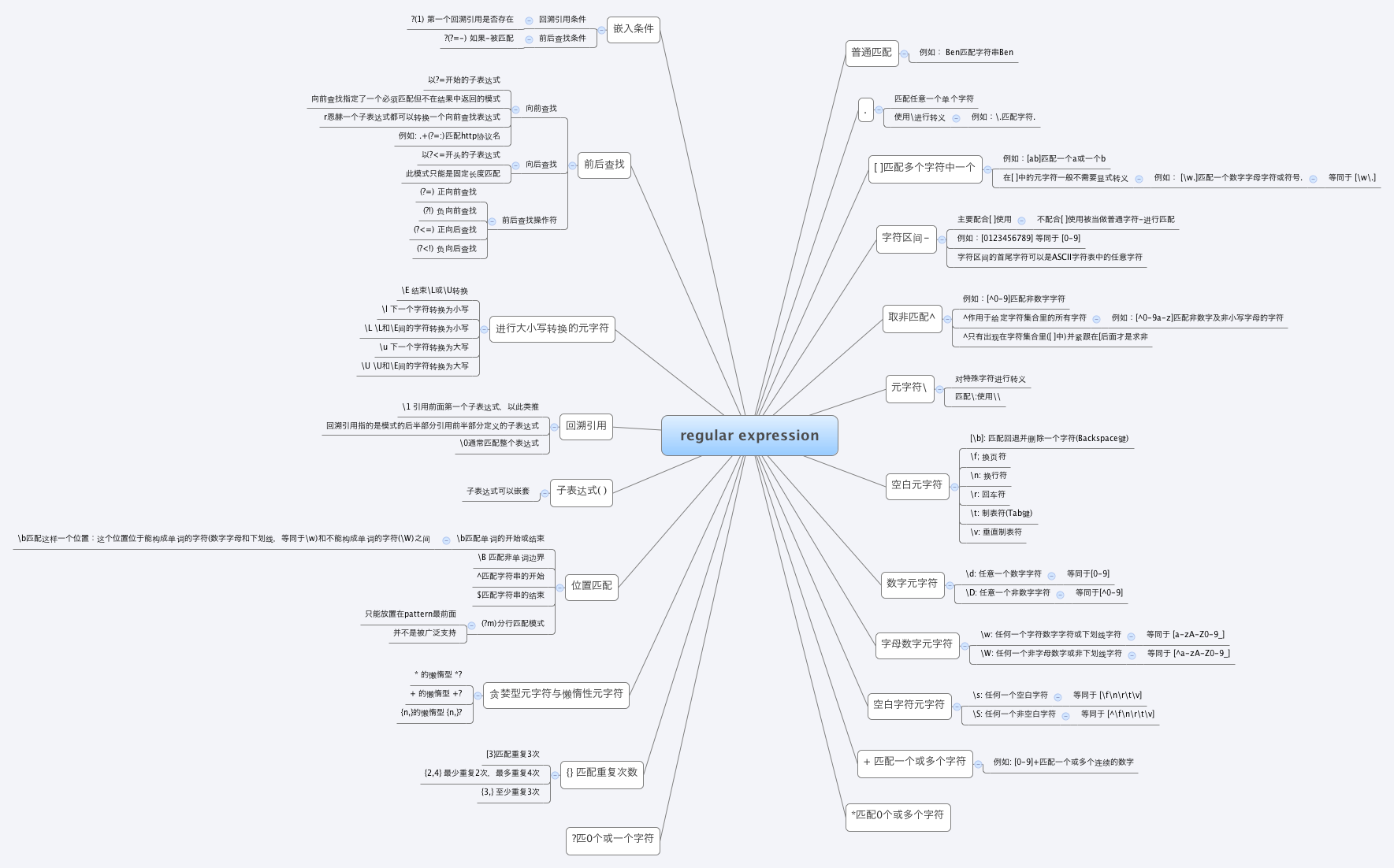
正则表达式
动机
- 文本处理已经能称为计算机常见工作之一
- 应对文本内容的搜索,定位,提取时逻辑比较复杂的情况
- 为了快速方便的解决上述问题,产生了正则表达式
简介
定义:即文本的高级匹配模式,提供搜索,替换等功能。其本质是由一系列字符和特殊符号构成的字符串,这个字符串即正则表达式
原理:通过特殊符号(元字符)去描述字符的组成规则,比如重复,位置等,来表达一类字符串,进而匹配。
元字符的使用
- 普通字符
匹配规则:每个普通字符匹配对应字符
注意:可以匹配utf-8字符
- 匹配两侧
元字符:|
匹配规则:匹配| 两侧任意正则表达式
- 匹配单个字符
元字符: .
