前言
介绍HBase基本原理,拆分风暴,数据热点问题,RowKey设计,协处理器,参数调优,性能测试等,并结合MCBS-Demo演示HBase在项目中如何应用。

 什么是列式数据库
什么是列式数据库
列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理和即时查询。相对应的是行式数据库,数据以行相关的存储体系架构进行空间分配,主要适合于大批量的数据处理,常用于联机事务型数据处理。 列式数据数优缺点
列式数据数优缺点
| 优点 | - 极高的装载速度 (最高可以等于所有硬盘IO 的总和,基本是极限了)。 - 适合大量的数据而不是小数据。 - 实时加载数据仅限于增加(删除和更新需要解压缩Block 然后计算然后重新压缩储存)。 - 高效的压缩率,不仅节省储存空间也节省计算内存和CPU。 - 非常适合做聚合操作。 |
|---|---|
| 缺点 | - 不适合扫描小量数据。 - 不适合随机的更新。 - 批量更新情况各异,有的优化的比较好的列式数据库(比如Vertica)表现比较好,有些没有针对更新的数据库表现比较差。 - 不适合做含有删除和更新的实时操作。 |
1. HBase简介
HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以容错地存储海量稀疏的数据。
HBase在列上实现了BigTable论文提到的压缩算法、内存操作和布隆过滤器。HBase的表能够作为MapReduce任务的输入和输出,可以通过Java API来访问数据,也可以通过REST、Avro或者Thrift的API来访问。
Apache HBase最初是Powerset公司为了处理自然语言搜索产生的海量数据而开展的项目。不过现在它已经是Apache基金会的顶级项目,并且引起了广泛关注。Facebook在2010年11月选用了HBase来实现它新的消息平台。
2. HBase架构及原理
更详细的HBase架构及原理介绍请参考文档《[HBase]深入HBase架构解析.docx》。
2.1. 基本架构



HBase基本组件功能描述:
| 组件 | 功能描述 |
|---|---|
| HMaster | 指定region到regionserver 恢复故障的rs 负载均衡 |
| HReginServer | 携带0~n个region 负责客户端rw请求 管理region split 通知master新的子region 管理offline的父代region以及对其的替换 |
| Zookeeper | 提供hbase regionserver状态信息(是否在线) 存储系统表信息 容错,HMaster选举与主备切换 |
| Client | 提交rw请求 |
HBase、HDFS和MapReduce比较:
| 比较项 | HBase | HDFS2.0 | MR2.0 | MR1.0 |
|---|---|---|---|---|
| Master | HMaster | NameNode(NN) | ResourceManger(RM) | JobTracker(JT) |
| Node | HRegionServer(HRS) | DataNode(DN) | NodeManager(NM) | TaskTracker(TT) |
| 协调者 | ZooKeeper | ZooKeeper | ZooKeeper | 无 |
| HA | HMaster-backups | NN(Standby) | RM(Standby) | 无,存在单点故障 |
| 故障转移方式 | 1.HMaster与ZooKeeper直接通讯(谁先建立znode,则谁为active)2.HRegionServer与ZooKeeper直接通讯 | NM不与ZooKeeper直接通讯,ZKFC监控NM状态,ZKFC与ZK通讯,由ZKFC来参与选举(谁先建立znode,则谁为active) | RM直接与ZK直接通讯,谁先建立znode,则谁为active | 无,存在单点故障 |
| Node恢复和转移 | HMaster | NameNode | ResourceManager | JobTracker |
| Master与Node通讯 | HRegionServer与ZK心跳,HMaster从ZK获取HRS状态 | DN周期性向NN汇报 | NM周期性向RM汇报 | TT周期性向JT汇报 |
| Master任务 | 分配HRegionServer上的Region | 分配DN的block | 分配NM上container上的任务 | 分配TaskTracker上的task |
| 负载均衡 | HRS上region的负载均衡 | block的负载均衡 | ||
| 写模式 | 随机写,批量新增 | 仅追加 | ||
| 读模式 | 随机读,范围扫描/表扫描 | 全表扫描/分区表扫描 | ||
| Hive性能 | 4-5x slower | 很好 | ||
| 结构化存储 | 松散列族数据模型 | 自己设定/tsv/seqfile/avro | ||
| 数据规模 | ~1PB | 30+PB | ||
| 特点 | 1.Region的预分区、分裂和合并2.Compaction机制3.WAL机制4.读写流程 | 1.副本策略2.数据写入的副本管道传输机制3.联邦制 | 1.资源调度和应用管理独立进程2.NM上节点资源由NM管理,ApplicationManager和 AppliactionMaster管理任务3.container概念 | 1.将资源划分为等量以slot为单位2.maptask和reducetask独立分配 |
总结:HBase和HDFS都具有良好的容错性和扩展性,都可以扩展到成百上千个节点。HDFS适合批处理场景,不支持数据随机查找,不适合增量数据处理,不支持数据更新。HBase适合需要对数据进行随机读/写操作的场景,支持大数据上的高并发操作,如每秒对PB级数据作上千次操作,只支持一些读写简单操作,不支持表关联、联合、复杂聚合等。
HBase与RDBMS比较:
| 比较项 | HBase | RDBMS |
|---|---|---|
| 数据类型 | 无数据类型,以字节码形式存储 | 有丰富的类型和存储方式 |
| 数据操作 | 简单的插入,查询,删除,清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,所以不能也没有必要实现表和表之间的关联等 | 通常有各种各样的函数,连接操作 |
| 存储模式 | 基于列存储的,每个列族都有几个文件保存,不同列族的文件是分离的 | 基于表格结构和行模式保存的 |
| 索引 | 仅支持RowKey | 任意列 |
| 查询语言 | Get/put/Scan | SQL |
| 事务 | 行级事务 | 多行ACID事务 |
| 安全 | 过程中操作 | 认证/授权 |
| 可伸缩性 | 能够轻易的增加或者减少硬件数量,并且对错误的兼容性比较高 | 需要增加中间层才能实现 |
| 吞吐量 | 百万级别 请求(交易)/每秒 | 1000s 请求(交易)/每秒 |
| 数据规模 | ~1PB | TBs |
2.2. 结构介绍

2.2.1 StoreFile
保存实际数据的物理文件,StoreFile 以HFile 的形式存储在HDFS 上。每个Store 会有一个或多个StoreFile(HFile),数据在每个StoreFile 中都是有序的。
2.2.2 MemStore
写缓存,由于HFile 中的数据要求是有序的,所以数据是先存储在MemStore 中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
2.2.3 WAL
由于数据要经MemStore 排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile 的文件中,然后再写入MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
2.3. 数据模型
HBase是一个类似Bigtable的分布式数据库,它是一个稀疏的长期存储的(存储在硬盘上)、多维度的、排序的映射表,这张表的索引是行关键字、列关键字和时间戳,HBase中的数据都是字符串,没有类型。
2.3.1. 概念视图
我们可以将一个表想象成一个大的映射关系,通过行健、行健+时间戳或行键+列(列族:列修饰符),就可以定位特定数据,HBase是稀疏存储数据的,因此某些列可以是空白的。
| Row Key | Time Stamp | Column Family:c1 | Column Family:c2 | ||
|---|---|---|---|---|---|
| 列 | 值 | 列 | 值 | ||
| r1 | t7 | c1:1 | value1-1/1 | ||
| t6 | c1:2 | value1-1/2 | |||
| t5 | c1:3 | value1-1/3 | |||
| t4 | c2:1 | value1-2/1 | |||
| t3 | c2:2 | value1-2/2 | |||
| t2 | t2 | c1:1 | value2-1/1 | ||
| t1 | c2:1 | value2-1/1 |
2.3.2. 物理视图
虽然从概念视图来看每个表格是由很多行组成的,但是在物理存储上面,它是按照列来保存的。<br />表:HBase数据的物理视图(1)
| Row Key | Time Stamp | Column Family:c1 | |
|---|---|---|---|
