- 1、MyBatis框架地位简介
- 2、为什么要使用MyBatis
- 3、初次使用
- 1、下载和文档
- 2、创建一个java空项目
- 3、SqlSession
- 4、日志打印配置
- settings(设置)">3、settings(设置)
- typeAliases(类型别名)">4、别名typeAliases(类型别名)
- typeHandlers(类型处理器)">5、typeHandlers(类型处理器)
- plugins(插件)">6、插件plugins(插件)
- environments(环境配置)">7、environments(环境配置)
- databaseIdProvider(数据库厂商标识)">8、databaseIdProvider(数据库厂商标识)
- mappers(映射器)">9 、mappers(映射器)
- 5、映射文件
- 动态SQL">6、动态SQL
- 7、缓存机制
1、MyBatis框架地位简介
- 最初使用JDBC-》DBUtils-》jdbcTemplate,这些都只是工具而已,不是整体解决方案
-
1、Hibernate
全自动全映射ORM(Object Relation Mapping)框架;SQL全是框架自动生成的
2、解析图
sql语句交给我们开发人员编写最好,sql不市区灵活性
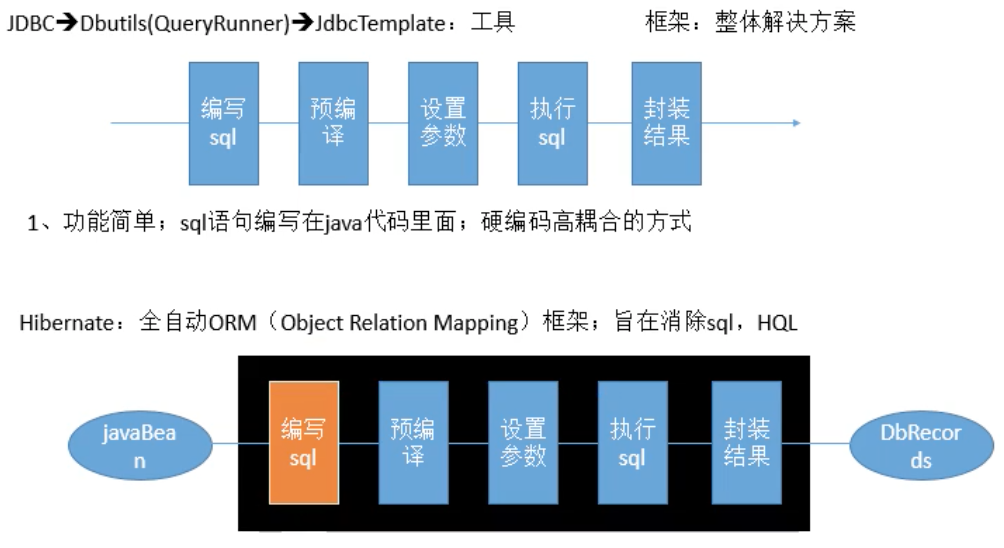
3、MyBatis流程
- 半自动
- 轻量级框架
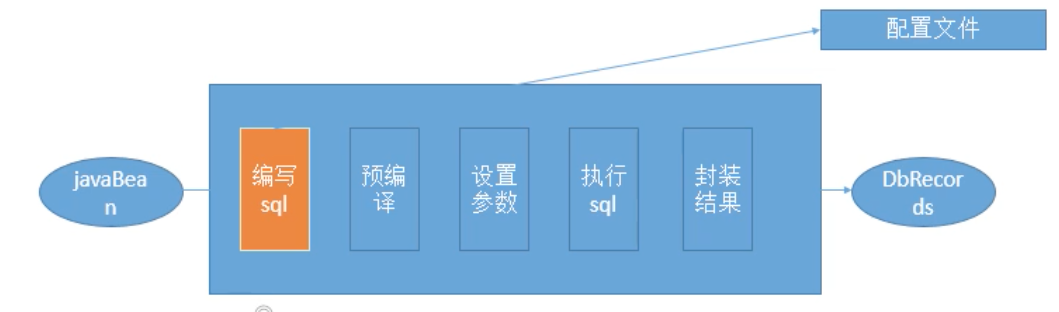
-
2、为什么要使用MyBatis
MyBatis是一个半自动化的持久化层框架。
- JDBC
- SQL夹在Java代码块里,耦合度高导致硬编码内伤
- 维护不易且实际开发需求中SQL是有变化,频繁修改的情况多见
- Hibernate和JPA
- 长难复查SQL,对于Hibernate而言处理也不容易
- 内部自动生产的SQL,不容易做特殊优化
- 基于全映射的全自动框架,大量字段的POJO进行部分映射时比较困难。导致数据库性能下降
- 对于开发人员而言,核心sql还是需要自己优化
sql和java编码分开,功能边界清晰,一个专注业务,一个专注数据。
3、初次使用
1、下载和文档
中文文档:https://mybatis.org/mybatis-3/zh/index.html
2、创建一个java空项目
config得设置为资源文件目录
1、导入jar
- mysql驱动
- mybatis包
2、创建一个映射文件
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.daijunyi.mapper.UserMapper"><select id="getUserList" resultType="com.daijunyi.User">select * from `user`</select></mapper>
3、创建mybatis.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--设置驼峰命名规则,得按照顺序先后配置-->
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/learn"/>
<property name="username" value="root"/>
<property name="password" value="qwerasdf123"/>
</dataSource>
</environment>
</environments>
<!--映射文件-->
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
</configuration>
4、创建一个bean类
package com.daijunyi;
public class User {
private Integer userId;
private String userName;
private Integer uStatus;
@Override
public String toString() {
return "bean{" +
"userId=" + userId +
", userName='" + userName + '\'' +
", uStatus=" + uStatus +
'}';
}
public Integer getUserId() {
return userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public Integer getuStatus() {
return uStatus;
}
public void setuStatus(Integer uStatus) {
this.uStatus = uStatus;
}
}
5、创建一个UserMapper接口
package com.daijunyi.mapper;
import com.daijunyi.User;
import java.util.List;
public interface UserMapper {
public List<User> getUserList();
}
6、测试代码
public class MyBatisTest {
@Test
public void test() throws IOException {
String resource = "mybatis.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
try (SqlSession session = sqlSessionFactory.openSession()) {
UserMapper mapper = session.getMapper(UserMapper.class);
List<User> userList = mapper.getUserList();
System.out.println(userList);
session.close();
}
}
}
3、SqlSession
- SqlSession代表和数据库的一次会话,用完得关闭
- SqlSession和connection一样她都是非线程安全的,每次使用都应该去获取新的对象
- mapper接口没有实现类,但是mybatis会为这个接口生成一个代理对象。(将接口和xml进行绑定)
- 两个重要的配置文件
- mybatis的全局配置文件:包含数据库连接池信息,事物管理器信息等
- sql映射文件,保存了没一个sql语句的映射信息,将sql提取了出来
4、日志打印配置
1、引入了包
2、全局配合中添加日志框架指定
<settings> <setting name="mapUnderscoreToCamelCase" value="true"/> <!--显示的指定延迟加载--> <setting name="lazyLoadingEnabled" value="true"/> <setting name="aggressiveLazyLoading" value="false"/> <setting name="logImpl" value="LOG4J"></setting> </settings>3、添加log4j.xml文件
添加配置信息 ```xml <?xml version=”1.0” encoding=”UTF-8”?> <!DOCTYPE log4j:configuration PUBLIC “-//log4j/log4j Configuration//EN” “log4j.dtd”>
<!-- 日志输出到控制台 -->
<appender name="console" class="org.apache.log4j.ConsoleAppender">
<!-- 日志输出格式 -->
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="[%p][%d{yyyy-MM-dd HH:mm:ss SSS}][%c]-[%m]%n"/>
</layout>
<!--过滤器设置输出的级别-->
<filter class="org.apache.log4j.varia.LevelRangeFilter">
<!-- 设置日志输出的最小级别 -->
<param name="levelMin" value="DEBUG"/>
<!-- 设置日志输出的最大级别 -->
<param name="levelMax" value="ERROR"/>
</filter>
</appender>
<!-- 输出日志到文件 -->
<appender name="fileAppender" class="org.apache.log4j.FileAppender">
