- 视频地址
- 正则语法手册
- 参考文档
1、基础知道
1、元字符
1、元字符是构造正则表达式的一种基本元素
| 元字符 | 说明 | | —- | —- | | . | 匹配出换行符以外的任意字符 | | \w | 匹配字母或数字或下划线或汉字 | | \s | 匹配任意的空白符 | | \d | 匹配数字 | | \b | 匹配单词的开始或结束 | | ^ | 匹配字符串的开始 | | $ | 匹配字符串的结束 |
2、元字符练习
1、匹配有abc开头的字符串
\babc或者^abc
2、匹配8位数字的QQ号码
^\d\d\d\d\d\d\d\d$
3、匹配1开头11位数字的手机号码
^1\d\d\d\d\d\d\d\d\d\d$
2、重复限定符
1、把重复部分用合适的限定符替代,
| 语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
2、练习
1、匹配a开头,0个或多个b结尾的字符串
^ab*$
2、匹配邮箱
- 中间有个@符号后边有个.
^.+@.+\..+$3、匹配8位数字的QQ号码
^\d{8}$4、匹配11位手机号
^1\d{10}$3、分组
| 语法 | 说明 | | —- | —- | | (pattern) | 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)” |
上面的例子匹配a开头,0个或多个b结尾的字符串,我们想要ab同时被*限定怎么办
比如改成以0到多个ab开头
正则表达式中用小括号()来做分组,也就是括号中的内容作为一个整体
^(ab)*4、转义
| 语法 | 说明 | | —- | —- | | \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。串行“\\”匹配“\”而“\(”则匹配“(”。 |
如果要匹配的字符串本身就包含小括号,那是不是冲突了。
- 这个时候我们可以使用\来转义特殊符号,
- \:把限定符
假如要匹配是以(ab)开头的0次或多次
^(\(ab\))*
5、条件或
1、语法
| 语法 | 说明 |
|---|---|
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”。 |
2、练习
1、匹配身份证号码
15位数字或18位数字
^\d{15}$|^\d{18}$6、区间
1、语法
| 语法 | 说明 | | —- | —- | | [xyz] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 | | [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“p”。 | | [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 | | [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