| 列 | 值 | ||
| r1 | t7 | c1:1 | value1-1/1 |
| t6 | c1:2 | value1-1/2 | |
| t5 | c1:3 | value1-1/3 |
表:HBase数据的物理视图(2)
| Row Key | Time Stamp | Column Family:c2 | |
|---|---|---|---|
| 列 | 值 | ||
| r1 | t4 | c2:1 | value1-2/1 |
| t3 | c2:2 | value1-2/2 |
需要注意的是,在概念视图上面有些列是空白的,这样的列实际上并不会被存储,当请求这些空白的单元格时,会返回null值。如果在查询的时候不提供时间戳,那么会返回距离现在最近的那一个版本的数据,因为在存储的时候,数据会按照时间戳来排序。<br />Region在RegionServer上的分布:<br />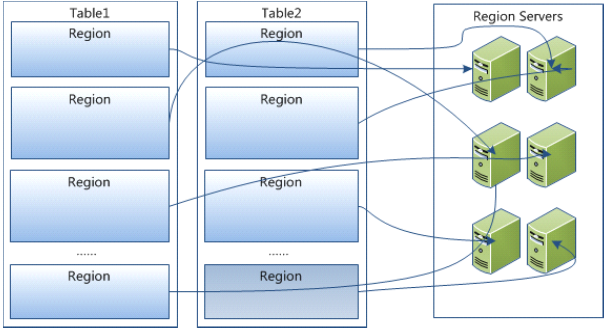<br />Region内部结构:<br />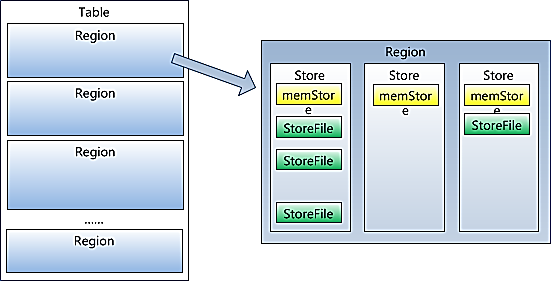<br /> **注意:对于同一个表,不同列族存放在不同的Region中。**
2.3.3. 命名空间
在关系数据库系统中,命名空间namespace指的是一个表的逻辑分组,同一组中的表有类似的用途。HBase中的命名空间类似于关系数据库,命名空间的概念为即将到来的多租户特性打下基础:
- 配额管理(Quota Management (HBASE-8410)):限制一个namespace可以使用的资源,资源包括region和table等;
- 命名空间安全管理(Namespace Security Administration (HBASE-9206)):提供了另一个层面的多租户安全管理;
- Region服务器组(Region server groups (HBASE-6721)):一个命名空间或一张表,可以被固定到一组regionservers上,从而保证了数据隔离性。
HBase有两个系统内置的预定义命名空间:
- hbase:系统命名空间,用于包含hbase的内部表。
- default:所有未指定命名空间的表都自动进入该命名空间。
命令空间管理:
#Create a namespacecreate_namespace 'my_ns'#create my_table in my_ns namespace, "fam"是列族create 'my_ns:my_table', 'fam'#drop namespacedrop_namespace 'my_ns'alter_namespace 'my_ns', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}
2.4. 存储引擎
 几种基本的存储引擎
几种基本的存储引擎
哈希存储引擎
代表数据库:redis、memcache等哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不需要有序的遍历数据,哈希表就是your Mr.Right。
B树存储引擎
代表数据库:MongoDB、mysql(基本上关系型数据库)等B树(关于B树的由来,数据结构以及应用场景可以看之前一篇博文)的持久化实现,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库(Mysql等)。
LSM树
代表数据库:nessDB、leveldb、hbase等存储引擎和B树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
LSM树是HBase里非常有创意的一种数据结构,它和传统的B+树不太一样。
 B+__树
B+__树
db2和Oracle的普通索引采用B+树的方式,下面是一个B+树的例子:
根节点和枝节点很简单,分别记录每个叶子节点的最小值,并用一个指针指向叶子节点。
叶子节点里每个键值都指向真正的数据块(如Oracle里的RowID),每个叶子节点都有前指针和后指针,这是为了做范围查询时,叶子节点间可以直接跳转,从而避免再去回溯至枝和跟节点。
B+树最大的性能问题是会产生大量的随机IO,随着新数据的插入,叶子节点会慢慢分裂,逻辑上连续的叶子节点在物理上往往不连续,甚至分离的很远,但做范围查询时,会产生大量读随机IO。对于大量的随机写也一样,举一个插入key跨度很大的例子,如7->1000->3->2000 … 新插入的数据存储在磁盘上相隔很远,会产生大量的随机写IO.
从上面可以看出,低下的磁盘寻道速度严重影响性能(近些年来,磁盘寻道速度的发展几乎处于停滞的状态)。 LSM__树
LSM__树
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。为了更好的说明LSM树的原理,下面举个比较极端的例子:
现在假设有1000个节点的随机key,对于磁盘来说,肯定是把这1000个节点顺序写入磁盘最快,但是这样一来,读就悲剧了,因为key在磁盘中完全无序,每次读取都要全扫描。那么,为了让读性能尽量高,数据在磁盘中必须得有序,这就是B+树的原理,但是写就悲剧了,因为会产生大量的随机IO,磁盘寻道速度跟不上。
LSM树本质上就是在读写之间取得平衡,和B+树相比,它牺牲了部分读性能,用来大幅提高写性能。它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。当读时,由于不知道数据在哪棵小树上,因此必须遍历所有的小树,但在每颗小树内部数据是有序的。
 LSM__树优化
LSM__树优化
以上就是LSM树最本质的原理,有了原理,就容易理解HBase一些设计上的原因:
为什么要有WAL(Write Ahead Log)?
因为数据是先写到内存中,如果断电,内存中的数据会丢失,因此为了保护内存中的数据,需要在磁盘上先记录logfile,当内存中的数据flush到磁盘上时,就可以抛弃相应的Logfile。
什么是memstore, storefile?
LSM树就是一堆小树,在内存中的小树即memstore,每次flush,内存中的memstore变成磁盘上一个新的storefile。
为什么会有compact?
随着小树越来越多,读的性能会越来越差,因此需要在适当的时候,对磁盘中的小树进行merge,多棵小树变成一颗大树,这样大部分老数据查询也可以直接使用log2N的方式找到,不需要再进行(N/m)*log2n的查询了。
为何使用Bloom filter?
布隆过滤器是带随即概率的bitmap,可以快速的告诉你,某一个小的有序结构里有没有指定的那个数据的。于是就可以不用二分查找,而只需简单的计算几次就能知道数据是否在某个小集合里,效率得到了提升,但付出的是空间代价。<br />**_补充:__WAL__清理机制_**
- Hlog通过LogRoller线程定期去检查并删除过期的日志文件。定期检查的时间间隔通过hbase.regionserver.logroll.period进行配置,默认为3600000ms=1小时。如果HLog已经失效(所有之前的写入MemStore已经持久化在HDFS),HLog存在于HDFS之上的文件会从/hbase/.logs转移至/hbase/.oldlogs, oldlogs会删除, HLog的生命周期结束。 - 在维护WAL的实例对象中,logSeqNum(FSHLog当中的一个递增的AtomicLong,每当往FSLog里面写入一条日志的时候,它都会加一)是一个重要的字段值, sequence number是作为StoreFile里的一个元数据字段,可以针对StoreFile直接得到longSeqNum;如果HLog的logSeqNum对应的HFile已经存储在HDFS了(主要是比较HLog的logSeqNum是否比与其对应的表的HDFS StoreFile的maxLongSeqNum小),那么HLog就没有存在的必要了.移动到.oldlogs目录,最后删除。反过来如果系统down了,可以通过HLog把数据从HDFS中读取,把原来要Put的数据读取出来, 重新刷新到HBase。 |
|---|
2.5. 关键流程
2.5.1. 写操作

写流程:
- Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
- 访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
- 与目标Region Server进行通讯;
- 将数据顺序写入(追加)到WAL;
- 将数据写入对应的MemStore,数据会在MemStore进行排序;
- 向客户端发送ack;
等达到MemStore的刷写时机后,将数据刷写到HFile。
2.5.2. MemStore Flush(刷写磁盘)

刷写流程:当某个memstroe的大小达到了“hbase.hregion.memstore.flush.size”(默认值128M),其所在region的所有memstore都会刷写。当memstore的大小达到了“hbase.hregion.memstore.flush.size(默认值128M)* hbase.hregion.memstore.block.multiplier(默认值4)”时,会阻止继续往该memstore写数据。
