1、树结构实际应用
1.1、堆排序
1.1.1、堆排序的介绍
- 1) 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。
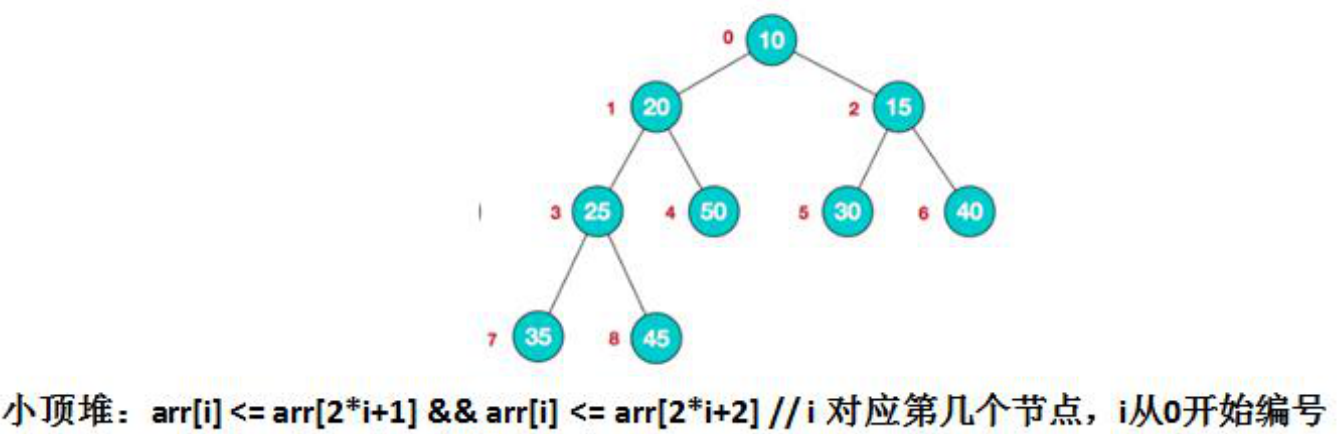
- 2) 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆,注意:没有要求结点的左孩子的值和右孩子的值的大小关系。
- 3) 每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
- 4)大顶堆距离说明

- 5)小顶堆说明
-
1.1.2、堆排序基本思想
堆排序的基本思想:
1)将待排序序列构造成一个大顶堆
- 2)此时,整个序列的最大值就是堆顶的根节点
- 3)将其与末尾元素进行交换,此时末尾就为最大值。
4)然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了
1.1.3、图解说明
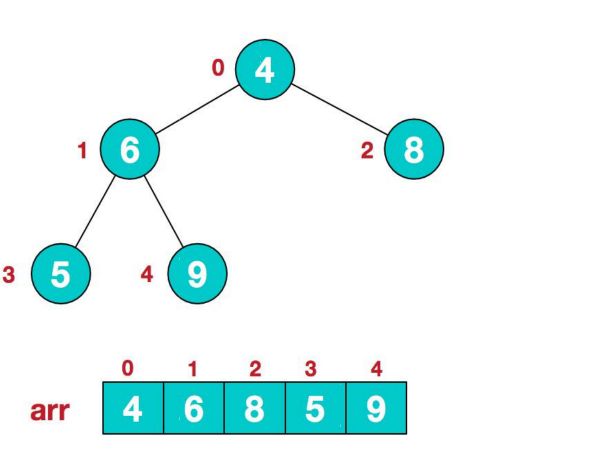
给你一个数组{4,6,8,5,9},要求使用堆排序法,将素组升序排序
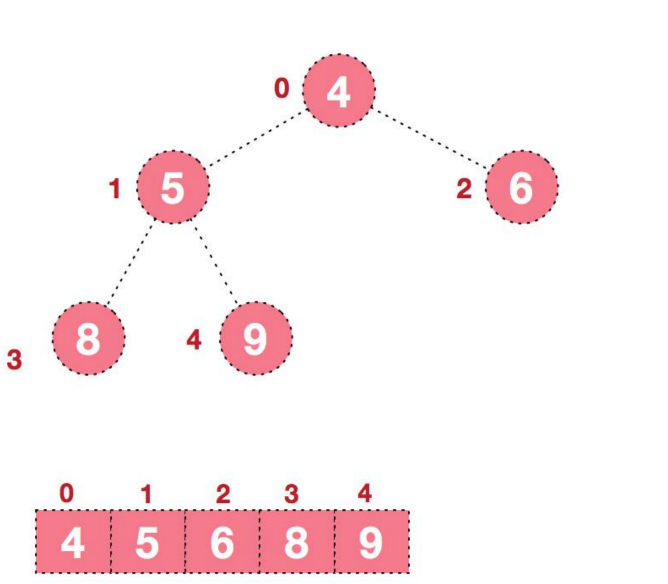
1.1.3.1、步骤一构造初始堆。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。原始的数组[4,6,8,5,9]
1、假设给定无序序列结构如下
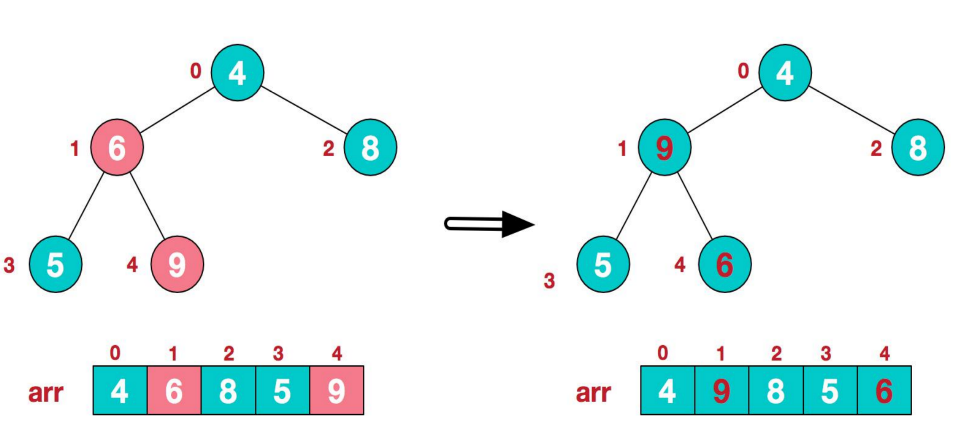
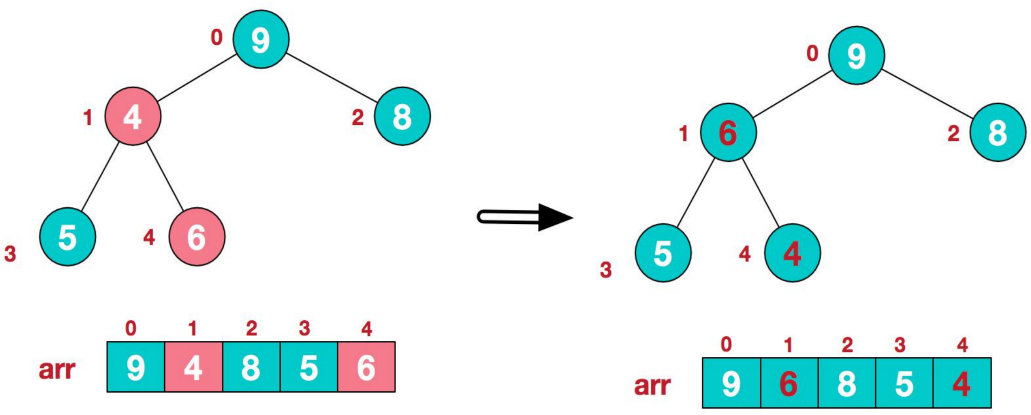
2、此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。
3、找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换。
4、这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。
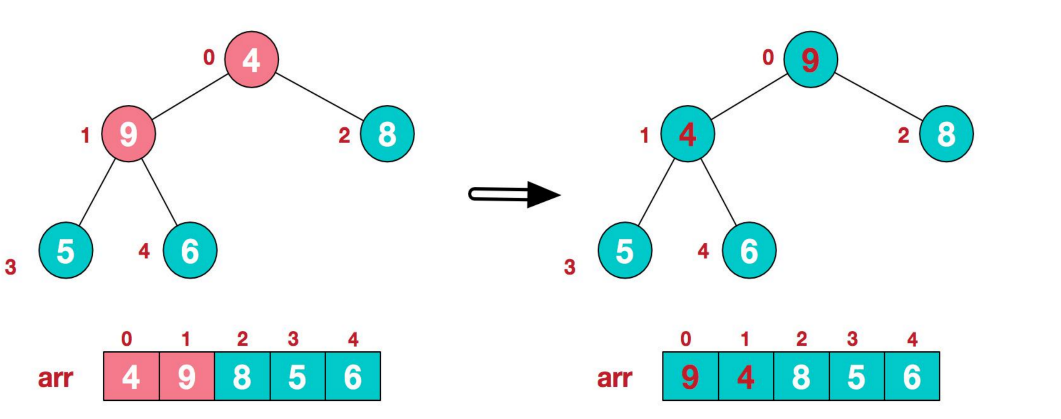
1.1.3.2、步骤二将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换得到第二大元素。如此反复进行交换、重建、交换。
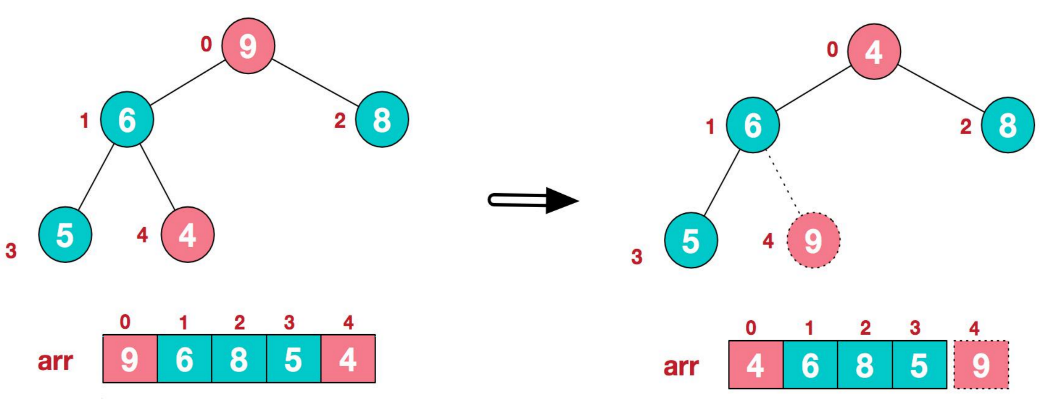
1、将堆顶元素9和末尾元素4进行交换
2、重新调整结构,使其继续满足堆定义
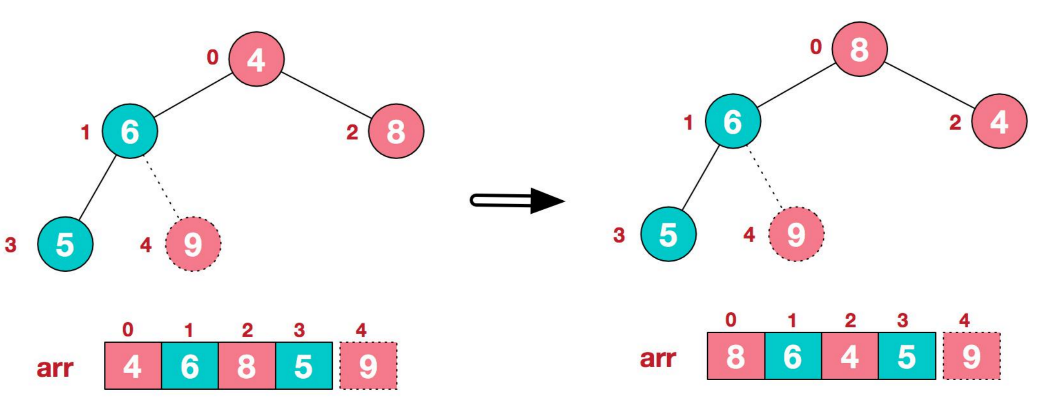
3、再将堆顶元素8与末尾元素5进行交换,得到第二个大元素8
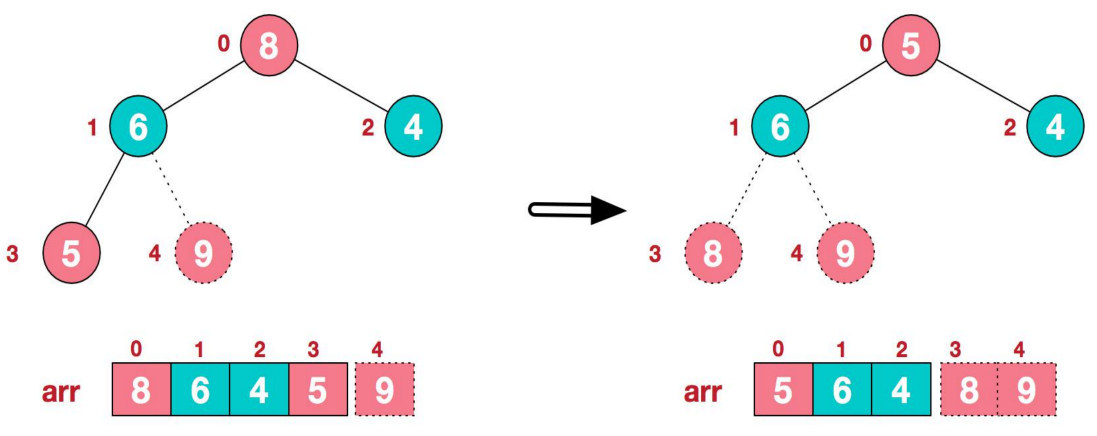
4、后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
1.1.3.3、再简单总结下堆排序的基本思路:
1).将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆
- 2).将堆顶元素与末尾元素交换,将最大元素”沉”到数组未端:
3)重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前未尾元素,反复执行调整+交换步骤直到整个序列有序。
1.1.4、代码实现
1.1.4.1、创建HeadSort
关键代码adjustHead
根据某个非叶子节点进行调整为大顶堆 ```java public class HeadSort implements Sort {
/**
- 堆排序升序,使用大顶堆, 大顶堆就是 非叶子节点,大于他的两个子节点,最顶部的是最大的值 实现思路 把数组整理成一个大顶堆,从最左边的的最底部的非叶子节点开始整理,
- 成为大顶堆之后,把最顶部的数和数组的最后一个数进行置换,然后再重新进行整理
- @param source
- @param
*/ @Override public > void sort(T[] source) { //1、调整为大顶堆,从最左边的最底部的非叶子节点开始 for (int i = source.length / 2 - 1; i >= 0; i—) {
} //2,进行交换,再调整为大顶堆 for (int length = source.length - 1; length > 0; length—) {adjustHead(source, i, source.length);
} }T tmp = source[length]; source[length] = source[0]; source[0] = tmp; adjustHead(source,0,length);
/**
- 以某个非叶子节点进行整理
- @param source
- @param i
- @param length
- @param
/ public > void adjustHead(T[] source, int i, int length) { T temp = source[i]; //左子节点 //从当前给的非叶子节点的左节点遍历到当前节点的下一个叶子节点 for (int k = 2 i + 1; k < length; k = k * 2 + 1) {
} source[i] = temp; } }//k+1 为i的下边的右节点。如果当前是左节点小于右节点,那就让右边的节点和非叶子节点进行进行比较 if (k + 1 < length && source[k].compareTo(source[k + 1]) < 0) { k++; } //如果非叶子节点小于下边比较大的子节点,就相互交换,并且赋值新位置 if (temp.compareTo(source[k]) < 0) { source[i] = source[k]; i = k; } else { //因为我们的原则是从最底部的左边的非叶子节点开始的,所以此处就可以直接break break; }