<!-- 输出文件全路径名-->
<param name="File" value="out/fileAppender.log"/>
<!--是否在已存在的文件追加写:默认时true,若为false则每次启动都会删除并重新新建文件-->
<param name="Append" value="false"/>
<param name="Threshold" value="INFO"/>
<!--是否启用缓存,默认false-->
<param name="BufferedIO" value="false"/>
<!--缓存大小,依赖上一个参数(bufferedIO), 默认缓存大小8K -->
<param name="BufferSize" value="512"/>
<!-- 日志输出格式 -->
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="[%p][%d{yyyy-MM-dd HH:mm:ss SSS}][%c]-[%m]%n"/>
</layout>
</appender>
<!-- 输出日志到文件,当文件大小达到一定阈值时,自动备份 -->
<!-- FileAppender子类 -->
<appender name="rollingAppender" class="org.apache.log4j.RollingFileAppender">
<!-- 日志文件全路径名 -->
<param name="File" value="out/RollingFileAppender.log" />
<!--是否在已存在的文件追加写:默认时true,若为false则每次启动都会删除并重新新建文件-->
<param name="Append" value="true" />
<!-- 保存备份日志的最大个数,默认值是:1 -->
<param name="MaxBackupIndex" value="10" />
<!-- 设置当日志文件达到此阈值的时候自动回滚,单位可以是KB,MB,GB,默认单位是KB,默认值是:10MB -->
<param name="MaxFileSize" value="10KB" />
<!-- 设置日志输出的样式 -->`
<layout class="org.apache.log4j.PatternLayout">
<!-- 日志输出格式 -->
<param name="ConversionPattern" value="[%d{yyyy-MM-dd HH:mm:ss:SSS}] [%-5p] [method:%l]%n%m%n%n" />
</layout>
</appender>
<!-- 日志输出到文件,可以配置多久产生一个新的日志信息文件 -->
<appender name="dailyRollingAppender" class="org.apache.log4j.DailyRollingFileAppender">
<!-- 文件文件全路径名 -->
<param name="File" value="out/dailyRollingAppender.log"/>
<param name="Append" value="true" />
<!-- 设置日志备份频率,默认:为每天一个日志文件 -->
<param name="DatePattern" value="'.'yyyy-MM-dd'.log'" />
<!--每分钟一个备份-->
<!--<param name="DatePattern" value="'.'yyyy-MM-dd-HH-mm'.log'" />-->
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="[%p][%d{HH:mm:ss SSS}][%c]-[%m]%n"/>
</layout>
</appender>
<!--
1. 指定logger的设置,additivity是否遵循缺省的继承机制
2. 当additivity="false"时,root中的配置就失灵了,不遵循缺省的继承机制
3. 代码中使用Logger.getLogger("logTest")获得此输出器,且不会使用根输出器
-->
<logger name="logTest" additivity="false">
<level value ="INFO"/>
<appender-ref ref="dailyRollingAppender"/>
</logger>
<!-- 根logger的设置,若代码中未找到指定的logger,则会根据继承机制,使用根logger-->
<root>
<appender-ref ref="console"/>
<appender-ref ref="fileAppender"/>
<appender-ref ref="rollingAppender"/>
<appender-ref ref="dailyRollingAppender"/>
</root>
---
<a name="kFPN0"></a>
# 4、Mybatis-全局配置文件
<a name="nYrwc"></a>
## 1、MyBatis 的配置
文件包含了会深深影响 MyBatis 行为的设置和属性信息。 配置文档的顶层结构如下:
- configuration(配置)
- [properties(属性)](https://mybatis.org/mybatis-3/zh/configuration.html#properties)
- [settings(设置)](https://mybatis.org/mybatis-3/zh/configuration.html#settings)
- [typeAliases(类型别名)](https://mybatis.org/mybatis-3/zh/configuration.html#typeAliases)
- [typeHandlers(类型处理器)](https://mybatis.org/mybatis-3/zh/configuration.html#typeHandlers)
- [objectFactory(对象工厂)](https://mybatis.org/mybatis-3/zh/configuration.html#objectFactory)
- [plugins(插件)](https://mybatis.org/mybatis-3/zh/configuration.html#plugins)
- [environments(环境配置)](https://mybatis.org/mybatis-3/zh/configuration.html#environments)
- environment(环境变量)
- transactionManager(事务管理器)
- dataSource(数据源)
- [databaseIdProvider(数据库厂商标识)](https://mybatis.org/mybatis-3/zh/configuration.html#databaseIdProvider)
- [mappers(映射器)](https://mybatis.org/mybatis-3/zh/configuration.html#mappers)
<a name="YdEZg"></a>
## 2、[properties(属性)](https://mybatis.org/mybatis-3/zh/configuration.html#properties)
<a name="W2r6q"></a>
### 1、创建db.properties
```xml
jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/learn
jdbc.username=root
jdbc.password=qwerasdf123
2、使用文件中属性
- 通过properties引入db.properties文件内容
使用${}来使用其中属性
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <properties resource="db.properties"></properties> <environments default="development"> <environment id="development"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> </dataSource> </environment> </environments> </configuration>3、settings(设置)
开启_和驼峰命名转换
