1、Zookeeper入门
1、概述
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目
2、工作机制
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化Zookeeper就将负责通知已经在Zookeeper.上注册的那些观察者做出相应的反应。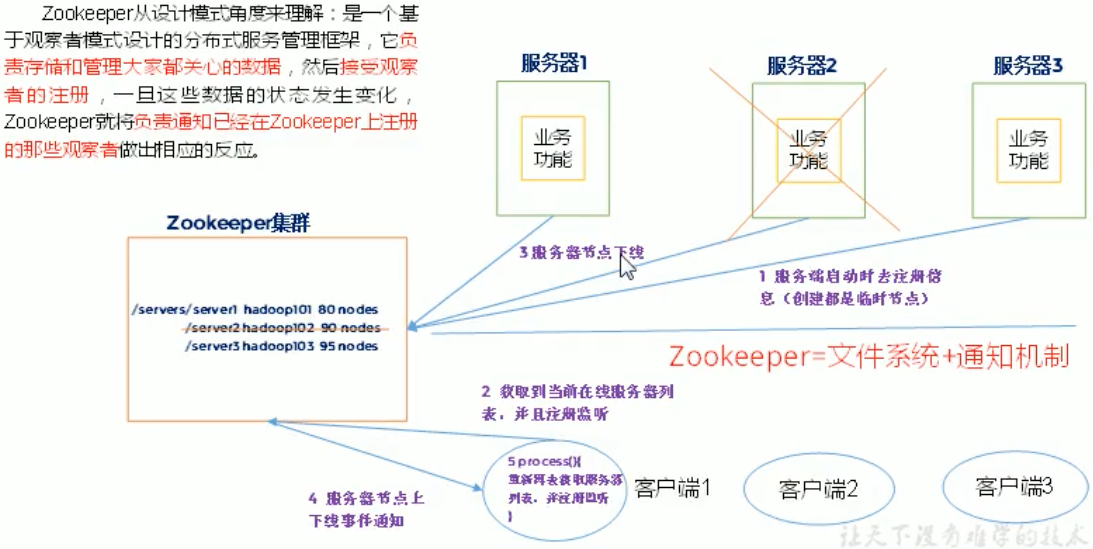
3、特点
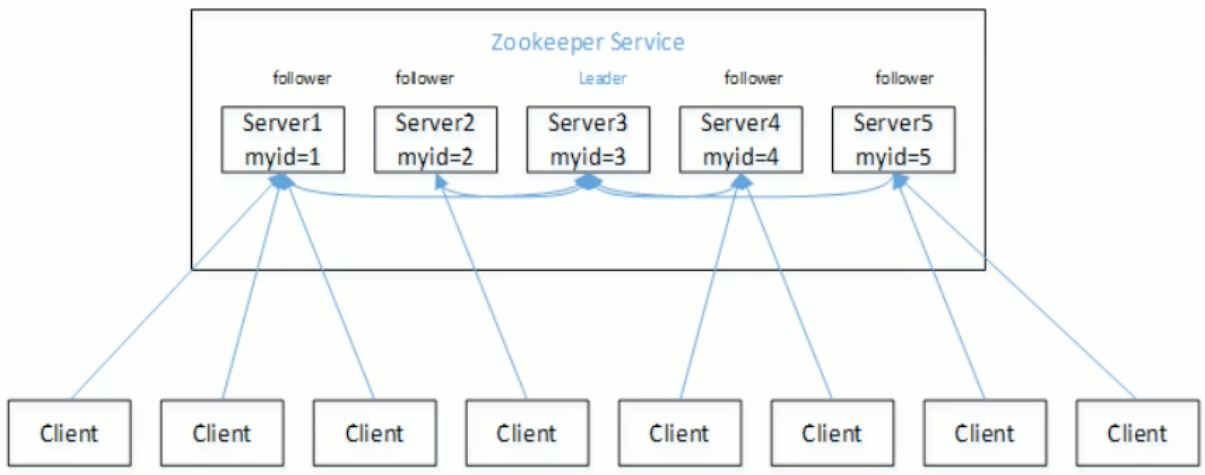
- Zookeeper:一个领导者(leader),多个跟随者(Follower)组成的集群
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务
- 全局数据一致 :每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的
- 更新请求顺序进行,来自同一个Client的更新请求按其发送顺序依次执行
- 数据更新原子性,一次数据更新要么成功,要么失败
- 实时性,在一定时间范围内,Client能读到最新数据
4、数据结构
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能够存储1MB的数据 ,每个ZNode都可以通过其路径唯一标识。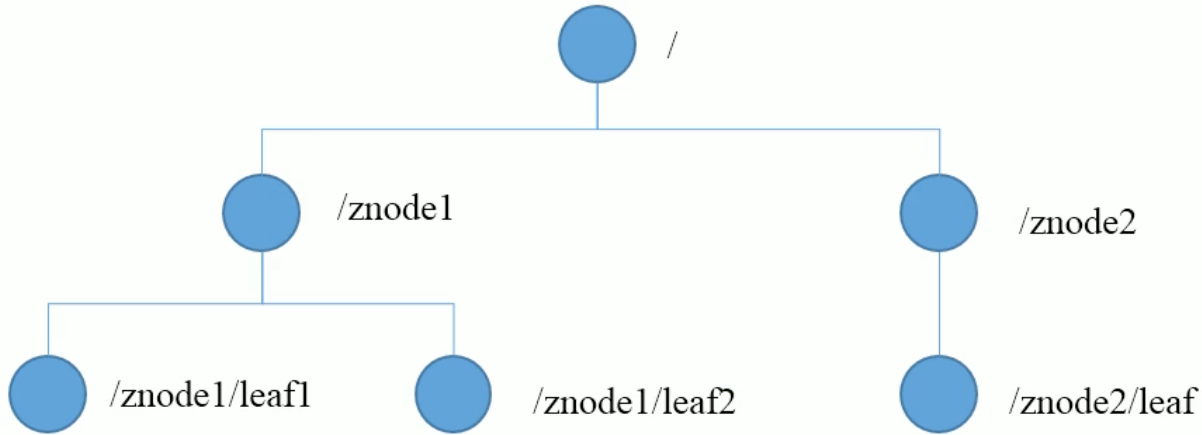
5、应用场景
