官方网站:https://cassandra.apache.org
代码托管:https://github.com/apache/cassandra
Apache Cassandra是一个高度可扩展的高性能分布式数据库;
Cassandra的数据模型
列
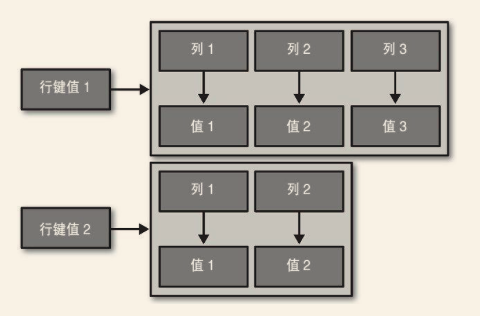
列(column)是Cassandra数据模型中的最基本数据结构单元。列是一个由名称,值和时钟构成的三元组,时钟可以看做一个时间戳。Cassandra中列名和行键值可以是字符串,也可以是长整数,UUID或其他任何类型的字节数组。这样的设计在存储“键值对”关系时(列名为键),不仅可以在“值”中存放有用的数据,在“键”中也同样可以。
行
假设一个用户表,需要有first_name,last_name,phone,email等列。在Cassandra中行时拥有某组列的集合的对象,每个行的唯一标识成为行键值(row key)。
宽行通常容纳自动生成的名字,如UUID或时间戳,用于存储一个列表。比如一个监控程序,你可以用一行来存放一个小时的时间片,使用修订的时间戳作为行键值,用列来存储这个时间段内访问应用的IP地址。这样,每小时会创建一个新的行键值。
窄行比较类似传统的RDBMS行,每行包含了类似的列的名字。与RDBMS行的区别在于,所有的列实际都是可选的。
宽行与窄行的另一个区别是,通常只有宽行才会考虑列名的排序问题。下节就讨论这个问题。
列族
列族(column family)是容纳一组有序的行的容器,每行都包含一组有序的列。列族和关系数据库中的表有着非常大的区别。Cassandra被认为是无scheme的,因为尽管定义了列族,但没有定义列。可以随意在列族中添加任意的列。其次列族有两个属性:名称和比较器(comparator)。比较器是在查询数据时返回的列的排序方式,可以根据long,byte,UTF8或其他方式排序。
列族的选项:
- keys_cached
每个SSTable中缓存的位置数量信息。这里指的不是列的名-值对的数量,而是键值的数量,同时列族中行的位置按照最近最少用(LRU)的方式缓存在内存中。
- rows_cached
缓存进内存中的整行内容的数量,包括每个行键值对应的所有名值对的列表。
- comment
注释信息
- read_repair_chance
一个介于0和1之间的值。当执行查询操作而没有指定读时检验要求的一致副本数(quorum),致使两个以上副本返回的一行数据的值出现歧义时,这个值决定了进行读修复操作的概率。当读操作比写操作多很多时,你可能会希望这个概率低一些。
- preload_row_cache
超级列族
一个列族中的一行是一个名/值对的集合,而超级列族中的列还包含有一组子列。所以在普通的列族里找到一个值对应的可以通过行键值和列名来确定,而在一个超级列族中寻址需要行键值,列名和子列名。超级列族仍然包含列,只是每个列里拥有子列。如下图中的1,2,3关系。超级列只允许使用一层。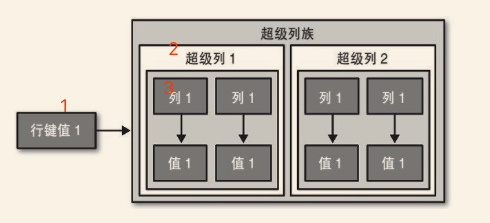
Keyspace
集群是keyspace的容器,而且里面通常只有一个keyspace。keyspace是Cassandra中数据的最外层容器,和关系型数据库的概念非常接近。与关系型数据库类似,keyspace有一个名字和一些定义了整个keyspace范围的全局行为的属性。可以针对keyspace设置的基本属性有如下几个。
- 副本因子(Replication factor)
副本因子是每行数据会复制到多少个节点上。副本因子决定了为一致性付出多少性能的代价。
- 副本放置策略(Replication placement strategy)
副本放置策略是指数据的副本如何分布到环上。Cassandra本身有多种可选的放置策略,用于决定键值到节点的映射方式。策略包含:SimpleStrategy(简单策略,之前称为RackUnawareStrategy,非机架感知策略)、OldNetworkTopologyStrategy(旧网络拓扑策略,之前称为RackAwareStrategy,机架感知策略)和NetworkTopology- Strategy(网络拓扑策略,之前称为DatacenterShardStrategy,数据中心分片策略)。
- 列族(Column families)