- 当region server 中memstore 的总大小达到“java_heapsize hbase.regionserver.global.memstore.size(默认值0.4) hbase.regionserver.global.memstore.size.lower.limit(默认值0.95)”,region 会按照其所有memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小到上述值以下。当region server中memstore的总大小达到“java_heapsize * hbase.regionserver.global.memstore.size(默认值0.4)”时,会阻止继续往所有的memstore 写数据。
- 到达自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置“hbase.regionserver.optionalcacheflushinterval(默认1 小时)”。
当WAL 文件的数量超过“hbase.regionserver.max.logs”,region会按照时间顺序依次进行刷写,直到WAL 文件数量减小到“hbase.regionserver.max.log”以下(该属性名已经废弃,现无需手动设置,最大值为32)。
2.5.3. 读操作

读流程:Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
- 访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
- 与目标Region Server 进行通讯;
- 分别在Block Cache(读缓存,LRU),MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
- 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为64KB)缓存到Block Cache。
-
2.5.4. StoreFile Compaction(合并)

由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
Compaction分为两种:Minor Compaction、Major Compaction。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,但不会清理过期和删除的数据。Major Compaction会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉过期和删除的数据。2.5.5. Region Split(拆分)
默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分(横向分割/水平分割,切片)。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。

拆分流程: 当1个region中的某个Store下所有StoreFile的总大小超过“hbase.hregion.max.filesize”,该Region就会进行拆分(0.94 版本之前)。
- 当1个region中的某个Store下所有StoreFile的总大小超过Min**(R^2 hbase.hregion.memstore.flush.size(默认值128M),hbase.hregion.max.filesize)*,该Region就会进行拆分,其中R为当前Region Server中属于该Table的个数(0.94 版本之后)。即:第一次总大小到达128M时,切片为:64M、64M;第二次到达521M时,切片为:64M、256M、256M,继续切分后,各个切片大小逐步产生数据倾斜问题(可通过预分区解决)。
3. HBase应用
3.1. 交互方式
| 交互方式 | 描述 | | —- | —- | | HBase Shell | HBase的命令行工具,最简单的接口,适合HBase管理使用。 | | Native Java API | 最常规和高效的访问方式。 | | MapReduce | 直接使用MapReduce作业处理Hbase数据; | | Thrift Gateway | 利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问HBase表数据。 | | REST Gateway | 支持REST 风格的Http API访问HBase, 解除了语言限制。 | | 第三方组件集成 | Hive\Pig处理HBase中的数据。 |
3.2. HBase shell
常用HBase shell命令参考文档《[**_HBase Shell_**](https://www.yuque.com/polaris-docs/bigdata/hbase-shell)》。
3.3. RowKey设计
HBase是三维有序存储的,通过rowkey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这个三个维度可以对HBase中的数据进行快速定位。HBase中rowkey可以唯一标识一行记录,在HBase查询的时候,有如下方式:<br />1、通过get方式,指定rowkey获取唯一一条记录;<br />2、通过scan方式,设置startRow和stopRow参数进行范围匹配;<br />3、全表扫描,即直接扫描整张表中所有行记录;
3.3.1. 设计原则
3.3.1.1. Rowkey长度原则
Rowkey是一个二进制码流,Rowkey的长度被很多开发者建议说设计在10~100个字节,不过建议是越短越好,不要超过16个字节。原因如下:
- 数据的持久化文件HFile中是按照KeyValue存储的,如果Rowkey过长比如100个字节,1000万列数据光Rowkey就要占用100*1000万=10亿个字节,将近1G数据,这会极大影响HFile的存储效率; - MemStore将缓存部分数据到内存,如果Rowkey字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。因此Rowkey的字节长度越短越好。 - 目前操作系统是都是64位系统,内存8字节对齐。控制在16个字节,8字节的整数倍利用操作系统的最佳特性。 |
|---|
3.3.1.2. Rowkey散列原则
如果Rowkey是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个Regionserver实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个 RegionServer上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。
3.3.1.3. Rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
3.3.2. 应用场景
基于Rowkey的上述3个原则,应对不同应用场景有不同的Rowkey设计建议。
3.3.2.1. 针对事务数据Rowkey设计
事务数据是带时间属性的,建议将时间信息存入到Rowkey中,这有助于提示查询检索速度。对于事务数据建议缺省就按天为数据建表,这样设计的好处是多方面的。按天分表后,时间信息就可以去掉日期部分只保留小时分钟毫秒,这样4个字节即可搞定。加上散列字段2个字节一共6个字节即可组成唯一 Rowkey。如下图所示:
| 事务数据Rowkey设计 | ||||||
|---|---|---|---|---|---|---|
| 第0字节 | 第1字节 | 第2字节 | 第3字节 | 第4字节 | 第5字节 | … |
| 散列字段 | 时间字段(毫秒) | 扩展字段 | ||||
| 0~65535(0x0000~0xFFFF) | 0~86399999(0x00000000~0x05265BFF) |
这样的设计从操作系统内存管理层面无法节省开销,因为64位操作系统是必须8字节对齐。但是对于持久化存储中Rowkey部分可以节省25%的开销。也许有人要问为什么不将时间字段以主机字节序保存,这样它也可以作为散列字段了。这是因为时间范围内的数据还是尽量保证连续,相同时间范围内的数据查找的概率很大,对查询检索有好的效果,因此使用独立的散列字段效果更好,对于某些应用,我们可以考虑利用散列字段全部或者部分来存储某些数据的字段信息,只要保证相同散列值在同一时间(毫秒)唯一。
3.3.2.2. 针对统计数据的Rowkey设计
统计数据也是带时间属性的,统计数据最小单位只会到分钟(到秒预统计就没意义了)。同时对于统计数据我们也缺省采用按天数据分表,这样设计的好处无需多说。按天分表后,时间信息只需要保留小时分钟,那么0~1400只需占用两个字节即可保存时间信息。由于统计数据某些维度数量非常庞大,因此需要4个字节作为序列字段,因此将散列字段同时作为序列字段使用也是6个字节组成唯一Rowkey。如下图所示:
| 统计数据Rowkey设计 | ||||||
|---|---|---|---|---|---|---|
| 第0字节 | 第1字节 | 第2字节 | 第3字节 | 第4字节 | 第5字节 | … |
| 散列字段(序列字段) | 时间字段(分钟) | 扩展字段 | ||||
| 0x00000000~0xFFFFFFFF) | 0~1439(0x0000~0x059F) |
同样这样的设计从操作系统内存管理层面无法节省开销,因为64位操作系统是必须8字节对齐。但是对于持久化存储中Rowkey部分可以节省25%的开销。预统计数据可能涉及到多次反复的重计算要求,需确保作废的数据能有效删除,同时不能影响散列的均衡效果,因此要特殊处理。