<a name="ELhD0"></a>
#### 1.1.4.2、测试
```java
class HeadSortMain {
public static void main(String[] args) {
HeadSort headSort = new HeadSort();
Integer[] waitSortArray = {4, 6, 8, 5, 9,-1,800,-20,30};
headSort.sort(waitSortArray);
System.out.println("排序完结果:");
for (int i=0;i<waitSortArray.length;i++){
System.out.print(waitSortArray[i]+",");
}
}
}
调试结果
排序完结果: -20,-1,4,5,6,8,9,30,800,1.1.4.3、性能测试
class HeadSortMain { public static void main(String[] args) { HeadSort headSort = new HeadSort(); //1万数据测试 SortUtil.sort(headSort,10000); //10万数据测试 SortUtil.sort(headSort,100000); //100万数据测试 SortUtil.sort(headSort,1000000); //800万数据 SortUtil.bigTest(headSort); } }性能测试结果
com.daijunyi.structure.sort.HeadSort:10000个数据排序时间:0秒5毫秒 com.daijunyi.structure.sort.HeadSort:100000个数据排序时间:0秒31毫秒 com.daijunyi.structure.sort.HeadSort:1000000个数据排序时间:0秒582毫秒 开始排序8000000个数据 排序时间:7秒性能测试总结 | | 1万数据 | 10万 | 100万 | 800万 | | —- | —- | —- | —- | —- | | 堆排序 | 5毫秒 | 31毫秒 | 582毫秒 | 7秒 |
1.2、赫夫曼树
1.2.1、基本介绍
- 1)给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度(p)达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Iuffman Tree),还有的书翻译为霍夫曼树。
-
1.2.2、赫夫曼树几个重要概念和举例说明
1.2.2.1、路径和路径长度
在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1
1.2.2.2、结点的权及带权路径长度:
若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积
1.2.2.3、树的带权路径长度:
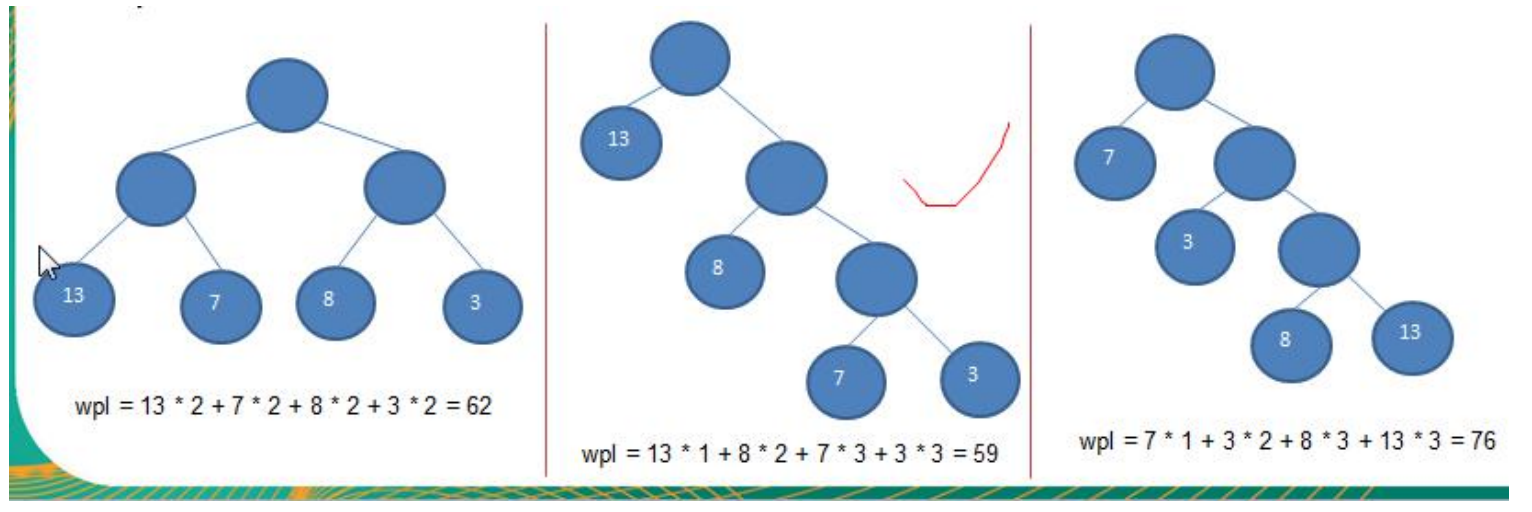
树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL(weighted path length),权值越大的结点离根结点越近的二叉树才是最优二叉树。
1.2.2.4、WPL最小的就是赫夫曼树
1.2.3、赫夫曼树创建图解
给你一个数列{13,7,8,3,29,6,1},要求转成一颗赫夫曼树
1.2.3.1、构建赫夫曼树的步骤
1)从小到大进行排序,将每一个数据,每个数据都是一个节点,每个节点可以看成是一颗最简单的二义树
- 2)取出根节点权值最小的两颗二叉树
- 3)组成一颗新的二叉树,该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和
4)再将这颗新的二叉树,以根节点的权值大小再次排序,不断重复1-23-4的步骤,直到数列中,所有的数据都被处理,就得到一颗赫夫曼树
1.2.3.2、图解
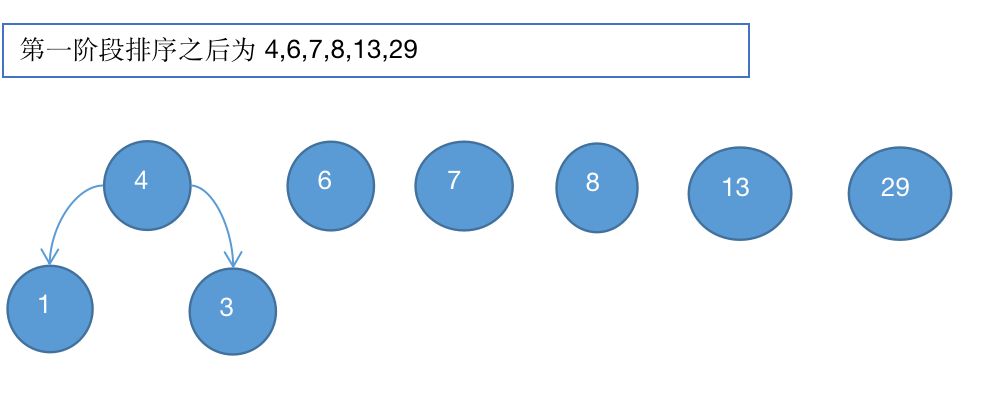
1、排序
2、取出根节点全职最小的两颗1和3进行组成二叉树
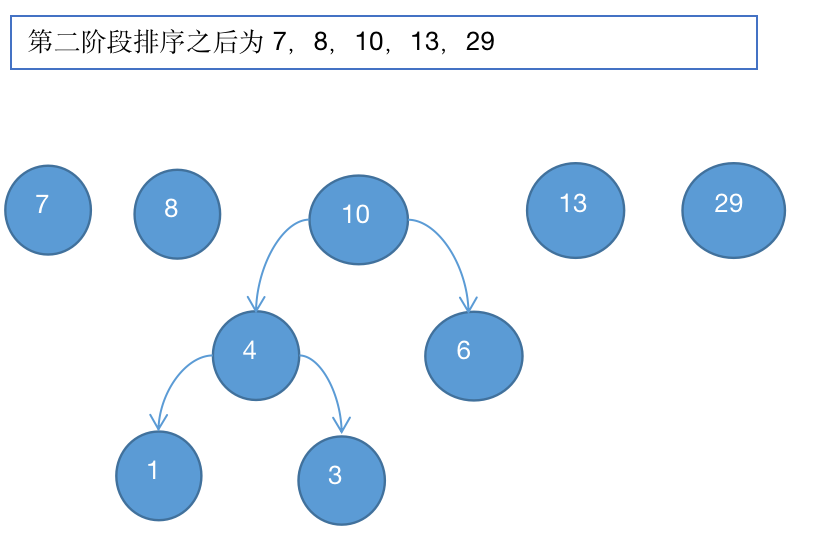
3、取出4和6进行组成新的二叉树
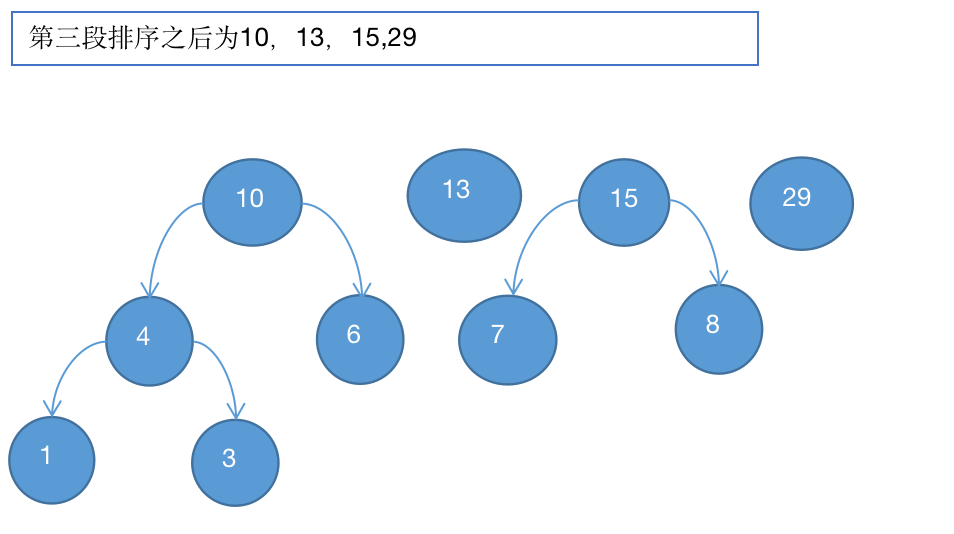
4、取出7和8组成新二叉树
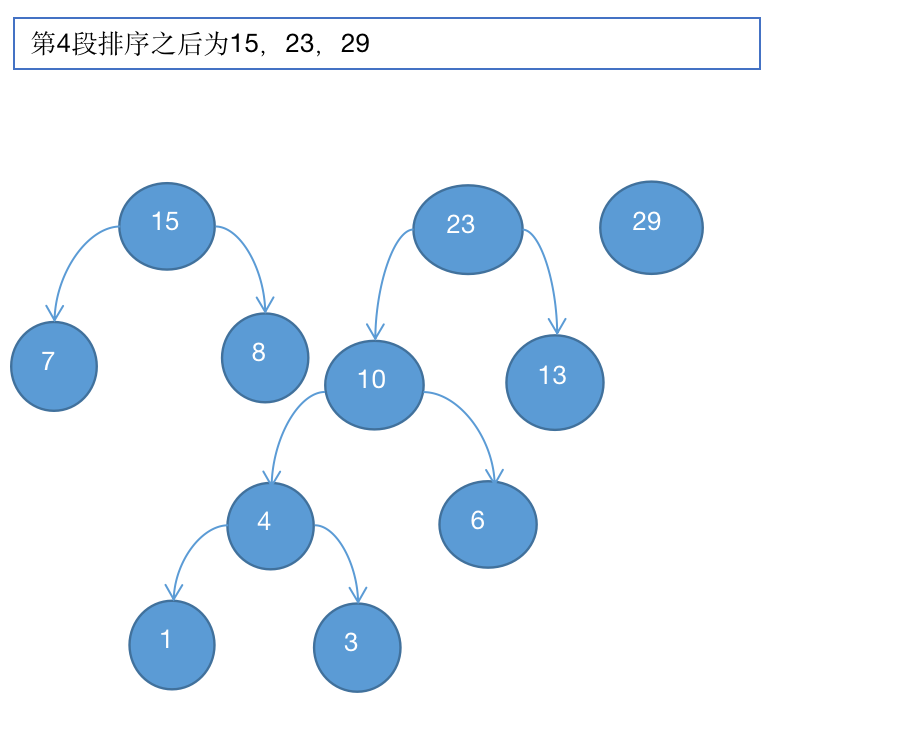
5、取出10和13
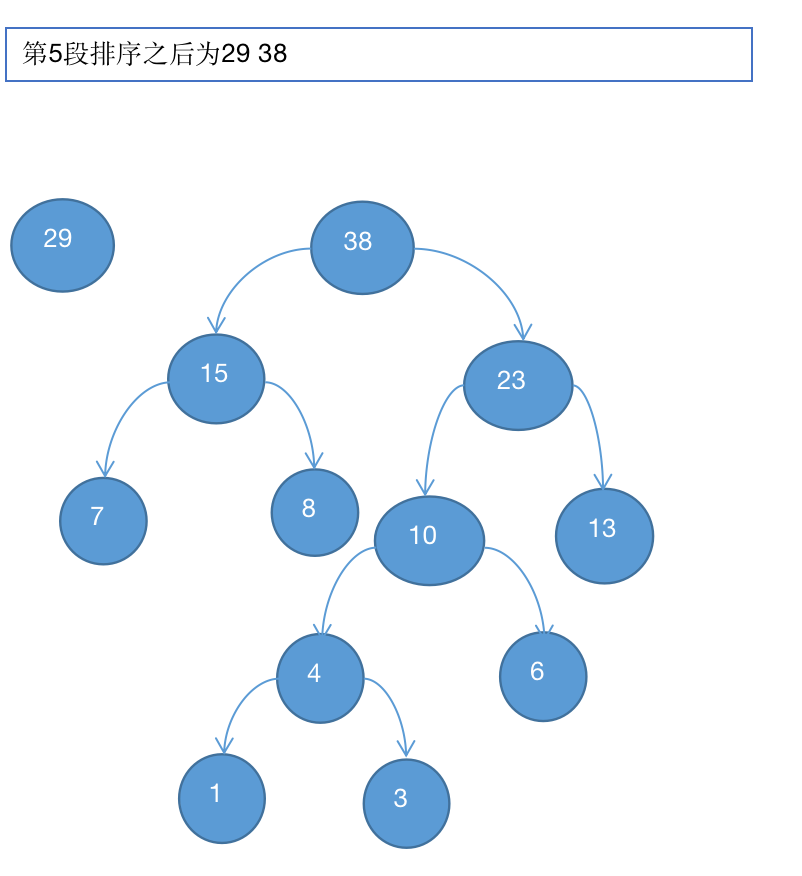
6、取出15和23
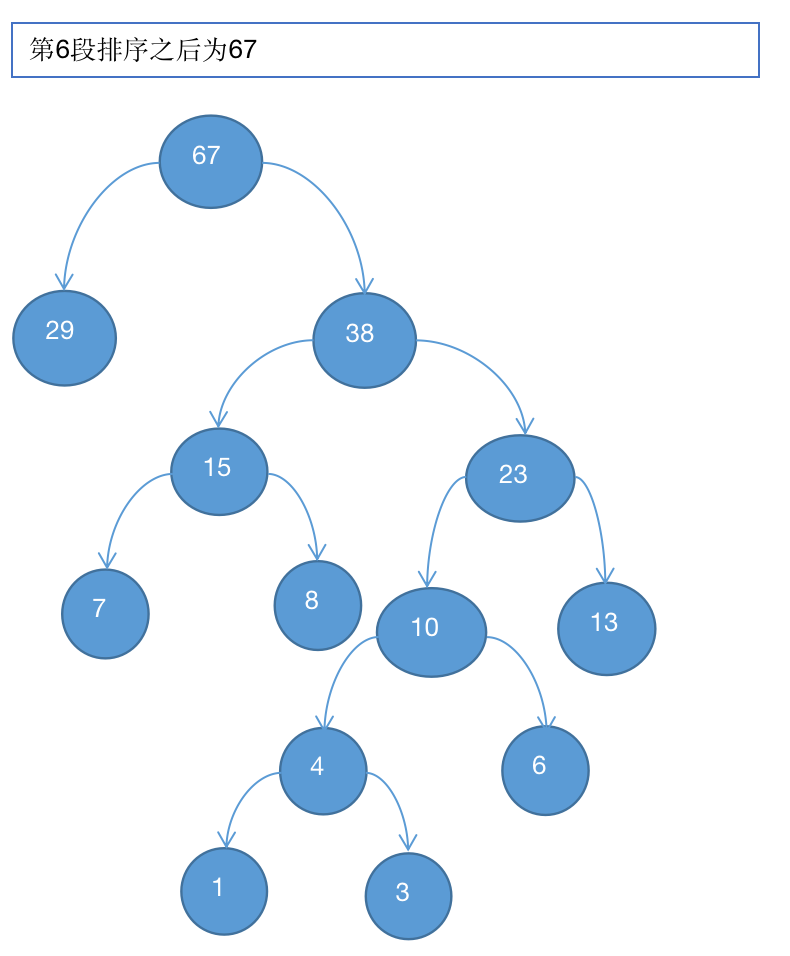
7、最终29和38结合组成赫夫曼树
1.2.4、代码实现
1、创建node类
class HuffmanNode implements Comparable<HuffmanNode> { public HuffmanNode(int value) { this.value = value; } private int value; private HuffmanNode left; private HuffmanNode right; public int getValue() { return value; } public HuffmanNode getLeft() { return left; } public void setLeft(HuffmanNode left) { this.left = left; } public HuffmanNode getRight() { return right; } public void setRight(HuffmanNode right) { this.right = right; } @Override public int compareTo(HuffmanNode o) { return this.value - o.value; } @Override public String toString() { return "HuffmanNode{" + "value=" + value + '}'; } }2、实现创建赫夫曼