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <properties resource="db.properties"></properties> <settings> <setting name="mapUnderscoreToCamelCase" value="true"/> </settings> <environments default="development"> <environment id="development"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> </dataSource> </environment> </environments> <mappers> <mapper resource="mapper/UserMapper.xml"/> </mappers> </configuration>4、别名typeAliases(类型别名)
为类取一个别名,为了书写方便
- 也可以批量导入别名
- 不区分大小写
-
5、typeHandlers(类型处理器)
-
6、插件plugins(插件)
MyBatis 允许你在映射语句执行过程中的某一点进行拦截调用。默认情况下,MyBatis 允许使用插件来拦截的方法调用包括:
Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
- ParameterHandler (getParameterObject, setParameters)
- ResultSetHandler (handleResultSets, handleOutputParameters)
StatementHandler (prepare, parameterize, batch, update, query)
7、environments(环境配置)
环境配置必须拥有两个标签
JDBC (JdbcTransactionFactory)– 这个配置直接使用了 JDBC 的提交和回滚设施,它依赖从数据源获得的连接来管理事务作用域。
MANAGED(ManagedTransactionFactory) – 这个配置几乎没做什么。它从不提交或回滚一个连接,而是让容器来管理事务的整个生命周期(比如 JEE 应用服务器的上下文)。 默认情况下它会关闭连接。然而一些容器并不希望连接被关闭,因此需要将 closeConnection 属性设置为 false 来阻止默认的关闭行为。例如:
<transactionManager type="MANAGED"> <property name="closeConnection" value="false"/> </transactionManager>提示 如果你正在使用 Spring + MyBatis,则没有必要配置事务管理器,因为 Spring 模块会使用自带的管理器来覆盖前面的配置。
这两种事务管理器类型都不需要设置任何属性。它们其实是类型别名,换句话说,你可以用 TransactionFactory 接口实现类的全限定名或类型别名代替它们。2、数据源(dataSource)
UNPOOLED(UnpooledDataSourceFactory)
- POOLED(PooledDataSourceFactory)
- JNDI(JndiDataSourceFactory)
8、databaseIdProvider(数据库厂商标识)
-
1、添加数据库别名配置
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!--配置数据库别名--> <databaseIdProvider type="DB_VENDOR"> <property name="MySQL" value="mysql"/> <property name="Oracle" value="oracle" /> </databaseIdProvider> </configuration>2、在mapper映射文件中指定数据库
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.daijunyi.mapper.UserMapper"> <!--使用databaseId指定在mysql数据库下执行--> <select id="getUserList" resultType="com.daijunyi.User" databaseId="mysql"> select * from `user` </select> <!--使用databaseId指定在oracle数据库下执行--> <select id="getUserList" resultType="com.daijunyi.User" databaseId="oracle"> select * from `tb_user` </select> </mapper>9 、mappers(映射器)
注册映射文件xml文件的
- resource:使用相对于类路径的资源引用
- url:使用完全限定资源定位符(URL)
- 注册类中的接口
- class:使用映射器接口实现类的完全限定类名
- name: 将包内的映射器接口实现全部注册为映射器
- 映射文件名必须和接口文件名一样,并且放在同一个目录下
- 另外还有一种就是接口中使用全注解方式的使用(此种请下没有xml映射文件)
5、映射文件
MyBatis 的真正强大在于它的语句映射,这是它的魔力所在。由于它的异常强大,映射器的 XML 文件就显得相对简单。如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。MyBatis 致力于减少使用成本,让用户能更专注于 SQL 代码。
SQL 映射文件只有很少的几个顶级元素(按照应被定义的顺序列出):
cache– 该命名空间的缓存配置。cache-ref– 引用其它命名空间的缓存配置。resultMap– 描述如何从数据库结果集中加载对象,是最复杂也是最强大的元素。parameterMap– 老式风格的参数映射。此元素已被废弃,并可能在将来被移除!请使用行内参数映射。文档中不会介绍此元素。sql– 可被其它语句引用的可重用语句块。insert– 映射插入语句。update– 映射更新语句。delete– 映射删除语句。-
1、CRUD
1、添加各自的接口
public interface UserMapper { public List<User> getUserList(); public Integer addUser(User user); public Integer delete(Integer userId); public Integer updateUser(User user); }2、映射文件
```xml <?xml version=”1.0” encoding=”UTF-8” ?> <!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<insert id="addUser" parameterType="com.daijunyi.User">
insert into `user` (user_id,user_name,u_status) values (#{userId},#{userName},#{uStatus})
</insert>
<delete id="delete" parameterType="int">
delete from `user` where user_id = #{userId}
</delete>
<update id="updateUser" parameterType="user">
update `user` set user_name = #{userName}, u_status = #{uStatus} where user_id = #{userId}
</update>
<a name="r6Ugu"></a>
### 3、获取自增主键值
- useGeneratedKeys=true
- keyProperty对象中键
- keyColumn表中键
```xml
<!-- public Integer addUser(User user);-->
<insert id="addUser" parameterType="com.daijunyi.User" useGeneratedKeys="true" keyProperty="userId" keyColumn="user_id">
insert into `user` (user_name,u_status) values (#{userName},#{uStatus})
</insert>
4、selectKey标签
用来对于一些不支持生成主键的数据库
这里就是相当于主动查询了一下自己的表的最大值已经是多少了,然后重新赋值给下一条
