流流关联
Φ Flink SQL
关于SQL Join
无论在OLAP还是OLTP领域,Join都是业务常会涉及到且优化规则比较复杂的SQL语句。对于离线计算而言,经过数据库领域多年的积累,Join语义以及实现已经十分成熟,然而对于近年来刚兴起的Streaming SQL来说Join却处于刚起步的状态。其中最为关键的问题在于Join的实现依赖于缓存整个数据集,而Streaming SQL Join的对象却是无限的数据流,内存压力和计算效率在长期运行来说都是不可避免的问题。
批量SQL Join
对于传统的离线批量SQL(面向有界数据集的SQL),join有三种经典算法,分别是Nested-Loop Join、Sort-Merge Join、Hash-join。
| 对比项 | 嵌套循环连接(Nested-loop Join) | 排序合并连接(Sort-Merge Join) | 哈希连接(Hash Join) |
|---|---|---|---|
| 适用场景 | 外层循环小,内存循环条件列有序 | 输入两端都有序 | 数据量大,且没有索引 |
| CPU | 低 | 低(如果没有显式排序) | 高 |
| 内存 | 低 | 低(如果没有显式排序) | 高 |
| IO | 可能高可能低 | 低 | 可能高可能低 |
- 嵌套循环连接
Nested-loop Join,最为简单直接,将两个数据集加载到内存,并用内嵌遍历的方式来逐个比较两个数据集内的元素是否符合Join条件。Nested-loop Join虽然时间效率以及空间效率都是最低的,但胜在比较灵活适用范围广,因此其变体BNLJ常被传统数据库用作为Join的默认基础选项(MySQL旧版本只支持Nested-loop Join这一种Join算法,新版本中开始支持Hash Join)。MySQL中的嵌套循环连接实现模式有以下几种方式(R:源表,S:连接表):
| 对比项 | Simple Nested Loop Join | Index Nested Loop Join | Block Nested Loop Join |
|---|---|---|---|
| 外表扫描次数 | 1 | 1 | 1 |
| 内表扫描次数 | R | 0 |  |
| 读取记录次数 | R + R * S | R + RS_Matches |  |
| 比较次数 | R * S | R * IndexHeight | R * S |
| 回表次数 | 0 | RS_Matches | 0 |
1.Simple Nested Loop Join(SNLJ)
SNLJ就是两层循环全量扫描连接的两张表,得到符合条件的两条记录则输出,这也就是让两张表做笛卡尔积,比较次数是R S,是比较暴力的算法,会比较耗时。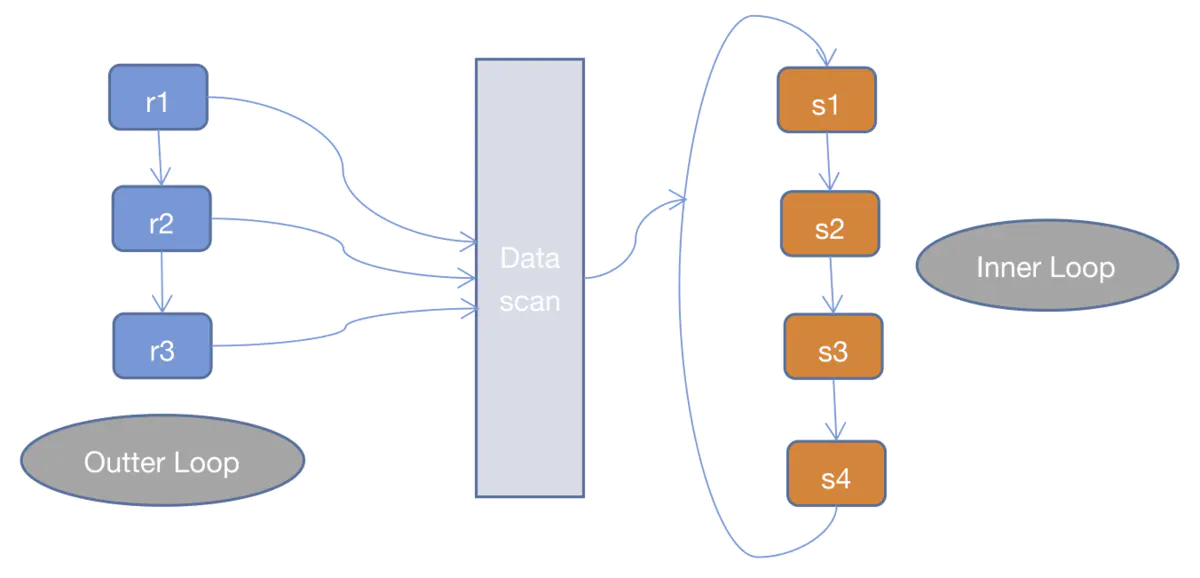
2.__Index Nested Loop Join(INLJ)
INLJ是在SNLJ的基础上做了优化,通过连接条件确定可用的索引,在Inner Loop中扫描索引而不去扫描数据本身,从而提高Inner Loop的效率。而INLJ也有缺点,就是如果扫描的索引是非聚簇索引,并且需要访问非索引的数据,会产生一个回表读取数据的操作,这就多了一次随机的I/O操作。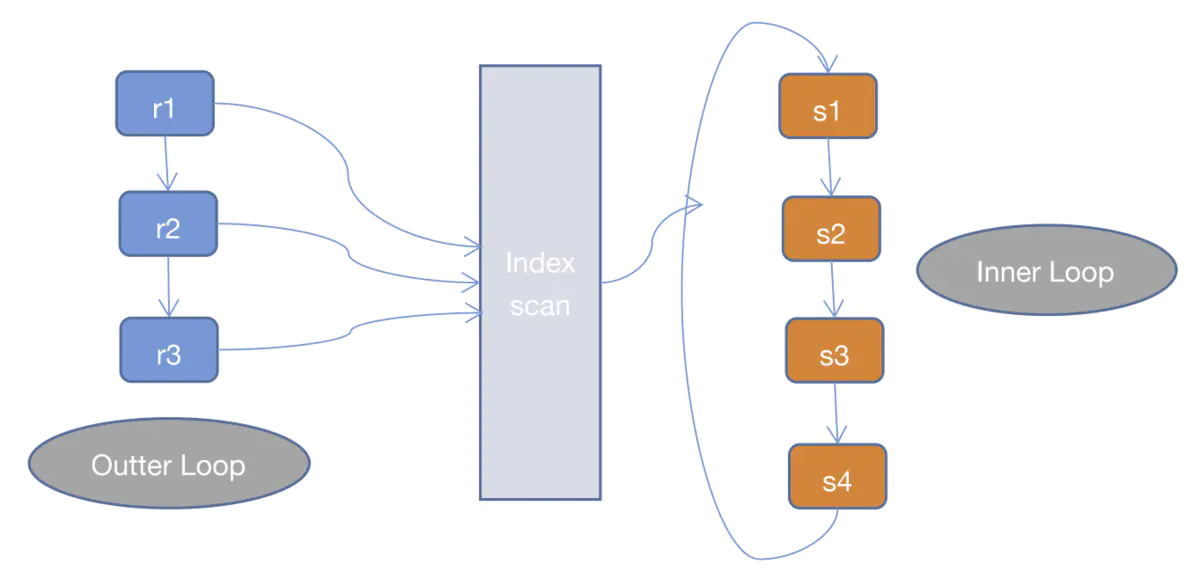
*3.__Block Nested Loop Join(BNLJ)