- 提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
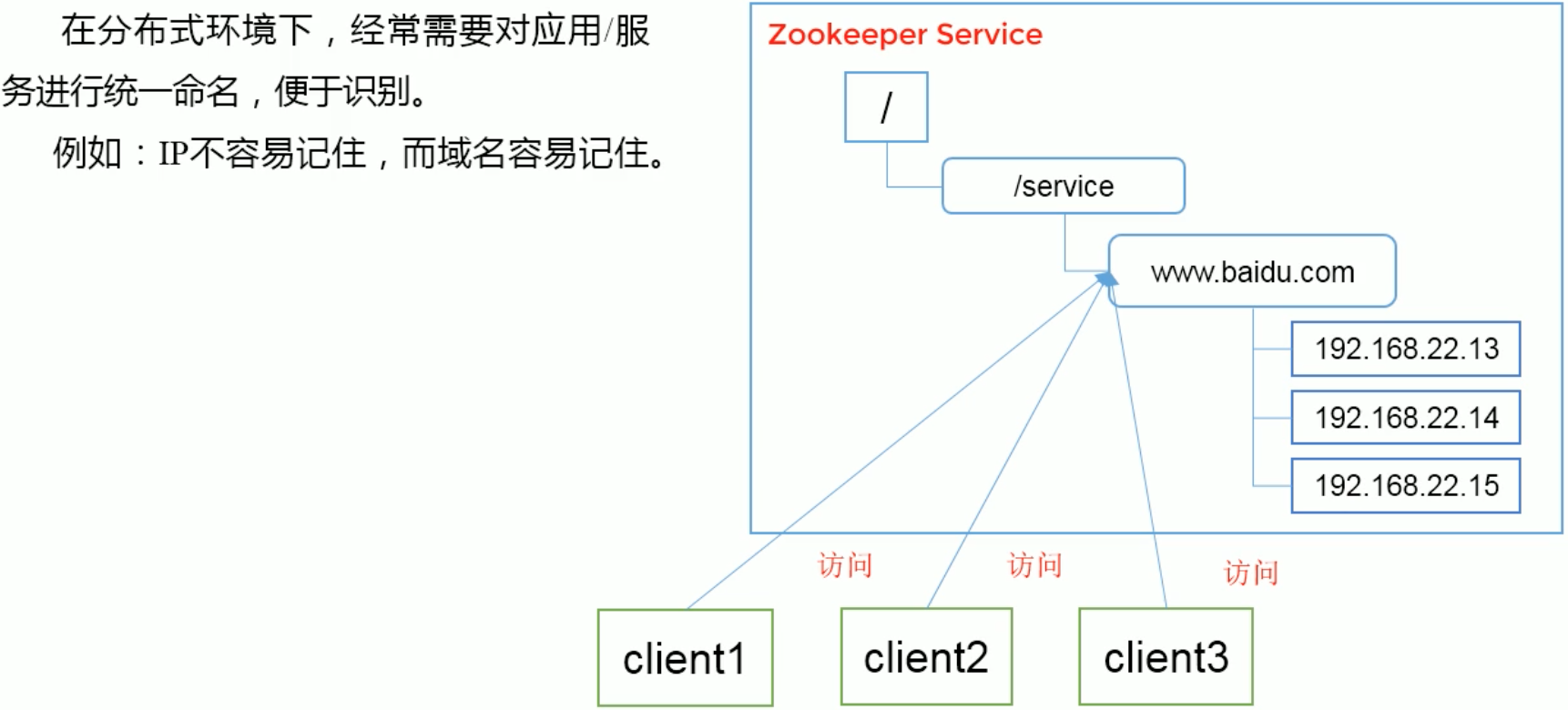
1、统一命名服务
2、统一配置服务

3、统一集群管理
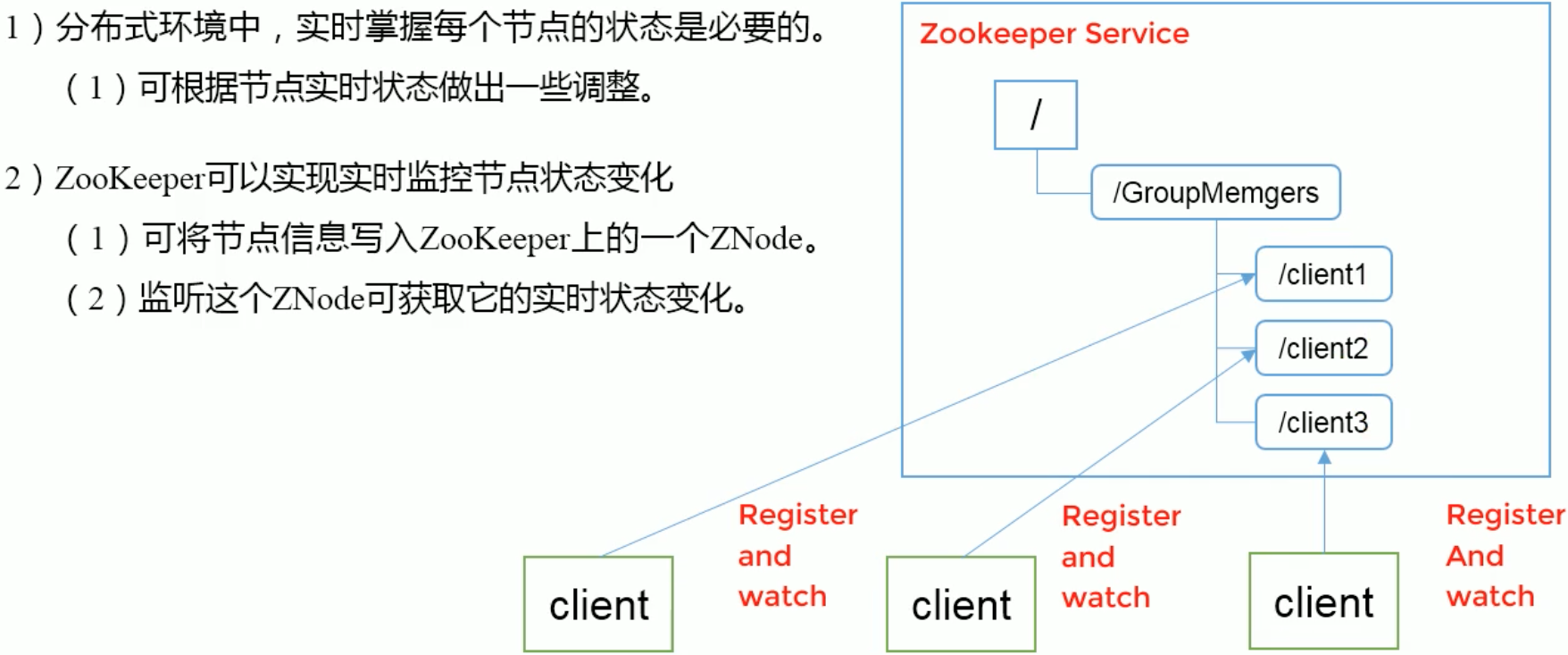
4、服务器动态上下线

5、软负载均衡

6、下载地址
1、官网地址
http://zookeeper.apache.org/
2、Zookeeper安装
1、本地模式安装部署
(1)安装jdk
(2)拷贝Zookeeper安装包到Linux系统下
(3)解压到指定目录
tar -zxvf zookeeper-3.4.10.tar.gz -C 目标路径
2、配置修改
(1) 将/Users/djy/WorkFile/zookeeper-3.6.3-bin/conf 这个路径下的 zoo_sample.cfg ,修改为 zoo.cfg;
mv zoo sample.cfg zoo.cfg
(2) 打开zoo.cfg文件,修改dataDir路径
vim zoo. cfg.
修改如下内容:
dataDir=/Users/djy/WorkFile/zookeeper-3.6.3-bin/zkData
(3) 在/Users/djy/WorkFile/zookeeper-3.6.3-bin/这个目录上创建zkData文件夹
mkdir zkData
3、操作
