资料来源
- https://flink.apache.org/flink-architecture.html
- 《Flink原理、实战与性能优化》
- https://github.com/flink-china/flink-training-course
Apache Flink的定义、架构、应用与运维
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
架构
- 擅长处理有界和无界的数据集,通过精确的时间控制和状态化运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理。
- 是一个分布式系统,需要计算资源来执行应用程序,集成了Hadoop YARN、 Apache Mesos 和Kubernetes等集群资源管理器,也可以作为独立集群运行。
- Flink旨在任意规模上运行有状态流式应用。应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。能够充分运用资源,而且易于维护,通过异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中。 Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
应用
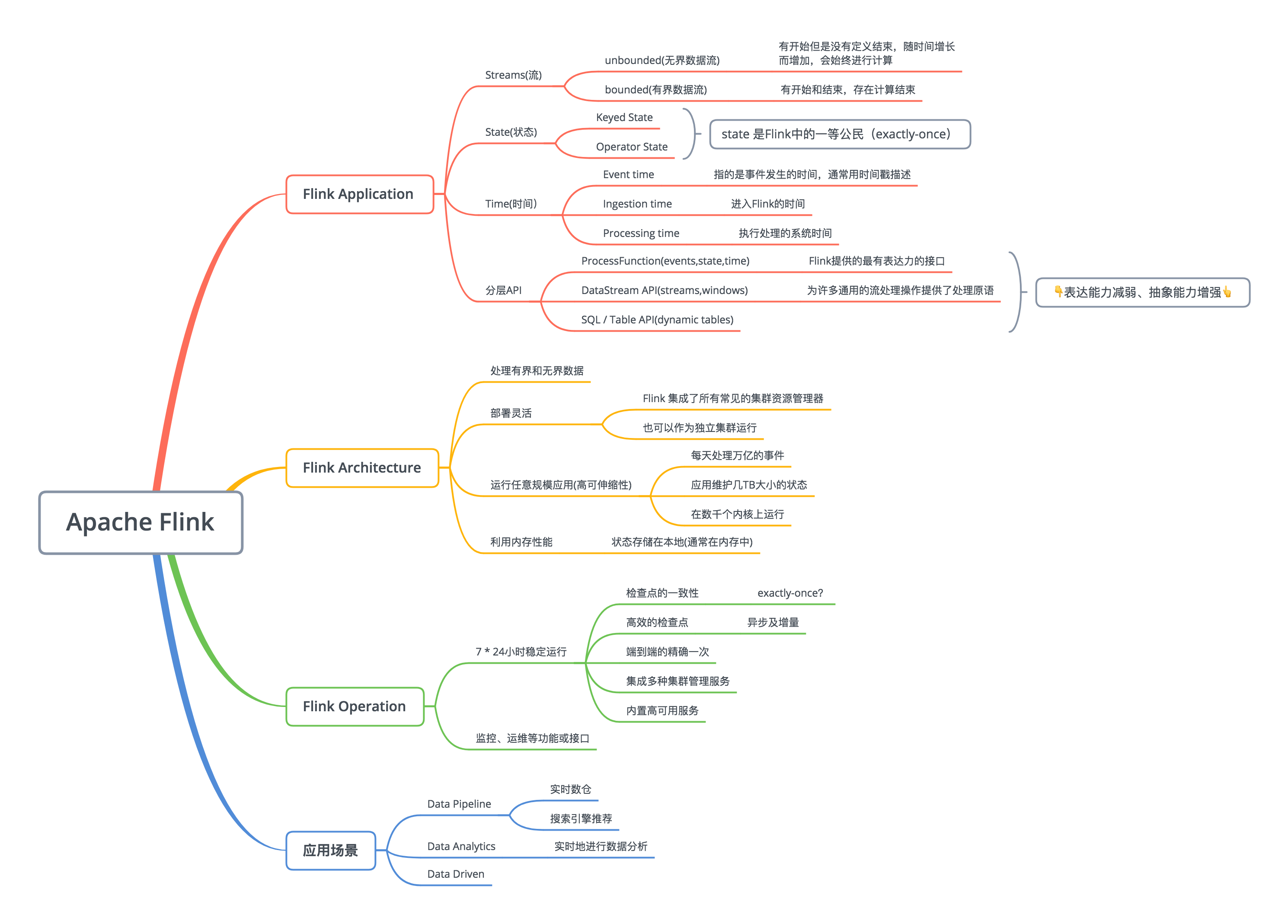
