1、Jedis操作Redis6
1、引入jar包
<!-- https://mvnrepository.com/artifact/redis.clients/jedis --><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.6.3</version></dependency>
2、测试代码
public class MainTest {public static void main(String[] args) {//连接Jedis jedis = new Jedis("192.168.1.154",6379);//授权密码jedis.auth("123");String ping = jedis.ping();System.out.println(ping);jedis.set("哈哈","嘿嘿");Set<String> keys = jedis.keys("*");System.out.println(keys.toString());List<GeoCoordinate> geopos = jedis.geopos("chinaLcity", "shanghai");System.out.println(geopos.toString());jedis.hset("user:1","userId","1");jedis.hset("user:1","userName","红领巾");String userName = jedis.hget("user:1", "userName");System.out.println(userName);}}
2、Redis和Spring-boot整合
1、引入jar包
<!--redis数据--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>
2、配置参数
####redis
spring.redis.port=6379
spring.redis.host=192.168.1.154
spring.redis.password=123
spring.redis.database=0
3、添加配置类
这边不配置也行,如果不配置RedisTemplate默认是使用的JdkSerializationRedisSerializer序列化器,我们自己可以配置成json返回值的Jackson2JsonRedisSerializer ```java @Configuration public class RedisConfig {
@Bean public RedisTemplate
RedisTemplate<String, Object> template = new RedisTemplate<>(); template.setConnectionFactory(factory); template.setKeySerializer(RedisSerializer.string()); template.setValueSerializer(RedisSerializer.json()); return template;}
}
<a name="Fsb55"></a>
## 4、配置controller
```java
@RestController
public class RedisController {
@Autowired
private RedisTemplate redisTemplate;
@GetMapping("/key")
public Object testRedis(@RequestParam("name") String name){
Object o = redisTemplate.opsForValue().get(name);
return o;
}
}
3、事物操作
1、介绍
Redis事物是一个单独的隔离操作,事物中的所有命令都会序列化,按顺序地执行。事务正执行的过程中,不会被其他客户端发送来的命令请求锁打断
Redis事务的主要作用就是串联多个命令防止别的命令插队
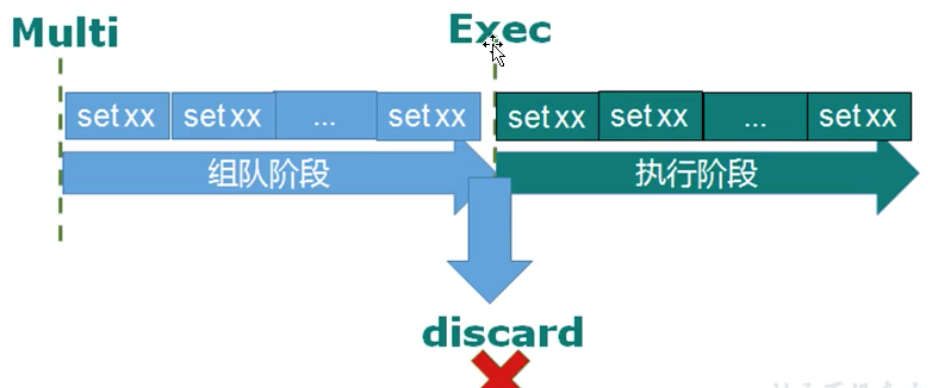
2、Multi、Exec、discard
- Multi:命令开始
- Exec:开始执行
- discard:放弃执行
192.168.1.154:6379> MULTI
OK
192.168.1.154:6379(TX)> set k1 v1
QUEUED
192.168.1.154:6379(TX)> set k2 v2
QUEUED
192.168.1.154:6379(TX)> EXEC
1) OK
2) OK
192.168.1.154:6379> MULTI
OK
192.168.1.154:6379(TX)> set k1 11
QUEUED
192.168.1.154:6379(TX)> DISCARD
OK
3、事务的错误处理
如果在组队的时候,输入命令就出错了,就所有都不执行了
192.168.1.154:6379> MULTI OK 192.168.1.154:6379(TX)> set hh 11 QUEUED 192.168.1.154:6379(TX)> set b (error) ERR wrong number of arguments for 'set' command 192.168.1.154:6379(TX)> EXEC (error) EXECABORT Transaction discarded because of previous errors.如果是在执行阶段出错,那就只会出错的命令不执行,其他正常执行
192.168.1.154:6379> MULTI OK 192.168.1.154:6379(TX)> get hh QUEUED 192.168.1.154:6379(TX)> set ee 11 QUEUED 192.168.1.154:6379(TX)> EXEC 1) (error) WRONGTYPE Operation against a key holding the wrong kind of value 2) OK4、事务冲突的问题
1、问题
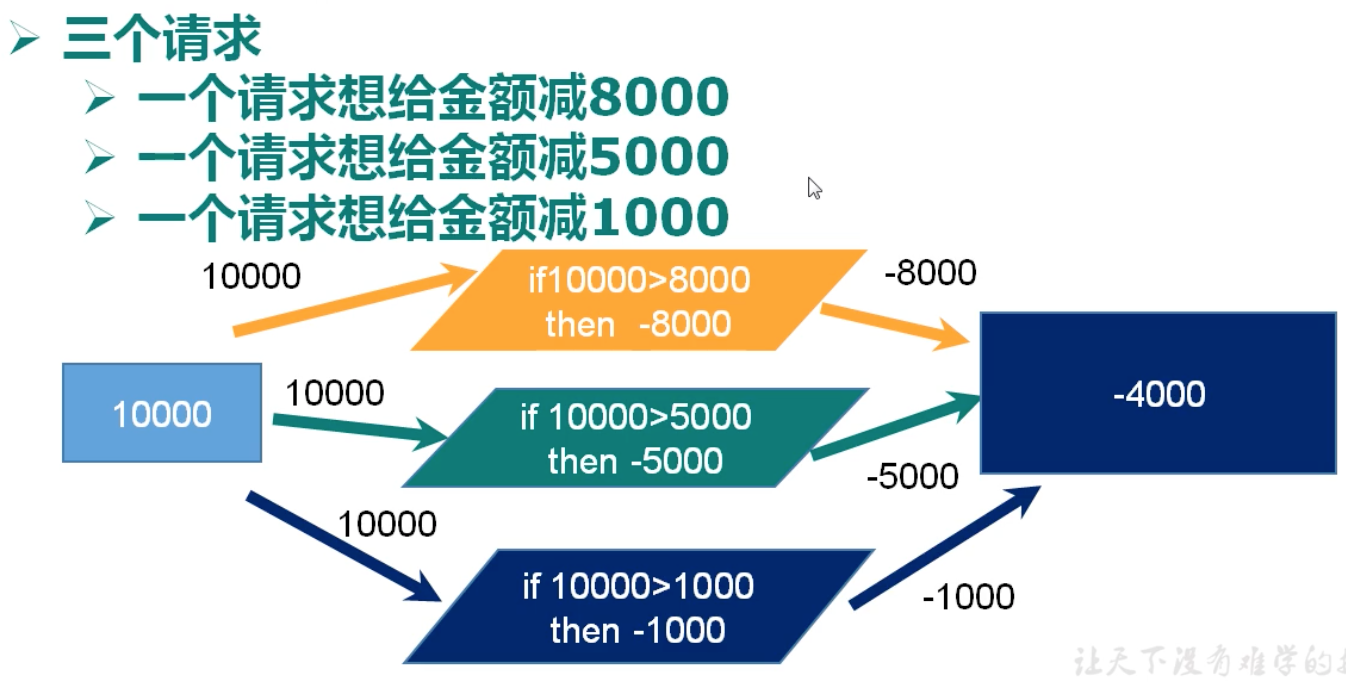
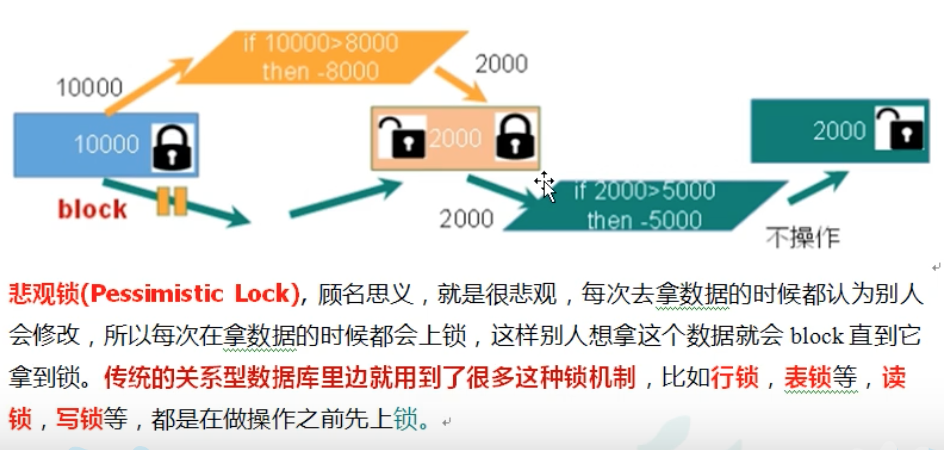
悲观锁:
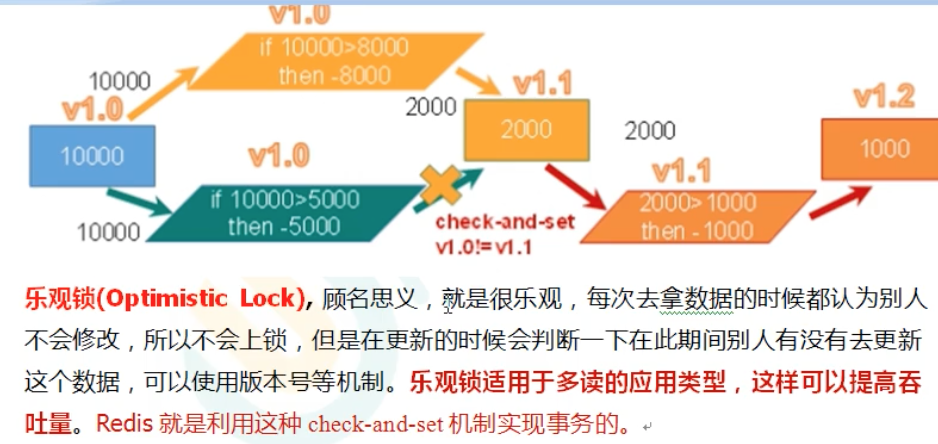
- 乐观锁
2、解决
watch
