引言
HBase
在HBase中,表的RowKey按照字典排序, Region按照RowKey设置split point进行shard,通过这种方式实现的全局、分布式索引. 成为了其成功的最大的砝码。然而单一的通过RowKey检索数据的方式,不再满足更多的需求,查询成为HBase的瓶颈,人们更加希望像sql一样快速检索数据,可是,HBase之前定位的是大表的存储,要进行这样的查询,往往是要通过类似Hive、Pig等系统进行全表的MapReduce计算,这种方式既浪费了机器的计算资源,又因高延迟使得应用黯然失色。于是,针对HBase Secondary Indexing的方案出现了。
Solr
Solr是一个独立的企业级搜索应用服务器,是Apache Lucene项目的开源企业搜索平台,其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr 4还增加了NoSQL支持,以及基于Zookeeper的分布式扩展功能SolrCloud。SolrCloud的说明可以参看:SolrCloud分布式部署。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
Solr可以高亮显示搜索结果,通过索引复制来提高可用性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
Key-Value Store Indexer
HBase Indexer全名为Lily HBase Indexer,是NGDATA公司为了将lily子系统里面相关HBase数据存储到Solr而开发的一个软件。这个组件非常关键,是Hbase到Solr生成索引的中间工具。在CDH5.3.2中的Key-Value Indexer使用的是Lily HBase NRT Indexer服务。
Lily HBase Indexer是一款灵活的、可扩展的、高容错的、事务性的,并且近实时的处理HBase列索引数据的分布式服务软件。它是NGDATA公司开发的Lily系统的一部分,已开放源代码。Lily HBase Indexer使用SolrCloud来存储HBase的索引数据,当HBase执行写入、更新或删除操作时,Indexer通过HBase的replication功能来把这些操作抽象成一系列的Event事件,并用来保证写入Solr中的HBase索引数据的一致性。并且Indexer支持用户自定义的抽取,转换规则来索引HBase列数据。Solr搜索结果会包含用户自定义的columnfamily:qualifier字段结果,这样应用程序就可以直接访问HBase的列数据。而且Indexer索引和搜索不会影响HBase运行的稳定性和HBase数据写入的吞吐量,因为索引和搜索过程是完全分开并且异步的。Lily HBase Indexer在CDH5中运行必须依赖HBase、SolrCloud和Zookeeper服务。
原理
HBase Indexer的主要作用是将HBase表里面的某些列(或者所有列)数据近乎实时地索引到SolrCloud里面。
为什么说近乎实时?因为HBase Indexer是依赖于HBase的replication功能来实现将数据索引到Solr里面的。HBase Indexer通过监听HBase WAL日志(WAL日志里面记录了所有对数据的增删改操作),将增删改操作事件转换成对应的Solr增删改操作。由于这个过程是异步进行的,并且重放HBase WAL日志本身就存在一定的延迟,所以才说HBase Indexer是近乎实时地将数据索引到Solr里面(我们可以类比MySQL Master/Slave架构,Slave与Master之间也会存在一定的延迟)。HBase Indexer集群可以看成是HBase高可用方案里面的Slave Cluster。
架构图
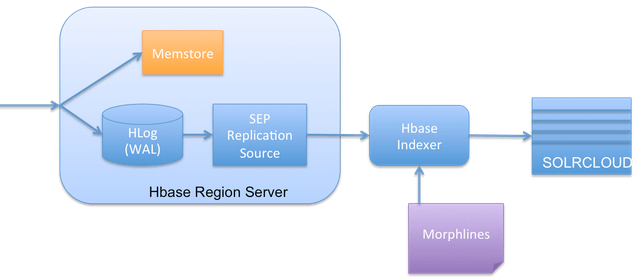
流程图
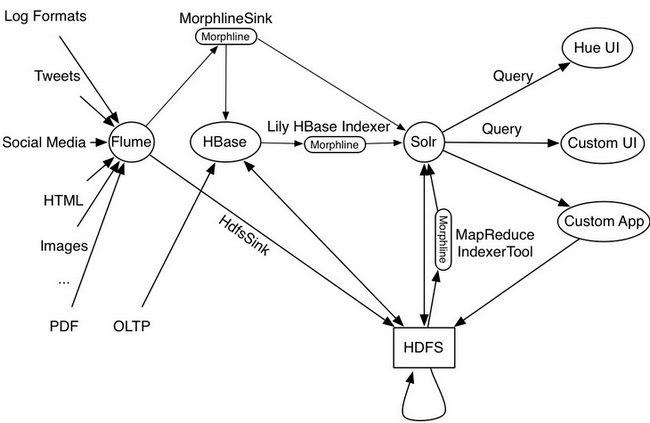
- 为什么选择Replication而不选择Coprocessor来实现HBase Indexer?
- HBase Replication的处理是由RegionServer开启独立的线程去处理的,处理方式是并行且异步的,依靠这种机制来实现HBase Indexer并不会给HBase带来入侵式的代码,而且不会影响写入性能。而通过Coprocessor来实现的话会给RegionServer带来入侵式代码,假如我们实现的逻辑出现问题,很可能会影响到HBase集群的性能(Coprocessor的实现至少会影响HBase集群的写性能),严重的情况还会导致整个HBase集群挂掉。
- 虽然选择Replication机制只能实现近实时的索引同步,但是这种实现方式具备很高的灵活性和可扩展性,对HBase集群的使用是几乎没有侵占性的。
参考
博客园:Key-Value Store Indexer(Lily HBase Indexer) 小型采坑
https://www.cnblogs.com/eviltuzki/p/9019095.html
CSDN:基于CDH的solr+Key-Value Store Indexer+HBase二级索引框架构建(1)
https://blog.csdn.net/yzh865318761/article/details/82898466
CSDN:基于CDH的Solr+Key-Value Store Indexer+HBase二级索引框架构建(2)离线数据HBase-BulkLoad-构建Solr索引简单优化
https://blog.csdn.net/yzh865318761/article/details/82899758
CSDN:Lily HBase Indexer使用整理
https://blog.csdn.net/kissmelove01/article/details/45196941
CSDN:HBase二级索引方案
https://blog.csdn.net/weixin_43892898/article/details/89249322
博文:CDH版本HBase二级索引方案Solr key value index_
https://www.cnblogs.com/thinkpad/p/5534627.html
博文:HBase Indexer整合Solr
http://www.niuchaoqun.com/14543825447680.html
博文:NRT(Near Real Time)Indexing using Cloudera Search And Lily HBase indexer
https://www.srccodes.com/nrt-near-real-time-indexing-cloudera-search-lily-hbase-indexer-morphline-apache-solr-lucene-tika-zookeeper

若有收获,就点个赞吧
0 人点赞
