一、集群概念
1、集群(cluster)技术是一种较新的技术,通过集群技术,可以在付出较低成本的情况下获得在性能、可靠性、灵活性方面的相对较高的收益,其任务调度则是集群系统中的核心技术。
2、集群是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器。
3、集群组成后,可以利用多个计算机和组合进行海量请求处理(负载均衡),从而获得很高的处理效率,也可以用多个计算机做备份(高可用),使得任何一个机器坏了整个系统还是能正常运行。集群在目前互联网公司是必备的技术,极大提高互联网业务的可用性和可缩放性。
二、集群系统扩展方式:
Scale UP:向上扩展,增强
Scale Out:向外扩展,增加设备,调度分配问题,Cluster
Cluster:集群,为解决某个特定问题将多台计算机组合起来形成的单个系统
三、Linux Cluster类型:
- LB:Load Balancing,负载均衡
- HA:High Availiablity,高可用,SPOF(single Point Of failure)
- MTBF:Mean Time Between Failure平均无故障时间
- MTTR:Mean Time To Restoration ( repair)平均恢复前时间
- A=MTBF/(MTBF+MTTR) 取值范围(0,1):99%,99.5%, 99.9%,99.99%, 99.999%
- HPC:High-performance computing,高性能处理复杂问题,科学计算集群
分布式系统:
分布式存储:云盘
分布式计算:hadoop,Spark
负载均衡集群
负载均衡集群为企业需求提供了可解决容量问题的有效方案,使负载可以在计算机集群中尽可能平均地分摊处理。
负载通常包括应用程序处理负载和网络流量负载。这样的系统非常适合向使用同一组应用程序的大量用户提供服务。每个节点都可以承担一定的处理负载,并且可以实现处理负载在节点之间的动态分配,以实现负载均衡。对于网络流量负载,当网络服务程序接受了高入网流量,以致无法迅速处理,这时,网络流量就会发送给在其它节点上运行的网络服务程序。也可根据服务器的承载能力,进行服务请求的分发,从而使用户的请求得到更快速的处理。
- 负载均衡技术类型:基于4层负载均衡技术和基于7层负载均衡技术
- 负载均衡实现方式:硬件负载均衡设备或者软件负载均衡
