简介
在计算机科学中,trie,又称前缀树或字典树,是一种有序树),用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
Trie这个术语来自于retrieval。根据词源学,trie的发明者Edward Fredkin把它读作/ˈtriː/ “tree”。但是,其他作者把它读作/ˈtraɪ/ “try”。
原理
在图示中,键标注在节点中,值标注在节点之下。每一个完整的英文单词对应一个特定的整数。Trie可以看作是一个确定有限状态自动机,尽管边上的符号一般是隐含在分支的顺序中的。键不需要被显式地保存在节点中。图示中标注出完整的单词,只是为了演示trie的原理。
trie中的键通常是字符串,但也可以是其它的结构。trie的算法可以很容易地修改为处理其它结构的有序序列,比如一串数字或者形状的排列。比如,bitwise trie中的键是一串比特,可以用于表示整数或者内存地址。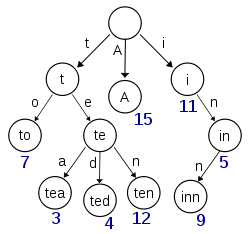
- 概括
tire树是为了快速查询一组字符串中是否含有一个字符串的结构,是以空间换取时间。tire树的每个节点有26个子节点(对应26个字母,不过也可以是根据实际进行改变) , 根节点不储存数值,而除了根节点以外的节点存储{一个字母,指向儿子的指针,以及一个bool类型判断是否是一个单词的末尾。
- 插入
从根节点开始,按照需插入字符串从左到右的顺序,第一个字母是第二层(第一层是根节点),第二个字母是第三层,以此类推,如果没有某个字母的节点,就新建一个。在最后的叶节点加一个标志表示其一个单词的末尾。
- 查找
按照需插入字符串从左到右的顺序,在搜索字符串的末端时,判断节点的标记是否是单词的末尾。
- 删除
我用的删除方法写起来相对简单(不过可能时间复杂度高一点(再高也是O(n))):
在节点中储存节点(字符)出现的次数,当删除某个字符串时,每个节点出现的次数减一,消除字符串末尾的节点的标志,再从字符串末尾的节点开始把计数(字符出现次数)为零的节点删去。
代码实现(Java版)
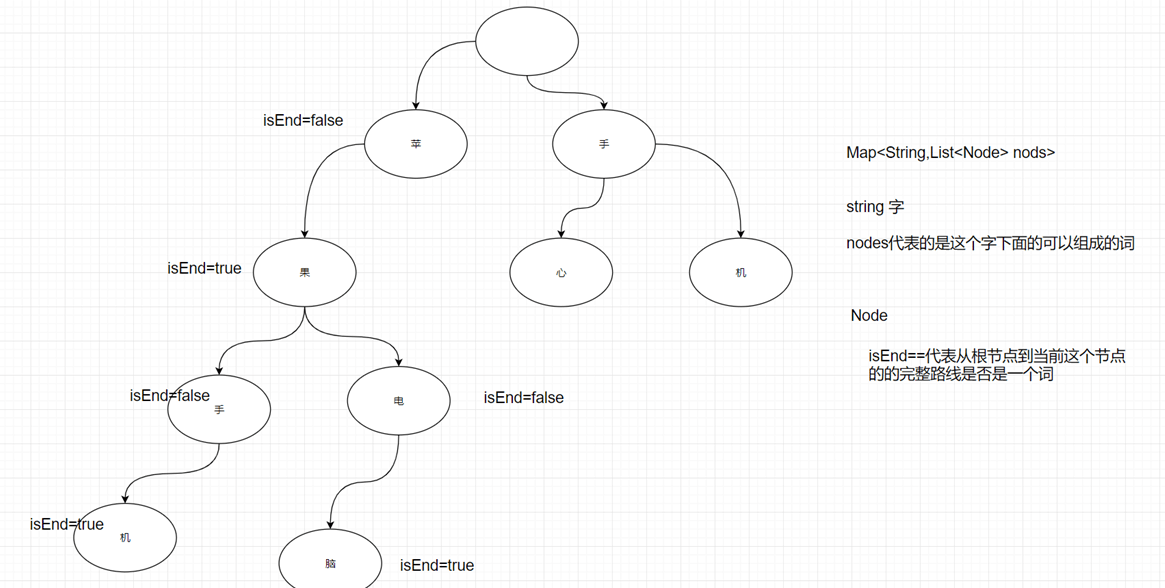
Node.java
import lombok.Data;import java.util.LinkedList;/*** 字典树的节点*/@Datapublic class Node {private char content; // 存在当前节点的字private boolean isEnd; // 是否是词的结尾private int count; // 这个词在这个字下面的分支的个数private LinkedList<Node> childList;// 子节点/**** @Description: 构造方法(初始化节点使用)*/public Node(char c){childList=new LinkedList<>();isEnd=false;content=c;count=0;}/***** @Description: 提供一个遍历node中的linkedList中是否有这个字。有就意味着可以继续查找下去,没有就没有*/public Node subNode(char c){if(null!=childList&&!childList.isEmpty()){for (Node node : childList) {if(node.content==c){return node;}}}return null;}}
TrieTree.java
/*** 字典树*/public class TrieTree {private Node root;// 根public TrieTree(){root=new Node(' '); // 构造一个空的根节点}/**** @Description: 查询* @Param: word 要判断的词*/public boolean search(String word){Node current=root; // 从根节点开始找if(null!=word){// 转成字符数组char[] chars = word.toCharArray();if(null!