unwatch 取消对所有key的监视
- 打开一个客户端 ```shell 192.168.1.154:6379> set balance 1000 OK 192.168.1.154:6379> WATCH balance OK 192.168.1.154:6379> MULTI OK 192.168.1.154:6379(TX)> incrby balance 100 QUEUED 192.168.1.154:6379(TX)> EXEC (nil)
- 打开另外也给客户端
```shell
192.168.1.154:6379> WATCH balance
OK
192.168.1.154:6379> MULTI
OK
192.168.1.154:6379(TX)> incrby balance 10
QUEUED
192.168.1.154:6379(TX)> EXEC
1) (integer) 1010
-
4、事物三特性
单独的格力操作
- 事务中的所有命令都会序列化,按顺序的执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断
- 没有隔离级别的概念
- 队列中的命令没有提交之前都不会实际被执行,因为事务提交前任何指令都不会被实际执行
不保证原子性
-
(1)安装
yum install httpd-tools(2)使用
-n是请求次数
- -c是并发数量
- -p是提交参数
ab -n 1000 -c 100 http://192.168.1.105:8080/key?name=haha
2、代码模拟秒杀
1、连接池
public class JedisPoolUtil {
private static volatile JedisPool jedisPool = null;
private JedisPoolUtil() {
}
public static JedisPool getJedisPoolInstance() {
if (null == jedisPool) {
synchronized (JedisPoolUtil.class) {
if (null == jedisPool) {
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(200);
poolConfig.setMaxIdle(32);
poolConfig.setMaxWaitMillis(100*1000);
poolConfig.setBlockWhenExhausted(true);
poolConfig.setTestOnBorrow(true); // ping PONG
jedisPool = new JedisPool(poolConfig, "192.168.44.168", 6379, 60000 );
}
}
}
return jedisPool;
}
public static void release(JedisPool jedisPool, Jedis jedis) {
if (null != jedis) {
jedisPool.returnResource(jedis);
}
}
}
2、秒杀代码
但是会存在库存遗留问题
//秒杀过程 public static boolean doSecKill(String uid,String prodid) throws IOException { //1 uid和prodid非空判断 if(uid == null || prodid == null) { return false; } //2 连接redis //Jedis jedis = new Jedis("192.168.44.168",6379); //通过连接池得到jedis对象 JedisPool jedisPoolInstance = JedisPoolUtil.getJedisPoolInstance(); Jedis jedis = jedisPoolInstance.getResource(); //3 拼接key // 3.1 库存key String kcKey = "sk:"+prodid+":qt"; // 3.2 秒杀成功用户key String userKey = "sk:"+prodid+":user"; //监视库存 jedis.watch(kcKey); //4 获取库存,如果库存null,秒杀还没有开始 String kc = jedis.get(kcKey); if(kc == null) { System.out.println("秒杀还没有开始,请等待"); jedis.close(); return false; } // 5 判断用户是否重复秒杀操作 if(jedis.sismember(userKey, uid)) { System.out.println("已经秒杀成功了,不能重复秒杀"); jedis.close(); return false; } //6 判断如果商品数量,库存数量小于1,秒杀结束 if(Integer.parseInt(kc)<=0) { System.out.println("秒杀已经结束了"); jedis.close(); return false; } //7 秒杀过程 //使用事务 Transaction multi = jedis.multi(); //组队操作 multi.decr(kcKey); multi.sadd(userKey,uid); //执行 List<Object> results = multi.exec(); if(results == null || results.size()==0) { System.out.println("秒杀失败了...."); jedis.close(); return false; } //7.1 库存-1 //jedis.decr(kcKey); //7.2 把秒杀成功用户添加清单里面 //jedis.sadd(userKey,uid); System.out.println("秒杀成功了.."); jedis.close(); return true; }3、LUA脚本解决超卖,和库存遗留问题
就是可以相当于悲观锁一样,一步执行到底,不被打断
