 由于 DS 和 RS 在同一个网络中,所以是通过二层来传输。POSTROUTING 链检查目标 MAC 地址为 RIP 的 MAC 地址,那么此时数据包将会发至 Real Server。
5、 RS 发现请求报文的 MAC 地址是自己的 MAC 地址,就接收此报文。处理完成之后,将响应报文通过 lo 接口传送给 eth0 网卡然后向外发出。 此时的源 IP 地址为 VIP,目标 IP 为 CIP
6、 响应报文最终送达至客户端
LVS-DR 模式的特性
(1) 确保前端路由器将目标 IP 为 VIP 的请求报文发往 Director:
(a) 在前端网关做静态绑定;
(b) 在 RS 上使用 arptables;
(c) 在 RS 上修改内核参数以限制 arp 通告及应答级别;
修改 RS 上内核参数(arp_ignore 和 arp_announce)将 RS 上的 VIP 配置在 lo 接口的别名上,并限制其不能响应对 VIP 地址解析请求。
(2) RS 的 RIP 可以使用私网地址,也可以是公网地址;RIP 与 DIP 在同一 IP 网络;RIP 的网关不能指向 DIP,以确保响应报文不会经由 Director;
(3) RS 跟 Director 要在同一个物理网络;
(4) 请求报文要经由 Director,但响应不能经由 Director,而是由 RS 直接发往 Client;
(5) 不支持端口映射;
缺陷:RS 和 DS 必须在同一机房中
增加 lo:0的命令: ifconfig lo:0 192.168.100.229 netmask 255.255.255.0 up
或者: ip a a 192.168.100:220/24 dev lo
本地网络别名,因为要为本地网络绑定VIP ,这个VIP不作为通信,只在响应的时候作为源地址使用。
VIP:Mac(DVIP) 路由绑定drectoor 的IP地址
这就会使多台Real server 绑定同样的VIP,为了避免多台都响应的问题,引入了
arptables;
kernel parameter:
arp_ignore:定义接收到ARP诗求时的响应级别:
默认0 只要本地配置的有相应地址,就给予响应。
1,仅在请求的目标地址配置在请求到达的接口上的时候,才给予响应
arp_announce; 定义将自己地址向外通告时的通告级别:
默认0 将本机任何接口上的 任何地址 向外通告
1,试图仅向目标网络通告与其网络匹配的地址
2,总是使用最佳本地地址对外通告
实现脚本示例:
#!/bin/bash#description : Start Real ServerVIP=192.168.81.233./etc/rc.d/init.d/functionscase "$1" instart)echo " Start LVS of Real Server "/sbin/ifconfig 10:0 $VIP broadcast $VIP netmask 255.255.255.255 upecho "1" >/proc/sys/net/ ipv4/conf/lo/arp_ignoreecho "2" >/proc/sys/net/ipv4/conf/lo/arp_announceecho "1" >/proc/sys/net/ipv4/conf/all/arp_ignoreecho "2" >/proc/sys/net/ipv4/conf /all/arp_announce;;stop)/sbin/ifconfig lo:0 downecho "close LVS Director server "echo "o" >/proc/sys/net/ ipv4/ conf/1o/arp_ignoreecho "o" >/proc/sys/net/ ipv4/conf/lo/arp_announceecho "O" >/proc/sys/net/ ipv4/conf/all/arp_ignoreecho "o" >/proc/sys/net/ipv4/conf /all/arp_announce;;*)echo "Usage: $0 {start|stop}"exit 1
3、LVS-Tun 原理和特点
Tunneling (隧道)
在原有的 IP 报文外再次封装多一层 IP 首部,内部 IP 首部 (源地址为 CIP,目标 IP 为 VIP),外层 IP 首部 (源地址为 DIP,目标 IP 为 RIP)