(1)启动运行/Users/djy/WorkFile/zookeeper-3.6.3-bin/bin里面的如下命令
./zkServer.sh start
(2)查看进程是否启动
djydeMacBook-Pro:bin DD$ jps8982 QuorumPeerMain9032 Jps488
(3)查看状态
djydeMacBook-Pro:bin DD$ ./zkServer.sh status/usr/bin/javaZooKeeper JMX enabled by defaultUsing config: /Users/djy/WorkFile/zookeeper-3.6.3-bin/bin/../conf/zoo.cfgClient port found: 2181. Client address: localhost. Client SSL: false.Mode: standalone
(4)启动客户端/Users/djy/WorkFile/zookeeper-3.6.3-bin/bin里面的
./zkCli.sh
(5)退出客户端
quit
(6)停止Zookeeper在/Users/djy/WorkFile/zookeeper-3.6.3-bin/bin里面的
./zkServer.sh stop
djydeMacBook-Pro:bin DD$ ./zkServer.sh stop/usr/bin/javaZooKeeper JMX enabled by defaultUsing config: /Users/djy/WorkFile/zookeeper-3.6.3-bin/bin/../conf/zoo.cfgStopping zookeeper ... STOPPED
4、配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
- 1、 tickTime =2000:通信心跳数,Zookeeper 服务器与客户端心跳时间,单位毫秒。
- Zookeeper使用的基木时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳, 时间单位为毫秒。它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime)
- 2、 initLimit =10: LF初始通信时限。
- 集群中的Follower跟随者服务器与Leader领导者服务器之间初始连接时能容忍的最多心跳数( tickTime的数量) ,用它来限定集群中的Zookeeper服务器连接到Leader的时限。
- syncLimit =5: LF同步通信时限。
- 集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit *tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer
- syncLimit =5: LF同步通信时限。
- dataDir: 数据文件目录+数据持久化路径
- 主要用于保存Zookeeper中的数据。
- dataDir: 数据文件目录+数据持久化路径