static String secKillScript ="local userid=KEYS[1];\r\n" + "local prodid=KEYS[2];\r\n" + "local qtkey='sk:'..prodid..\":qt\";\r\n" + "local usersKey='sk:'..prodid..\":usr\";\r\n" + "local userExists=redis.call(\"sismember\",usersKey,userid);\r\n" + "if tonumber(userExists)==1 then \r\n" + " return 2;\r\n" + "end\r\n" + "local num= redis.call(\"get\" ,qtkey);\r\n" + "if tonumber(num)<=0 then \r\n" + " return 0;\r\n" + "else \r\n" + " redis.call(\"decr\",qtkey);\r\n" + " redis.call(\"sadd\",usersKey,userid);\r\n" + "end\r\n" + "return 1" ; static String secKillScript2 = "local userExists=redis.call(\"sismember\",\"{sk}:0101:usr\",userid);\r\n" + " return 1"; public static boolean doSecKill(String uid,String prodid) throws IOException { JedisPool jedispool = JedisPoolUtil.getJedisPoolInstance(); Jedis jedis=jedispool.getResource(); //String sha1= .secKillScript; String sha1= jedis.scriptLoad(secKillScript); Object result= jedis.evalsha(sha1, 2, uid,prodid); String reString=String.valueOf(result); if ("0".equals( reString ) ) { System.err.println("已抢空!!"); }else if("1".equals( reString ) ) { System.out.println("抢购成功!!!!"); }else if("2".equals( reString ) ) { System.err.println("该用户已抢过!!"); }else{ System.err.println("抢购异常!!"); } jedis.close(); return true; }4、持久化操作RDB
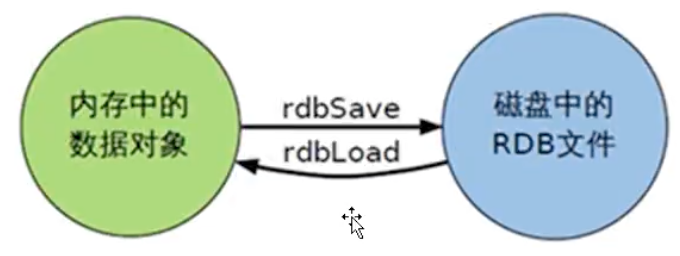
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里
在使用redis-server /etc/redis.conf 运行的时候会在你运行这个命令的目录中生成文件dump.rdb
1、备份是如何执行的
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能,如果需要进行大规模数据的恢复,切对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
1、Fork
Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量,环境变量,程序计数器等)数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
- 在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,linux中引入了“写时复制技术”
一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程
2、RDB备份在redis.conf相关配置
1、redis.conf,生成dump.rdb
默认生成的缓存文件 dump.rdb

- 保存这个文件的默认地址就是启动命令的地址
- config get dir 也可以查看设置的目录

- 默认间隔保存时间
- 3600秒有1个key改变
- 300秒有至少100个key改变
- 60秒至少10000个key改变
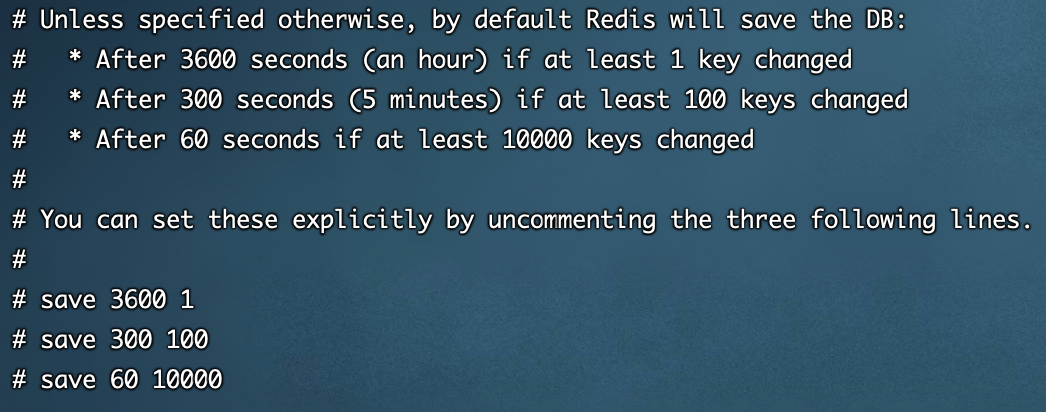
- 比如当到60秒的时候 我们有10010key发生了变化,会先进行10000个进行保存,然后剩下10个重新开始计时
-
2、writes-on-bgsave-error
-
3、rdbcompression压缩文件
默认是yes
- 对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩,如果你不想消耗cpu来进行压缩的话,可以关闭设置,
-
4、rdbchecksum检查完整性
默认yes
- 在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提醒,可以关闭此功能
- 推荐yes

3、RDB恢复
2、劣势
- Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑
- 虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
5、持久化AOF(Append Only File)
1、简介
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以修改文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
2、AOF持久化流程
(1)客户端的请求写命令会被append追加到AOF缓冲区内;小
(2) AOF缓冲区根据AOF持久化策略[always,everysec,no ]将操作sync同步到磁盘的
AOF文件中;
(3)AOF文件大小超过重写策略或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量;。
(4) Redis服务重启时,会重新load加载AOF文件中的写操作达到数据恢复的目的;3、AOF默认不开启
通过配置appendonly 设置为yes 开启功能
- 可以在redis.conf中配置文件名称,默认为appendonly.aof