原理
在 DR 模式中是所有服务机共享一个 VIP,但是在 IP 隧道模式中,就相当于主代理机将包经过自己打包之后,将 IP 转化成公网可传递的 IP,并将消息经过自己又一次的打包,发送给真实服务器,真实服务器对这个请求作出响应,这样就达到一个可以跨地区的传输。并且也避免了 DR 模式中代理机与真实服务机必须在同一局域网的不便。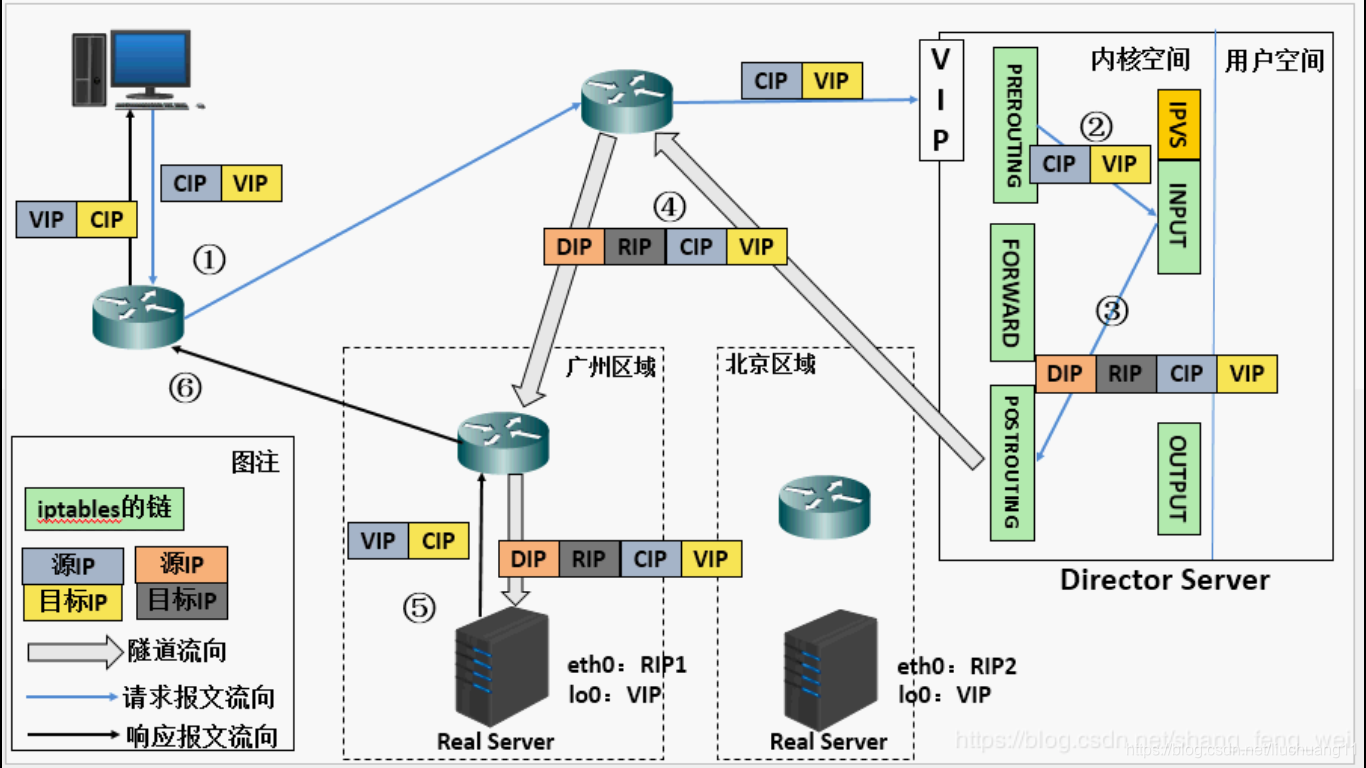
原理说明:
1、 当用户请求到达Director Server,此时请求的数据报文会先到内核空间的PREROUTING链。此时报文的源IP为CIP,目标IP为VIP 。2、 PREROUTING检查发现数据包的目标IP是本机,将数据包送至INPUT链3、IPVS比对数据包请求的服务是否为集群服务,若是,在请求报文的首部再次封装一层IP报文,封装源IP为为DIP,目标IP为RIP。然后发至POSTROUTING链。此时源IP为DIP,目标IP为RIP4、 POSTROUTING链根据最新封装的IP报文,将数据包发至RS(因为在外层封装多了一层IP首部,所以可以理解为此时通过隧道传输)。此时源IP为DIP,目标IP为RIP5、RS接收到报文后发现是自己的IP地址,就将报文接收下来,拆除掉最外层的IP后,会发现里面还有一层IP首部,而且目标是自己的lo接口VIP,那么此时RS开始处理此请求,处理完成之后,通过lo接口送给eth0网卡,然后向外传递。此时的源IP地址为VIP,目标IP为CIP
LVS-Tun 模型特性
RIP、VIP、DIP全是公网地址RS的网关不会也不可能指向DIP所有的请求报文经由Director Server,但响应报文必须不能进过Director Server不支持端口映射RS的系统必须支持隧道
LVS(隧道模式 tun) 模式搭建
注意:在实际生产中 RIP、VIP、DIP 全是公网地址,目前由于条件限制,为了实现实验效果。实验中 RIP、VIP、DIP 、CIP 全部为同一个网段的 ip。
以下实验时在 7.3 主机上进行
[root@lucky2 ~]# ipvsadm -C 为了保证实验的纯净性,可以先清除一下策略
优点: 可跨局域
代理端:
[root@lucky2 ~]# modprobe ipip 加入ip隧道的命令[root@lucky2 ~]# ip addr show 在加入ip隧道之后,出现了一个tunl0的IP设备1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000link/ether 52:54:00:50:95:19 brd ff:ff:ff:ff:ff:ffinet 172.25.35.2/24 brd 172.25.35.255 scope global eth0valid_lft forever preferred_lft foreverinet 172.25.35.100/24 scope global secondary eth0valid_lft forever preferred_lft foreverinet6 fe80::5054:ff:fe50:9519/64 scope linkvalid_lft forever preferred_lft forever3: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN qlen 1link/ipip 0.0.0.0 brd 0.0.0.0
给这个 tunl0 加上隧道 ip
[root@lucky2 ~]# ip addr add 172.25.35.100/24 dev tunl0[root@lucky2 ~]# ip link set up tunl0 使这个隧道IP生效
编写策略:
[root@lucky2 ~]# ipvsadm -A -t 172.25.35.100:80 -s rr 输出的数据轮询达到负载均衡的目的[root@lucky2 ~]# ipvsadm -a -t 172.25.35.100:80 -r 172.25.35.4:80 -i[root@lucky2 ~]# ipvsadm -a -t 172.25.35.100:80 -r 172.25.35.3:80 -i 当用户访问代理的时候,代理是不知道的,就会访问后端的服务器,在此访问两台达到负载均衡的效果就可以了[root@lucky2 ~]# ipvsadm -LIP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags-> RemoteAddress:Port Forward Weight ActiveConn InActConnTCP lucky2:http rr-> lucky3:http Tunnel 1 0 0-> lucky4:http Tunnel 1 0 0