- 硬件负载均衡产品:F5、BIG-IP、CitrixNetscaler、深信服、Array、Radware
- 软件负载均衡产品:LVS(LinuxVirtualServer)、Haproxy、Nginx、Ats(apachetrafficserver)
1、实现效果图
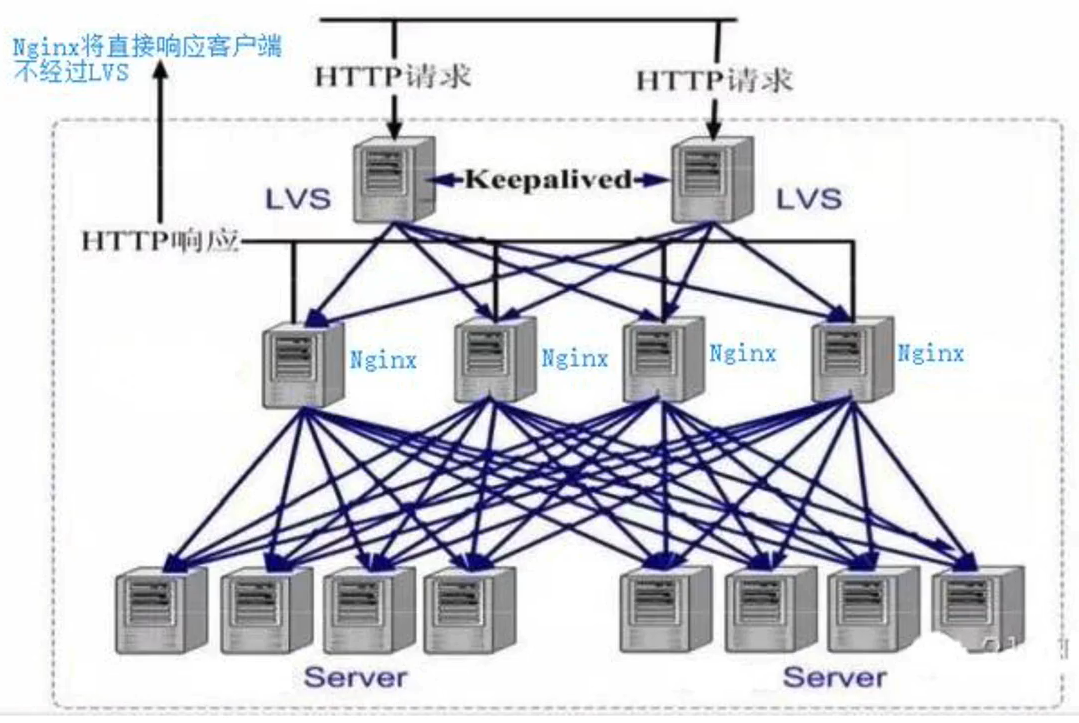
2、负载均衡分类
负载均衡根据所采用的设备对象(软/硬件负载均衡),应用的 OSI 网络层次(网络层次上的负载均衡),及应用的地理结构(本地/全局负载均衡)等来分类。本文着重介绍的是根据应用的 OSI 网络层次来分类的两个负载均衡类型。
我们先来看一张图,相信很多同学对这张图都不陌生,这是一-张网络模型图,包含了OSI模型及TCP/IP模型,两个模型虽然有一点点区别,但主要的目的是一样的,模型图描述了通信是怎么进行的。它解决了实现有效通信所需要的所有过程,并将这些过程划分为逻辑上的层。层可以简单地理解成数据通信需要的步骤。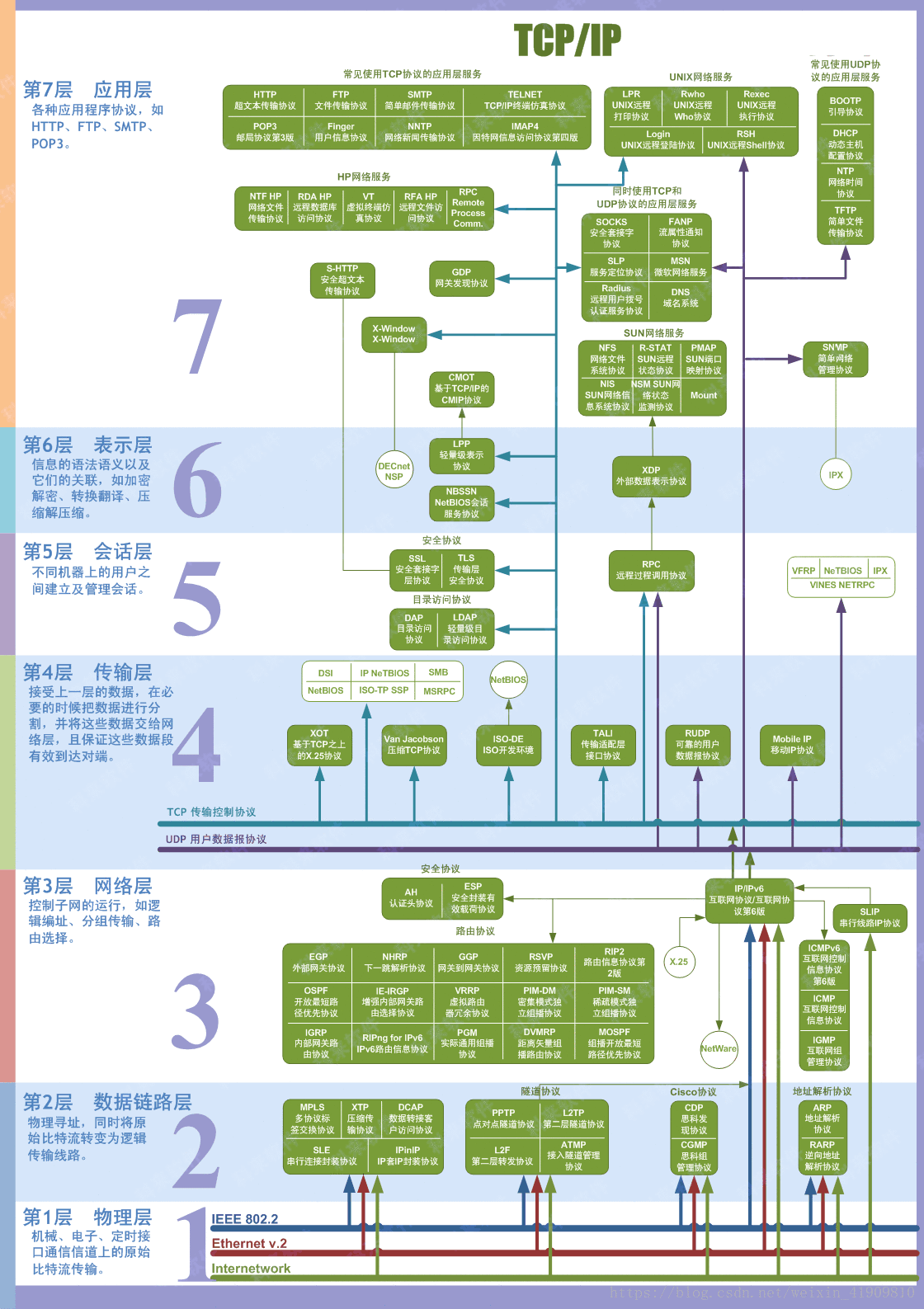
1.报文(message)
我们将位于应用层的信息分组称为报文。报文是网络中交换与传输的数据单元,也是网络传输的单元。报文包含了将要发送的完整的数据信息,其长短不需一致。报文在传输过程中会不断地封装成分组、包、帧来传输,封装的方式就是添加一些控制信息组成的首部,那些就是报文头。
2.报文段(segment)
通常是指起始点和目的地都是传输层的信息单元。
3.分组/包(packet)
分组是在网络中传输的二进制格式的单元,为了提供通信性能和可靠性,每个用户发送的数据会被分成多个更小的部分。在每个部分的前面加上一些必要的控制信息组成的首部,有时也会加上尾部,就构成了一个分组。它的起始和目的地是网络层。
4.数据报(datagram)
面向无连接的数据传输,其工作过程类似于报文交换。采用数据报方式传输时,被传输的分组称为数据报。通常是指起始点和目的地都使用无连接网络服务的的网络层的信息单元。
5.帧(frame)
帧是数据链路层的传输单元。它将上层传入的数据添加一个头部和尾部,组成了帧。它的起始点和目的点都是数据链路层。
6.数据单元(data unit)
指许多信息单元。常用的数据单元有服务数据单元(SDU)、协议数据单元(PDU)。