一般情况下,MySQL优化器在索引可用的情况下,会优先选择使用INLJ算法,但是在无索引可用,或者判断full scan可能比使用索引更快的情况下,还是不会选择使用过于粗暴的SNLJ算法。这里就出现了BNLJ算法了,BNLJ在SNLJ的基础上使用了join buffer,会提前读取Inner Loop所需要的记录到buffer中,以提高Inner Loop的效率。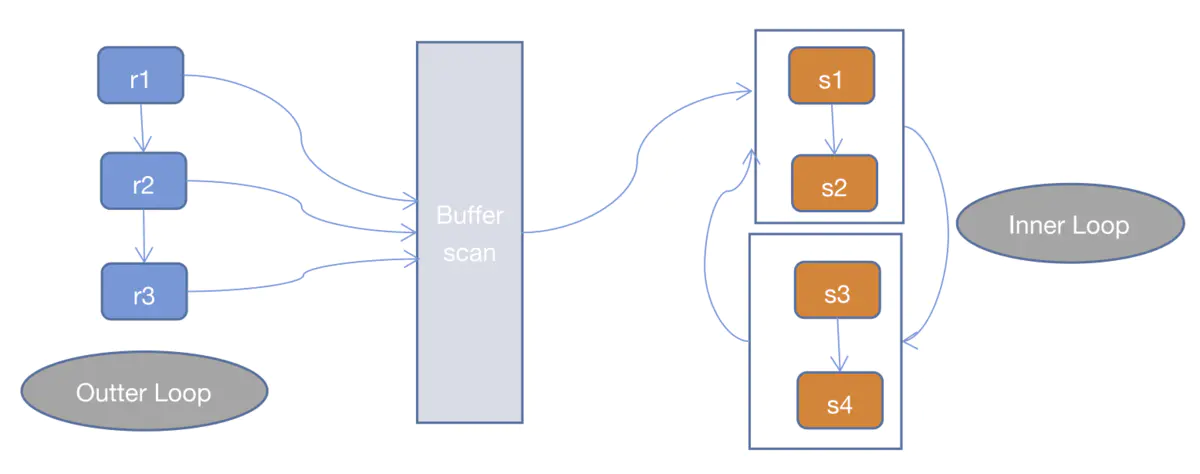
- 排序合并连接
Sort-Merge Join,顾名思义,分为Sort和Merge两个阶段。首先将两个数据集进行分别排序,然后对两个有序数据集分别进行遍历和匹配,类似于归并排序的合并。值得注意的是,Sort-Merge只适用于Equi-Join(Join条件均使用等于作为比较算子)。**Sort-Merge Join要求对**两个数据集进行排序,成本很高,通常作为输入本就是有序数据集的情况下的优化方案。
示例:
SparkSQL对两张大表join采用了全新的算法:sort-merge join,如下图所示,整个过程分为三个步骤: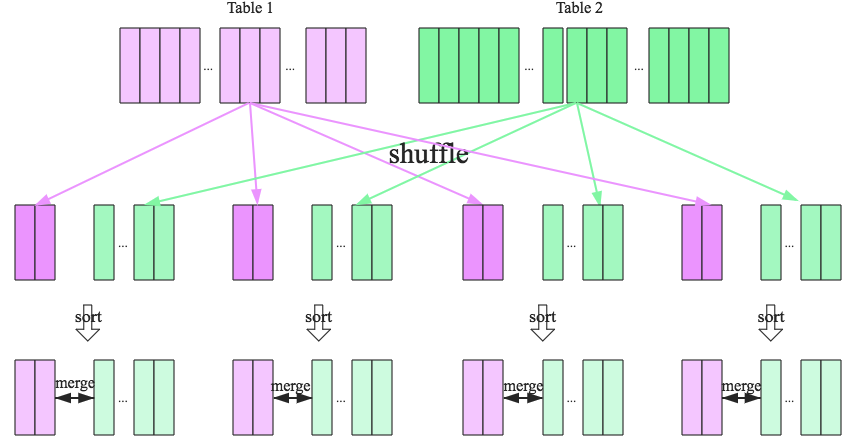
1.shuffle阶段
将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理。
2.sort阶段
对单个分区节点的两表数据,分别进行排序。
3.merge阶段**
对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则取更小一边。如下图所示: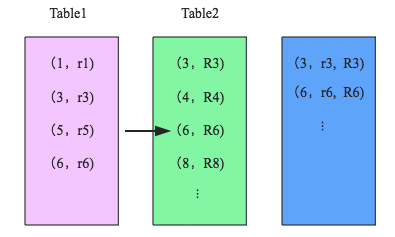
- 哈希连接
Hash Join,同样分为两个阶段,首先将一个数据集转换为Hash Table,然后遍历另外一个数据集元素并与 Hash Table内的元素进行匹配。第一阶段和第一个数据集分别称为build阶段和build table(小表),第二个阶段和第二个数据集分别称为probe阶段和probe table。Hash Join效率较高但对空间要求较大,通常是作为Join其中一个表为适合放入内存的小表的情况下的优化方案。和 Sort-Merge Join类似,Hash Join也只适用于Equi-Join。
示例:
对于一条简单SQL语句:select from order,item where item.id = order.i_id,参与join的两张表是item和order,join key分别是item.id以及order.i_id。采用hash join算法,整个过程会经历三步:
1.确定Build Table以及Probe Table
这个概念比较重要,Build Table使用join key构建Hash Table,而Probe Table使用join key进行探测,探测成功就可以join在一起。通常情况下,小表会作为Build Table,大表作为Probe Table。此示例中item为Build Table,order为Probe Table。
2.构建Hash Table
依次读取Build Table(item)的数据,对于每一行数据根据join key(item.id)进行hash,hash到对应的Bucket,生成hash table中的一条记录。数据缓存在内存中,如果内存放不下需要dump到外存。
*3.探测