后端服务器集群:
后端服务器集群进行的操作都是一样的:
[root@lucky3 html]# modprobe ipip[root@lucky3 html]# ip addr add 172.25.35.100/24 dev tunl0 需要确认的是服务器的隧道ip要和代理的隧道ip是相同的,这样能保证跨区域的实现。[root@lucky3 html]# ip link set up tunl0 生效ip ,后端服务器,也确保httpd服务是打开的,用户端检测的时候才能链接上
代理端:
**sysctl -a | grep rp_filter 将里面的全换乘等于 0,不检验数据包地址,也就是在包裹的一层 ip 地址。**
rp_filter参数有三个值,0、1、2,具体含义rp_filter参数用于控制系统是否开启对数据包源地址的校验。- 0:不开启源地址校验。
- 1:开启严格的反向路径校验。对每个进来的数据包,校验其反向路径是否是最佳路径。如果反向路径不是最佳路径,则直接丢弃该数据包。
- 2:开启松散的反向路径校验。对每个进来的数据包,校验其源地址是否可达,即反向路径是否能通(通过任意网口),如果反向路径不同,则直接丢弃该数据包。
需要注意的一点就是
sysctl -w net.ipv4.conf.all.rp_filter=0 将所有的1 都替换成1的过程中,= 号两侧必须是无间隔的,这样是才会生效的
检测:
[root@foundation35 images]# curl 172.25.35.100lucky4[root@foundation35 images]# curl 172.25.35.100lucky3[root@foundation35 images]# curl 172.25.35.100lucky4[root@foundation35 images]# curl 172.25.35.100lucky3[root@foundation35 images]# curl 172.25.35.100
https://blog.csdn.net/liuchuang11/article/details/93677282
六、LVS 的十种调度算法
1、静态调度:
①RR(Round Robin): 轮询调度
轮询调度算法的原理是每一次把来自用户的请求轮流分配给内部中的服务器,从 1 开始,直到 N(内部服务器个数),然后重新开始循环。算法的优点是其简洁性,它无需记录当前所有连接的状态,所以它是一种无状态调度。【提示:这里是不考虑每台服务器的处理能力】
②WRR:weight, 加权轮询(以权重之间的比例实现在各主机之间进行调度)
由于每台服务器的配置、安装的业务应用等不同,其处理能力会不一样。所以,我们根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求。
③SH:source hashing, 源地址散列。主要实现会话绑定,能够将此前建立的 session 信息保留了
源地址散列调度算法正好与目标地址散列调度算法相反,它根据请求的源 IP 地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的并且没有超负荷,将请求发送到该服务器,否则返回空。它采用的散列函数与目标地址散列调度算法的相同。它的算法流程与目标地址散列调度算法的基本相似,除了将请求的目标 IP 地址换成请求的源 IP 地址,所以这里不一个一个叙述。
④DH:Destination hashing: 目标地址散列。把不同IP对同一个URI的请求,发送给同一个 server。多用于cache server。
目标地址散列调度算法也是针对目标 IP 地址的负载均衡,它是一种静态映射算法,通过一个散列(Hash)函数将一个目标 IP 地址映射到一台服务器。目标地址散列调度算法先根据请求的目标 IP 地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。