SDU是在同一机器上的两层之间传送信息。PDU是发送机器上每层的信息发送到接收机器上的相应层(同等层间交流用的)。
应用层——消息
传输层——数据段/报文段(segment) (注:TCP叫TCP报文段,UDP叫UDP数据报,也有人叫UDP段)
网络层——分组、数据包(packet)
链路层——帧(frame)
物理层——P-PDU(bit)

其实,segment,datagram,packet,frame是存在于同条记录中的,是基于所在协议层不同而取了不同的名字。我们可以用一个形象的例子对数据包的概念加以说明:我们在邮局邮寄产品时,虽然产品本身带有自己的包装盒,但是在邮寄的时候只用产品原包装盒来包装显然是不行的。必须把内装产品的包装盒放到一个邮局指定的专用纸箱里,这样才能够邮寄。这里,产品包装盒相当于数据包,里面放着的产品相当于可用的数据,而专用纸箱就相当于帧,且一个帧中通常只有一个数据包。
TCP数据流(TCP stream)
Wireshark中是这么定义的:相同四元组(源地址,源端口,目的地址,目的端口)的包就为一条TCP流,即一条流有很多个包。
[IP address A, TCP port A, IP address B, TCP port B]
All the packets for the same tcp.stream value should have the same values for these fields (though the src/dest will be switched for A->B and B->A packets).
the stream index is an internal Wireshark mapping to: [IP address A, TCP port A, IP address B, TCP port B]
All the packets for the same tcp.stream value should have the same values for these fields (though the src/dest will be switched for A->B and B->A packets)
see the Statistics/Conversations/TCP tab in Wireshark to show a summary of these streams.