<insert id="addUser" parameterType="com.daijunyi.User" useGeneratedKeys="true" keyProperty="userId" keyColumn="user_id">
<selectKey keyProperty="userId" keyColumn="user_id" resultType="int" order="BEFORE">
select user_id+1 from `user` order by user_id DESC limit 1
</selectKey>
insert into `user` (user_id,user_name,u_status) values (#{userId},#{userName},#{uStatus})
</insert>
2、参数处理
1、单个参数
Mybatis不会特殊处理 直接#{参数名}取值 参数名可以随便写,不用管什么名字
2、多个参数
Mybatis会做特殊处理,封装成map
如果不做参数名称指定 只能通过[arg1, arg0, param1, param2] 这样取值示例 #{arg1}
<!-- public User getUser(Integer userId,String userName);--> <select id="getUser" resultType="user"> select * from `user` where user_id = #{arg0} and user_name = #{arg1} </select>我们最好使用接口中@Param注解来处理指定名称
public User getUser(@Param("userId") Integer userId, @Param("userName") String userName);<!-- public Integer updateUser(User user);--> <update id="updateUser" parameterType="user"> update `user` set user_name = #{userName}, u_status = #{uStatus} where user_id = #{userId} </update>3、多个参数解决方案
使用POJO对象的形式传入,这样可以从对象中取值#{属性名}
- 也可以使用封装成MAP的形式传入 #{key}
3、特殊参数 List Array set等

3、参数原理解析
1、方法参数名称解析
public ParamNameResolver(Configuration config, Method method) { this.useActualParamName = config.isUseActualParamName(); final Class<?>[] paramTypes = method.getParameterTypes(); final Annotation[][] paramAnnotations = method.getParameterAnnotations(); final SortedMap<Integer, String> map = new TreeMap<>(); int paramCount = paramAnnotations.length; // get names from @Param annotations for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) { if (isSpecialParameter(paramTypes[paramIndex])) { // skip special parameters continue; } String name = null; for (Annotation annotation : paramAnnotations[paramIndex]) { if (annotation instanceof Param) { hasParamAnnotation = true; name = ((Param) annotation).value(); break; } } if (name == null) { // @Param was not specified. if (useActualParamName) { name = getActualParamName(method, paramIndex); } if (name == null) { // use the parameter index as the name ("0", "1", ...) // gcode issue #71 name = String.valueOf(map.size()); } } map.put(paramIndex, name); } names = Collections.unmodifiableSortedMap(map); }
2、根据名称获取出对应的值
ParamNameResolver中
//ParamNameResolver public Object getNamedParams(Object[] args) { final int paramCount = names.size(); if (args == null || paramCount == 0) { return null; } else if (!hasParamAnnotation && paramCount == 1) { Object value = args[names.firstKey()]; return wrapToMapIfCollection(value, useActualParamName ? names.get(0) : null); } else { final Map<String, Object> param = new ParamMap<>(); int i = 0; for (Map.Entry<Integer, String> entry : names.entrySet()) { param.put(entry.getValue(), args[entry.getKey()]); // add generic param names (param1, param2, ...) final String genericParamName = GENERIC_NAME_PREFIX + (i + 1); // ensure not to overwrite parameter named with @Param if (!names.containsValue(genericParamName)) { param.put(genericParamName, args[entry.getKey()]); } i++; } return param; } }3、如果当只有一个参数的时候并且没有@Param注解的时候
判断当前对象的类型,根据对象的类型
- 如果是Collection,key取名称为collection,
- 如果进一步是List再增加一个名称list
- 如果是数组类型 key为array
public static Object wrapToMapIfCollection(Object object, String actualParamName) { if (object instanceof Collection) { ParamMap<Object> map = new ParamMap<>(); map.put("collection", object); if (object instanceof List) { map.put("list", object); } Optional.ofNullable(actualParamName).ifPresent(name -> map.put(name, object)); return map; } else if (object != null && object.getClass().isArray()) { ParamMap<Object> map = new ParamMap<>(); map.put("array", object); Optional.ofNullable(actualParamName).ifPresent(name -> map.put(name, object)); return map; } return object; }4、param的关键代码
```java public static final String GENERIC_NAME_PREFIX = “param”;
final String genericParamName = GENERIC_NAME_PREFIX + (i + 1);
可以发现就是这样拼接出来的
<a name="05DI5"></a>
