简介
Hive最早由Facebook开源,用于解决海量结构化日志的数据统计。Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储(将结构化的数据文件映射为一张表)、查询(类SQL)和分析存储在Hadoop中的大规模数据的机制。通俗的讲就是:解析用户编写的HQL,匹配对应的**Hive内置**MapReduce模板,之后由Yarn执行模板对应的MR任务,数据存储在HDFS之上。
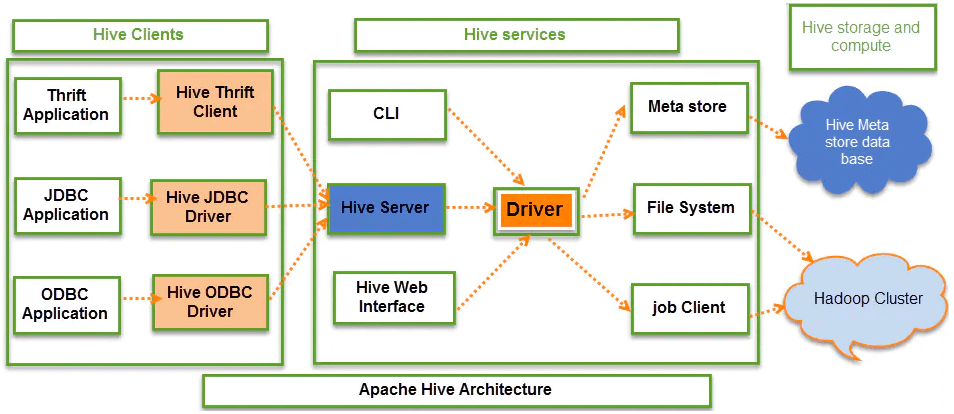
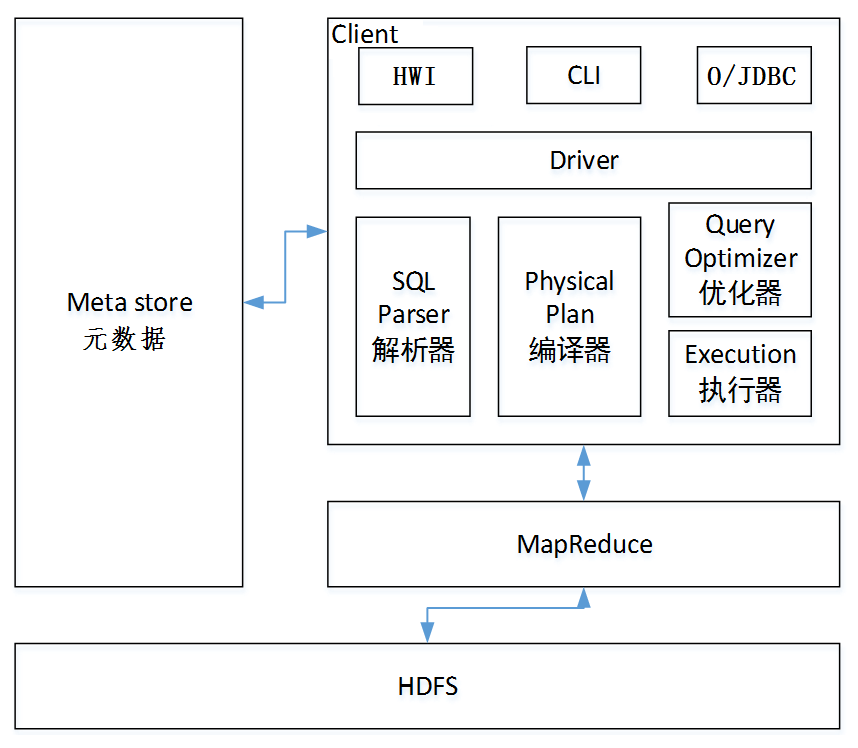
| 组成 | 组件 | 描述 |
|---|---|---|
| 客户端 | CLI | 命令行,即hive shell |
| JDBC/ODBC | java访问hive | |
| Beeline CLI | thrift方式访问hive | |
| WebGUI | 通过浏览器访问Hive | |
| 元数据 | Derby(默认) | Hive将元数据存储在数据库中。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。默认存储在自带的**Derby数据库中(Derby只允许单进程访问),推荐使用MySQL**存储Metastore。 |
| MySQL(5.6.17+) | ||
| Postgres(9.1.13+) | ||
| Oracle(11g+) | ||
| MS SQL Server(2008 R2+) | ||
| 驱动器 | SQL |
Parser | 解析器:将SQL字符串转换成抽象语法树(AST),这一步一般都用第三方工具库完成,比如Druid、antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。 | | | Physical Plan | 编译器:将AST编译生成逻辑执行计划。 | | | Query Optimizer | 优化器:对逻辑执行计划进行优化。 | | | Execution | 执行器:把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Tez/Spark/Flink。 |