3.3.2.3. 针对通用数据的Rowkey设计
通用数据采用自增序列作为唯一主键,用户可以选择按天建分表也可以选择单表模式。这种模式需要确保同时多个入库加载模块运行时散列字段(序列字段)的唯一性。可以考虑给不同的加载模块赋予唯一因子区别。设计结构如下图所示。
| 通用数据Rowkey设计 | ||||
|---|---|---|---|---|
| 第0字节 | 第1字节 | 第2字节 | 第3字节 | … |
| 散列字段(序列字段) | 扩展字段(控制在12字节内) | |||
| 0x00000000~0xFFFFFFFF) | 可由多个用户字段组成 |
3.3.2.4. 支持多条件查询的RowKey设计
HBase按指定的条件获取一批记录时,使用的就是scan方法。 scan方法有以下特点:
- scan可以通过setCaching与setBatch方法提高速度(以空间换时间);
- scan可以通过setStartRow与setEndRow来限定范围。范围越小,性能越高。
scan可以通过setFilter方法添加过滤器,这也是分页、多条件查询的基础。
通过巧妙的RowKey设计使我们批量获取记录集合中的元素挨在一起(应该在同一个Region下),可以在遍历结果时获得很好的性能。在满足长度、三列、唯一原则后,我们需要考虑如何通过巧妙设计RowKey以利用scan方法的范围功能,使得获取一批记录的查询速度能提高。下例就描述如何将多个列组合成一个RowKey,使用scan的range来达到较快查询速度。
3.4. 协处理器
HBase协处理器总体来说包含两种协处理器:Observers和Endpoint。
3.4.1. Observers协处理器
Observers可以理解为传统数据库的触发器,当发生某个特定操作的时候触发Observer。Observer协处理器也可以看作服务端的拦截器,用户可以先根据需求确定拦截点,再去重写这些拦截点对应的方法即可,在不修改HBase内部代码的情况下对HBase扩展更加方便,如实现权限管理、优先级设置、监控、 ddl 控制、 二级索引等功能权限,Phoenix中使用了大量协处理器以增强HBase的易用性。在设计Observer协处理器时需要注意防止重复性触发。
RegionObserver
提供基于表的region上的Get, Put, Delete, Scan等操作,比如可以在客户端进行get操作的时候定义RegionObserver来查询其是否具有get权限等。具体的方法(拦截点)有:
| preOpen, postOpen preFlush, postFlush preGet, postGet preExists, postExists prePut and postPut preDelete and postDelete |
|---|
WALObserver
提供基于WAL的写和刷新WAL文件的操作,一个regionserver上只有一个WAL的上下文。具体的方法(拦截点)有:
| preWALWrite/postWALWrite |
|---|
MasterObserver
提供基于诸如ddl的操作检查,如create, delete, modify table等,同样的当客户端delete表的时候通过逻辑检查是否具有此权限场景等,其运行于Master进程中。具体的方法(拦截点)有:
| preCreateTable/postCreateTable preDeleteTable/postDeleteTable |
|---|
以上对于Observer的逻辑以RegionObserver举例来说其时序图如下:
3.4.2. Endpoint协处理器
Endpoint可以理解为传统数据库的存储过程操作,供客户端调用,比如可以进行某族某列值的加和。无Endpoint特性的情况下需要全局扫描表,通过Endpoint则可以在多台分布有对应表的regionserver上同步加和,再将加和数返回给客户端进行全局加和操作,充分利用了集群资源,增加性能。Endpoint可以实现 min、 max、 avg、 sum、 distinct、 group by 等功能。Endpoint基本概念如下图:<br />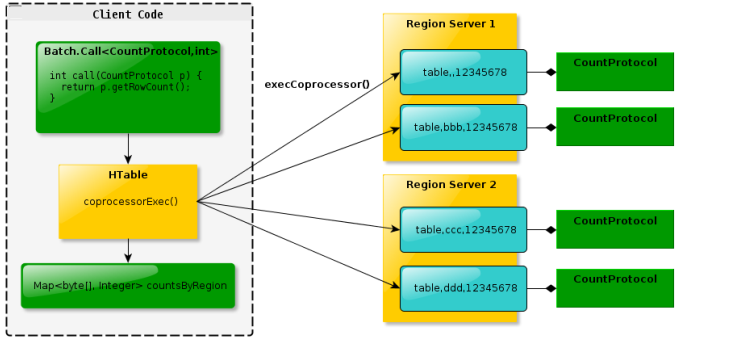<br />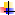 **_区别与联系_**<br /> 在实现两种协处理器的时候稍有区别,无论哪种协处理器都需要运行于Server端的环境中。其中Endpoint还需要通过protocl来定义接口实现客户端代码进行rpc通信以此来进行数据的搜集归并。而Observer则不需要客户端代码,只在特定操作发生的时候出发服务端代码的实现。<br /> **_协处理器加载_**<br /> 协处理器的加载有三种方式,第一种是通过配置文件,在配置文件中指定加载路径、类名等,通过这种方式加载的处理器都是SYSTEM级别的,会作用于所有的请求,所有的表;第二种方式是通过在创建表的时候在表中指定,这种方式既可以创建全局的SYSTEM级别的处理器,也可以创建USER级别的处理器,USER级别的处理器是针对表的。第三种是通过 HBase API,用编程的方法为指定 table 部署协处理器。相应的 API 为 HTableDescriptor.addCoprocessor(String className)。
- 静态方式(系统级),使用配置文件
- 编写协处理器,并打成一个jar包,加入hbase/lib目录下,或者在hbase-env.sh里面配置相对应的jar,以及依赖的jar的路径 。
加入静态的配置,在hbase-site.xml里配置主类 。
<property><name>hbase.coprocessor.region.classes</name><value>org.polaris.hbase.coprocessor.observer.myobserver</value></property>
把依赖的jar分发到每一个regionserver上,然后重启hbase,协处理生效,是系统级的协处理器。
- 动态方式(表级别),使用Hbase shell
- 编写协处理器,打成一个jar包,上传至HDFS,将依赖的jar拷贝到hbase的lib下,配置hbase-env.sh指定依赖的jar。
建立表。
hbase(main)> create 'c', NAME=>'cf'
禁用表。
hbase(main)> disable 'c'
指定协处理器的jar。
hbase(main)> alter 'c', METHOD => 'table_att','coprocessor'=>'hdfs:///user/hbase/hbase-increment-index.jar| org.polaris.hbase.coprocessor.observer.myobserver |1001|'
参数说明:
‘coprocessor’=>(1)jar文件在hdfs上的绝对路径|(2)协处理器主类|(3)优先级|(4)协处理器参数激活表。
hbase(main)> enable 'c'
删除协处理jar。
# 如果有多个协处理器,按照$1 $2 $n删除指定的jar配置hbase(main)> alter 'c',METHOD => 'table_att_unset',NAME =>'coprocessor$1'
API__方式(表级别)
采用 Java 编程的方法部署协处理器,不需要对已经运行的 HBase 实例做任何修改,但是为了 HBase 能够加载协处理器的 jar 包,我们必须将其拷贝到 HBase 实例的 CLASSPATH 所指定的目录下。standalone 模式下,最简单的方法是将 jar 包放到$HBASE_HOME/lib 目录下。在真实的分布式环境下,需要将 jar 包拷贝到每台集群节点的$HBASE_HOME/lib 中,也可以将 jar 包上传到 HDFS 的指定目录,这样每台 RegionServer 都可以通过 HDFS 读取。
void createTable(String tableName) {try{Configuration config = new Configuration();HBaseAdmin admin = new HBaseAdmin(config);HTableDescriptor tableDesc = new HTableDescriptor(tableName);if(admin.tableExists(tableName) == true) {admin.disableTable(tableName);admin.deleteTable(tableName);}tableDesc.addFamily(new HColumnDescriptor("c1")); //add column familytableDesc.addCoprocessor("org.ibm.developerworks.coprocessor.RowCountObserver");tableDesc.addCoprocessor("org.ibm.developerworks.coprocessor.RowCountEndpoint");admin.createTable(tableDesc);}catch(Exception e) {e.printStackTrace();}}
3.4.3. 应用场景
HBase中协处理器应用于解决如下问题:

- 访问权限控制;
- 引用完整性,基于外键检验数据;