/** * 赫夫曼树构建类 */ public class HuffmanTree { /** * 获取赫夫曼二叉树 * @param array * @return */ public static HuffmanNode getHuffmanNode(int[] array) { if (array == null || array.length == 0) { throw new IllegalArgumentException("参数非法"); } //第一步把数组转换成node节点 ArrayList<HuffmanNode> list = new ArrayList<>(); for (int i = 0; i < array.length; i++) { list.add(new HuffmanNode(array[i])); } Collections.sort(list); //只要集合结果大于1就可以再次循环 System.out.println("排序之后结果:" + list); int index = 0; while (list.size() > 1) { index++; //开始组成哈夫曼树 HuffmanNode leftNode = list.get(0); HuffmanNode rightNode = list.get(1); HuffmanNode parentNode = new HuffmanNode(leftNode.getValue() + rightNode.getValue()); parentNode.setLeft(leftNode); parentNode.setRight(rightNode); //删除原来集合总的前两个数据,并且添加新的根节点 list.remove(leftNode); list.remove(rightNode); list.add(parentNode); Collections.sort(list); System.out.println("排序轮次" + index + "结果:" + list); } return list.get(0); } /** * 前序遍历 * @param node */ public static void preOrder(HuffmanNode node){ System.out.println("值:"+node.getValue()); if (node.getLeft() != null){ preOrder(node.getLeft()); } if (node.getRight() != null){ preOrder(node.getRight()); } } }3、测试
1、测试代码
```java /**
- @author djy
- @createTime 2022/5/18 下午4:03
- @description 赫夫曼树 */

class HuffmanTreeMain { public static void main(String[] args) { int[] array = {13, 7, 8, 3, 29, 6, 1}; HuffmanNode huffmanNode = HuffmanTree.getHuffmanNode(array); HuffmanTree.preOrder(huffmanNode); } }
<a name="FiL8X"></a>
##### 2、测试结果
- 打印结果
```shell
排序之后结果:[HuffmanNode{value=1}, HuffmanNode{value=3}, HuffmanNode{value=6}, HuffmanNode{value=7}, HuffmanNode{value=8}, HuffmanNode{value=13}, HuffmanNode{value=29}]
排序轮次1结果:[HuffmanNode{value=4}, HuffmanNode{value=6}, HuffmanNode{value=7}, HuffmanNode{value=8}, HuffmanNode{value=13}, HuffmanNode{value=29}]
排序轮次2结果:[HuffmanNode{value=7}, HuffmanNode{value=8}, HuffmanNode{value=10}, HuffmanNode{value=13}, HuffmanNode{value=29}]
排序轮次3结果:[HuffmanNode{value=10}, HuffmanNode{value=13}, HuffmanNode{value=15}, HuffmanNode{value=29}]
排序轮次4结果:[HuffmanNode{value=15}, HuffmanNode{value=23}, HuffmanNode{value=29}]
排序轮次5结果:[HuffmanNode{value=29}, HuffmanNode{value=38}]
排序轮次6结果:[HuffmanNode{value=67}]
值:67
值:29
值:38
值:15
值:7
值:8
值:23
值:10
值:4
值:1
值:3
值:6
值:13
Process finished with exit code 0
1.3、赫夫曼编码
1、基本介绍
- 1)赫夫曼编码也翻译为哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,属于一种程序算法
- 2)赫夫曼编码是赫哈夫曼树在电讯通信中的经典的应用之一。
- 3)赫夫曼编码广泛地用于数据文件压缩。其压缩率通常在20%~90%之间
4)赫夫曼码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,称之为最佳编码