再依次扫描Probe Table(order)的数据,使用相同的hash函数映射Hash Table中的记录,映射成功之后再检查join条件(item.id = order.i_id),如果匹配成功就可以将两者join在一起。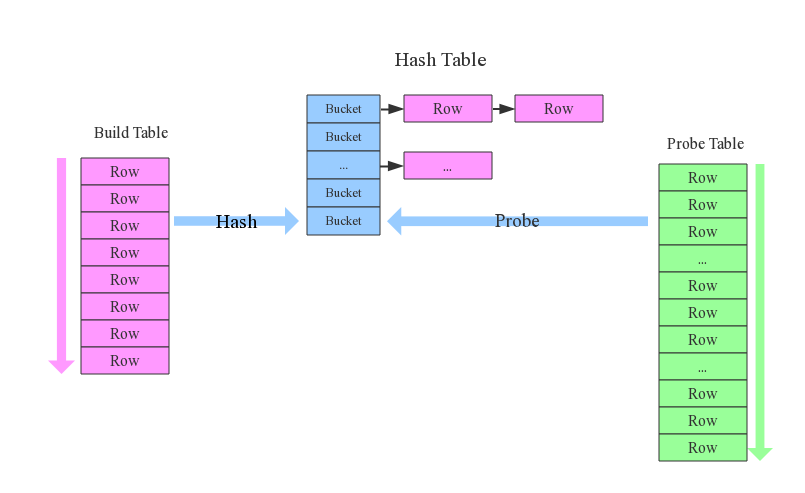
实时SQL Join
相对于离线的Join,实时Streaming SQL(面向无界数据集的SQL)无法缓存所有数据,因此Sort-Merge Join 要求的对数据集进行排序基本是无法做到的,而Nested-loop Join和Hash Join经过一定的改良则可以满足实时SQL的要求。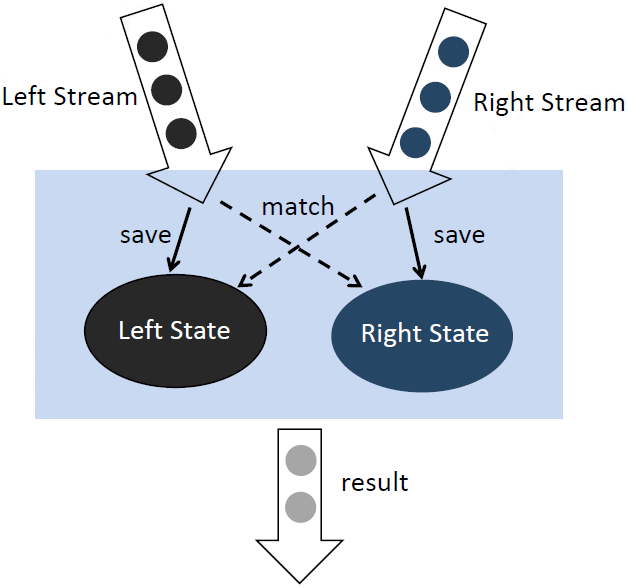
通过案例来看基本的Nested-loop Join在实时Streaming SQL的基础实现。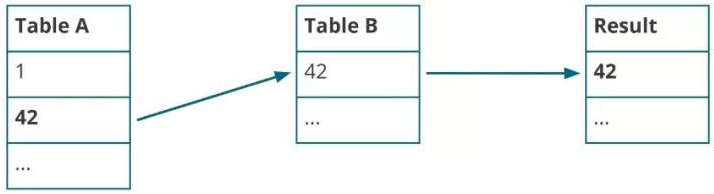
Table A有“1”、“42” 两个元素,Table B有“42”一个元素,所以此时的Join结果会输出“42”。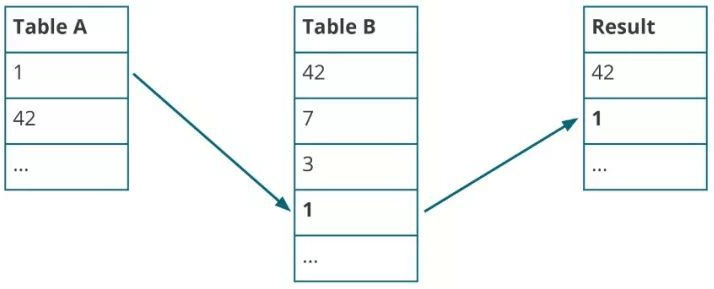
接着Table B依次接受到三个新的元素,分别是“7”、“3”、“1”。因为“1”匹配到Table A的元素,因此结果表再输出一个元素“1”。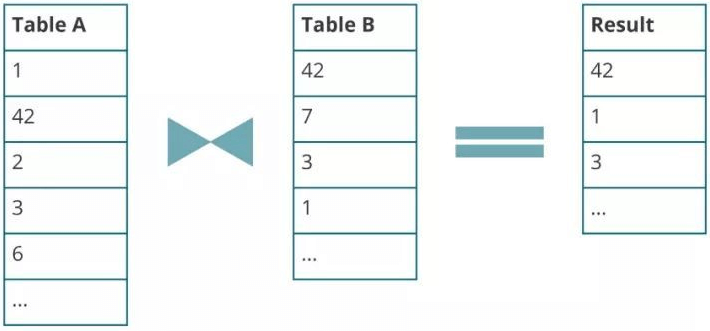
随后Table A出现新的输入“2”、“3”、“6”、“3”,匹配到Table B的元素,因此再输出“3”到结果表。
可以看到在Nested-Loop Join中我们需要保存两个输入表的内容,而随着时间的增长Table A和Table B需要保存的历史数据无止境地增长,导致很不合理的内存磁盘资源占用,而且单个元素的匹配效率也会越来越低。类似的问题也存在于Hash Join中。
那么有没有可能设置一个缓存剔除策略,将不必要的历史数据及时清理呢?答案是肯定的,关键在于缓存剔除策略如何实现,这也是Flink SQL提供的几种Join的主要区别。
Flink SQL Join
Regular Join
Regular Join是最为基础的没有缓存剔除策略的Join。Regular Join中两个表的输入和更新都会对全局可见,影响之后所有的Join结果。举例,在如下的Join查询里,Orders表的新记录会和Product表所有历史记录以及未来的记录进行匹配。
SELECT * FROM OrdersINNER JOIN ProductON Orders.productId = Product.id
因为历史数据不会被清理,所以Regular Join允许对输入表进行任意种类的更新操作(insert、update、delete)。然而因为资源问题Regular Join通常是不可持续的,一般只用做有界数据流的Join。
Flink目前不支持cross join。
-- inner joinselect *from Orders inner join Product on Orders.productId=Product.id-- left joinselect *from Orders left join Product on Orders.productId=Product.id-- right outer joinselect *from Orders right join Product on Orders.productId=Product.id-- full outer joinselect *from Orders full outer join Product on Orders.productId=Product.id