2、动态调度:
①LC(Least-Connection):最少连接
最少连接调度算法是把新的连接请求分配到当前连接数最小的服务器,最小连接调度是一种动态调度短算法,它通过服务器当前所活跃的连接数来估计服务器的负载均衡,调度器需要记录各个服务器已建立连接的数目,当一个请求被调度到某台服务器,其连接数加 1,当连接中止或超时,其连接数减一,在系统实现时,我们也引入当服务器的权值为 0 时,表示该服务器不可用而不被调度。
简单算法:active*256+inactive(谁的小,挑谁)
②WLC(Weighted Least-Connection Scheduling):加权最少连接。
加权最小连接调度算法是最小连接调度的超集,各个服务器用相应的权值表示其处理性能。服务器的缺省权值为 1,系统管理员可以动态地设置服务器的权限,加权最小连接调度在调度新连接时尽可能使服务器的已建立连接数和其权值成比例。
简单算法:(active256+inactive)/weight【(活动的连接数255 + 非活动连接数)/ 权重】(谁的小,挑谁)
③SED(Shortest Expected Delay):最短期望延迟
基于 wlc 算法
简单算法:(active+1)256/weight 【(活动的连接数 + 1)256 / 权重】
④NQ(never queue): 永不排队(改进的 sed)
无需队列,如果有台 realserver 的连接数=0 就直接分配过去,不需要在进行 sed 运算。
⑤LBLC(Locality-Based Least Connection):基于局部性的最少连接
基于局部性的最少连接算法是针对请求报文的目标 IP 地址的负载均衡调度,不签主要用于 Cache 集群系统,因为 Cache 集群中客户请求报文的布标 IP 地址是变化的,这里假设任何后端服务器都可以处理任何请求,算法的设计目标在服务器的负载基本平衡的情况下,将相同的目标 IP 地址的请求调度到同一个台服务器,来提高个太服务器的访问局部性和主存 Cache 命中率,从而调整整个集群系统的处理能力。
基于局部性的最少连接调度算法根据请求的目标 IP 地址找出该目标 IP 地址最近使用的 RealServer,若该 Real Server 是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用 “最少链接” 的原则选出一个可用的服务器,将请求发送到该服务器。
⑥LBLCR(Locality-Based Least Connections withReplication):带复制的基于局部性最少链接
带复制的基于局部性最少链接调度算法也是针对目标 IP 地址的负载均衡,该算法根据请求的目标 IP 地址找出该目标 IP 地址对应的服务器组,按 “最小连接” 原则从服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按 “最小连接” 原则从这个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。
七、K8S与IPVS
在Kubernetes官方博客之前的文章《Kubernetes1.11: In-Cluster Load Balancingand CoreDNS Plugin Graduate to General Availability中我们宣布了基于IPVS的集群内负载均衡已经实现了GA(General Availability),在这篇文章中我们将详细介绍该特性的实现细节。
什么是IPVS
IPVS (IP Virtual Server)是基于Netfilter的、作为linux内核的一部分实现传输层负载均衡的技术。
IPVS集成在LVS(Linux Virtual Server)中,它在主机中运行,并在真实服务器集群前充当负载均衡器。IPVS可以将对TCP/UDP服务的请求转发给后端的真实服务器,因此IPVS天然支持Kubernetes Service。
为什么选择IPVS
随着kubernetes使用量的增长,其资源的可扩展性变得越来越重要。特别是对于使用kubernetes运行大型工作负载的开发人员或者公司来说,service的可扩展性至关重要。