- AOF文件的保存路径,同RDB的路径一致
4、AOF和RDB同时开启,redis听谁的
5、AOF 启动/修复/恢复
- AOF的备份机制和性能虽然和RDB不同,但是备份和恢复的操作同RDB一样,都是拷贝备份文件,需要恢复时再拷贝到Redis工作目录下,启动系统即加载。
- 正常恢复
- 修改默认的appendonly no 为yes
- 将有数据的aof文件复制一份保存到对应目录(查看目录:config get dir)
异常恢复
appendfsync always
- 始终同步,每次Redis的写入都会立刻计入日志,性能较差但数据完整性比较好
- appendfsync everysec
- 每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失
appendfsync no
- redis不主动进行同步,把同步时机交给操作系统
7、Rewrite压缩
1、简介
AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过设置的阀值时,Redis会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集,可以使用命令bgrewriteaof2、原理
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最
后再rename) , redis4.0 版本后的重写,是指上就是把rdb的快照,以二级制的形式附
在新的aof头部,作为已有的历史数据,替换掉原来的流水账操作。
no-appendfsync-on-rewrite :。
Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大
小的一倍且文件大于64M时触发。
重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有-定的负担的
因此设定Redis要满足一定条件才会进行重写。。
- redis不主动进行同步,把同步时机交给操作系统
auto-aof-rewrite-percentage :设置重写的基准值,文件达到100%时开始重写(文件
是原来重写后文件的2倍时触发)
auto-aof-rewrite-min-size :设置重写的基准值,最小文件64MB。达到这个值开始
8、优势
备份机制更加稳健,丢失数据概率比较低。
-
9、劣势
比起RDB占用更多的磁盘空间
- 恢复备份速度要慢
- 每次读写都同步的话,有一定的性能压力
-
6、主从复制
1、简介
主机数据封信后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
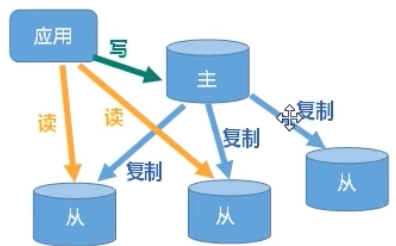
2、作用
读写分离,性能扩展
-
3、配置
1、1主2仆
(1)创建/myredis文件夹
- (2)复制redis.conf配置文件到文件夹中
- (3)创建三个文件
- redis6379.conf
- redis6380.conf
- redis6381.conf
(4)使用include 命令配置redis6379.conf引入redis.conf配置文件配置
- 如果主机中配置了密码,那从机中需要添加 主机密码 masterauth 密码
配置redis6379.conf
include /myredis/redis.conf pidfile /myredis/redis_6379.pid port 6379 dbfilename dump6379.rdb配置redis6380.conf
include /myredis/redis.conf pidfile /myredis/redis_6380.pid port 6380 dbfilename dump6380.rdb masterauth qwerasdf123配置redis6381.conf
include /myredis/redis.conf pidfile /myredis/redis_6381.pid port 6381 dbfilename dump6381.rdb masterauth qwerasdf123
(5)如果aof配置打开了先关闭或者修改appendonly.aof文件名称修改掉
- (6)启动三台服务器 ```shell [root@localhost myredis]# redis-server /myredis/redis6379.conf [root@localhost myredis]# redis-server /myredis/redis6380.conf [root@localhost myredis]# redis-server /myredis/redis6381.conf
- (7)查看是否启动
```shell
[root@localhost myredis]# ps -aux | grep redis
root 17256 0.1 0.1 162400 9940 ? Ssl 01:12 0:00 redis-server *:6380
root 18197 0.1 0.1 162400 9944 ? Ssl 01:13 0:00 redis-server *:6381
root 19889 0.1 0.1 162400 9944 ? Ssl 01:14 0:00 redis-server *:6379
root 21695 0.0 0.0 112720 972 pts/0 R+ 01:15 0:00 grep --color=auto redis
(8)分别连接上服务器查看 服务器状况
- info replication
[root@localhost myredis]# redis-cli -p 6379 127.0.0.1:6379> AUTH qwerasdf123 OK 127.0.0.1:6379> info replication # Replication role:master connected_slaves:0 master_failover_state:no-failover master_replid:620489594d7ac066f676d17a580ce1bb1ea8ea2f master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
- info replication
(9)配从(库)不配主(库)
- 从上配置
- slaveof