以下用Wireshark实际抓包说明一下:
一个包就是一行记录,可看出是从No.1开始计数的。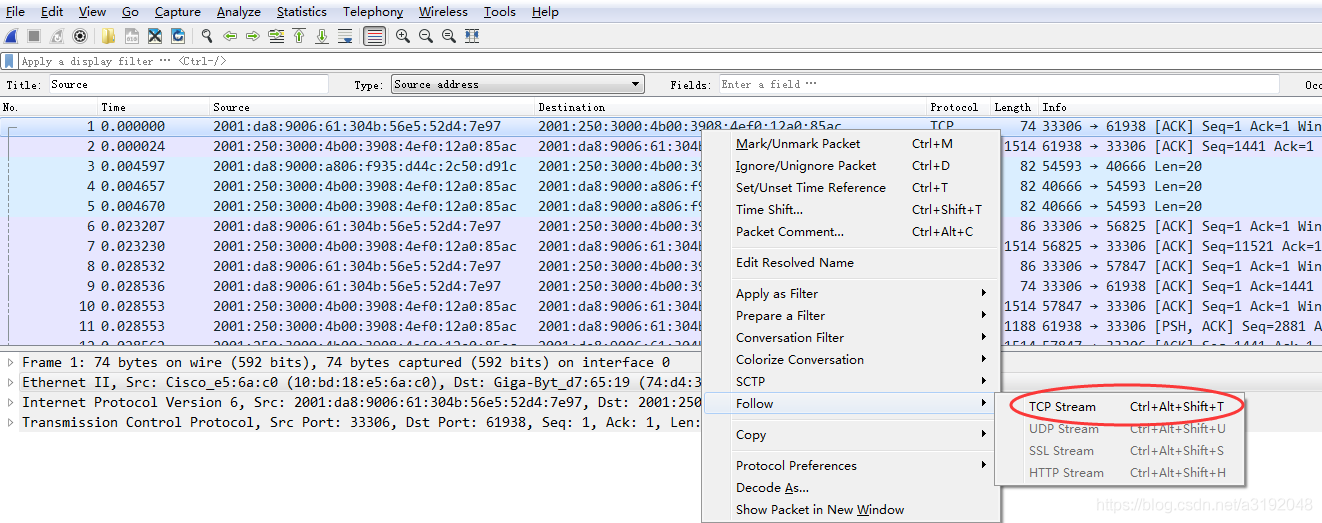
点击Follow->TCP Stream可查看该包所属的流:
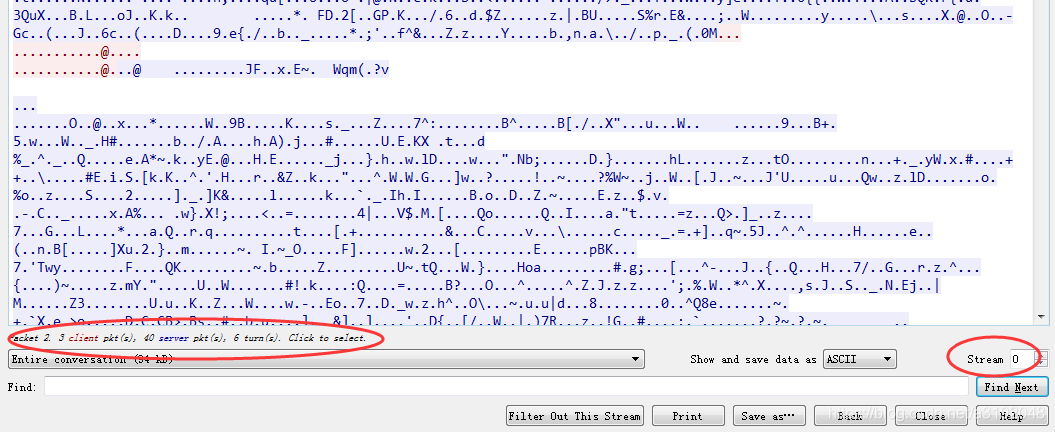
可看出wireshark中流是从0开始计数的,这个流序号没什么意义,只是为了唯一标识一条流(Stream indexes are Wireshark-internal. It just uses a number to