Interval Join
Interval Join旧的名称为:Time-Windowed Join,利用窗口(时间窗口)给两个输入表设定一个Join的时间界限,超出时间范围的数据则对Join不可见并可以被清理掉。值得注意的是,这里涉及到的一个问题是时间的语义,时间可以指计算发生的系统时间(即 Processing Time),也可以指从数据本身的时间字段提取的Event Time。如果是Processing Time,Flink根据系统时间自动划分Join的时间窗口并定时清理数据;如果是Event Time,Flink分配Event Time窗口并依据Watermark来清理数据。
以更常用的Event Time Windowed Join为例,一个将Orders订单表和Shipments运输单表依据订单时间和运输时间Join的查询如下:
SELECT *FROMOrders o,Shipments sWHEREo.id = s.orderId ANDs.shiptime BETWEEN o.ordertime AND o.ordertime + INTERVAL '4' HOUR
这个查询会为Orders表设置o.ordertime > s.shiptime- INTERVAL ‘4’ HOUR的时间下界。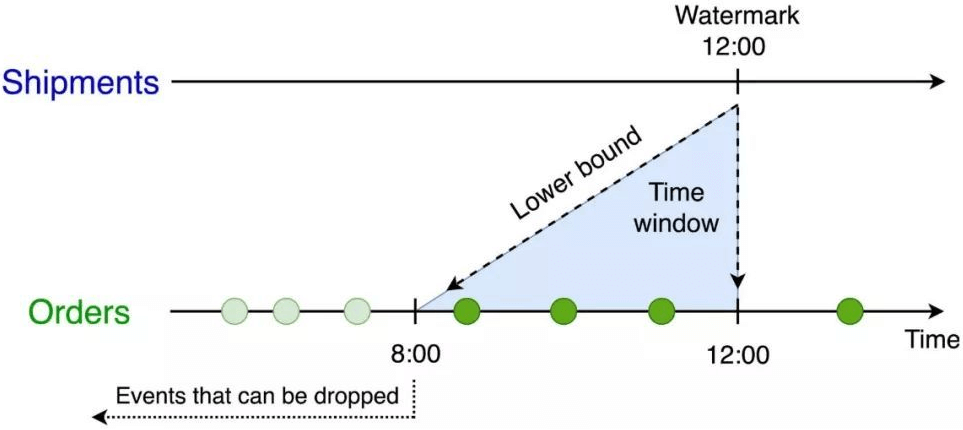
并为Shipmenets表设置s.shiptime >= o.ordertime的时间下界。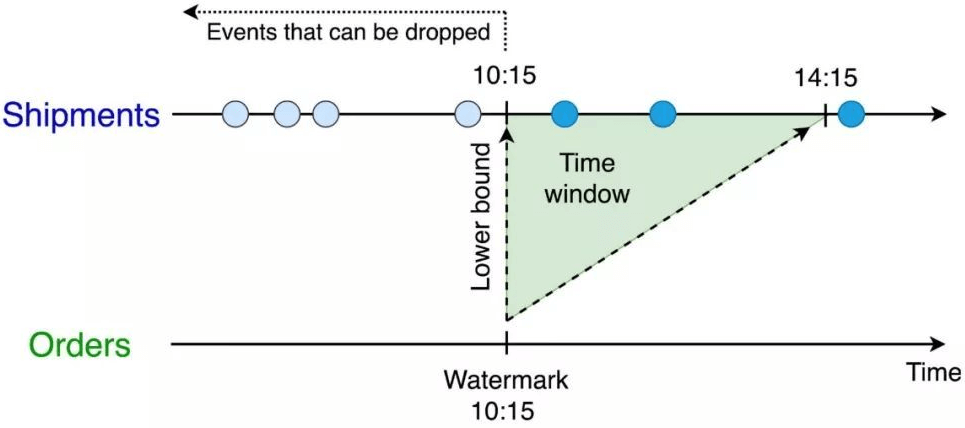
因此两个输入表都只需要缓存在时间下界以上的数据,将空间占用维持在合理的范围。不过虽然底层实现上没有问题,但如何通过SQL语法定义时间仍是难点。尽管在实时计算领域Event Time、Processing Time、Watermark这些概念已经成为业界共识,但在SQL领域对时间数据类型的支持仍比较弱。因此,定义Watermark和时间语义都需要通过编程API的方式完成,比如从DataStream转换至Table,不能单纯靠SQL完成。
Temporal Table Join
虽然Interval Join解决了资源问题,但也限制了使用场景: Join两个输入流都必须有时间下界,超过之后则不可访问。这对于很多Join维表的业务来说是不适用的,因为很多情况下维表并没有时间界限。针对这个问题,Flink 提供了Temporal Table Join来满足用户需求。
Temporal Table Join类似于Hash Join,将输入分为Build Table和Probe Table。前者一般是维度表的changelog(对表的一系列更新操作),后者一般是业务数据流,典型情况下后者的数据量应该远大于前者。在Temporal Table Join中,Build Table是一个基于append-only数据流的带时间版本的视图,所以又称为Temporal Table。Temporal Table要求定义一个主键和用于版本化的字段(通常就是Event Time时间字段),以反映记录在不同时间的内容。
比如典型的一个例子是对商业订单金额进行汇率转换。假设有一个Orders流记录订单金额,需要和RatesHistory汇率流进行Join。RatesHistory代表不同货币转为日元的汇率,每当汇率有变化时就会有一条更新记录。两个表在某一时间节点内容如下: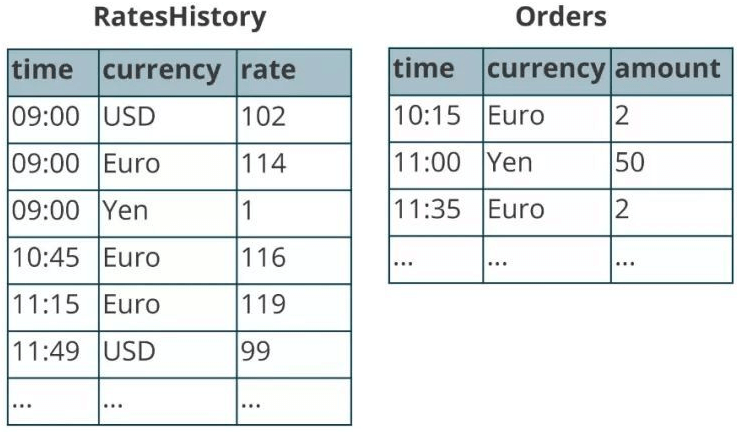