2、原理剖析
1、通信领域中信息的处理方式1-定长编码
i like like like java do you like a java

2、通信领域中信息的处理方式2变长编码

3、通信领域中信息的处理方式3-赫夫曼编码
1、原理
- 1)i like like like java do you like a java
- 2)d:1y:1u:1j2V:2o:21:4k:4e:4i:5a:5:9/各个字符对应的个数
- 3)按照上面字符出现的次数构建一颗赫夫曼树,次数作为权值
- 构建赫夫曼树步骤
- 1)从小到大进行排序,将每一个数据,每个数据都是一个节点,每个节点可以看成是一颗最简单的二叉树
- 2)取出根节点权值最小的两颗二叉树
- 3)组成一颗新的二叉树,该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和
- 4)再将这颗新的二叉树,以根节点的权值大小再次排序,不断重复1-2-3-4的步骤,直到数列中,所有的数据都被处理,就得到一颗赫夫曼树
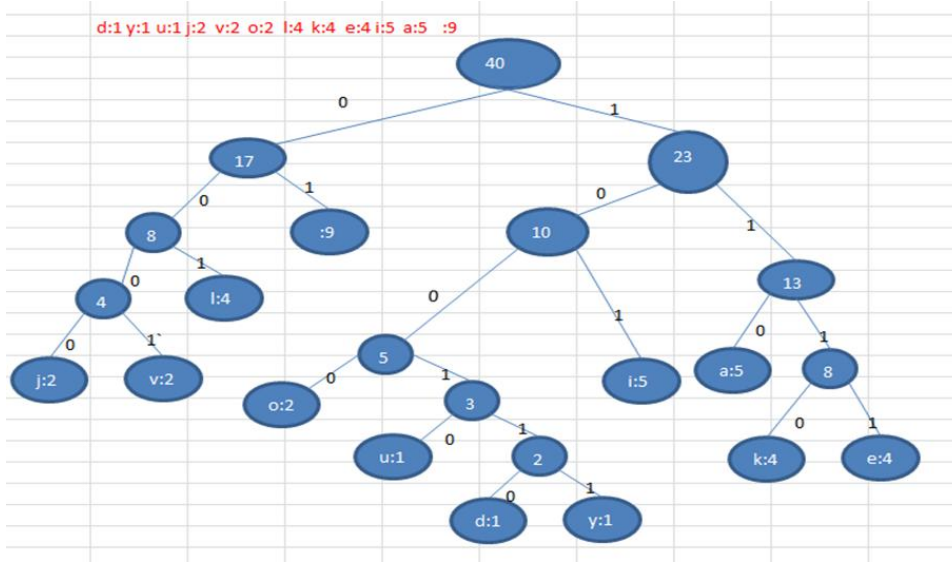
- 构建赫夫曼树步骤
- 4)根据赫夫曼树,给各个字符,规定编码(前缀编码),向左的路径为0向右的路径为1,编码
- 如下:
- 0:1000
- u:10010
- d:100110y:100111i:101
- a:110
- k:1110
- e:1111
- j:0000
- v:0001
- l:001
- :01
- 如下:
- 5)按照上面的赫夫曼编码,我们的”i like like like java do you like a java”字符串对应的编码为(注意这里我们使用的无损压缩)
- 1010100110111101111010011011110111101001101111011110100001100001110011001111000011001111000100100100110111101111011100100001100001110
- 通过赫夫曼编码处理长度为133
6)长度为:133
- 说明:
- 原来长度是359,压缩了(359-133)/359=62.9%
- 此编码满足前缀编码,即字符的编码都不能是其他字符编码的前缀。不会造成匹配的多义性赫夫曼编码是无损处理方案
2、注意事项
注意,这个赫夫曼树根据排序方法不同,也可能不太一样,这样对应的赫夫曼编码也不完全一样,但是wpl是一样的,都是最小的,最后生成的赫夫曼编码的长度是一样,比如:如果我们让每次生成的新的二叉树总是排在权值相同的二叉树的最后一个,则生成的二叉树为: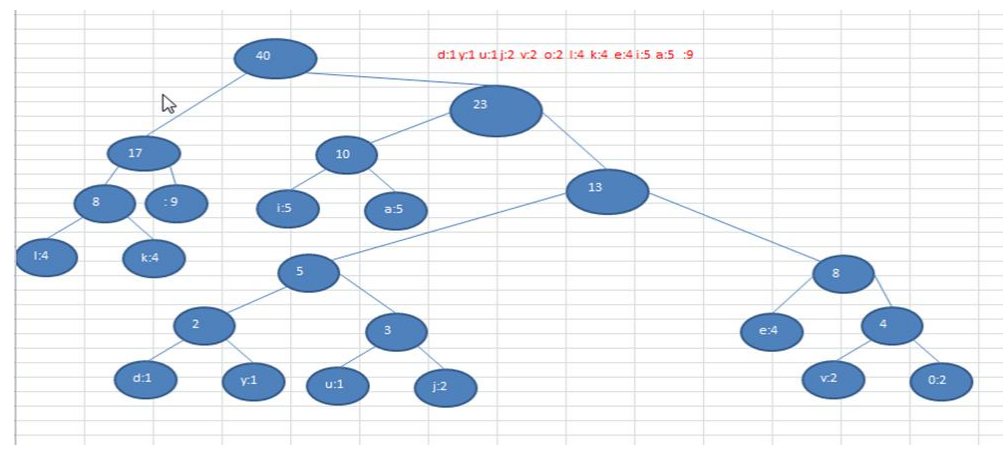
3、最佳实践-数据压缩和解压缩
将给出的一段文本,比如”i like likelike java do you like a java’”,根据前面的讲的赫夫曼编码原理,对其进行数据压缩处理形式如
10101001101111011110100110111101111010011011110111101000011000011100110011110000110011110001001001001101111011110111001000011000011101、数据压缩
1、实现步骤
计算每个字节出现的次数,统计出现的次数,生成统计的map
- 根据这个map生成node节点列表,出现次数为权重(weight)
- 对node节点列表进行生成赫夫曼树
- 根据赫夫曼树进行生成新的前缀匹配编码表。
根据编码生成压缩后的字符串,字符串中只有0和1,对新字符串,重新进行一个字节的数据转换。变成新的字节数组。此字节数组就是压缩后的数据。
2、节点对象
/** * 赫夫曼的内部节点对象 */ static class Node implements Comparable<Node> { public Node(Byte data, int weight) { this.data = data; this.weight = weight; } private Byte data; private int weight; private Node left; private Node right; public int getWeight() { return weight; } public Byte getData() { return data; } public Node getLeft() { return left; } public void setLeft(Node left) { this.left = left; } public Node getRight() { return right; } public void setRight(Node right) { this.right = right; } @Override public int compareTo(Node o) { return this.weight - o.weight; } @Override public String toString() { return "Node{" + "data=" + data + ", weight=" + weight + '}'; } }3、统计节点出现的次数,并生成node列表
/** * 根据原始数据生成数据出现的次数节点 * @param bytes * @return */ private static List<Node> getNodes(byte[] bytes) { ArrayList<Node> nodes = new ArrayList<>(); HashMap<Byte, Integer> weights = new HashMap<>(); for (byte b : bytes) { if (weights.get(b) == null) { weights.put(b, 1); } else { weights.put(b, weights.get(b) + 1); } } Set<Map.Entry<Byte, Integer>> entries = weights.entrySet(); for (Map.Entry<Byte, Integer> entry : entries) { nodes.add(new Node(entry.getKey(), entry.getValue())); } return nodes; }4、生成赫夫曼树