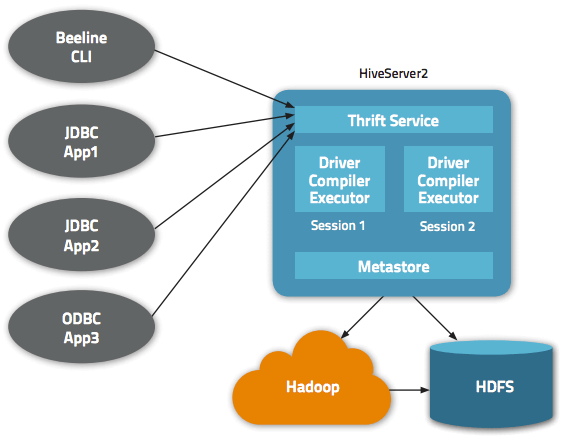
说明:下图中的Hive Service对应进程“RunJar”,__指的是CLI或Beeline。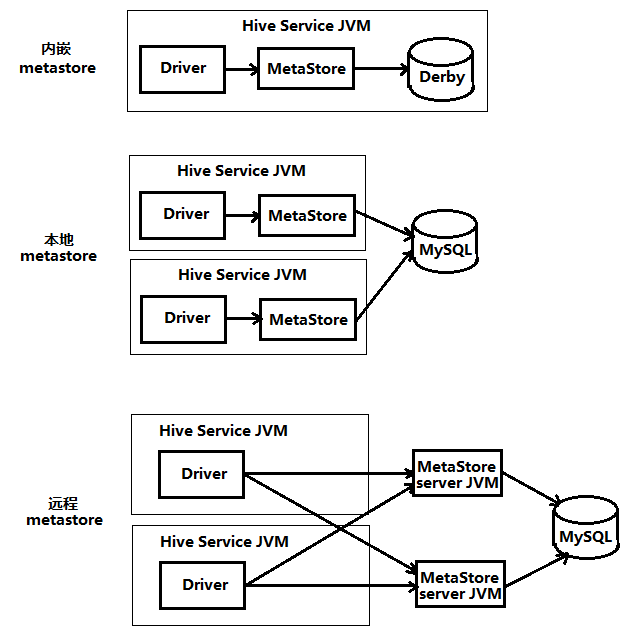
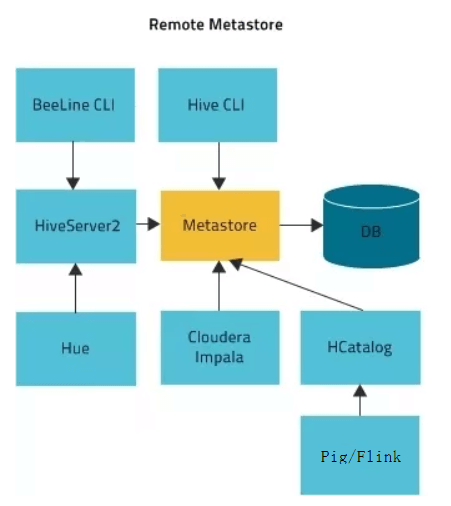
总结:
- 单机使用CLI时,不需开启Metastore和HiveServer2服务。
- 单机使用Beeline时,则只需开启服务端HiveServer2__服务。
- 集群使用Hive时,如果仅提供客户端CLI访问,则只需开启服务端Metastore服务。
集群使用Hive时,如果仅提供客户端Beeline访问,则只需开启服务端HiveServer2服务。
优缺点
| 优点
| 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手),避免了MapReduce编程,减少了开发人员的学习成本。 | | :—-: | —- | | | 适合处理大规模离线分析计算任务。 | | | 统一的元数据管理,可与其他大数据组件共享(Impala/Spark/Flink) | | | 易扩展集群规模,且Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。 | | 缺点
| Hql表达能力有限(迭代式算法无法表达,数据挖掘方面不擅长)。 | | | Hive的效率比较低(Hive自动生成的MapReduce作业,通常情况下不够智能化,调优比较困难,粒度较粗)。 | | | 不适用OLTP场景,暂不支持列级别添加、更新、删除。 |
对比传统数据库
| 比较项 | Hive | RDBMS |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 数据更新 | 读多写少(尾写、覆写) | DML全面支持 |
| 执行引擎 | MapReduce | Excutor |
| 延迟 | 高(亚秒级、分钟级) | 低(秒级、亚秒级) |
| 处理数据规模 | 大 | 小 |
| 索引 | 位图索引 | 复杂索引 |
| 事务 | 不支持 | 支持 |
| 函数 | 二百左右(内置)、UDF、UDAF、UDTF | 数百(内置)、自定义函数、存储过程 |

若有收获,就点个赞吧
0 人点赞