匹配规则:匹配除换行外任意一个字符
- 匹配字符集
元字符: [字符集]
匹配规则:匹配字符集中任意一个字符
表达形式:[字符] [字符区间] [字符集字符区间] —字符区间写在后面
- 匹配字符集取反
元字符:[^字符集]
匹配规则:除了字符集外的任意一个字符
- 匹配字符串开始位置
元字符:^写在正则表达式开始处
匹配规则:匹配字符串开始位置
- 匹配字符串结束位置
元字符:$写在正则表达式结尾处
匹配规则:匹配字符串结束位置
- 匹配字符重复
元字符:*
匹配规则:匹配前面的字符出现0次或多次
元字符:+
匹配规则:匹配前面的字符出现1次或者多次
元字符:?
匹配规则:匹配前面的字符出现0次或者1次
元字符:{n}
匹配规则:匹配前面的字符出现了n次
元字符:{m,n}
匹配规则:匹配前面的字符出现了m-n次
9.匹配任意(非)数字字符
元字符:\d \D
匹配规则:\d 匹配任意数字字符 ==>[0-9]
\D 匹配任意非数字字符 ==>[^0-9]
10.匹配任意(非)普通字符
元字符:\w \W
匹配规则:\w 匹配普通字符
\W 匹配非普通字符
说明:普通字符指,数字,字母,下划线,汉字 普通utf-8字符
- 匹配任意(非)空字符
元字符:\s \S
匹配规则: \s 匹配任意空字符
\S 匹配任意非空字符
说明:空字符指 空格 \n \t \v \f
- 匹配字符串开头结尾位置
元字符:\A \Z
匹配规则:\A ==> ^
\Z ==> $
使用技巧:如果正则表达式中同时出现^ $,则两者之间的正则表达式需要将目标字符串内容全部匹配
- 匹配单词(非)边界位置
元字符:\b \B
匹配规则:单词边界指普通字符(\w代表的字符)与其他字符的交界位置
匹配字符:. […] [^…] \d \D \w \W \s \S
匹配重复: * + ? {n} {m,n}
匹配位置: ^ $ \A \Z \v \B
其他: | ( ) \
元字符的使用
- 如果使用正则表达式匹配特殊字符,需要加\ 表示转义
特殊字符: . * + ? ^ $ [] { } ( ) | \
- raw字符串:在字符串前加r,表示该字符串为raw字符串,这样的字符串不会进行字符串转义处理。
贪婪与非贪婪
贪婪模式:默认情况下,匹配重复的元字符总是竟可能多的向后匹配更多内容。
非贪婪模式(懒惰):让重复元字符尽可能少的匹配内容 元字符后+?贪婪—>非贪婪
正则表达式分组
- 定义:在正则表达式中,以()建立正则表达式内部分组,子组是正则表达式的一部分,可作为内部整体操作。
- 作用:作为内部整体,改变元字符的操作对象。
- 捕获组:给正则表达式子组起一个名字,表达一定的意义,该组就是捕获组。
格式:(?P
- 注意事项:一个正则表达式中可以有多个分组
子组可以嵌套
引用
通过默认分组编号进行后向引用
re.search(r’(go)\s+\1\s+\1’, ‘go go go’).group() ‘go go go’
交换 字符串位置
s = ‘abc.xyz’ re.sub(r’(.).(.)’, r’\2.\1’, s) ‘xyz.abc
正则表达式原则
- 正确性:能够正确的匹配出目标字字符串
- 排他性:除了目标字符串外尽可能不匹配其他内容
- 全面性:尽可能考虑到目标字符串所有情况,不遗漏

若有收获,就点个赞吧
0 人点赞