将RatesHistory注册为一个名为Rates的Temporal Table,设定主键为currency,版本字段为time。
此后给Rates指定时间版本,Rates则会基于RatesHistory来计算符合时间版本的汇率转换内容。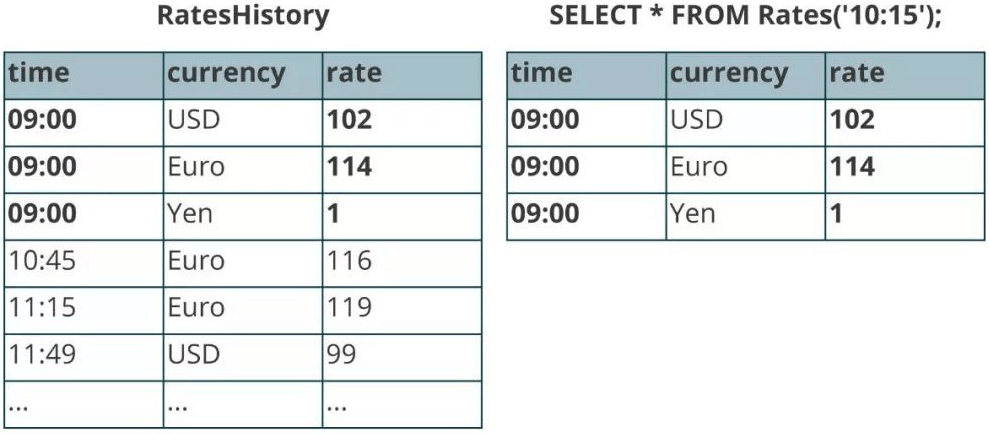
在Rates的帮助下,可以将业务逻辑用以下的查询来表达:
SELECTo.amount * r.rateFROMOrders o,LATERAL Table(Rates(o.time)) rWHEREo.currency = r.currency
值得注意的是,不同于在Regular Join和Interval Join中两个表是平等的,任意一个表的新记录都可以与另一表的历史记录进行匹配,在Temporal Table Join中,Temoparal Table的更新对另一表在该时间节点以前的记录是不可见的。这意味着我们只需要保存Build Side的记录直到Watermark超过记录的版本字段。因为Probe Side的输入理论上不会再有早于Watermark的记录,这些版本的数据可以安全地被清理掉。
Φ Flink DataStream API
Window Join
两个流join时,先做join操作,形成JoinedStream,然后再指定Window,最后接着join后的transform操作。Window Join将两个流中有相同key和处在相同window(计数窗口)的元素做join,其使用语法如下:
stream.join(otherStream).where(<KeySelector>).equalTo(<KeySelector>).window(<WindowAssigner>) // WindowAssigner定义window划分方式.apply(<JoinFunction>) // JoinFunction/FlatJoinFunction中实现匹配元素的处理逻辑
- 翻滚窗口
Tumbling Window Join。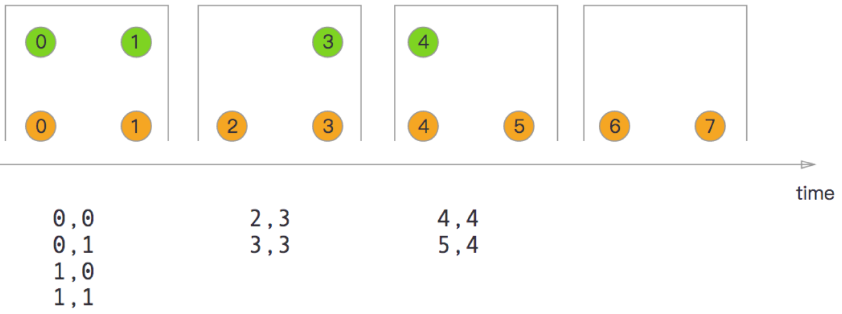
实现:
orangeStream.join(greenStream).where(elem => /* select key */).equalTo(elem => /* select key */).window(TumblingEventTimeWindows.of(Time.milliseconds(2))).apply((e1,e2)=> e1 + "," +e2)
- 滑动窗口
Sliding Window Join。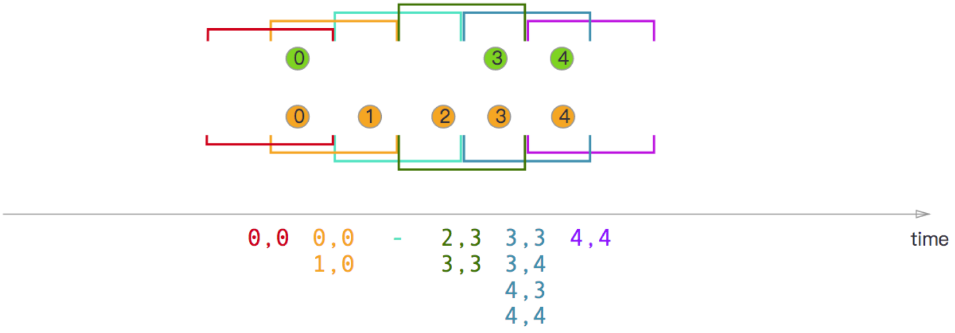
实现:
orangeStream.join(greenStream).where(elem => /* select key */).equalTo(elem => /* select key */).window(SlidingEventTimeWindows.of(Time.milliseconds(2)) /* size */, Time.milliseconds(1) /* slide */).apply((e1,e2)=> e1 + "," +e2)
- 会话窗口