/** * 获取赫夫曼树 * @param bytes 原始数据 * @return */ private static Node getHuffmanTree(byte[] bytes) { //找出出现的次数,并生成节点 List<Node> nodes = getNodes(bytes); //根据出现的次数构建赫夫曼树 while (nodes.size() > 1) { Collections.sort(nodes); Node leftNode = nodes.get(0); Node rightNode = nodes.get(1); Node parentNode = new Node(null, leftNode.getWeight() + rightNode.getWeight()); parentNode.setLeft(leftNode); parentNode.setRight(rightNode); nodes.remove(leftNode); nodes.remove(rightNode); nodes.add(parentNode); } return nodes.get(0); }5、生成赫夫曼编码
根据赫夫曼tree生成赫夫曼编码
向左节点查找为0向右节点查找为1
/** * 获取赫夫曼编码表 * @param root 赫夫曼树根节点 * @return */ public static Map<Byte, String> getHuffmanCode(Node root) { HashMap<Byte, String> code = new HashMap<>(); buildCode(code, root, "", new StringBuilder()); return code; } /** * 递归构建赫夫曼编码 * @param code * @param node * @param path * @param lastPath */ public static void buildCode(HashMap<Byte, String> code, Node node, String path, StringBuilder lastPath) { if (node != null) { StringBuilder newString = new StringBuilder(lastPath).append(path); if (node.getData() == null) { //说明不是叶子节点 buildCode(code, node.getLeft(), "0", newString); buildCode(code, node.getRight(), "1", newString); } else { code.put(node.getData(), newString.toString()); } } }6、压缩数据
/** * 根据赫夫曼编码表进行压缩字节 * @param bytes * @param huffmanCode */ private static byte[] byteZip(byte[] bytes, Map<Byte, String> huffmanCode) { StringBuilder zipString = new StringBuilder(); for (byte b : bytes) { zipString.append(huffmanCode.get(b)); } //根据新的字符串,转成新的字节数组 int len = (zipString.length() + 7) / 8; byte[] zipBytes = new byte[len]; for (int i = 0; i < len; i++) { int startIndex = i * 8; String cutString = i == len - 1 ? zipString.substring(startIndex) : zipString.substring(startIndex, startIndex + 8); zipBytes[i] = (byte) Integer.parseInt(cutString, 2); } return zipBytes; }2、数据解压
1、实现步骤
此处得在有赫夫曼编码的情况下进行
- 把字节数组转成字符串。
- 对赫夫曼编码表进行反正从Map
-
2、字节数组转成字符串
/** * 把byte数据转换成编码的字符串 * @param bytes */ private static String getCodeStr(byte[] bytes) { StringBuilder stringBuilder = new StringBuilder(); //先转会一个字符串 for (int i = 0; i < bytes.length; i++) { int b = bytes[i]; if (i != bytes.length - 1) { //此处主要是为了 比如 int为 3 的时候 直接转成二进制字符串会是 11 //256 二进制是 100000000 和11 | 成为 100000011 b = b | 256; } String binStr = Integer.toBinaryString(b); if (i != bytes.length - 1) { binStr = binStr.substring(binStr.length() - 8); } stringBuilder.append(binStr); } return stringBuilder.toString(); }3、翻转编码表