限定0-9可以写成[0-9]
- 限定A-Z可以写成[A-Z]
- 限定某些数字[165]
2、练习
1、匹配字 字符 只要是 abc中的一个就行
^[abc]$2、断言
参考网址:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions/Assertions
| 语法 | 说明 |
|---|---|
| (?:pattern) | 匹配pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分是很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
| (?=pattern) | 正向肯定预查,返回匹配表达式前面部分,不返回本身。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
| (?<=pattern) | 反向肯定预查,返回匹配的表达式后部分,不返回本身。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 |
| (?<!pattern) | 反向否定预查,与正向否定预查类拟,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。 |
1、断言:
俗话的断言就是“我断定什么什么”, 而正则中的断言, 就是说正则可以指明在指定的内容的前面或后面会出现满足指定规则的内容,意思正则也可以像人类那样断定什么什么,比如”SS1aa2bb3”,正则可以用断言找出aa2前面有bb3, 也可以找出aa2后面有ss1.
2、零宽:
就是没有宽度, 在正则中,断言只是匹配位置,不占字符,也就匹配结果里是不会返回断言本身。
3、举例
1、使用正向先行断言(正前顾)
- 语法(?=Pattern)
- 作用:匹配pattern表达式的前面内容,不返回本身
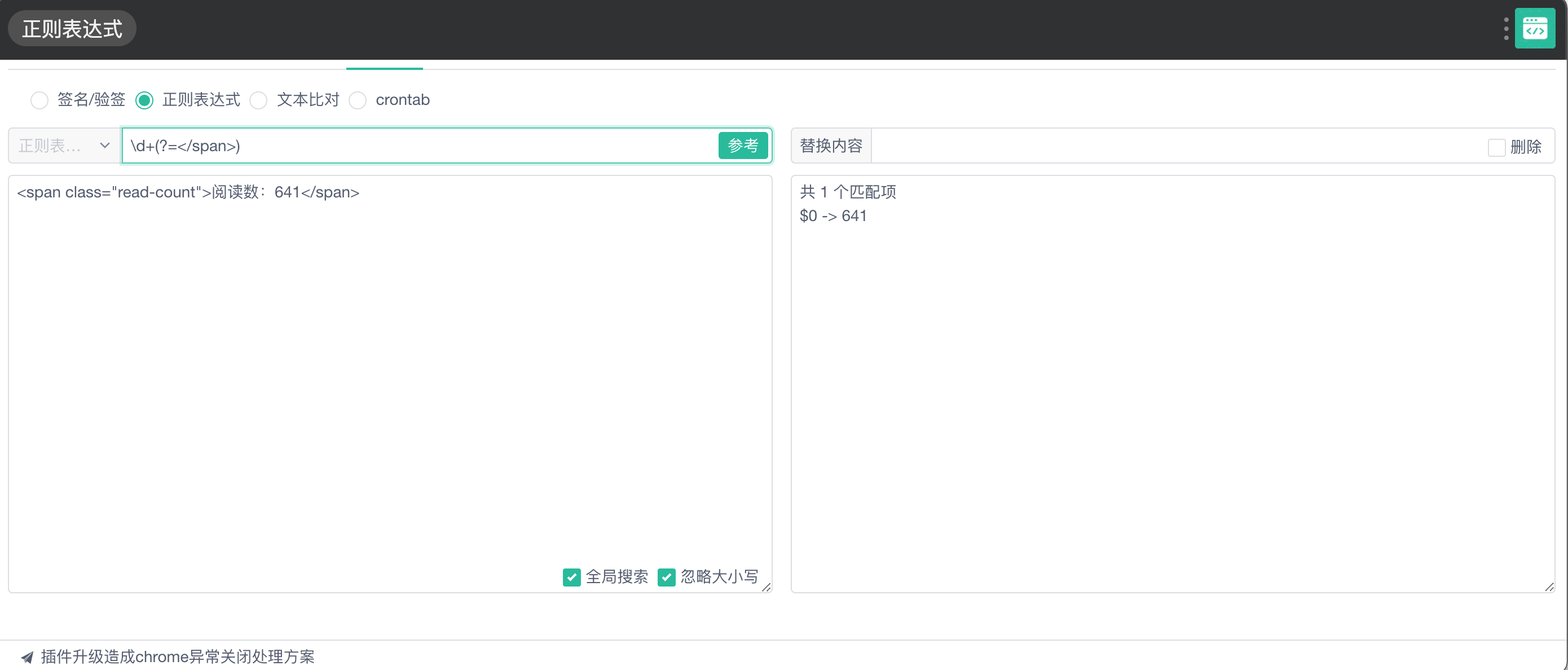
写一个正则
\d+(?=</span>)
- 运行结果就是641
2、使用后行断言(正后顾)
- 语法:(?<=pattern)
- 作用:匹配pattern表达式的后面的内容,不返回本身
有先行就有后行,先行是匹配前面的内容,那后行就是匹配后面的内容啦
上面的栗子,我们也可以用后行断言来处理.
(?<=<span class="read-count">阅读数:)\d+

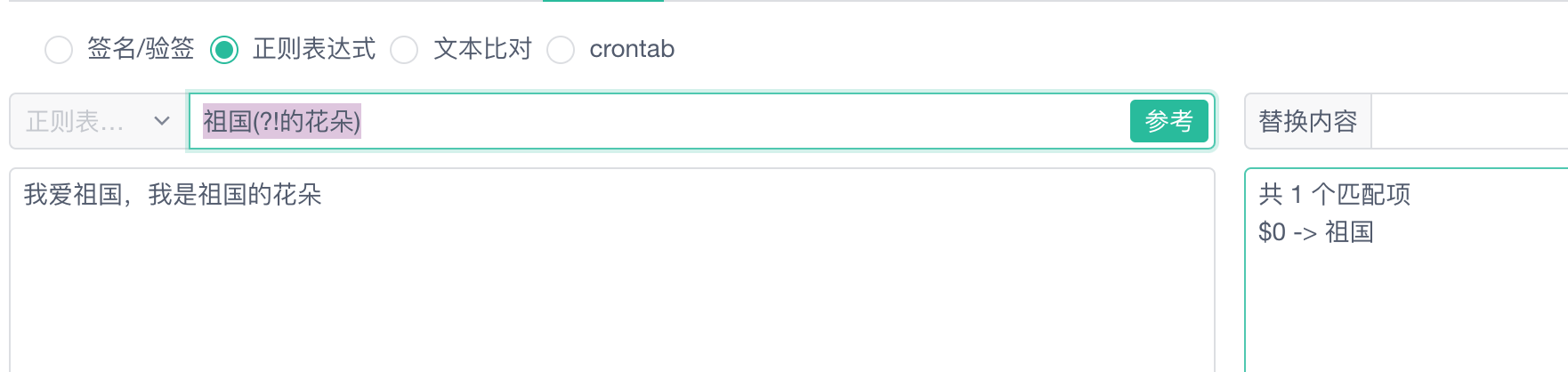
3、负向先行断言(负前瞻)
- 语法:(?!pattern)
- 作用:匹配非pattern表示是前面内容,不返回本身
有正向也有负向,负向就是非的意思(不是)

若有收获,就点个赞吧
0 人点赞