Session Window Join。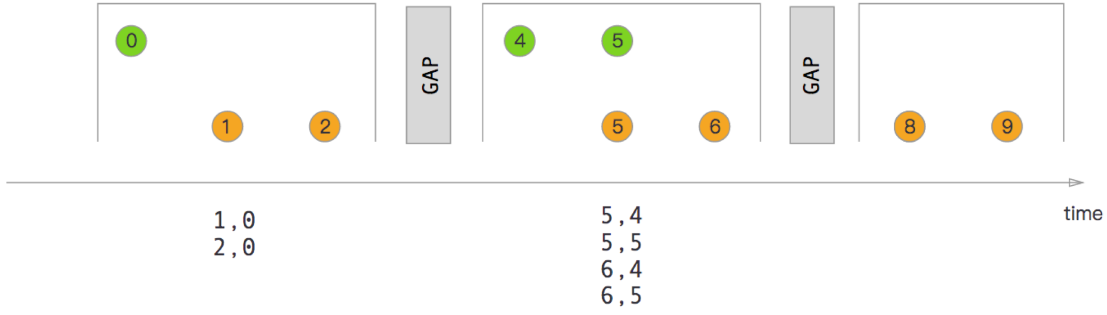
实现:
orangeStream.join(greenStream).where(elem => /* select key */).equalTo(elem => /* select key */).window(EventTimeSessionWindows.withGap(Time.milliseconds(2))).apply((e1,e2)=> e1 + "," +e2)
Interval Join
interval join与其他窗口关联不同,间隔关联的数据元素关联范围不依赖窗口划分,而是通过DataStream元素的时间加上或减去指定Interval作为关联窗口,然后和另外一个DataStream的数据元素时间在窗口内进行Join操作。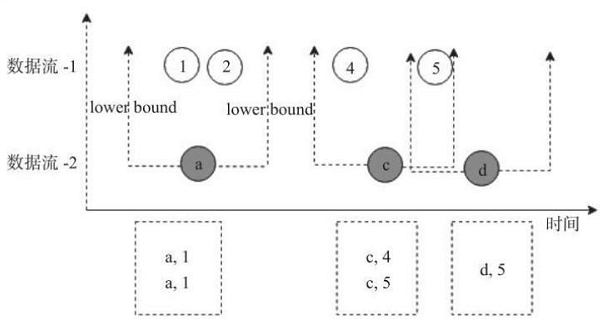
Flink对于interval join的支持从1.4版本开始,直到Flink1.6,经过几个版本的增强,形成了从开始的Table/Sql Api的支持,到后续DataStream Api的支持,从开始的inner join 到后来的left outer,right outer, full outer join的支持,算是完成了FLink对双流关联的支持,不同版本的功能支持如下:
| Flink版本 | Join支持类型 | join API |
|---|---|---|
| 1.4 | inner | Table/SQL |
| 1.5 | inner,left,right,full | Table/SQL |
| 1.6 | inner,left,right,full | Table/SQL/DataStream |
实现:
// 创建黑色元素数据集val blackStream: DataStream[(Int, Long)] = env.fromElements((2, 21L), (4, 1L), (5, 4L))// 创建白色元素数据集val whiteStream: DataStream[(Int, Long)] = env.fromElements((2, 21L), (1, 1L), (3, 4L))// 通过Join方法将两个数据集进行关联val windowStream: DataStream[String] = blackStream.keyBy(_._1)// 调用intervalJoin方法关联另外一个DataStream.intervalJoin(whiteStream.keyBy(_._1))// 设定时间上限和下限.between(Time.milliseconds(-2), Time.milliseconds(1)).process(new ProcessWindowFunciton())// 通过单独定义ProcessWindowFunciton实现ProcessJoinFunctionclass ProcessWindowFunciton extends ProcessJoinFunction[(Int, Long), (Int, Long), String] {override def processElement(in1: (Int, Long), in2: (Int, Long), context: ProcessJoinFunction[(Int, Long), (Int, Long), String]#Context, collector: Collector[String]): Unit = {collector.collect(in1 + ":" + (in1._2 + in2._2))}}