/** * 获取反向的编码表 * @param code * @return */ private static HashMap<String, Byte> getReversedHuffmanCode(Map<Byte, String> code) { HashMap<String, Byte> reversedCode = new HashMap<>(); for (Map.Entry<Byte, String> entry : code.entrySet()) { reversedCode.put(entry.getValue(), entry.getKey()); } return reversedCode; }4、重新匹配获取原来的自己数组
/** * 根据反向编码表获取原始byte数据 * @param codeStr * @param reversedCode * @return */ private static byte[] getSourceBytes(String codeStr, HashMap<String, Byte> reversedCode) { ArrayList<Byte> sourceArray = new ArrayList<>(); //进行匹配 for (int i = 0; i < codeStr.length();) { int count = 1; boolean find = false; Byte aByte = null; while (!find){ String subStr = codeStr.substring(i, i + count); aByte = reversedCode.get(subStr); if (aByte == null){ count++; }else{ find = true; } } i += count; sourceArray.add(aByte); } byte[] sourceBytes = new byte[sourceArray.size()]; for (int i=0;i<sourceArray.size();i++){ sourceBytes[i] = sourceArray.get(i); } return sourceBytes; }5、最终合成解压缩
/** * 解压缩 * @param bytes * @param code * @return */ public static byte[] byteUnzip(byte[] bytes, Map<Byte, String> code) { //获取编码的字符串 String codeStr = getCodeStr(bytes); //把编码表反向存储为key为编码,值为数据 HashMap<String, Byte> reversedCode = getReversedHuffmanCode(code); byte[] sourceBytes = getSourceBytes(codeStr, reversedCode); return sourceBytes; }3、完整的代码
1、代码
```java
/**
- @author djy
- @createTime 2022/5/19 下午3:21
@description 赫夫曼编码 */ public class HuffmanCode {
/**
- 使用赫夫曼进行数据压缩
- @param bytes
@return */ public static void huffmanZipTest(byte[] bytes) { if (bytes == null || bytes.length == 0) {
throw new IllegalArgumentException("参数异常");} System.out.println(“压缩前的字符串数据:”+new String(bytes)); System.out.println(“压缩前的数据” + Arrays.toString(bytes)); //生成赫夫曼树 Node huffmanTree = getHuffmanTree(bytes); //生成赫夫曼编码 Map
/**
- 解压缩
- @param bytes
- @param code
@return */ public static byte[] byteUnzip(byte[] bytes, Map
/**
- 根据反向编码表获取原始byte数据
- @param codeStr
- @param reversedCode
@return */ private static byte[] getSourceBytes(String codeStr, HashMap
sourceArray = new ArrayList<>(); //进行匹配 for (int i = 0; i < codeStr.length();) { int count = 1; boolean find = false; Byte aByte = null; while (!find){ String subStr = codeStr.substring(i, i + count); aByte = reversedCode.get(subStr); if (aByte == null){ count++; }else{ find = true; } } i += count; sourceArray.add(aByte);}
byte[] sourceBytes = new byte[sourceArray.size()]; for (int i=0;i<sourceArray.size();i++){
sourceBytes[i] = sourceArray.get(i);} return sourceBytes; }
/**
- 获取反向的编码表
- @param code
@return */ private static HashMap
reversedCode.put(entry.getValue(), entry.getKey());} return reversedCode; }
/**
- 把byte数据转换成编码的字符串