- 成为某个实例的从服务器
- 在6380和6381上执行:slaveof 127.0.0.1 6379
- 配置完主机信息
```shell
127.0.0.1:6379> info replication
Replication
role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6380,state=online,offset=504,lag=1 slave1:ip=127.0.0.1,port=6381,state=online,offset=504,lag=1 master_failover_state:no-failover master_replid:166cbb5a783cec2325321292aba5174a139c2ffd master_replid2:0000000000000000000000000000000000000000 master_repl_offset:504 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:504
- 从机信息
```shell
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:70
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:166cbb5a783cec2325321292aba5174a139c2ffd
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:70
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:70
1、说明
- 如果从机挂了,从机起来不会自己变成从机,而是变成了自己的主机,得重新配置从机,配置之后数据会从主服务器再恢复
-
2、薪火相传
1、6379主,7380从(主为6379),6381从(主为6380)
3、反客为主
命令 slaveof no one
-
4、哨兵模式
1、配置
反客为主自动模式
(1)调成为1主2从
- (2)自定义的/myredis目录下新建sentinel.conf文件,名字绝不能错
(3)配置哨兵,填写内容
- 添加 sentinel monitor mymaster 127.0.0.1 6379 1
- 其中mymaster为监控主机对象起的主服务器名称,1为至少有多少个哨兵同意迁移的数量
- 如果有密码加入密码 sentinel auth-pass mymaster 密码
sentinel monitor mymaster 127.0.0.1 6379 1 sentinel auth-pass mymaster qwerasdf123
- 添加 sentinel monitor mymaster 127.0.0.1 6379 1
(4)启动哨兵
- redis-sentinel /myredis/sentinel.conf
- (5)就可以自动监控了,如果主机挂了,从机就会选出一个主机,之前的主机就会被设置为从机。 ```shell 21606:X 18 Aug 2021 07:19:55.937 # Sentinel ID is eea29d5537bc6ae7bb7c49252dc4ead0b3467235 21606:X 18 Aug 2021 07:19:55.937 # +monitor master mymaster 127.0.0.1 6379 quorum 1 21606:X 18 Aug 2021 07:19:55.939 +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:19:55.941 +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:18.211 # +sdown master mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:18.211 # +odown master mymaster 127.0.0.1 6379 #quorum 1/1 21606:X 18 Aug 2021 07:28:18.211 # +new-epoch 2 21606:X 18 Aug 2021 07:28:18.211 # +try-failover master mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:18.214 # +vote-for-leader eea29d5537bc6ae7bb7c49252dc4ead0b3467235 2 21606:X 18 Aug 2021 07:28:18.214 # +elected-leader master mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:18.214 # +failover-state-select-slave master mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:18.298 # +selected-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:18.298 +failover-state-send-slaveof-noone slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:18.381 +failover-state-wait-promotion slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:18.604 # +promoted-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:18.604 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:18.686 +slave-reconf-sent slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:19.628 +slave-reconf-inprog slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:19.628 +slave-reconf-done slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:19.704 # +failover-end master mymaster 127.0.0.1 6379 21606:X 18 Aug 2021 07:28:19.704 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6380 21606:X 18 Aug 2021 07:28:19.705 +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6380 21606:X 18 Aug 2021 07:28:19.705 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6380
<a name="GqoaW"></a>
#### 2、选举新主机原则
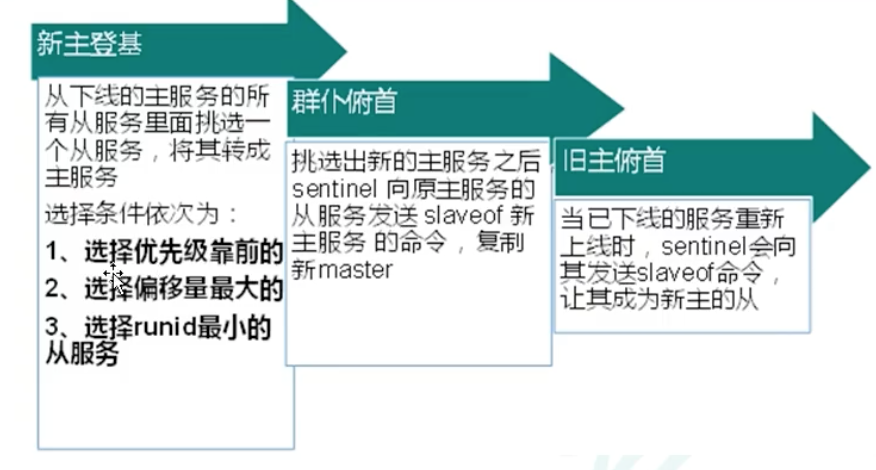<br />优先级在redis.conf中默认:
- slave-priority 100 (6.1版本后为replica-priority) 值越小优先级越高
- 偏移量是指获得主机数据最全的
- 每个redis实例启动后都会随机生成一个40位的runid
<a name="ObC0N"></a>
## 4、原理
- (1)从连接上主服务器之后,从服务器向主服务器发送要进行数据同步的消息
- (2)主服务器接到从服务器发送过来的消息之后,把主服务器数据进行持久化rdb文件,把rdb文件发送从服务器,从服务器拿到rdb进行读取
- (3)每次主服务器进行写操作之后,和从服务器进行数据同步
- 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master继续将新的所有手机到的修改命令依次传给slave,完成同步
<a name="QEZi6"></a>
## 5、复制延迟
由于所有的写操作都是先在Master上操作,然后同步更新到Slave.上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重, Slave机器数量的增加也会使这个问题更加严重。
<a name="JggtR"></a>
# 7、集群操作
<a name="4hWfa"></a>
## 1、问题
- 容量不够,redis如何进行扩容,并发写操作,redis如何分摊
- 另外,主从模式,薪火相传模式,主机宕机,导致ip地址发生变化,引用程序中配置需要修改对应的主机地址,端口等信息
- 之前通过代理主机解决,但是redis3.0中提供了解决方案,就是无中心化集群配置
<a name="jNoas"></a>
## 2、什么是集群
- Redis集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/n
- Redis集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求
<a name="iJfLx"></a>
## 3、搭建
<a name="bhpvK"></a>
### 1、做6个实例
- (1)6379,6380,6381,6389,6390,6391
- (2)/myredis删除dump文件
- (3)配置redis.conf
- 添加集群配置
- appendonly关闭或者修改appendonly.aof文件名称
- cluster-enabled yes 打开集群模式
- cluster-config-file nodes-6379.conf 设定节点配置文件名
- cluster-node-timeout 15000 设置节点失联时间,超过该时间(毫秒),集群自动进入主从切换
- 然后快速的创建出6分配置
- (4)启动6个redis服务
```shell
[root@localhost myredis]# redis-server redis6379.conf
[root@localhost myredis]# redis-server redis6380.conf
[root@localhost myredis]# redis-server redis6381.conf
[root@localhost myredis]# redis-server redis6389.conf
[root@localhost myredis]# redis-server redis6390.conf
[root@localhost myredis]# redis-server redis6391.conf
[root@localhost myredis]# ps -aux | grep redis
root 5641 0.1 0.1 164960 10232 ? Ssl 09:31 0:00 redis-server *:6379 [cluster]
root 8509 0.1 0.1 164960 10460 ? Ssl 09:33 0:00 redis-server *:6380 [cluster]
root 8604 0.1 0.1 164960 10484 ? Ssl 09:33 0:00 redis-server *:6381 [cluster]
root 8723 0.1 0.1 164960 10480 ? Ssl 09:33 0:00 redis-server *:6389 [cluster]
root 8831 0.0 0.1 164960 10476 ? Ssl 09:33 0:00 redis-server *:6390 [cluster]
root 8929 0.0 0.1 164960 10484 ? Ssl 09:33 0:00 redis-server *:6391 [cluster]
root 9083 0.0 0.0 112720 968 pts/0 S+ 09:33 0:00 grep --color=auto redis
include /myredis/redis.conf
pidfile "/myredis/redis_6379.pid"
port 6379
dbfilename "dump6379.rdb"
#主机密码
masterauth qwerasdf123
#开启集群
cluster-enabled yes
#节点配置文件名称