1)半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper 适合安装奇数台服务器。
- 2) Zookeeper虽然在配置文件中并没有指定Master和Slave.但是,Zookeeper.工作时,是有一个节点为Leader, 其他则为Follower, Leader是通过内部的选举机制临时产生的。
- 3)以一个简单的例子来说明整个选举的过程。假设有五台服务器组成的Zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么,如图所示。
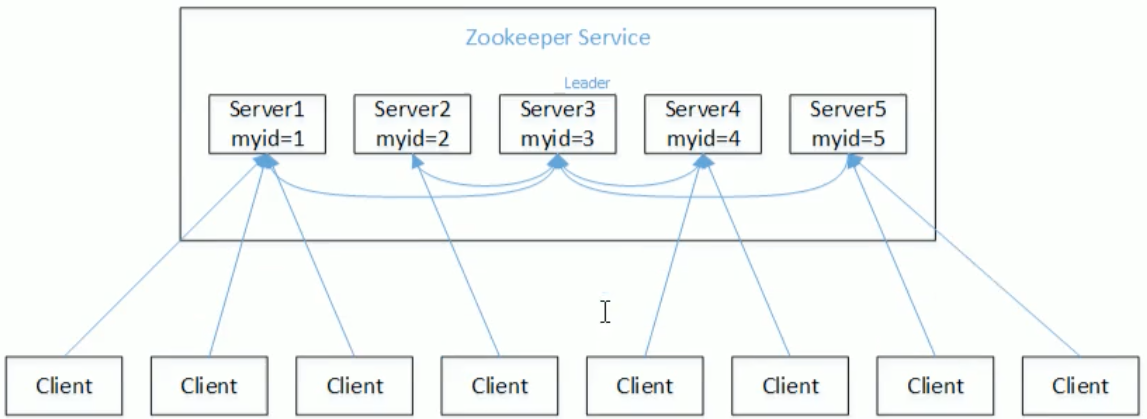
- (1)服务器1启动,此时只有它一台服务器启动了,它发出去的报文没有任何响应,所以它的选举状态一直是LOOKING状态。
- (2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
- (3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的Leader。
- (4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
- (5)服务器5启动,同4一样当小弟。
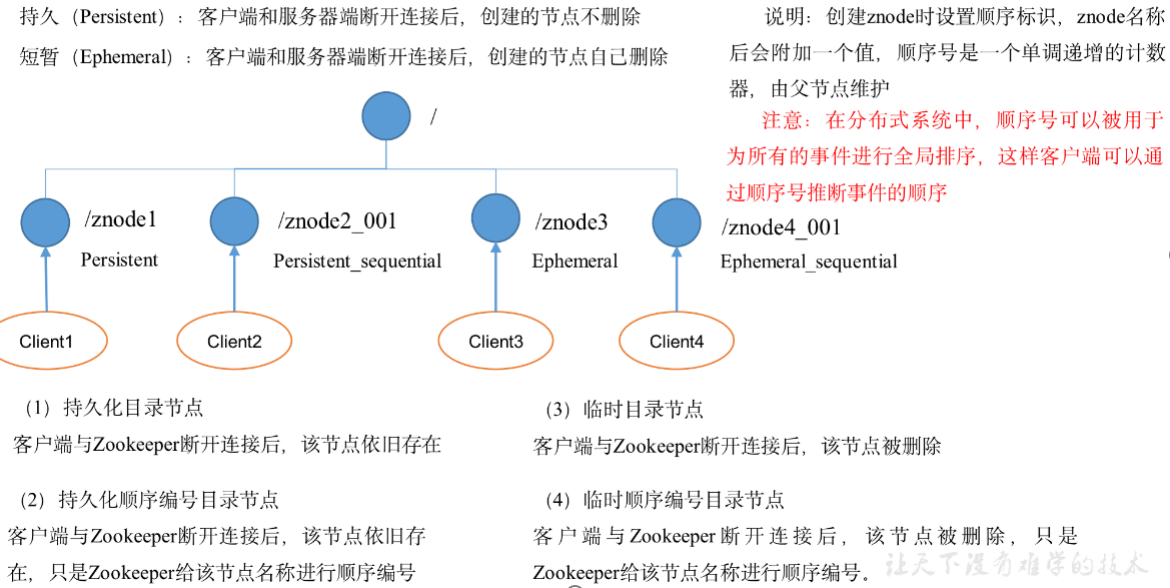
2、节点类型
4、Zookeeper实战

若有收获,就点个赞吧
0 人点赞