@param bytes */ private static String getCodeStr(byte[] bytes) { StringBuilder stringBuilder = new StringBuilder(); //先转会一个字符串 for (int i = 0; i < bytes.length; i++) {
int b = bytes[i]; if (i != bytes.length - 1) { //此处主要是为了 比如 int为 3 的时候 直接转成二进制字符串会是 11 //256 二进制是 100000000 和11 | 成为 100000011 b = b | 256; } String binStr = Integer.toBinaryString(b); if (i != bytes.length - 1) { binStr = binStr.substring(binStr.length() - 8); } stringBuilder.append(binStr);} return stringBuilder.toString(); }
/**
- 根据赫夫曼编码表进行压缩字节
- @param bytes
@param huffmanCode */ private static byte[] byteZip(byte[] bytes, Map
zipString.append(huffmanCode.get(b));} //根据新的字符串,转成新的字节数组 int len = (zipString.length() + 7) / 8; byte[] zipBytes = new byte[len]; for (int i = 0; i < len; i++) {
int startIndex = i * 8; String cutString = i == len - 1 ? zipString.substring(startIndex) : zipString.substring(startIndex, startIndex + 8); zipBytes[i] = (byte) Integer.parseInt(cutString, 2);} return zipBytes; }
/**
- 获取赫夫曼编码表
- @param root 赫夫曼树根节点
@return */ public static Map
/**
- 递归构建赫夫曼编码
- @param code
- @param node
- @param path
@param lastPath */ public static void buildCode(HashMap
StringBuilder newString = new StringBuilder(lastPath).append(path); if (node.getData() == null) { //说明不是叶子节点 buildCode(code, node.getLeft(), "0", newString); buildCode(code, node.getRight(), "1", newString); } else { code.put(node.getData(), newString.toString()); }} }
/**
- 获取赫夫曼树
- @param bytes 原始数据
@return */ private static Node getHuffmanTree(byte[] bytes) { //找出出现的次数,并生成节点 List
nodes = getNodes(bytes); //根据出现的次数构建赫夫曼树 while (nodes.size() > 1) { Collections.sort(nodes); Node leftNode = nodes.get(0); Node rightNode = nodes.get(1); Node parentNode = new Node(null, leftNode.getWeight() + rightNode.getWeight()); parentNode.setLeft(leftNode); parentNode.setRight(rightNode); nodes.remove(leftNode); nodes.remove(rightNode); nodes.add(parentNode);} return nodes.get(0); }
/**
- 根据原始数据生成数据出现的次数节点
- @param bytes
@return */ private static List
getNodes(byte[] bytes) { ArrayList nodes = new ArrayList<>(); HashMap if (weights.get(b) == null) { weights.put(b, 1); } else { weights.put(b, weights.get(b) + 1); }} Set
nodes.add(new Node(entry.getKey(), entry.getValue()));} return nodes; }
/**
赫夫曼的内部节点对象 */ static class Node implements Comparable
{ public Node(Byte data, int weight) {
this.data = data; this.weight = weight;}
private Byte data; private int weight; private Node left; private Node right;
public int getWeight() {
return weight;}
public Byte getData() {
return data;}
public Node getLeft() {
return left;}
public void setLeft(Node left) {
this.left = left;}