- 给hbase设计辅助索引(二级索引),从而提高基于列过滤时的查询性能;
- 像监控MySQL的binlog一样,监控hbase的wal预写log ;
- 服务端自定义实现一些聚合函数的功能 ;
3.5. 辅助索引
Hbase作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。比如,在旧版本的(<0.92)Hbase中,统计数据表的总行数,需要使用Counter方法,执行一次MapReduce Job才能得到。虽然HBase在数据存储层中集成了MapReduce,能够有效用于数据表的分布式计算。然而在很多情况下,做一些简单的相加或者聚合计算的时候,如果直接将计算过程放置在server端,能够减少通讯开销,从而获得很好的性能提升。于是,HBase在0.92之后引入了协处理器(coprocessors),实现一些激动人心的新特性:能够轻易建立二次索引、复杂过滤器(谓词下推)以及访问控制等。
3.5.1. 二级索引方案
常见的二级索引方案:
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| MapReduce | 利用MR的方式构建Index,存储节省,也不需要建索引表,只需要靠强大的集群计算能力即可导出结果。但一般不适合online业务。 | 并发批量构建Index | 不能实时构建Index |
| ITHBASE | 建一张事务表GLOBAL_TRX_LOG,每次开启事务时,在表中记录状态。客户端对多张表更新时,先启动事务,然后每次PUT,将事务id传递给HRegionServer。ITHbase通过继承HRegionServer和HReogin类,重写了大多数操作接口方法,比如put, ?update, delete, 用于获取transactionalId和状态。当server收到操作和事务id后,先确认服务端收到,标记当前事务为待写入状态(需要再发起一次PUT)。当所有表的操作完成后,由客户端统一做commit写入,做二阶段提交。 http://github.com/hbase-trx/hbase-transactional-tableindexed |
ITHBase(Indexed Transactional HBase)是HBase的一个事物型的带索引的扩展。支持全局排序 | 需要重构hbase,版本几年没有更新,存储冗余和数据一致性问题。 |
| IHBASE | 在Memstore满了以后刷磁盘时,IHBase会进行拦截请求,并为这个memstore的数据构建索引,索引另一个CF的方式存储在表内。scan的时候,IHBase会结合索引列中的标记,来加速scan。 http://github.com/ykulbak/ihbase |
一次扫描可同时使用多个索引,支持并行扫描 | 不支持全局排序,不支持全表扫描 |
| Coprocessor | 协处理器的机制可以理解为,server端添加了一些回调函数,如preGet、prePut、preDelete、preScannerOpen等,利用这些hooks可以实现region级二级索引,实现count, sum, avg, max, min等聚合操作而不需要返回所有的数据。 HIndex–来自华为的HBase二级索引 http://github.com/Huawei-Hadoop/hindex |
支持region级别索引 | 全局排序就很难做 |
| Solr+hbase | 基于Solr的HBase多条件查询原理很简单,将HBase表中涉及条件过滤的字段和rowkey在Solr中建立索引,通过Solr的多条件查询快速获得符合过滤条件的rowkey值,拿到这些rowkey之后在HBASE中通过指定rowkey进行查询。 | 支持对扫描结果进行动态的分组和过滤 | 分布式索引全量、增量控制粒度,尚不够友好。指定结点,指定条件下增量都不够顺利。 |
3.5.2. 二级索引设计
 设计思路
设计思路
二级索引的本质就是建立各列值与行键之间的映射关系。
(图1)设计思路
如(图1),当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分)
其查询步骤如下:
- 根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1。
- 得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。
 逻辑视图
逻辑视图
(图2) 部分数据在HBase中存储的逻辑视图
图2中有两个列族,其中一个是列族INDEX,其并不存储任何的数据,仅仅是为了将索引数据与主数据分开存储(因为在HBase中同一列族的数据会被压缩在一起存储),索引数据的行键格式为:RegionStartKey-索引名-索引键-Rowkwy,其他RegionStartKey就是出发点,因为在创建HBase表时就对表根据出发点进行了预分区,索引键为主数据中某列(可能是多列)的列值,Rowkey对应主数据的行键;主数据的行键格式为:出发点-目的地-性价比,所以在存储数据时,同一出发点 目的地的数据默认是按性价比排序的;索引数据的行键和主数据的行键的前缀都是出发点,所以在存储时相同出发点的索引数据和主数据是存储在同一个Region中的,这样避免了在通过索引得到RK后又去其他Region上查询目标数据,提高了查询效率。 缺点
缺点
需要额外的存储空间,属于一种以空间换时间的方式。
3.6. 调优
3.6.1. 运维问题
3.6.1.1. 拆分风暴
通常HBase是自动处理Region拆分的:一旦它们达到了既定的阈值,Region将被拆分成两个,之后它们可以接收新的数据并继续增长。这个默认行为能满足大多数用例的需要。其中一种可能出现问题的情况被称之为“拆分/合并风暴”:当用户的Region大小以恒定的速度保持增长时,Region拆分会在同一时间发生,因为同时需要压缩region中的存储文件,这个过程会重写拆分之后的Region,这将会引起磁盘I/O上升。
- 解决方案
与其依赖HBase自动管理拆分,用户还不如关闭这个行为,然后手动调用“split”和“major_compact”命令。用户可以通过设置这个集群的“hbase.hregion.max.filesize”值或者在列簇级别上把表模式中对应参数设置成非常大的值来完成。为防止手动拆分无法运行,最好不要将其设置为“Long.MAX_VALUE”。用户zu最好将这个值设置为一个合理的上限,例如:100GB(如果触发的话将会导致一个小时的major合并)。
手动运行命令来拆分和压缩Region的好处是可以对它们进行时间控制。在不同Region上交错地运行,这样可以尽可能分散I/O负载,并且避免拆分/合并风暴。用户可以实现一个可以调用split()和majorCompact()方法的客户端,也可以使用Shell交互地调用相关命令,或者使用cron定时第运行它们。用户可以参见“RegionSplitter”类(0.90.2版本添加进来的)的另一种拆分Region的方法:其拥有滚动拆分(rolling split)的特性,用户可以使用该功能拆分正在长时间等待合并操作完成的Region(参见-r和-o命令行选项)。
方案实现
Region的最大大小在HBase配置文件(Hbase-default.xml)中定义:
<!-- 默认大小10G=10 * 1024 * 1024 * 1024=10737418240 --><property><name>hbase.hregion.max.filesize</name><value>10737418240</value></property>
该值也可以针对每个表单独设置,例如在hbase shell中设置:
hbase(main)> create 't','f'hbase(main)> disable 't'hbase(main)> alter 't', METHOD => 'table_att', MAX_FILESIZE => '134217728'hbase(main)> enable 't'
说明:
HStoreFile最大值取“conf.getLong(“hbase.hregion.max.filesize”,HConstants.DEFAULT_MAX_FILE_SIZE);”,HConstants.DEFAULT_MAX_FILE_SIZE=25610241024默认256M,而Hbase-default.xml中设置
“hbase.hregion.max.filesize=10737418240”默认10G,根据配置文件加载顺序:Hbase-default.xml—>Hbase-site.xml,默认取到10G。3.6.1.2. 数据热点
 什么是热点
什么是热点
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。
为了避免写热点,设计rowkey使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。
下面是一些常见的避免热点的方法以及它们的优缺点:
| 方法 | 描述 |
|---|---|
| 加盐 | 这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。 |
| 哈希 | 哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据。 |
| 反转 | 第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。举栗:反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题。 |