cluster-config-file nodes-6379.conf
#节点失联主从切换时间
cluster-node-timeout 15000
- (5)合体
/进入安装的文件夹中进入/src下
里面有一个redis-cli,因为这边目录下执行 会有一个redis-trib.rb环境,其他目录无法执行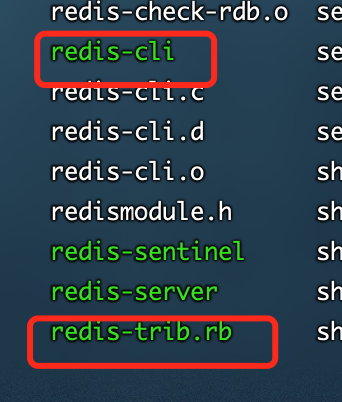
- 用真实ip地址不要用127.0.0.1
—replicas 1采用最简单的方式配置集群,一台主机,一台从机,正好三组
redis-cli --cluster create --cluster-replicas 1 192.168.1.154:6379 192.168.1.154:6380 192.168.1.154:6381 192.168.1.154:6389 192.168.1.154:6390 192.168.1.154:6391注意在配置集群的时候先不要设置requirepass 密码,因为cluster create不支持设置密码,等配置成功之后可以再单独给每台服务器通过config set requirepass 密码和config set masterauth 密码 进行设置密码 ```shell [root@localhost src]# redis-cli —cluster create —cluster-replicas 1 192.168.1.154:6379 192.168.1.154:6380 192.168.1.154:6381 192.168.1.154:6389 192.168.1.154:6390 192.168.1.154:6391
Performing hash slots allocation on 6 nodes… Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 192.168.1.154:6390 to 192.168.1.154:6379 Adding replica 192.168.1.154:6391 to 192.168.1.154:6380 Adding replica 192.168.1.154:6389 to 192.168.1.154:6381 Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: dd5a46c460cb1633631bfd49086edf68ff9e12c3 192.168.1.154:6379 slots:[0-5460] (5461 slots) master M: ef280242b823807fd468b0f511bd2f51999b3726 192.168.1.154:6380 slots:[5461-10922] (5462 slots) master M: bcc818af37c2a8ef91eaac51b341367891b4649f 192.168.1.154:6381 slots:[10923-16383] (5461 slots) master S: 25baa118f0e0e3f725898f8a05f58bb94754f58e 192.168.1.154:6389 replicates dd5a46c460cb1633631bfd49086edf68ff9e12c3 S: a9205a31befb1d19b0e78edc38b480768ef452a6 192.168.1.154:6390 replicates ef280242b823807fd468b0f511bd2f51999b3726 S: e08fd8e60a2e8a138819221acff4d5f029f39139 192.168.1.154:6391 replicates bcc818af37c2a8ef91eaac51b341367891b4649f Can I set the above configuration? (type ‘yes’ to accept): yes Nodes configuration updated Assign a different config epoch to each node Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join … Performing Cluster Check (using node 192.168.1.154:6379) M: dd5a46c460cb1633631bfd49086edf68ff9e12c3 192.168.1.154:6379 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: ef280242b823807fd468b0f511bd2f51999b3726 192.168.1.154:6380 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: a9205a31befb1d19b0e78edc38b480768ef452a6 192.168.1.154:6390 slots: (0 slots) slave replicates ef280242b823807fd468b0f511bd2f51999b3726 M: bcc818af37c2a8ef91eaac51b341367891b4649f 192.168.1.154:6381 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: e08fd8e60a2e8a138819221acff4d5f029f39139 192.168.1.154:6391 slots: (0 slots) slave replicates bcc818af37c2a8ef91eaac51b341367891b4649f S: 25baa118f0e0e3f725898f8a05f58bb94754f58e 192.168.1.154:6389 slots: (0 slots) slave replicates dd5a46c460cb1633631bfd49086edf68ff9e12c3 [OK] All nodes agree about slots configuration. Check for open slots… Check slots coverage… [OK] All 16384 slots covered.