kube-proxy是为service构建路由规则的模块,之前依赖iptables来实现主要service类型的支持,比如(ClusterIP和NodePort)。但是iptables很难支持上万级的service,因为iptables纯粹是为防火墙而设计的,并且底层数据结构是内核规则的列表。
kubernetes早在1.6版本就已经有能力支持5000多节点,这样基于iptables的kube-proxy就成为集群扩容到5000节点的瓶颈。举例来说,如果在一个5000节点的集群,我们创建2000个service,并且每个service有10个pod,那么我们就会在每个节点上有至少20000条iptables规则,这会导致内核非常繁忙。
基于IPVS的集群内负载均衡就可以完美的解决这个问题。IPVS是专门为负载均衡设计的,并且底层使用哈希表这种非常高效的数据结构,几乎可以允许无限扩容。
基于IPVS的kube-proxy
IPVS (IP Virtual Server)是基于Netfilter的、作为linux内核的一部分实现传输层负载均衡的技术。
IPVS集成在LVS(Linux Virtual Server)中,它在主机中运行,并在真实服务器集群前充当负载均衡器。IPVS可以将对TCP/UDP服务的请求转发给后端的真实服务器,因此IPVS天然支持Kubernetes Service。
启动参数变更
启动参数:—proxy-mode。除了userspace模式和iptables模式外,现在用户可以通过—proxy-mode=ipvs使用IPVS模式。它默认使用IPVS的NAT模式,用于实现service端口映射。
启动参数:—ipvs-scheduler。引入新的kube-proxy参数以支持IPVS的负载均衡算法,用户可以通过—IPVS-scheduler配置,默认使用轮询模式(rr)。下面是另外支持的几种负载均衡算法:
• rr:轮询
• lc:最少连接数
• dh:目的地址哈希
• sh:源地址哈希
• sed:最短期望延时
• nq:从不排队
未来还可以实现通过service定义调度策略(可能是基于annotation),覆盖kube-proxy默认的调度策略。
启动参数:-cleanup-ipvs。与iptables的—cleanup-iptables参数类似,如果设置为true,清理IPVS相关配置,以及IPVS模式创建的iptables规则。
启动参数:—ipvs-sync-period。刷新IPVS规则的最大时间间隔,必须大于0。
启动参数:—ipvs-min-sync-period。刷新IPVS规则的最小时间间隔,必须大于0。
启动参数:—ipvs-exclude-cidrs。指定一个用逗号分隔的CIDR列表,这个列表规定了IPVS刷新时不能清理的规则。因为基于IPVS的kube-proxy不能区分自身创建的规则和系统中用户自带的规则,因此如果您要使用基于IPVS的kube-proxy并且系统中原来存在一些IPVS规则,那么应该加上这个启动参数,否则系统中原来的规则会被清理掉。
设计细节
a) IPVS service网络拓扑
当我们创建ClusterIP类型的service时,IPVS模式的kube-proxy会做下面几件事:
• 确认节点中的虚拟网卡,默认是kube-ipvs0
• 绑定service IP地址到虚拟网卡
• 为每个service IP地址创建IPVS虚拟服务器
下面是一个示例:
# kubectl describe svc nginx-serviceName: nginx-service...Type: ClusterIPIP: 10.102.128.4Port: http 3080/TCPEndpoints:10.244.0.235:8080,10.244.1.237:8080Session Affinity: None# ip addr ... 73:kube-ipvs0:<BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN qlen 1000link/ether 1a:ce:f5:5f:c1:4d brd ff:ff:ff:ff:ff:ffinet 10.102.128.4/32scope global kube-ipvs0 valid_lft forever preferred_lft forever# ipvsadm -ln IP Virtual Server version 1.2.1 (size=4096)Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 10.102.128.4:3080 rr -> 10.244.0.235:8080 Masq 1 0 0 -> 10.244.1.237:8080 Masq 1 0 0
需要注意的是,service与IPVS虚拟服务器应该是1:N的对应关系,因为service可能有多个IP地址(比如ExternalIP类型的service,就有clusterIP和ExternalIP两个地址)。而endpoint与IPVS真实服务器的对应关系应该是1:1。