## 4、取值${}和#{}区别
- ${}会直接把值取出来,然后写在sql语句中
- 而#{}方式取值是先会加?预编译的形式加入sql中,所以${}没法防止sql注入
- 但是${} 使用场景是在一些原生jdbc不支持占位符的地方使用${}来写入
- 比如分表的时候对表名 select * from ${year}_salary等
<a name="cNtLV"></a>
## 5、#{}更丰富用法
规定参数的一些规则:<br />javaType、jdbcType、mode(存储过程)、numericScale、resultMap、typeHandler、jdbcTypeName、expression(未来准备支持的功能)
<a name="Tm8NQ"></a>
### 1、jdbcType
通常需要在某种特定的条件下被设置:<br />在我们数据为null的时候,有些数据库可能不能识别mybatis对null的默认处理。比如Oracle<br />在Oracle下传null会报错,jdbcType OTHER:无效的类型,因为mybatis对所有的null都映射的是原生jdbc的OTHER类型,所以我们这里需要把jdbcType类型修改为NULL<br />两种修改方式
- mybatis配置文件<setting中jdbcTypeForNull修改为NULL,因为默认是OTHER

- 另外一种是直接在#{userName,jdbcType=NULL}
<a name="37frL"></a>
## 6、返回类型是List的时候
如果接口返回参数是List的时候,我们的resultType还是得写List中的返回对象的具体类名
<a name="6qn4W"></a>
## 7、@MapKey+resultType=“map”
@MapKey 指定User对象中哪一个属性作为map的key
```java
@MapKey("user_id")
public Map<Integer,User> getUserMap();
<!-- public Map<Integer,User> getUserMap();-->
<select id="getUserMap" resultType="map">
select * from `user`
</select>
测试打印出
/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/bin/java -ea -Didea.test.cyclic.buffer.size=1048576 -Dfile.encoding=UTF-8 -classpath "/Applications/IntelliJ IDEA.app/Contents/lib/idea_rt.jar:/Applications/IntelliJ IDEA.app/Contents/plugins/junit/lib/junit5-rt.jar:/Applications/IntelliJ IDEA.app/Contents/plugins/junit/lib/junit-rt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/charsets.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/deploy.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/ext/cldrdata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/ext/dnsns.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/ext/jaccess.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/ext/jfxrt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/ext/localedata.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/ext/nashorn.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/ext/sunec.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/ext/sunjce_provider.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/ext/sunpkcs11.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/ext/zipfs.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/javaws.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/jce.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/jfr.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/jfxswt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/jsse.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/management-agent.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/plugin.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/resources.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/rt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/lib/ant-javafx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/lib/dt.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/lib/javafx-mx.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/lib/jconsole.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/lib/packager.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/lib/sa-jdi.jar:/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/lib/tools.jar:/Users/djy/WorkFile/learn/mybatis/mybatis01/out/production/mybatis01:/Users/djy/WorkFile/learn/mybatis/mybatis01/lib/log4j-1.2.17.jar:/Users/djy/WorkFile/learn/mybatis/mybatis01/lib/mybatis-3.5.7.jar:/Users/djy/WorkFile/learn/mybatis/mybatis01/lib/log4j-api-2.14.1.jar:/Users/djy/WorkFile/learn/mybatis/mybatis01/lib/log4j-core-2.14.1.jar:/Users/djy/WorkFile/learn/mybatis/mybatis01/lib/mysql-connector-java-8.0.26.jar:/Users/djy/.m2/repository/junit/junit/4.12/junit-4.12.jar:/Users/djy/.m2/repository/org/hamcrest/hamcrest-core/1.3/hamcrest-core-1.3.jar" com.intellij.rt.junit.JUnitStarter -ideVersion5 -junit4 com.daijunyi.test.MyBatisTest,testQueryMap