参考:
Apache Flink 漫谈系列 - Time Interval JOIN
https://blog.csdn.net/qq_31866793/article/details/96476571
https://enjoyment.cool/2019/03/22/Apache%20Flink%20%E6%BC%AB%E8%B0%88%E7%B3%BB%E5%88%97%20-%20Time%20Interval%20JOIN/#more
维表关联
维表Join一般由单流驱动(**probe流驱动**),维表(Build Table)通过预加载到内存、缓存、热存储、广播等多种方式引入流式计算。(Temporal Table JOIN 也是单流驱动)
Φ 方案1:数据库关联
实时数据库查找关联(Per-Record Reference Data Lookup)是在DataStream API(用户自定义函数)中直接访问数据库来进行关联的方式。这种方式通常开发量最小,但一般会给数据库带来很大的压力,而且因为关联是基于Processing Time的,如果数据有延迟或者重放,可能会得到和原来不一致的数据。
方案1.1:同步数据库查找关联
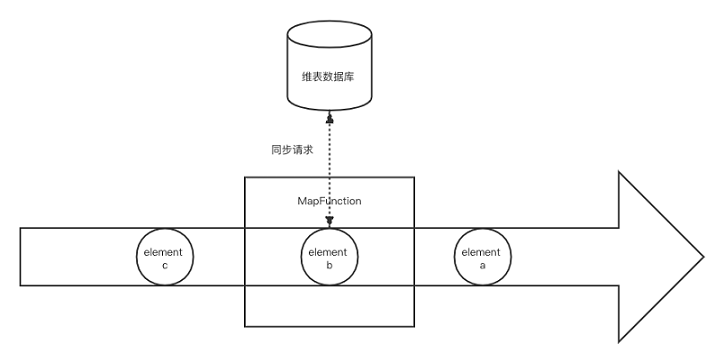
- 实现方式
同步实时数据库查找关联是最为简单的关联方式,只需要在一个Map或者FlatMap函数中访问数据库,处理好关联逻辑后,将结果数据输出。
- 优点
实现简单、不需要额外内存、维表的更新延迟低。
- 缺点
- 因为每条数据都需要请求一次数据库,给数据库造成的压力很大;
- 访问数据库是同步调用,导致subtask线程会被阻塞,影响吞吐量;
- 关联是基于Processing Time的,结果并不具有确定性;
- 瓶颈在数据库端,但实时计算的流量通常远大于普通数据库的设计流量,因此可拓展性比较低。
- 适用场景
可用于流量比较低的作业,但通常不是最好的选择。
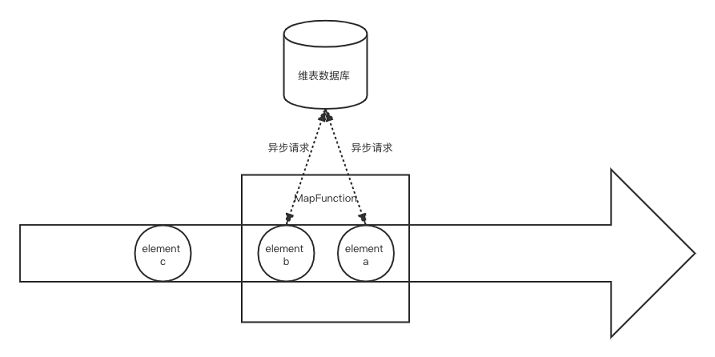
异步数据库查找关联是通过Flink AsyncIO API来访问外部数据库的方式。利用数据库提供的异步客户端,AsyncIO可以并发地处理多个请求,很大程度上减少了对subtask线程的阻塞。因为数据库请求响应时长是不确定的,可能导致后输入的数据反而先完成计算,所以AsyncIO提供有序和无序两种输出模式,前者会按请求返回顺序输出数据,后者则会缓存提前完成计算的数据,并按输入顺序逐个输出结果。
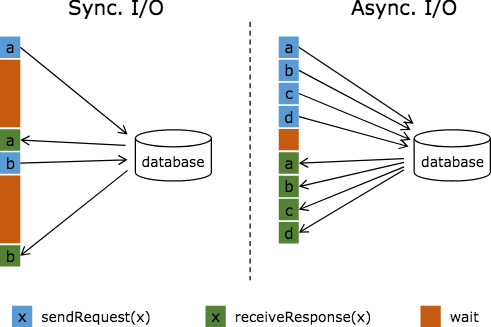
- 优点
实现简单(Flink AsyncIO API封装)。
- 缺点
- 有序输出模式下的AsyncIO会需要缓存数据,且这些数据会被写入checkpoint,因此会消耗一定量的系统存储资源。
- 同步数据库查找关联的吞吐量问题得到解决,但仍不可避免地有数据库负载高和结果不确定两个问题。
- 适用场景
比较适合流量低的实时计算。
代码示例
// TODO
参考:
Flink使用异步IO访问外部数据
https://blog.icocoro.me/2019/06/10/1906-apache-flink-asyncio/