| 时间戳反转 | 一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp 追加到key的末尾,例如 [key][reverse_timestamp] , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。 |
尽量减少行和列的大小在HBase中,value永远和它的key一起传输的。当具体的值在系统间传输时,它的rowkey,列名,时间戳也会一起传输。如果你的rowkey和列名很大,甚至可以和具体的值相比较,那么你将会遇到一些有趣的问题。HBase storefiles中的索引(有助于随机访问)最终占据了HBase分配的大量内存,因为具体的值和它的key很大。可以增加block大小使得storefiles索引再更大的时间间隔增加,或者修改表的模式以减小rowkey和列名的大小。压缩也有助于更大的索引。列族尽可能越短越好,最好是一个字符,冗长的属性名虽然可读性好,但是更短的属性名存储在HBase中会更好。
3.6.2. 表的设计
3.6.2.1. 预分区
默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡。
# 方式一hbase(main)> create 't1','cf',SPLITS=>['10','20','30']# 方式二hbase(main)> n_splits=20hbase shell>> create 't1','cf',{SPLITS => (1...n_splits).map{|i| "user#{1000+i*(9999-1000)/n_splits}"}}# 方式三hbase(main)> create 't1','cf',SPLITS_FILE=>'/data/user/sss-split.txt'# 通过预分区尽量将不同Region分布到不同RegionServer上,如果不均匀可以手动移动分区# step:先查看表相关信息,ENCODED_REGIONNAME:MD5(表名,startKey,起始码serverstartcode)hbase(main)> scan 'hbase:meta'hbase(main)> move '源ENCODED_REGIONNAME' '目标ENCODED_REGIONNAME'
3.6.2.2. 合并 & 分割
在HBase中,数据在更新时首先写入WAL 日志(HLog)和内存(MemStore)中,MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。于此同时, 系统会在zookeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了(minor compact)。<br /> StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定的阈值后,就会进行一次合并(major compact),将对同一个key的修改合并到一起,形成一个大的StoreFile,当StoreFile的大小达到一定阈值后,又会对 StoreFile进行分割(split),等分为两个StoreFile。<br /> 由于对表的更新是不断追加的,处理读请求时,需要访问Store中全部的StoreFile和MemStore,将它们按照row key进行合并,由于StoreFile和MemStore都是经过排序的,并且StoreFile带有内存中索引,通常合并过程还是比较快的。<br /> 实际应用中,可以考虑必要时手动进行major compact,将同一个row key的修改进行合并形成一个大的StoreFile。同时,可以将StoreFile设置大些,减少split的发生。
# 分割表(均分)hbase(main)> split 'ns1:t1'# 分割region(指定分割点-rowKey)hbase(main)> split 'splitRowKey','crowKey' #splitRowKey:用户表Region元信息rowKey,crowKey:表中的rowKey# 合并Regionhbase(main)> merge_region '源ENCODED_REGIONNAME','目标ENCODED_REGIONNAME'# 合并Store,把HStore所有的HFile都compact为一个HFile# 一般情况下都是做Minor合并,Major不少集群都是禁止,然后再集群负载较小时,进行手动Major合并,也是配置了一个<name>hbase.hregion.majorcompaction</name><value>0</value>,这是配置major的合并周期(默认为7天),很多集群配置成一天,如果配置成0即关闭Major合并。# Compact all regions in a tablehbase(main)> major_compact 't1'# Compact an entire regionhbase(main)> major_compact 'r1'# Compact a single column family within a regionhbase(main)> major_compact 'r1', 'c1'# Compact a single column family within a tablehbase(main)> major_compact 't1', 'c1'
3.6.2.3. 压缩方式
在Hadoop和HBase文件传输可以在压缩之后在进行传输,这样就可以在传输的时候减少传输数据,增大I/O和带宽效率。在Hadoop中主要提供了三种压缩方式Gzip、LZO、Snappy三种数据压缩。实际使用中,可以考虑分别尝试两种压缩模式,选出最适合业务场景要求的。
3.6.3. 写表操作
3.6.2.1. Row Key设计
HBase中row key用来检索表中的记录,支持以下三种方式:
- 通过单个row key访问:即按照某个row key键值进行get操作;
- 通过row key的range进行scan:即通过设置startRowKey和endRowKey,在这个范围内进行扫描;
全表扫描:即直接扫描整张表中所有行记录。
row key是按照字典序存储,因此,设计row key时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。<br /> 如果最近写入HBase表中的数据是最可能被访问的,可以考虑将时间戳作为row key的一部分,由于是字典序排序,所以可以使用Long.MAX_VALUE – timestamp作为row key,这样能保证新写入的数据在读取时可以被快速命中。
3.6.2.2. 多HTable并发写
创建多个HTable客户端用于写操作,提高写数据的吞吐量。
static final Configuration conf = HBaseConfiguration.create();static final String table_log_name = "user_log";wTableLog = new HTable[tableN];for (int i=0;i< tableN;i++){wTableLog[i]=new HTable(conf,table_log_name);wTableLog[i].setWriteBufferSize(5*1024*1024);//5MBwTableLog[i].setAutoFlush(false);}
3.6.2.3. HTable参数设置
3.6.2.3.1 Auto Flush
通过调用HTable.setAutoFlush(false)方法可以将HTable写客户端的自动flush关闭,这样可以批量写入数据到HBase,而不是有一条put就执行一次更新,只有当put填满客户端写缓存时,才实际向HBase服务端发起写请求。默认情况下auto flush是开启的。
3.6.2.3.2 Write Buffer
通过调用HTable.setWriteBufferSize(writeBufferSize)方法可以设置HTable客户端的写buffer大小,如果新设置的buffer小于当前写buffer中的数据时,buffer将会被flush到服务端。其中,writeBufferSize的单位是byte字节数,可以根据实际写入数据量的多少来设置该值。
3.6.2.3.3 WAL Flag
在HBae中,客户端向集群中的RegionServer提交数据时(Put/Delete操作),首先会先写WAL(Write Ahead Log)日志(即HLog,一个RegionServer上的所有Region共享一个HLog),只有当WAL日志写成功后,再接着写MemStore,然后客户端被通知提交数据成功;如果写WAL日志失败,客户端则被通知提交失败。这样做的好处是可以做到RegionServer宕机后的数据恢复。因此,对于相对不太重要的数据,可以在Put/Delete操作时,通过调用Put.setWriteToWAL(false)或Delete.setWriteToWAL(false)函数,放弃写WAL日志,从而提高数据写入的性能。
3.6.4. 读表操作
3.6.3.1. 多HTable并发读
创建多个HTable客户端用于读操作,提高读数据的吞吐量。