{112={user_id=112, user_name=红领巾3, u_status=2}, 113={user_id=113, user_name=红领巾3, u_status=2}, 2={user_id=2, user_name=红领巾, u_status=2}, 114={user_id=114, user_name=红领巾3, u_status=2}, 115={user_id=115, user_name=红领巾3, u_status=2}, 116={user_id=116, user_name=红领巾3, u_status=2}, 111={user_id=111, user_name=11, u_status=1}}
Process finished with exit code 0
8、自定义ResultMap
1、
- 标签属性
- type:自定义规则的Java类型
- id:唯一id方便引用
- 内部标签
指定主键 指定返回集 - 如果user对象中还有一个对象的话可以使用级联赋值
封装成一个对象 - javaType 指定是什么对象类型
- select可以调用某个查询
- column:指定将哪一列的值专递给这个方法
- fetchType: 延迟加载单独控制
- lazy:延迟
- eager,立即
封装成一个集合 - ofType:指定集合里面元素的类型
- select可以调用某个查询
- column:指定将哪一列的值专递给这个方法
- fetchType: 延迟加载单独控制
- lazy:延迟
- eager,立即
鉴别器 - 鉴别器:mybatis可以使用discriminator判断某列的值,然后根据某列的值改变封装行为
1、在association和collection中column传递多值
column=”{key1=column1,key2=column2}”
示例:column=”{userId=user_id,userName=user_name}”2、鉴别器(discriminator)
有时候,一个数据库查询可能会返回多个不同的结果集(但总体上还是有一定的联系的)。 鉴别器(discriminator)元素就是被设计来应对这种情况的,另外也能处理其它情况,例如类的继承层次结构。 鉴别器的概念很好理解——它很像 Java 语言中的 switch 语句。<discriminator javaType="int" column="draft"> <case value="1" resultType="DraftPost"/> </discriminator>
一个鉴别器的定义需要指定 column 和 javaType 属性。column 指定了 MyBatis 查询被比较值的地方。 而 javaType 用来确保使用正确的相等测试(虽然很多情况下字符串的相等测试都可以工作)。例如:
在这个示例中,MyBatis 会从结果集中得到每条记录,然后比较它的 vehicle type 值。 如果它匹配任意一个鉴别器的 case,就会使用这个 case 指定的结果映射。 这个过程是互斥的,也就是说,剩余的结果映射将被忽略(除非它是扩展的,我们将在稍后讨论它)。 如果不能匹配任何一个 case,MyBatis 就只会使用鉴别器块外定义的结果映射。 所以,如果 carResult 的声明如下:<resultMap id="vehicleResult" type="Vehicle"> <id property="id" column="id" /> <result property="vin" column="vin"/> <result property="year" column="year"/> <result property="make" column="make"/> <result property="model" column="model"/> <result property="color" column="color"/> <discriminator javaType="int" column="vehicle_type"> <case value="1" resultMap="carResult"/> <case value="2" resultMap="truckResult"/> <case value="3" resultMap="vanResult"/> <case value="4" resultMap="suvResult"/> </discriminator> </resultMap>
那么只有 doorCount 属性会被加载。这是为了即使鉴别器的 case 之间都能分为完全独立的一组,尽管和父结果映射可能没有什么关系。在上面的例子中,我们当然知道 cars 和 vehicles 之间有关系,也就是 Car 是一个 Vehicle。因此,我们希望剩余的属性也能被加载。而这只需要一个小修改。<resultMap id="carResult" type="Car"> <result property="doorCount" column="door_count" /> </resultMap>
现在 vehicleResult 和 carResult 的属性都会被加载了。<resultMap id="carResult" type="Car" extends="vehicleResult"> <result property="doorCount" column="door_count" /> </resultMap>
可能有人又会觉得映射的外部定义有点太冗长了。 因此,对于那些更喜欢简洁的映射风格的人来说,还有另一种语法可以选择。例如:
提示 请注意,这些都是结果映射,如果你完全不设置任何的 result 元素,MyBatis 将为你自动匹配列和属性。所以上面的例子大多都要比实际的更复杂。 这也表明,大多数数据库的复杂度都比较高,我们不太可能一直依赖于这种机制。<resultMap id="vehicleResult" type="Vehicle"> <id property="id" column="id" /> <result property="vin" column="vin"/> <result property="year" column="year"/> <result property="make" column="make"/> <result property="model" column="model"/> <result property="color" column="color"/> <discriminator javaType="int" column="vehicle_type"> <case value="1" resultType="carResult"> <result property="doorCount" column="door_count" /> </case> <case value="2" resultType="truckResult"> <result property="boxSize" column="box_size" /> <result property="extendedCab" column="extended_cab" /> </case> <case value="3" resultType="vanResult"> <result property="powerSlidingDoor" column="power_sliding_door" /> </case> <case value="4" resultType="suvResult"> <result property="allWheelDrive" column="all_wheel_drive" /> </case> </discriminator> </resultMap>2、延迟加载
- 鉴别器:mybatis可以使用discriminator判断某列的值,然后根据某列的值改变封装行为
在全局设置中打开开关 | lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置
fetchType属性来覆盖该项的开关状态。 | true | false | false | | :—- | :—- | :—- | :—- | | aggressiveLazyLoading | 开启时,任一方法的调用都会加载该对象的所有延迟加载属性。 否则,每个延迟加载属性会按需加载(参考lazyLoadTriggerMethods)。 | true | false | false (在 3.4.1 及之前的版本中默认为 true) |
<settings>
<!--显示的指定延迟加载-->
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
在fetchType 可以单独控制某个分段查询是否延迟还是分段
- lazy:延迟
- eager,立即
6、动态SQL
1、特殊字符
& 转义字符 &
“ 转义 "2、标签
1、if条件判断
