官网:http://www.tpc.org/tpc_documents_current_versions/current_specifications.asp
概述
TPC-DS 是基于SQL的大数据系统基准测试标准,是一套决策支持系统测试基准,主要针对零售行业。提供99个SQL查询,分析数据量大,测试数据与实际商业数据高度相似,同时具有各种业务模型(分析报告型,数据挖掘型等等)。

Hadoop等大数据分析技术也是对海量数据进行大规模的数据分析和深度挖掘,也包含交互式联机查询和统计报表类应用,同时大数据的数据质量也较低,数据分布是真实而不均匀的。因此TPC-DS成为客观衡量多个不同Hadoop版本以及SQL on Hadoop技术的最佳测试集。这个测试集包含对大数据集的统计、报表生成、联机查询、数据挖掘等复杂应用,测试用的数据和值是有倾斜的,与真实数据一致。主要特点如下:
- 一共99个测试案例,遵循SQL’99和SQL 2003的语法标准,SQL案例比较复杂。
- 分析的数据量大,并且测试案例是在回答真实的商业问题。
- 测试案例中包含各种业务模型(如分析报告型,迭代式的联机分析型,数据挖掘型等)。
- 几乎所有的测试案例都有很高的IO负载和CPU计算需求。
数据模式
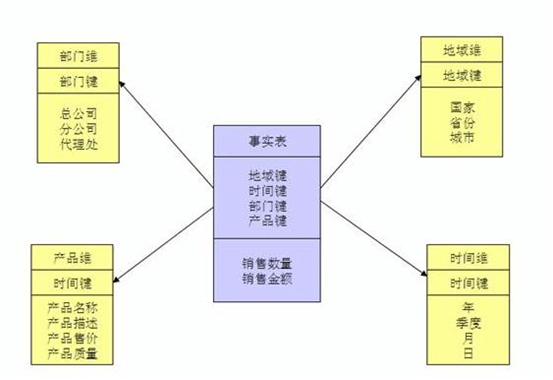
TPC-DS采用星型、雪花型等多维数据模式。
星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的“层次” 区域,这些被分解的表都连接到主维度表而不是事实表。如图,将地域维表又分解为国家,省份,城市等维表。它的优点是 : 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。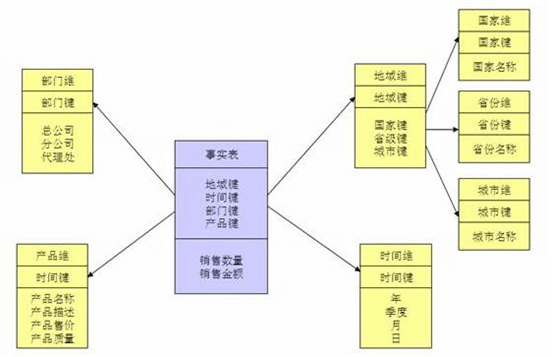
型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现 都比较简单。 雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数 据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
组成

事实表

若有收获,就点个赞吧
0 人点赞