static final Configuration conf = HBaseConfiguration.create();static final String table_log_name = "user_log";rTableLog = new HTable[tableN];for (int i=0;i< tableN;i++){rTableLog[i]=new HTable(conf,table_log_name);rTableLog[i].setScannerCaching (50);}
3.6.3.2. 批量读
通过调用HTable.get(Get)方法可以根据一个指定的row key获取一行记录,同样HBase提供了另一个方法:通过调用HTable.get(List)方法可以根据一个指定的row key列表,批量获取多行记录,这样做的好处是批量执行,只需要一次网络I/O开销,这对于对数据实时性要求高而且网络传输RTT高的情景下可能带来明显的性能提升。
3.6.3.3. 多线程并发读
在客户端开启多个HTable读线程,每个读线程负责通过HTable对象进行get操作。
3.6.3.4. 缓存查询结果
对于频繁查询HBase的应用场景,可以考虑在应用程序中做缓存,当有新的查询请求时,首先在缓存中查找,如果存在则直接返回,不再查询HBase;否则对HBase发起读请求查询,然后在应用程序中将查询结果缓存起来。至于缓存的替换策略,可以考虑LRU等常用策略。
3.6.3.5. Blockcache
HBase上Regionserver的内存分为两个部分,一部分作为Memstore,主要用来写;另外一部分作为BlockCache,主要用于读。
写请求会先写入Memstore,Regionserver会给每个region提供一个Memstore,当Memstore满64MB以后,会启动 flush刷新到磁盘。当Memstore的总大小超过限制时(heapsize hbase.regionserver.global.memstore.upperLimit 0.9),会强行启动flush进程,从最大的Memstore开始flush直到低于限制。
读请求先到Memstore中查数据,查不到就到BlockCache中查,再查不到就会到磁盘上读,并把读的结果放入BlockCache。由于BlockCache采用的是LRU策略,因此BlockCache达到上限(heapsize hfile.block.cache.size 0.85)后,会启动淘汰机制,淘汰最老的一批数据。
一个Regionserver上有一个BlockCache和N个Memstore,它们的大小之和不能大于等于heapsize * 0.8,否则HBase不能启动。默认BlockCache为0.2,而Memstore为0.4。对于注重读响应时间的系统,可以将 BlockCache设大些,比如设置BlockCache=0.4,Memstore=0.39,以加大缓存的命中率。3.6.5. asynchbase
Hbase原生java 客户端是完全同步的,当使用原生API 例如HTableInterface 访问HBase表,每个动作都会有一个短暂的阻塞,这对于一些流程较长的操作看起来比较不利。 HBase在此还提供了另外一种java客户端 asynchbase,它实现了完全异步以及考虑线程安全。 依赖jar:asynchbase.jar 、slf4j-api.jar 、slf4j-simple.jar 。
3.6.6. 参数调优
3.7. HBase Java API
详见:https://www.yuque.com/polaris-docs/bigdata/hbase-base-api
3.8. Phoenix
Phoniex安装请参考文档《**_[__安装文档__]VMware9_CentOS7_SQuirrel&Phoniex&Hive.docx_**》。<br /> Phoenix其本质是用Java写的基于JDBC API操作HBase的开源SQL引擎。它有如下几个功能特性:<br />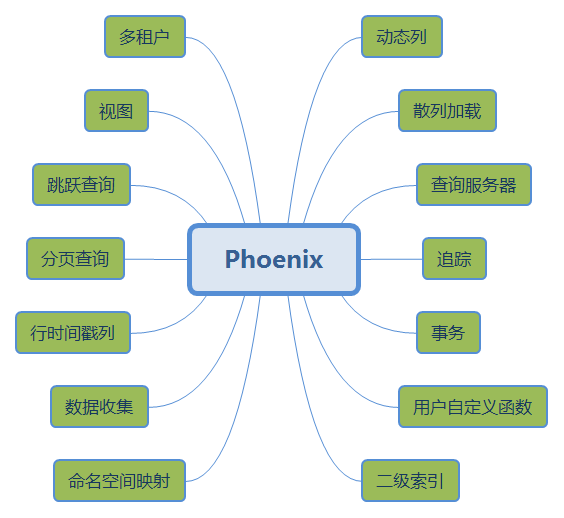<br /> 值得关注的几个特性主要有以下几块:
通过JDBC API实现了大部分的java.sql接口,包括元数据API;
- DDL支持:通过CREATE TABLE、DROP TABLE及ALTER TABLE来添加/删除;
- DML支持:用于逐行插入的UPSERT VALUES,用于相同或不同表之间大量数据传输的UPSERT SELECT,用于删除行的DELETE;
- 事务支持:通过客户端的批处理实现的有限的事务支持;
- 二级索引支持;
- 遵循ANSI SQL标准;

 架构
架构
 在Hadoop生态系统中的位置
在Hadoop生态系统中的位置
 数据存储
数据存储
 QL__命令支持
QL__命令支持
支持的命令如下:


3.9. 整合Hive
Hive整合Hbase是现阶段比较成熟的一套基于HBase实现SQL引擎的方案,现在业内的使用也比较多, Hive整合HBase方案的优点和缺点如下:
| 优点 | - Hive方便地提供了Hive QL的接口来简化MapReduce的使用,而HBase提供了低延迟的数据库访问。如果两者结合,可以利用MapReduce的优势针对HBase存储的大量内容进行离线的计算和分析。 - 操作方便,hive提供了大量系统功能。 - 低耦度整合,对Hive和HBase的依赖度低,没有较大耦合度。 - 由Apache官方提供,从Hive0.6开始支持,更新比较及时,bug较少,可以用于生产环境。 |
|---|---|
| 缺点 | - 查询速度慢,大部分操作都需要启动MapReduce,查询过程比较耗时。 - 对HBase集群的访问压力较大,每个MapReduce任务都需要启动N个Handler连接HBase集群,这样会大量占用HBase连接,造成资源使用紧张。 - 列映射有诸多限制。现有版本的列映射以及Rowkey的限制很多,例如无法使用组合主键,无法使用timestamp属性(版本)。 |
4. HBase集群监控
4.1. JMX监控
HBase的Jmx在1.0后分开了master和regionserver的jmx监控,其中master的页面在masterHOSTNAME:60010/jmx页面中,regionserver在REGIONSERVER_HOSTNAME:60030/jmx中,如果想更详细的信息使用http://REGIONSERVER_HOSTNAME:60030/jmx?description=true。页面展示的是json文件,可以将该页面信息发送给ganglia,zabbix等监控工具,hbase原生支持ganglia,如果发送给zabbix,需要自己开发获取其中的数据,解析出来。
Jmx可以监控每个regionServer的总请求数,readRequestsCount,writeRequestCount,region分裂,region合并,Store。
**数据来源:/jmx?qry=Hadoop:service=HBase,name=RegionServer,sub=Server
常见Jmx获取监控数据参考:《Jmx获取Hadoop和HBase_性能数据.docx》。
设计:**
- 定时调度Hbase Jmx去捞取数据,数据存放在Mysql,最新的一条数据存放到redis缓存中查(设置过期时间5分钟)并插入数据库中(定时每五分钟调度一次)。
- 每次获取Jmx数据后,从redis中获取5分钟前的数据,进行计算获取5分钟内的数据并保存到数据库中。
查看详细图片:



jmx常用监控指标:
| 监控指标 | 范围 | 指标含义 |
|---|---|---|
| OpenFileDescriptorCount | Regionserver本机 | 当前机器打开文件数 |
| FreePhysicalMemorySize | Regionserver本机 | 空虚物理内存大小 |
| AvailableProcessors | Regionserver本机 | 可用cpu个数 |
| Region前缀—storeCount | 单个region | Store个数 |
| Region前缀—storeFileCount | 单个region | Storefile个数 |
| Region前缀—memStoreSize | 单个region | Memstore大小 |
| Region前缀—storeFileSize | 单个region | Storefile大小 |
| Region前缀—compactionsCompletedCount | 单个region | 合并完成次数 |
| Region前缀—numBytesCompactedCount | 单个region | 合并文件总大小 |
| Region前缀— numFilesCompactedCount | 单个region | 合并完成文件个数 |
| totalRequestCount | Regionserver | 总请求数 |
| readRequestCount | Regionserver | 读请求数 |
| writeRequestCount | Regionserver | 写请求数 |
| compactedCellsCount | Regionserver | 合并cell个数 |
| majorCompactedCellsCount | Regionserver | 大合并cell个数 |
| flushedCellsSize | Regionserver | flush到磁盘的大小 |
| blockedRequestCount | Regionserver | 因memstore大于阈值而引发flush的次数 |