流处理的基本组件:流(有界流和无界流)、状态(Flink中的first-class citizen)、时间(Event Time / Processing Time / Ingestion Time)
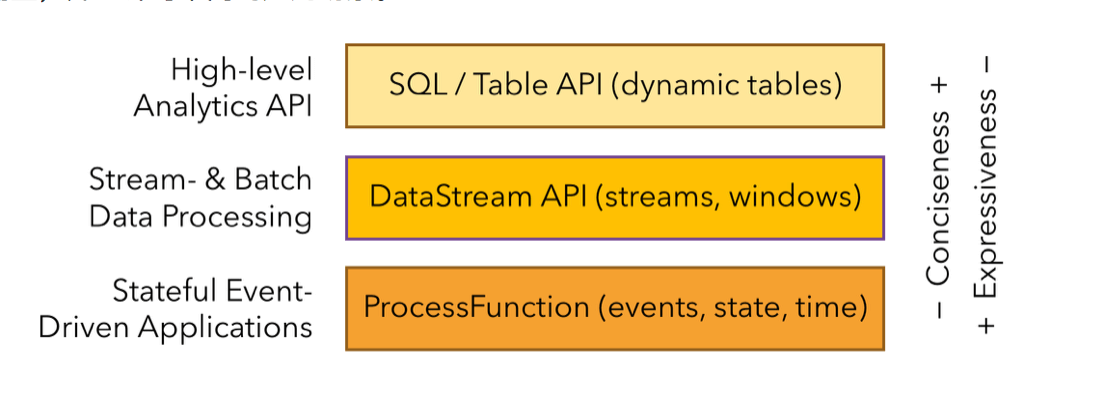
- 分层API:根据抽象程度分层,提供了三种不同API ,由上至下抽象程度降低,表达能力增强。如ProcessFunction 层 API 的表达能力非常强,可以进行多种灵活方便的操作,但抽象能力也相对越小。
运维(待完善)
- Flink 具备 7 X 24 小时高可用的面向服务的架构
- Flink 本身提供监控、运维等功能或接口
应用场景
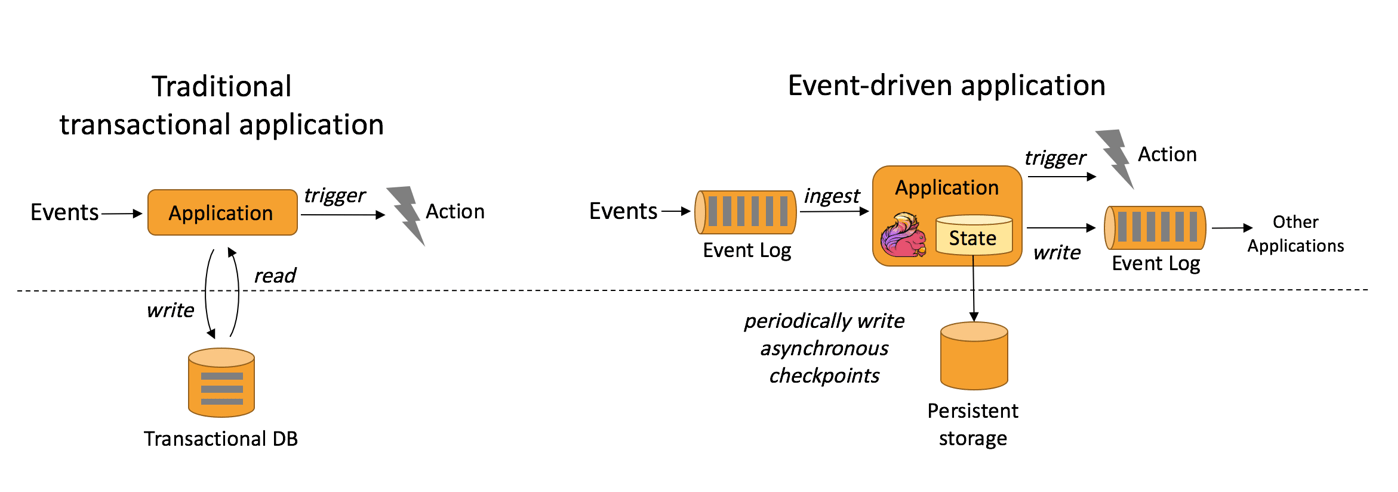
事件驱动应用
事件驱动型应用会受制于底层流处理系统对时间和状态的把控能力,它提供了一系列丰富的状态操作原语,允许以精确一次的一致性语义合并海量规模的状态数据。Flink还支持事件时间和自由度极高的定制化窗口逻辑,而且它内置的ProcessFunction 支持细粒度时间控制,方便实现一些高级业务逻辑。同时,Flink 还拥有一个复杂事件处理(CEP)类库,可以用来检测数据流中的模式。
数据分析应用
Flink对持续的批量处理和流式处理都提供了良好的支持。典型的应用实例有电信网络质量监控、实时大屏、实时报表等。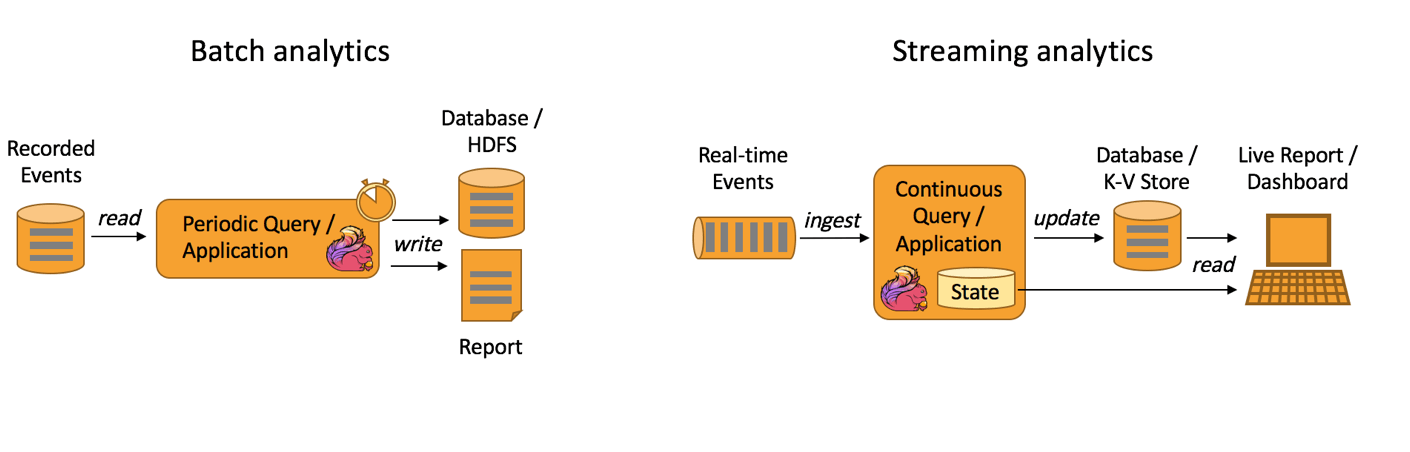