<a name="t1ot1"></a>
### 2、集群客户端连接
- -c表示集群连接
```shell
redis-cli -c -p 端口号
djydeMacBook-Pro:~ DD$ redis-cli -c -h 192.168.1.154 -p 6379
192.168.1.154:6379> keys *
(empty array)
192.168.1.154:6379> set name 11
-> Redirected to slot [5798] located at 192.168.1.154:6380
OK
192.168.1.154:6380> set key 20
-> Redirected to slot [12539] located at 192.168.1.154:6381
OK
192.168.1.154:6381> keys *
1) "key"
3、cluster nodes 可以查看节点信息
192.168.1.154:6381> cluster nodes
bcc818af37c2a8ef91eaac51b341367891b4649f 192.168.1.154:6381@16381 myself,master - 0 1629252373000 3 connected 10923-16383
dd5a46c460cb1633631bfd49086edf68ff9e12c3 192.168.1.154:6379@16379 master - 0 1629252373482 1 connected 0-5460
e08fd8e60a2e8a138819221acff4d5f029f39139 192.168.1.154:6391@16391 slave bcc818af37c2a8ef91eaac51b341367891b4649f 0 1629252372474 3 connected
ef280242b823807fd468b0f511bd2f51999b3726 192.168.1.154:6380@16380 master - 0 1629252373000 2 connected 5461-10922
25baa118f0e0e3f725898f8a05f58bb94754f58e 192.168.1.154:6389@16389 slave dd5a46c460cb1633631bfd49086edf68ff9e12c3 0 1629252374490 1 connected
a9205a31befb1d19b0e78edc38b480768ef452a6 192.168.1.154:6390@16390 slave ef280242b823807fd468b0f511bd2f51999b3726 0 1629252372000 2 connected
192.168.1.154:6381>
4、slots
- 一个Redis有16384个插槽,数据库中的每个键都属于这16384个插槽的其中一个,
- 集群使用公式CRC16(key)%16384来计算键属于哪个槽,其中CRC16(key)语句用于计算键key的CRC16检验和。
- 集群中的每个节点负责处理一部分插槽。如果一个集群可以有主节点,
- 其中节点A负责处理0号至5460号插槽
- 节点B负责5461-10922
- 节点C负责10923-16383
5、mget,mset等多键操作
可以通过{}来定义组的概念,从而使用key中{}内相同内容的键值对放在一个slot中去。 ```shell 192.168.1.154:6379> mset name{user} red age{user} 10 sex{user} 1 -> Redirected to slot [5474] located at 192.168.1.154:6380 OK 192.168.1.154:6380> mget name{user} age{user} 1) “red” 2) “10”
<a name="Dnqvi"></a>
## 6、查询集群中的槽
<a name="403adec7"></a>
### 1、计算key的槽cluster keyslot <key>
```shell
192.168.1.154:6380> cluster keyslot user
(integer) 5474
2、查询槽中有几个key
cluster countkeysinslot <槽>
192.168.1.154:6380> cluster countkeysinslot 5474
(integer) 3
3、在某个槽中返回几个key
cluster getkeysinslot <槽> <数量>
192.168.1.154:6380> cluster getkeysinslot 5474 2
1) "age{user}"
2) "name{user}"
7、故障恢复
- 如果一个节点挂了,下面的从机会启动变成节点
如果刚挂的节点重新起来了,如果该节点已经被上线了,老节点会变成从机
8、如果某一段槽主从节点都宕机,redis服务是否还能继续?
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage为yes,那么,整个集群都挂掉
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage为no,那么只有该插槽数据全都不能使用,也无法存储。其他插槽还是能用
9、Java中Jedis操作集群
public class ClusterTest { public static void main(String[] args) { HostAndPort hostAndPort = new HostAndPort("192.168.1.154",6379); JedisCluster jedisCluster = new JedisCluster(hostAndPort); String yes = jedisCluster.set("yes", "11"); System.out.println(yes); String s = jedisCluster.get("name{user}"); System.out.println(s); jedisCluster.close(); } }10、集群好处
实现扩容
- 分摊压力
-
11、集群的不足
多键操作是不被支持的L。
- 多键的Redis事务不被支持的。lua 脚本不被支持。
- 由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster ,需要整体迁移而不是逐步过渡,复杂度较大。

若有收获,就点个赞吧
0 人点赞