=chars&&chars.length>0){for (char c : chars) {Node node = current.subNode(c);if(null==node){ // 如果返回的子节点为空 说明不存在return false;}else{current=current.subNode(c);}}// 判断当前节点是否是结束节点if(current.isEnd()){return true;}else{return false;}}else{return false;}}else{return false;}}/**** @Description: 插入方法,先判断是否有这个词,(通过上面的写的查询方法) 如果没有,就一个个按顺序判断里面的字* 如果有这个字,继续判断下一个,当没有字个字的时候,new Node对象,放到上一个字的LindkedList里面* @Param: [word] 要插入的分词*/public void insert(String word){ //华为电脑// 判断有没有这个词 有就直接说这个词在整个字典数已存在if(this.search(word)){return;}// 如果不存在 ,就从根节点一个个找Node current=root;if(null!=word){char[] chars = word.toCharArray();if(null!=chars&&chars.length>0){for (char c : chars) {Node child = current.subNode(c);if(null!=child){current=child;}else{// 构造新的current.getChildList().add(new Node(c));current=current.subNode(c);}current.setCount(current.getCount()+1); // 分支数加一}// 循环结束之后把最后一个字变成isEnd:truecurrent.setEnd(true);}}}/**** @Description: 删除分词* @Param: [word] 要删除的分词*/public void deleteWord(String word) {// 查询一个词在不在字典树if (this.search(word) == false) {return;}Node current = root;if (null != word) {char[] chars = word.toCharArray();if (null != chars && chars.length > 0) {for (char c : chars) {Node node = current.subNode(c);if (node.getCount() == 1) {current.getChildList().remove(node);return;} else {current.setCount(current.getCount() - 1); // 分支数减一current = node;}}current.setEnd(false); // isend设置为false代表当前链路上的字连起来不是一个词了}}}}
测试类
public class TestTrieTree {public static void main(String[] args) {String content="华为-华为手机-华为平板-华为牛逼-鸿蒙-华为鸿蒙操作系统";// 模拟分词String[] split = content.split("-");// 构造字典树TrieTree trie = new TrieTree();// 把分词插入for (String s : split) {trie.insert(s);}System.out.println(trie.search("华为"));System.out.println(trie.search("华为手"));// 删除分词trie.deleteWord("华为");System.out.println(trie.search("华为"));System.out.println(trie.search("华为手机"));}}
参考
https://zh.wikipedia.org/wiki/Trie
https://www.cnblogs.com/end/archive/2013/01/21/2870161.html

若有收获,就点个赞吧
0 人点赞