数据管道应用
很多常见的数据转换和增强操作可以利用 Flink 的 SQL 接口(或 Table API)及用户自定义函数解决。
应用实例有搜索引擎推荐、实时数仓。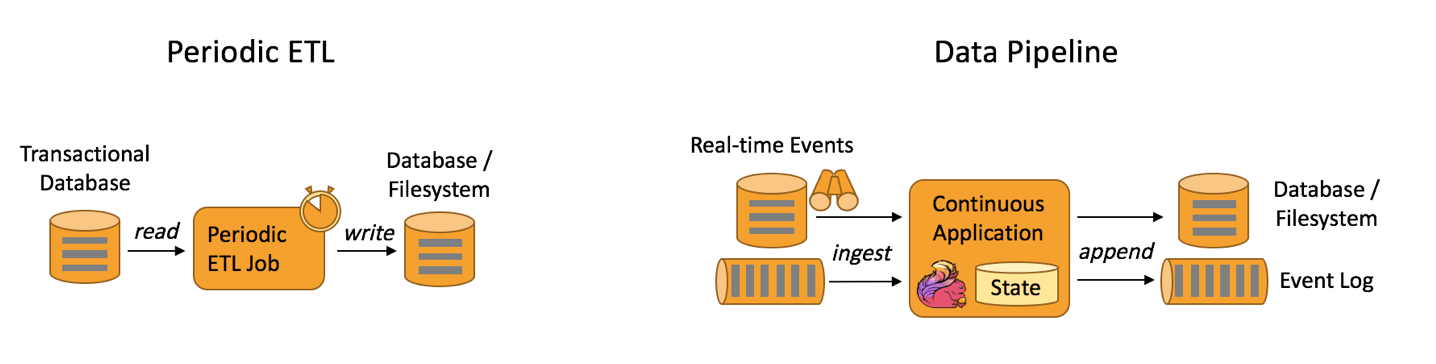
延迟数据处理
对迟到元素处理,要根据具体业务权衡利弊。
对于不是很重要的数据,并且追求实效性可以直接抛弃。
对于数据实效性可以一定容忍,可以使用WaterMark去延迟处理数据。
对于数据很重要,并且要求很实时计算,可以加入Allowed lateness 不关闭窗口延迟更新。但是注意这会消耗大量的资源。
甚至可以结合WaterMark再加上Allowed lateness来处理延迟数据。
处理迟到的元素的策略
DataStream API提供了三种策略来处理迟到元素:
- 直接抛弃迟到的元素
- 将迟到的元素发送到另一条流中去
- 可以更新窗口已经计算完的结果,并发出计算结果。
参考
CSDN:Flink迟到元素的处理
https://blog.csdn.net/shenjianyu_rex/article/details/108453046
B站:Flink时间和水印推荐
https://www.bilibili.com/video/BV1hy4y1E7Sx

若有收获,就点个赞吧
0 人点赞