2、where标签
会帮我们去掉 标签前面的and 然后进行拼接
<!-- public User getUser(Integer userId,String userName);--> <select id="getUser" resultType="user"> select * from `user` <where> <if test="userId != null"> and user_id = #{userId} </if> <if test="userName != null and userName != ''"> and user_name = #{userName} </if> </where> </select>3、trim
prefix:前缀,给拼接后的字符串前面加一个前缀
- prefixOverrides:前缀覆盖,去掉前面多余的字符
- suffix:后缀 给拼接后的整个字符串添加一个后缀
suffixOverrides:后缀覆盖,去掉后面多余的字符串
<select id="getUser" resultType="user"> select * from `user` <trim prefix="where" suffixOverrides="and"> <if test="userId != null"> user_id = #{userId} and </if> <if test="userName != null and userName != ''"> user_name = #{userName} and </if> </trim> </select>4、choose(when,otherwise)
分支选择;
<!-- public User getUser(Integer userId,String userName);--> <select id="getUser" resultType="user"> select * from `user` <where> <choose> <when test="userId != null"> and user_id = #{userId} </when> <when test="userName != null && userName == ''"> and user_name = #{userName} </when> <otherwise> and user_id = 2 </otherwise> </choose> </where> </select>生成如下sql
Preparing: select * from `user` WHERE user_id = ?5、set
set 会帮我们去掉结尾多余的,不管逗号在前面还是在后面都会帮我们去掉。
<!-- public Integer updateUser(User user);--> <update id="updateUser" parameterType="user"> update `user` <set> <if test="userName != null and userName != ''"> user_name = #{userName}, </if> <if test="uStatus != null"> u_status = #{uStatus} </if> </set> where user_id = #{userId} </update>生成sql
Preparing: update `user` SET user_name = ?, u_status = ? where user_id = ?6、foreach
collection:指定要遍历的集合
- item:将当前遍历出的原生赋值给指定的变量
- separator:每个元素之间的分隔符
- open:遍历出所有结果拼接一个开始的字符
- close:遍历出所有结果拼接一个结束的字符
index:索引
- 遍历list的时候是索引,item就是值
- 遍历map的时候index表示就是map的key,item就是map的值
1、查询使用
生成的sql<!-- public List<User> getUserListById(List<Integer> userIds);--> <select id="getUserListById" parameterType="list" resultType="user"> select * from `user` where user_id in <foreach collection="list" item="item" separator="," open="(" close=")" index="index"> #{item} </foreach> </select>Preparing: select * from `user` where user_id in ( ? , ? , ? , ? )2、批量插入
mysql 支持values(),()语法
<!-- public Integer addUsers(List<User> users);--> <insert id="addUsers" parameterType="list" useGeneratedKeys="true" keyColumn="user_id" keyProperty="userId"> insert into `user` (user_name,u_status) values <foreach collection="list" item="item" separator=","> (#{item.userName},#{item.uStatus}) </foreach> </insert>insert into `user` (user_name,u_status) values (?,?) , (?,?)7、两个内置参数(_parameter,_databaseId)
_parameter:代表整个参数
- 单个参数:_parameter就是这个参数
- 多个参数:参数会被封装为一个map;——parameter就是代表这个map
- _parameter 用来判断user是否为null
<!-- public Integer updateUser(User user);--> <update id="updateUser" parameterType="user"> <if test="_parameter != null"> update `user` <set> <if test="userName != null and userName != ''"> , user_name = #{userName} </if> <if test="uStatus != null"> , u_status = #{uStatus} </if> </set> where user_id = #{userId} </if> </update>
_databaseId:如果配置了databaseIdProvider标签
<!--配置数据库别名--> <databaseIdProvider type="DB_VENDOR"> <property name="MySQL" value="mysql"/> <property name="Oracle" value="oracle" /> </databaseIdProvider>- _databaseId就是代表当前数据库的别名
<!-- public Map<Integer,User> getUserMap();--> <select id="getUserMap" resultType="map"> <if test="_databaseId == 'mysql'"> select * from `user` </if> <if test="_databaseId == 'oracle'"> select user_id from `user` </if> </select>8、bind标签使用
可以将OGNL表达式的值绑定到一个变量中,方便后来引用这个变量的值
可以把’%’+userName+’%’绑定一个新的名称_userName<!-- public User getUser(Integer userId,String userName);--> <select id="getUser" resultType="user"> <bind name="_userName" value="'%'+userName+'%'"/> select * from `user` where user_id = #{userId} and user_name like #{_userName} </select>9、sql标签,include(引入)
抽取可重用的sql片段。方便后面引用
- _databaseId就是代表当前数据库的别名