删除kubernetes的service将会触发删除相应的IPVS虚拟服务器、IPVS真实服务器并且解绑虚拟网卡上的IP。
b)端口映射
IPVS有三种代理模式:NAT(masq),IPIP 和DR,其中只有NAT模式支持端口映射。kube-proxy使用NAT模式进行端口映射,以下示例是IPVS映射service端口3080到pod端口8080:
TCP 10.102.128.4:3080 rr
-> 10.244.0.235:8080 Masq 1 0 0
-> 10.244.1.237:8080 Masq 1 0
c) 会话保持
IPVS支持会话保持,当kubernetes的service指定会话保持时,IPVS会设置超时时间,默认180分钟,下面是会话保持示例:
kubectl describe svc nginx-service
Name: nginx-service
…
IP: 10.102.128.4
Port: http 3080/TCP
Session Affinity: ClientIP
ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:3080 rr persistent 10800
d) IPVS模式中的iptables和ipset
IPVS是专门为负载均衡设计的,因此IPVS自身不能实现kube-proxy的其他功能,比如包过滤、hairpin、源地址转换等。
IPVS模式会在上述场景中使用iptables,具体来说分为下面四种场景:
• kube-proxy启动参数中带有—masquerade-all=true,即所有流量作源地址转换。
• kube-proxy启动参数中指定CIDR。
• 支持LoadBalancer类型的service。
• 支持NodePort类型的service。
但是IPVS模式不会像iptables模式,创建太多iptables规则。所以我们引入了ipset来减少iptables规则。以下是IPVS模式维护的ipset表:
| ipset名称 | set成员 | 功能 |
|---|---|---|
| KUBE-CLUSTER-IP | 所有Service IP + port | 如果启动参数中加了masquerade-all=true或clusterCIDR,用来做masquerade |
| KUBE-LOOP-BACK | 所有Service IP + port + IP | 针对hairpin问题做masquerade |
| KUBE-EXTERNAL-IP | Service External IP + port | 对方问外部IP的流量做masquerade |
| KUBE-LOAD-BALANCER | lb型service的ingress IP + port | 对访问lb类型service的流量做masquerade |
| KUBE-LOAD-BALANCER-LOCAL | 规定了externalTrafficPolicy=local的lb型的service的ingress IP + port | 接收规定了externalTrafficPolicy=local的lb型service |
| KUBE-LOAD-BALANCER-FW | 规定了loadBalancerSourceRanges的lb型的service的ingress IP + port | 针对规定了loadBalancerSourceRanges的lb型service,用于过滤流量 |
| KUBE-LOAD-BALANCER-SOURCE-CIDR | lb型的service的ingress IP + port + source CIDR | 针对规定了loadBalancerSourceRanges的lb型service,用于过滤流量 |