uniquely identify a TCP stream.),该流有3个客户端包,40个服务端包,最左边的packet 2 表示鼠标点击的这个包在全部包序列中的序号。
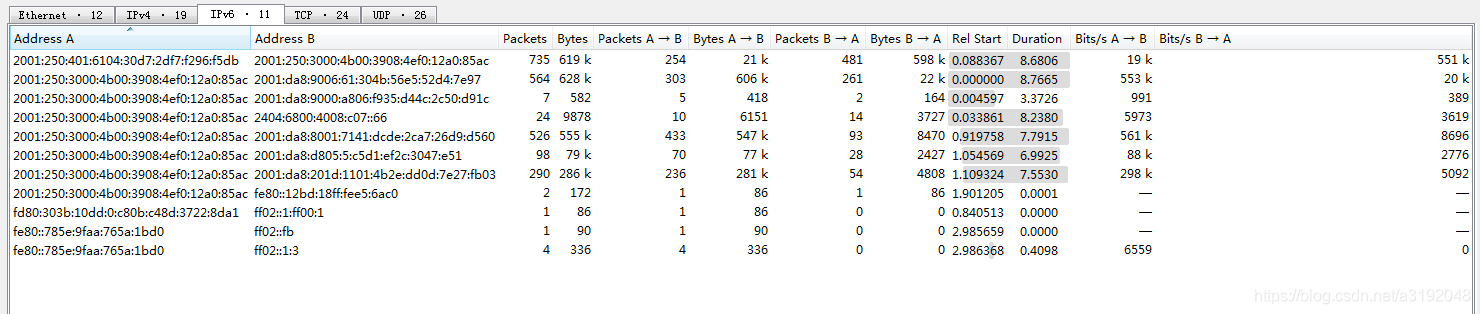
点击Statistics->Conversations

(注:我的ipv4地址是公网ip,所以做了马赛克处理,ipv6是临时ip就无所谓了。)
可看到:TCP流有24条,UDP流有26条。IPv4流有19条,IPv6流有11条,为什么IPv4+IPv6流总数小于TCP+UDP流呢?