sql抽取公共的sql语句,里面可以使用include传递过来的值,也可以使用_parameter和_databaseId的值,
- include可以sql语句片段,并且可以传递值
生成语句<!-- public Integer addUsers(List<User> users);--> <insert id="addUsers" parameterType="list" useGeneratedKeys="true" keyColumn="user_id" keyProperty="userId"> insert into `user` ( <include refid="insertField"> <property name="list" value="#{list}"/> </include> ) values <foreach collection="list" item="item" separator=","> (#{item.userName},#{item.uStatus}) </foreach> </insert> <!--也可以引入 和判断参数--> <sql id="insertField"> <if test="_databaseId == 'mysql'"> <if test="_parameter != null and list != null"> user_name,u_status </if> </if> </sql>insert into `user` ( user_name,u_status ) values (?,?) , (?,?)
7、缓存机制
1、简介
MyBatis包含一个非常强大的查询缓存特性,它可以非常方便的配置和定制。缓存可以极大的提升查询效率。
MyBatis系统中默认定义了两级缓存
-
2、一级缓存(本地缓存)
与数据库同一次会话期间查询到的数据会存放在本地缓存中,以后如果需要获取相同的数据,直接从缓存中拿,没必要再去查询数据库
sqlSession级别的缓存,底层是一个map,一级缓存是一直开启的,无法关闭
@Test public void testFirstLevelCache(){ SqlSession sqlSession = null; try { SqlSessionFactory sqlSessionFactory = getSqlSessionFactory(); sqlSession = sqlSessionFactory.openSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); List<User> userList = mapper.getUserList(); List<User> userList1 = mapper.getUserList(); System.out.println(userList); System.out.println(userList1); System.out.println(userList.equals(userList1)); } catch (Exception e) { e.printStackTrace(); } finally { if (sqlSession != null){ sqlSession.close(); } } }1、一级缓存失效
当sqlSession不同的时候会失效
- 当sqlSession相同,查询条件不同的时候也会失效
- sqlSession相同,两次查询之间执行了增删改操作,也会失效,重新查询
sqlSession相同,手动清除了一级缓存sqlSession.clearCache();
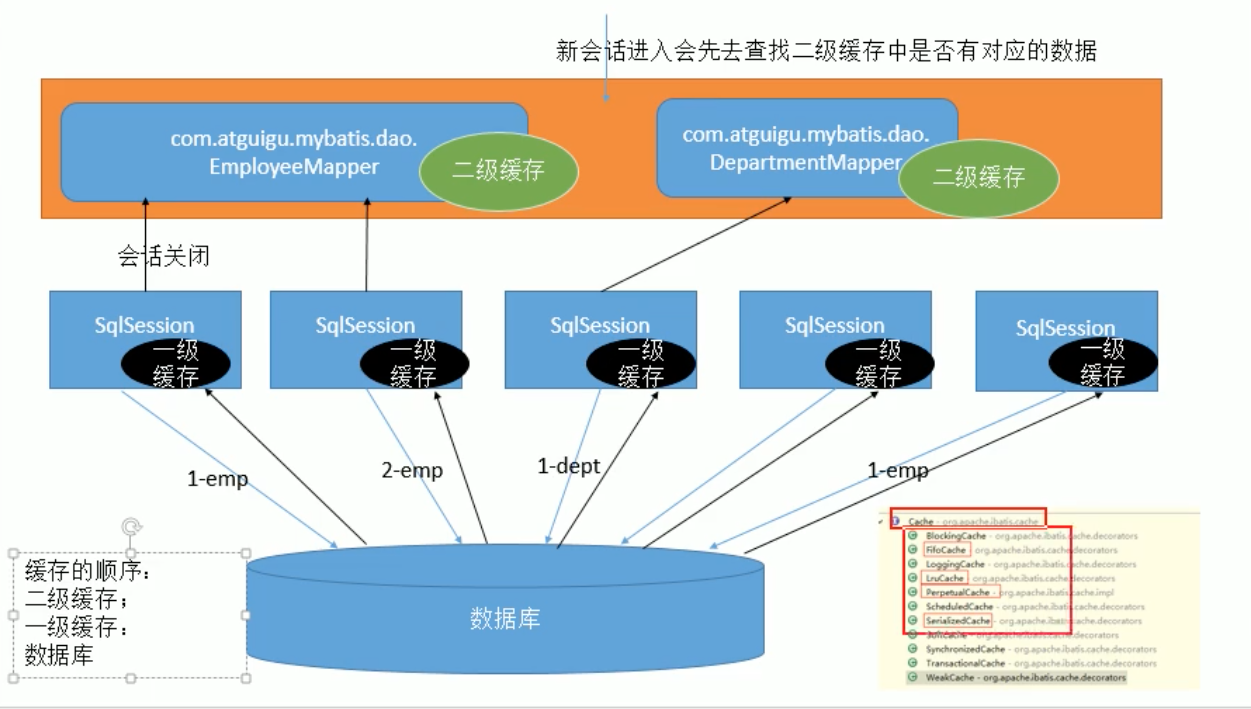
3、二级缓存(全局缓存)
基于namespace级别的缓存,一个namespace对应一个二级缓存
1、工作机制
一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中
- 如果会话关闭了,一级缓存中的数据会被保存到二级缓存中,新的会话查询信息,就可以参照二级缓存
- 不同namespace查出的数据会被放在自己对应的缓存中(map)
之后匹配上的数据会从二级缓存中取出,但是一定是sqlSession关闭了此次的会话才会保存进二级缓存。
2、缓存配置开启
(1)开启全局二级缓存开关
cacheEnabled控制的是二级缓存,控制不了一级缓存(一级缓存无法关闭) | 设置名 | 描述 | 有效值 | 默认值 | | :—- | :—- | :—- | :—- | | cacheEnabled | 全局性地开启或关闭所有映射器配置文件中已配置的任何缓存。 | true | false | true |
<settings>
<!-- 开启缓存-->
<setting name="cacheEnabled" value="true"/>
</settings>
(2)在mapper.xml文件中配置使用二级缓存(不对具体的映射文件不配置cache不会开启缓存)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.daijunyi.mapper.UserMapper">
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
</mapper>
3、cache标签里面属性介绍
- eviction:
LRU– 最近最少使用:移除最长时间不被使用的对象。FIFO– 先进先出:按对象进入缓存的顺序来移除它们。SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
- flushInterval:缓存刷新间隔,缓存多长时间清空一次,默认不清空,设置一个毫秒值
- readOnly:是否只读,(只读)属性可以被设置为 true 或 false。
- true:只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。
- false:而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
- size:缓存存放多少元素
-
4、缓存相关控制
全局配置sessting中cacheEnabled:控制的是二级缓存,一级缓存控制不了
- 映射文件中select标签中userCache=“true”
- false: 不是用缓存(控制二级缓存,一级缓存不控制)
- 每个增删改标签上都有一个:flushCache=“true”清除缓存,默认是true,增删改执行完成之后一级缓存和二级缓存都会清除,查询标签默认flushCache默认是false的。所以查询不会清理缓存
- sqlSession.clearCache();只是清理当前session的一级缓存,不会清理二级缓存
- localCacheScope:本地缓存作用域(一级缓存Session)
- SESSION,会缓存一个会话中执行的所有查询
- STATEMENT,本地缓存将仅用于执行语句,对相同 SqlSession 的不同查询将不会进行缓存。 | localCacheScope | MyBatis 利用本地缓存机制(Local Cache)防止循环引用和加速重复的嵌套查询。 默认值为 SESSION,会缓存一个会话中执行的所有查询。 若设置值为 STATEMENT,本地缓存将仅用于执行语句,对相同 SqlSession 的不同查询将不会进行缓存。 | SESSION | STATEMENT | SESSION | | :—- | :—- | :—- | :—- |
5、缓存原理
1、缓存查询顺序
- 二级缓存
- 一级缓存
- 数据库
2、Mybatis整合EhCache(缓存)
1、引入jar包
2、mybatis已经帮我们做好了各种缓存整合包
mybatis-ehcache
源码:https://github.com/mybatis/ehcache-cache
下载地址:https://github.com/mybatis/ehcache-cache/releases
再次导入ehcache
3、在映射文件中指定缓存器
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.daijunyi.mapper.UserPlusMapper">
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
<!-- void getUserById(Integer userId);-->
<select id="getUserById" parameterType="int" resultType="user">
select * from `user` where user_id = #{userId}
</select>
</mapper>

若有收获,就点个赞吧
0 人点赞