与数据库是表的容器类似,keyspace是一个或多个列族的容器。列族就类似于关系型数据库里的表,是集合了很多行的容器。每一行都有一些有序的列。列族的设置就呈现了数据结构,每个keyspace都至少有一个列族,而通常会有多个列族。这里,我提到副本因子和副本放置策略是因为它们都是每个keyspace的设置。但是,它们并不直接影响数据模型本身。虽然一般不建议这么做,但可以为一个应用创建多个keyspace。通常只有希望为不同的列族设置不同的副本因子和副本放置策略的时候,才会考虑让同一个应用使用多个不同keyspace。比如,对于一些低优先级的数据,可以将它们单独放在一个设有较低副本因子的keyspace当中,这样就可以减少一些 Cassandra复制这些数据的工夫。但是这样或许增加了太多的复杂度,有可能得不偿失。一个更好的选择大概是开始只建立一个keyspace,视需求再决定是否有必要调整到那个级别。
集群
Cassandra的最外层结构就是集群(cluster),有时也叫做环(ring),因为Cassandra将集群中的节点组织成一个环,并依次来分配数据到集群中节点上。每个节点会存放部分数据的一个副本。如果一个节点宕机,它的另一个副本可以响应查询请求。
Cassandra与RDBMS的设计差别
- 没有查询语句。
- 没有引用完整性,没有join,没有级联删除概念。
- 排序成为一种设计决策,排序依据列族定义中的CompareWith配置元素。
- 反范式化。
设计模式
- 人们通常使用Cassandra的方法,可以归纳为设计模式:具体化视图,无值列和聚合键。
具体化视图
比如有一个User 列族,现在你希望通过所在城市来搜索用户,那么就可以创建一个称为UserCity 的第二列族,以城市为键值(而非以用户为键值)存放用户数据,它的列以居住在这个城市的用户的名字来命名。这个反范式化技术将会加快查询,这就是一个围绕查询方式设计数据模型的例子(而非反向进行)。这种使用方式在Cassandra中非常常见。当希望通过城市查询用户的时候,只要查询UserCity 列族就可以了,而不用去查询User 列族,然后跨过一个可能很大的数据集,在客户端上做很多琐碎的工作。
ps: 0.7版本,Cassandra原声支持了第二索引,后续更新。
无值列
现在,我们在User/UserCity 例子上继续前进。因为在User 列族中存放了引用信息,这就出现两个问题:首先,需要唯一且完备的键值,以此来达到引用一致性;其次,UserCity 列族中的列实际不需要值。如果你有一个行键值Boise,那么列的名字可以是这个城市里的所有用户名字。因为引用的数据来自于User 列族,所以这些列自己就不需要存储什么值了,你只把它用做一个列表,至于列表中其他相关的附加信息,都可以从被引用的列族中获取。
聚合键
当使用无值列模式时,可能还希望同时使用聚合键模式。这个模式把两个标量值以一个分隔符连在一起来创建一个聚合。现在继续扩展我们的例子。城市的名字常常不具有唯一性,美国的很多州都有叫Springfield的城市,得克萨斯州和田纳西州也都有叫巴黎的城市。所以,如果把州的名字和城市的名字融合到一起创建一个聚合键就好多了,可以用在具体化视图之中。这些键值可能会像:TX:Pari s和TN:Paris 这样。在传统上,很多Cassandra用户都使用冒号作为分隔符,不过使用管道符或是其他的没有歧义的字符都可以。
小结
本章,我们循序渐进地讲解了Cassandra的数据模型,包括keyspace、列族、列以及超级列等概念。我们还了解了一些RDBMS与Cassandra的不同之处。
参考
中文社区:中国Cassandra技术社区
http://www.cassandra123.com
博客园:Cassandra系列
https://www.cnblogs.com/youzhibing/tag/cassandra
W3Cschool:Cassandra教程
https://www.w3cschool.cn/cassandra/cassandra_introduction.html
CSDN:Cassandra、HBase和MongoDB性能比较
https://blog.csdn.net/lihe55966/article/details/51375413
https://jaxenter.com/evaluating-nosql-performance-which-database-is-right-for-your-data-107481.html
CSDN:三大NoSQL数据库HBase、Cassandra和MongoDB大比拼
https://blog.csdn.net/kwame211/article/details/83624276
CSDN:我们为什么选择了Cassandra而没有用Hbase
https://blog.csdn.net/mshootingstar/article/details/47127747
阿里云开发者社区:Apache Cassandra从入门到精通
https://developer.aliyun.com/article/699492

若有收获,就点个赞吧
0 人点赞