| splitRequestCount | Regionserver | region分裂请求次数 |
| splitSuccessCounnt | Regionserver | region分裂成功次数 |
| slowGetCount | Regionserver | 请求完成时间超过1000ms的次数 |
| numOpenConnections | Regionserver | 该regionserver打开的连接数 |
| numActiveHandler | Regionserver | rpc handler数 |
| receivedBytes | Regionserver | 收到数据量 |
| sentBytes | Regionserver | 发出数据量 |
| HeapMemoryUsage —->>>used | Regionserver | 堆内存使用量 |
| SyncTime_mean | Regionserver | WAL写hdfs的平均时间 |
| regionCount | Regionserver | Regionserver管理region数量 |
| memStoreSize | Regionserver | Regionserver管理的总memstoresize |
| storeFileSize | Regionserver | 该Regionserver管理的storefile大小 |
| staticIndexSize | Regionserver | 该regionserver所管理的表索引大小 |
| storeFileCount | Regionserver | 该regionserver所管理的storefile个数 |
| hlogFileSize | Regionserver | WAL文件大小 |
| hlogFileCount | Regionserver | WAL文件个数 |
| storeCount | Regionserver | 该regionserver所管理的store个数 |
| Name: java.lang:type=MemoryPool,name=Par Eden Space CollectionUsage—>>used | Regionserver | Eden区使用空间大小 |
| Name: java.lang:type=MemoryPool,name=CMS Old Gen | Regionserver | 老年代内存大小 |
| Name: java.lang:type=MemoryPool,name=Par Survivor Space CollectionUsageà> used | Regionserver | Survivor内存大小 |
| GcTimeMillis | Regionserver | GC总时间 |
| GcTimeMillisParNew | Regionserver | ParNew GC时间 |
| GcCount | Regionserver | GC总次数 |
| GcCountConcurrentMarkSweep | Regionserver | ConcurrentMarkSweep总次数 |
| GcTimeMillisConcurrentMarkSweep | Regionserver | ConcurrentMarkSweep GC时间 |
| ThreadsBlocked | Regionserver | Block线程数 |
| ThreadsWaiting | Regionserver | 等待线程数 |
4.2. Java API采集
Hbase对每张表的读写监控<br />**_数据来源_**:通过Hbase Java Api连接HBASEorg.apache.hadoop.hbase.client.Connection connection然后获取org.apache.hadoop.hbase.client.Admin admin = connection.getAdmin();得到HBASE中的regionServer集合,获取每个regionServer中RegionsLoad();遍历RegionLoad获取每张表的Table Region。<br />**_查看详细图片_**:<br />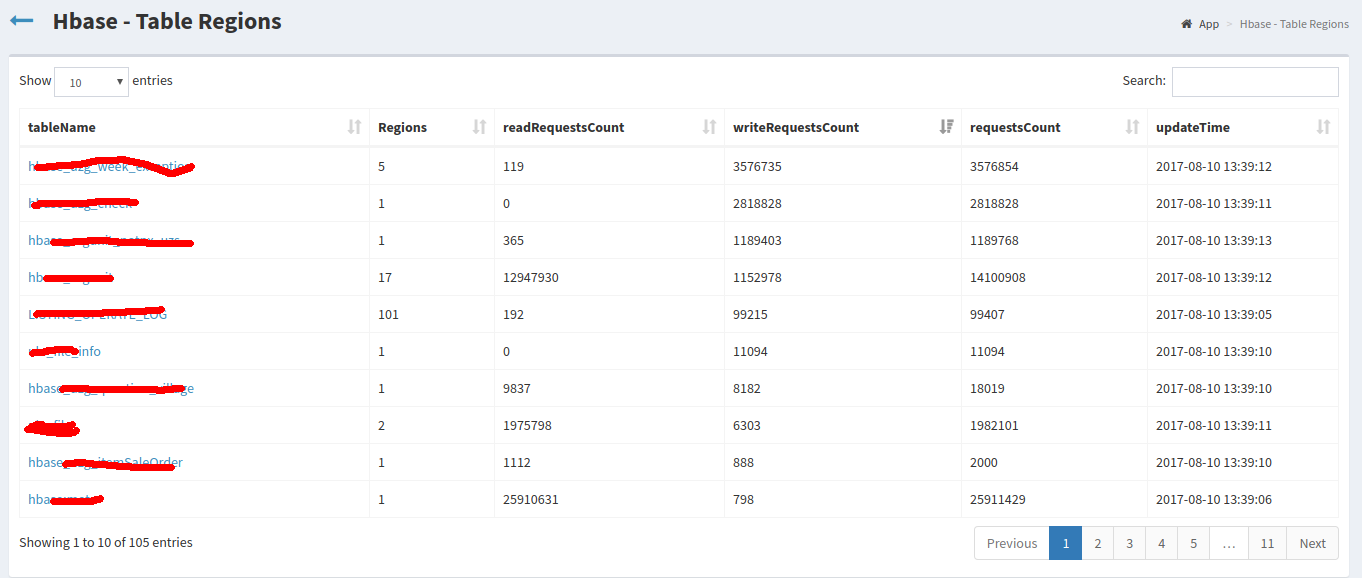<br />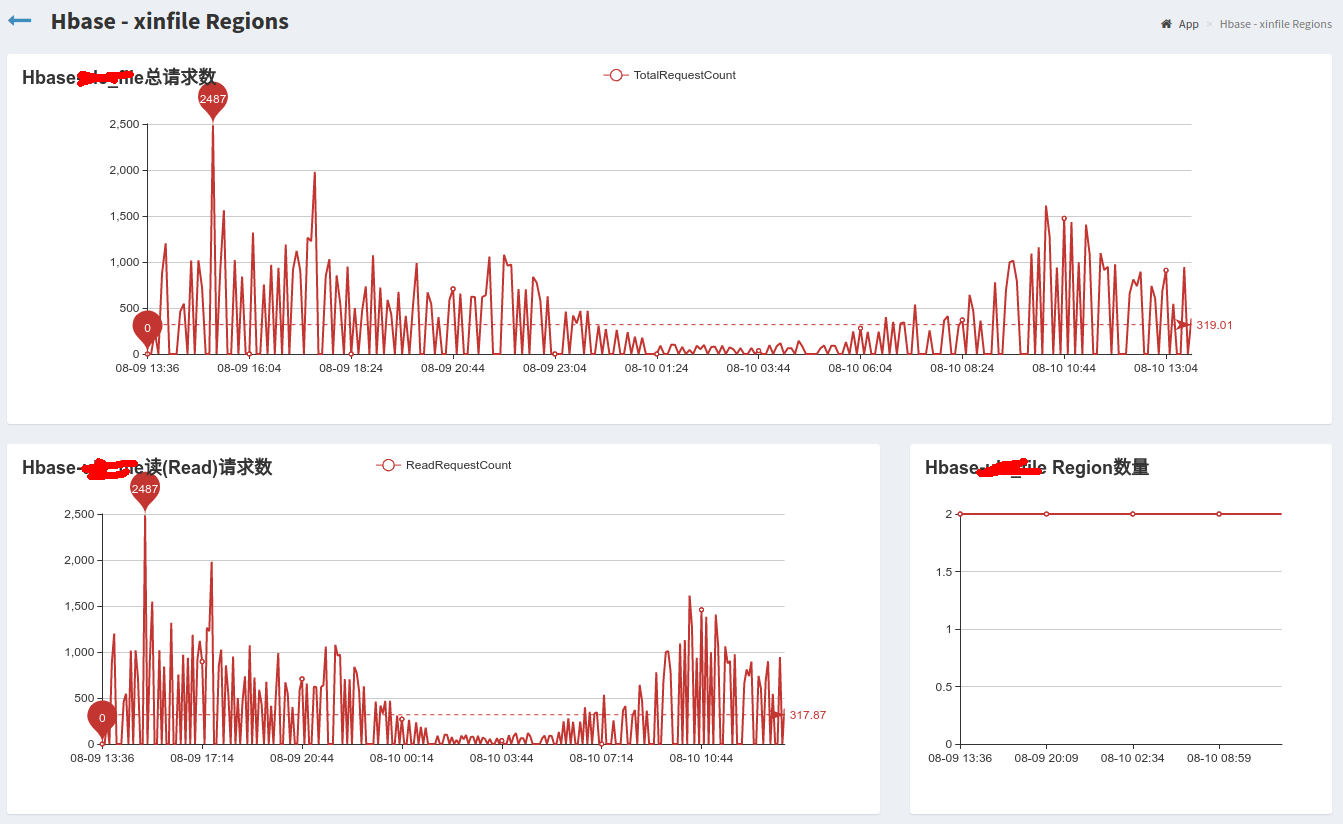<br />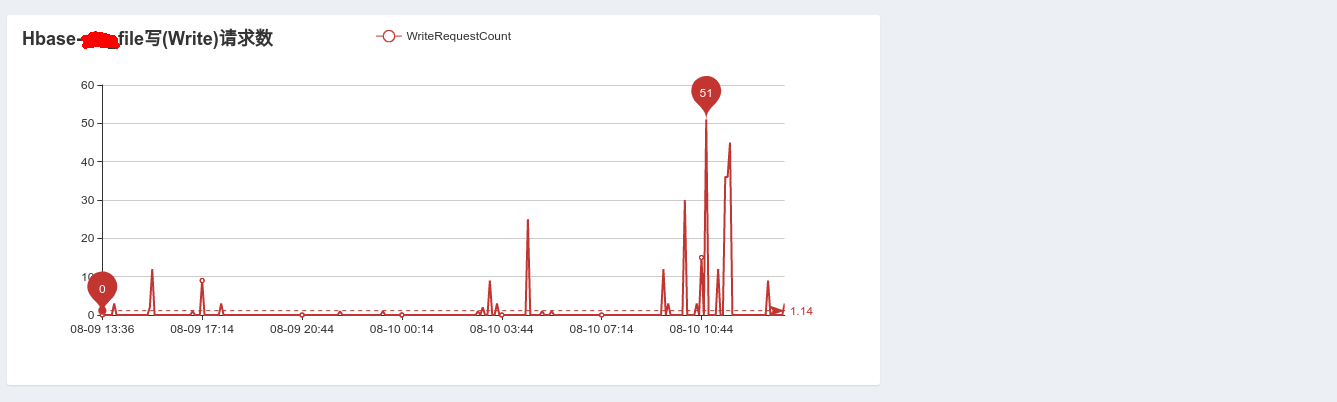<br />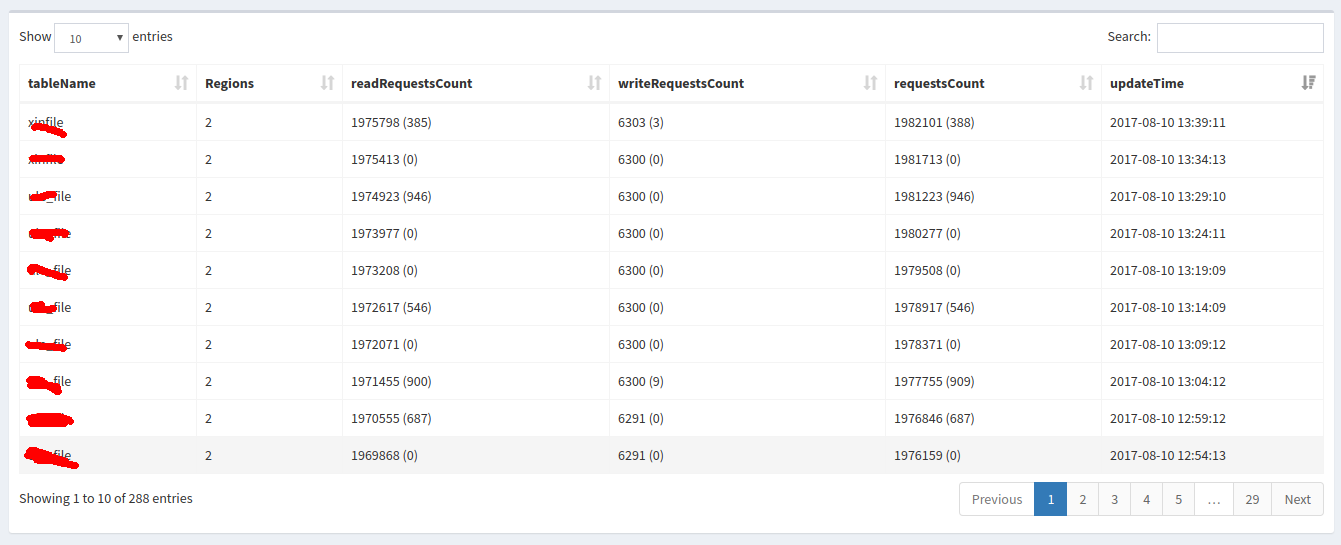
5. HBase性能测试
目前应用于HBase性能测试的主要工具如下表:
| 测试工具 | 特点 | 描述 |
|---|---|---|
| YCSB | 优点: 1 可以任意设置读写比例、线程数量,打印结果比较详细 ; 2 它是hbase等nosql官方jira上面的测试标准,与人交流时ycsb的测试数据最能说明问题 ; 缺点: 1 每次测试时数据需要重新写入,否则读取时选取不了正确的key值,导致内存命中率低; 2 key值分布不均匀,节点多数据少时,会导致倾斜 ; 3 线程多时有bug; |
YCSB与HBase自带的性能测试工具(PerformanceEvaluation)相比: 扩展:进行性能测试的客户端不仅仅只是HBase一款产品,而且可以是HBase不同的nosql数据库。 灵活:进行性能测试的时候,可以选择进行测试的方式:read+write,read+scan等,还可以选择不同操作的频度与选取Key的方式。 监控: a) 进行性能测试的时候,可以实时显示测试进行的进度: b) 测试完成之后,会显示整体的测试情况: |
| PerformanceEvaluation | HBase自带测试工具 | 可以测试随机读,随机写,顺序读,顺序写,全扫描等操作 |
| LoadRunner | 功能强大,重量级, LoadRunner11以上版本需要运行在XP之后的windows版本上。 Virtual User Generator(虚拟用户生成器):录制脚本,调试脚本 Controller(控制台):创建和运行场景,并对客户和服务器间数据响应进行监控 Analysis(分析器):对整个系统进行压力测试的结果进行分析 |
一种预测系统行为和性能的负载测试工具。通过以模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,LoadRunner能够对整个企业架构进行测试。 |
| Jmeter | 开源,轻量级 | Jmeter做功能测试的脚本可以同样用来做性能测试 |
目前主流的HBase测试工具为YCSB,相关安装和测试方式见《[安装文档]VMware9_CentOS7_YCSB.docx》,详细的测试报告参考《Hbase性能测试详细设计文档及用例(模版).docx》。
附录
附录A:常用HBase命令
| 命令 | 描述 |
|---|---|
| scan ‘ns1:t1’,{COLUMN=>’f1’,RAW=>true,VERSIONS=>10} | 原生扫描 |
| list_namespace, list_namespace_tables ‘mcbsdb’ | 查看namespace |
| alter “test”,NAME=>’fa’,TTL=>’200’ | 修改TTL,需要先disable 表,单位为秒,默认值“2147483647”大约69年 |
| alter ‘t’, METHOD => ‘table_att’, MAX_FILESIZE => ‘134217728’ | 修改表默认region拆分阈值 |
| flush ‘t1’/ flush ‘ regionName‘ | 手工把memstore写到Hfile中 |
| create ‘t1’,’cf’,SPLITS=>[‘10’,’20’,’30’] | 预分区 |
| create ‘t1’,’cf’,{SPLITS => (1…10).map{|i| “user#{1000+i*(9999-1000)/10}”}} | 预分区 |
| create ‘t1’,’cf’,SPLITS_FILE=>’/data/user/sss-split.txt’ | 预分区 |
| move ‘源ENCODED_REGIONNAME’ ‘目标ENCODED_REGIONNAME’ | 手动移动分区 |
| split ‘ns1:t1’ | 拆分表(将表均分两半) |
| split ‘splitRowKey’,’crowKey’ | 拆分region(指定分割点-rowKey) |
| merge_region ‘源ENCODED_REGIONNAME’,’目标ENCODED_REGIONNAME’ | 合并region |
| major_compact ‘t1’ | 合并table上的所有region |
| major_compact ‘r1’ | 合并region |
| major_compact ‘r1’, ‘c1’ | 合并region上的列族 |
| major_compact ‘t1’, ‘c1’ | 合并table上所有列族 |
附录B:附件
Jmx获取Hadoop和HBase性能数据.docx
[安装文档]VMware9_CentOS7_YCSB.docx
Hbase性能测试详细设计文档及用例(模版).docx

若有收获,就点个赞吧
0 人点赞