public Node getRight() {
return right;}
public void setRight(Node right) {
this.right = right;}
@Override public int compareTo(Node o) {
return this.weight - o.weight;}
@Override public String toString() {
return "Node{" + "data=" + data + ", weight=" + weight + '}';} }
}
<a name="DIrna"></a>
##### 2、测试
```java
class HuffmanCodeMain {
public static void main(String[] args) {
String content = "i like like like java do you like a java";
byte[] preBytes = content.getBytes();
HuffmanCode.huffmanZipTest(preBytes);
}
}
3、打印结果
压缩前的字符串数据:i like like like java do you like a java
压缩前的数据[105, 32, 108, 105, 107, 101, 32, 108, 105, 107, 101, 32, 108, 105, 107, 101, 32, 106, 97, 118, 97, 32, 100, 111, 32, 121, 111, 117, 32, 108, 105, 107, 101, 32, 97, 32, 106, 97, 118, 97]
压缩后的数据[-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28]
解压后的数据[105, 32, 108, 105, 107, 101, 32, 108, 105, 107, 101, 32, 108, 105, 107, 101, 32, 106, 97, 118, 97, 32, 100, 111, 32, 121, 111, 117, 32, 108, 105, 107, 101, 32, 97, 32, 106, 97, 118, 97]
解压的字符串数据:i like like like java do you like a java
4、文件压缩和解压
1、压缩文件
/**
* 压缩文件
* @param inputPath 输入文件
* @param targetPath 输出文件
*/
public static void zipFile(String inputPath, String targetPath) {
InputStream io = null;
FileOutputStream os = null;
ObjectOutputStream oos = null;
try {
io = new FileInputStream(new File(inputPath));
byte[] b = new byte[io.available()];
io.read(b);
Node huffmanTree = getHuffmanTree(b);
Map<Byte, String> huffmanCode = getHuffmanCode(huffmanTree);
byte[] zipB = byteZip(b, huffmanCode);
os = new FileOutputStream(new File(targetPath));
oos = new ObjectOutputStream(os);
oos.writeObject(zipB);
oos.writeObject(huffmanCode);
oos.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
io.close();
os.close();
oos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
2、文件解压缩
/**
* 解压缩文件
* @param inputPath
* @param outPath
*/
public static void unzipFile(String inputPath,String outPath){
ObjectInputStream ois = null;
FileInputStream is = null;
FileOutputStream os = null;
try {
is = new FileInputStream(new File(inputPath));
ois = new ObjectInputStream(is);
byte[] data = (byte[]) ois.readObject();
HashMap<Byte,String> code = (HashMap<Byte, String>) ois.readObject();
byte[] bytes = byteUnzip(data, code);
os = new FileOutputStream(new File(outPath));
os.write(bytes);
os.flush();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
} finally {
try {
is.close();
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
3、使用赫夫曼编码压缩注意事项
- 1)如果文件本身就是经过压缩处理的,那么使用赫夫曼编码再压缩效率不会有明显变化,比如视频,ppt等等文件[举例压一个ppt]
- 2)赫夫曼编码是按字节来处理的,因此可以处理所有的文件(二进制文件、文本文件)[举例压一个.mxl文件]
- 3)如果一个文件中的内容,重复的数据不多,压缩效果也不会很明显

若有收获,就点个赞吧
0 人点赞