| KUBE-NODE-PORT-TCP | NodePort型Service TCP port | 对访问NodePort(TCP)的流量作masquerade |
| KUBE-NODE-PORT-LOCAL-TCP | 规定了externalTrafficPolicy=local的NodePort型Service TCP port | 接收规定了externalTrafficPolicy=local的NodePort型service |
| KUBE-NODE-PORT-UDP | NodePort型Service UDP port | 对访问NodePort(UDP)的流量作masquerade |
| KUBE-NODE-PORT-LOCAL-UDP | 规定了externalTrafficPolicy=local的NodePort型Service UDP port | 接收规定了externalTrafficPolicy=local的NodePort型service |
通常来说,对于IPVS模式的kube-proxy,无论有多少pod/service,iptables的规则数都是固定的。
e)使用基于IPVS的kube-proxy
目前,local-up-cluster脚本,GCE部署集群脚本,kubeadm都已经支持通过环境变量KUBE_PROXY_MODE=ipvs自动部署IPVS模式的集群。
另外可以通过在kube-proxy的启动参数中添加—proxy=mode=ipvs启动IPVS模式的kube-proxy,不过需要保证事先加载了IPVS依赖的内核模块。
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack_ipv4
最后,在kubernetes之前的版本中,需要通过设置特性开关SupportIPVSProxyMode来使用IPVS。在kubernetes v1.10版本中,特性开关SupportIPVSProxyMode默认开启,在1.11版本中该特性开关已经被移除。但是如果您使用kubernetes 1.10之前的版本,需要通过—feature-gates=SupportIPVSProxyMode=true开启SupportIPVSProxyMode才能正常使用IPVS。
八、ipadm
apt-get install ipadm
ipvsadm:管理集群服务
添加:-A -tlu|f service-address [-s scheduler]
-t:TCP协议的集群
-u:UDP协议的集群
service-address: IP:PORT
-f:FWM:防火墙标记
service-address: Mark Number
修改:-E
删除:-D -t|u|f service-address
# ipvsadm -A -t 172.16.100.1:80 -s rr
管理集群服务中的RS
添加:-a -tlu|f service-address r server-address [-gli|m] [-w weight]
-tlu|f service-address: 事先定义好的某集群服务
-rserver-address:某Rs的地址, 在NAT模型中,可使用IP:PORT实现端口映射;
[-gli|m]:LVS类型
-g (getway): DR
-i (interne)t:TUN
-m (masquerading):NAT or network access translation
修改: -e
删除: -d -t | u | f service-address -r server-address
# ipvsadm -a -t 172.16.100.1:80 -r 192.168.10.8 -m
查看
-L| l
-n:数字格式显示主机地址和端口
—stats:统计数据
—rate:速率
—timeout:显示tcp、tcpfin和udp的会话超时时长
-c:显示当前的ipvs连接状况
—sort 排序
—daemon
删除所有集群服务
-C:清空ipvs保存规则
保存ipvs规则
-S
# ipvsadm -S > /path/to/somefile
载入此前的规则:
-R
# ipvsadm -R < /path/form/somefile
各节点之间的时间偏差不应该超出1秒钟:
NTP: Network Time Protocol
九、附件

若有收获,就点个赞吧
0 人点赞