因为IP流没有端口,只考虑相同二元组(源ip,目的ip):
根据负载均衡所作用在OSI模型的位置不同,负载均衡可以大概分为以下几类:
- 二层负载均衡(mac)
根据OSI模型分的二层负载,一般是用虚拟mac地址方式,外部对虚拟MAC地址请求,负载均衡接收后分配后
端实际的MAC地址响应。
- 三层负载均衡(ip)
一般采用虚拟IP地址方式,外部对虚拟的ip地址请求,负载均衡接收后分配后端实际的IP地址响应。
- 四层负载均衡(tcp)
在三层负载均衡的基础上,用ip+port接收请求,再转发到对应的机器。
- 七层负载均衡(http)
根据虚拟的url或IP,主机名接收请求,再转向相应的处理服务器。
实际应用中,比较常见的就是四层负载及七层负载
3、四层负载均衡
基于IP+端口的负载均衡
所谓四层负载均衡,也就是主要通过报文中的目标地址和端口,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。
layer4
在三层负载均衡的基础上,通过发布三层的IP地址(VIP),然后加四层的端口号,来决定哪些流量需要做负载均衡,对需要处理的流量进行NAT处理,转发至后台服务器,并记录下这个TCP或者UDP的流量是由哪台服务器处理的,后续这个连接的所有流量都同样转发到同一台服务器处理。
以常见的TCP为例,负载均衡设备在接收到第一一个来自客户端的SYN请求时,即通过上述方式选择-一个最佳的服务器,并对报文中目标IP地址进行修改(改为后端服务器IP),直接转发给该服务器。TCP的连接建立,即三次握手是客户端和服务器直接建立的,负载均衡设备只是起到一个类似路由器的转发动作。在某些部署情况下,为保证服务器回包可以正确返回给负载均衡设备,在转发报文的同时可能还会对报文原来的源地址进行修改。
对应的负载均衡器称为四层交换机(L4switch),主要分析IP层及TCP/UDP层,实现四层负载均衡。此种负载均衡器不理解应用协议(如HTTP/FTP/MySQL等等)要处理的流量进行NAT处理,转发至后台服务器,并记录下这个TCP或者UDP的流量是由哪台服务器处理的,后续这个连接的所有流量都同样转发到同一台服务器处理。
实现四层负载均衡的软件有:
基于虚拟的URL或主机IP的负载均衡
所谓七层负载均衡,也称为“内容交换”,也就是主要通过报文中的真正有意义的应用层内容,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。
layer7
在四层负载均衡的基础上(没有四层是绝对不可能有七层的),再考虑应用层的特征,比如同一个Web服务器的负载均衡,除了根据VIP加80端口辨别是否需要处理的流量,还可根据七层的URL、浏览器类别、语言来决定是否要进行负载均衡。举个例子,如果你的Web服务器分成两组,一组是中文语言的,一组是英文语言的,那么七层负载均衡就可以当用户来访问你的域名时,自动辨别用户语言,然后选择对应的语言服务器组进行负载均衡处理。
以常见的TCP为例,负载均衡设备如果要根据真正的应用层内容再选择服务器,只能先代理最终的服务器和客户端建立连接(三次握手)后,才可能接受到客户端发送的真正应用层内容的报文,然后再根据该报文中的特定字段,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。负载均衡设备在这种情况下,更类似于一个代理服务器。负载均衡和前端的客户端以及后端的服务器会分别建立TCP连接。所以从这个技术原理上来看,七层负载均衡明显的对负载均衡设备的要求更高,处理七层的能力也必然会低于四层模式的部署方式。
对应的负载均衡器称为七层交换机(L7switch),除了支持四层负载均衡以外,还有分析应用层的信息,如HTTP协议URI或Cookie信息,实现七层负载均衡。此种负载均衡器能理解应用协议。
实现七层负载均衡的软件有:
四层负载均衡就像银行的自助排号机,每一个达到银行的客户根据排号机的顺序,选择对应的窗口接受服务;而七层负载均衡像银行大堂经理,先确认客户需要办理的业务,再安排排号。这样办理理财、存取款等业务的客户会根据银行内部资源得到统一协调处理,加快客户业务办理流程。
| 四层负载均衡(layer4) | 七层负载均衡(layer7) | |
|---|---|---|
| 基于 | 基于IPPort | URL |
| 类似于 | 路由器 | 代理服务器 |
| 握手次数 | 1次 | 2次 |
| 复杂度 | 低 | 高 |
| 性能 | 高;无需解析内容 | 中,需要算法识别URL,Cookie和HTTPhead等信息 |
| 安全性 | 低,无法识别DDoS等攻击 | 高,可以防御SYNcookie以SYNflood等 |
| 额外功能 | 无 | 会话保持,图片压缩,防盗链等 |
从上面的对比看来四层负载与七层负载最大的区别就是效率与功能的区别。四层负载架构设计比较简单,无需解析具体的消息内容,在网络吞吐量及处理能力上会相对比较高,而七层负载均衡的优势则体现在功能多,控制灵活强大。在具体业务架构设计时,使用七层负载或者四层负载还得根据具体的情况综合考虑。

若有收获,就点个赞吧
0 人点赞