flink异步IO
https://blog.csdn.net/wflh323/article/details/102916853
Flink 异步IO访问外部数据(mysql篇)
https://www.cnblogs.com/Springmoon-venn/p/11103558.html方案1.3:带缓存的数据库查找关联
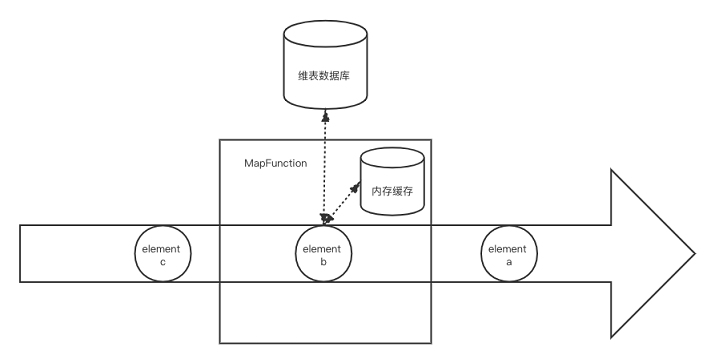
实现方式
为了解决上述两种关联方式对数据库造成太大压力的问题,可以引入一层缓存来减少直接对数据库的请求。缓存并一般不需要通过checkpoint机制持久化,因此简单地用一个WeakHashMap或者Guava Cache就可以实现。
- 优点
数据库的压力将得到一定程度的缓解。
- 缺点
冷启动的时候仍会给数据库造成一定压力,维表的更新并不能及时反应到关联操作上,当然这也和缓存剔除的策略有关,需要根据维度表更新频率和业务对过时维表数据的容忍程度来设计。
- 适用场景
适合于流量比较低,且对维表数据实时性要求不太高或维表更新比较少的业务场景。
代码示例
// TODO
Φ 方案2:预加载维表关联
预加载维表关联(Pre-Loading of Reference Data),相比起实时数据库查找在运行期间为每条数据访问一次数据库,预加载维表关联是在作业启动时就将维表读到内存中,而在后续运行期间,每条数据都会和内存中的维表进行关联,而不会直接触发对数据的访问。与带缓存的实时数据库查找关联相比,区别是后者如果不命中缓存还可以退回到数据库访问,而前者如果不命中则会关联不到数据。
方案2.1:启动预加载维表
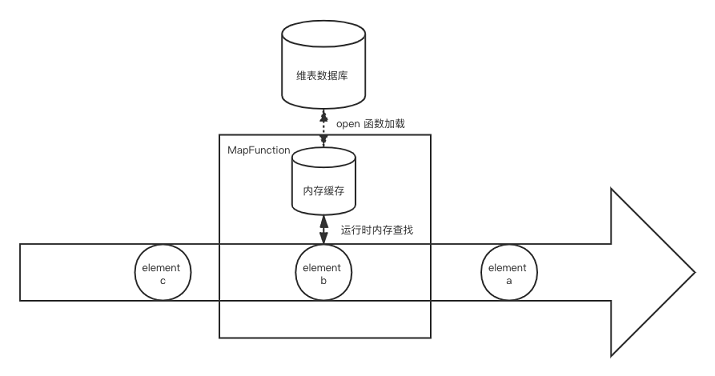
实现方式
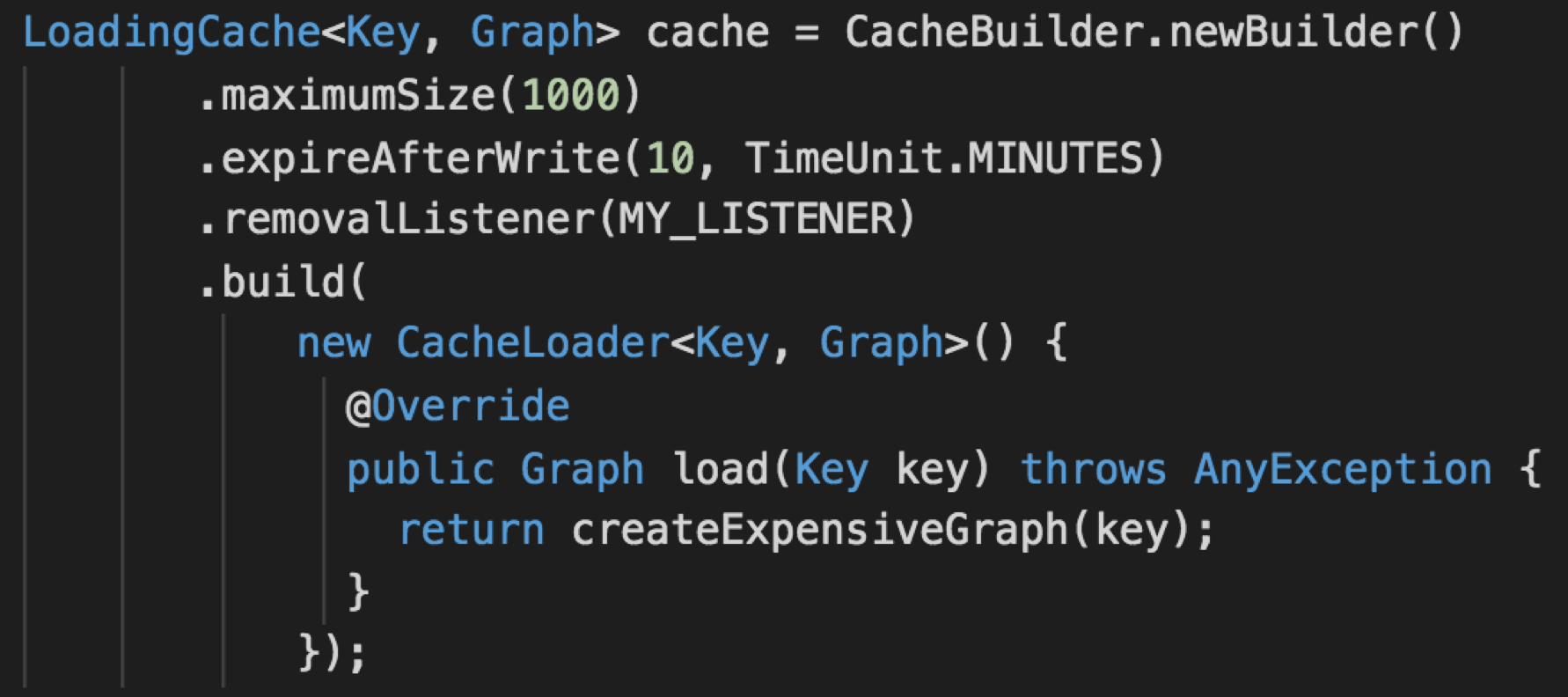
启动预加载维表是最为简单的一种方式,即在作业初始化的时候,比如用户函数的open()方法,直接从数据库将维表拷贝到内存中。维表并不需要用State来保存,因为无论是手动重启或者是Flink的错误重试机制导致的重启,open()方法都会被执行,从而得到最新的维表数据。定义一个类实现RichFlatMapFunction,在open()中读取维度数据库,将数据全量加载到内存。在probe流上使用该算子,运行时与内存维度数据关联。
- 优点
实现简单,启动预加载维表对数据库的压力只持续很短时间,运行期间不需要再访问数据库,可以提高效率,有点类似离线计算。
- 缺点
因为是拷贝整个维表所以压力是很大的,仅支持小数据量维表,维表更新需要重启作业,运行期间维表数据不能更新,且对TaskManager内存的要求比较高。
- 适用场景
维表小、变更频率低、对变更及时性要求低。如:根据ip库解析国家地区,若ip库有新版本,重启作业即可。
代码示例 ```scala class DimFlatMapFunction extends RichFlatMapFunction[(Int,String),(Int,String,String)]{ var dim: Map[Int,String] = Map() var connection: Connection = _
override def open(conf: Configuration): Unit = {
super.open(conf)Class.forName("com.mysql.jdbc.Driver")val url = "jdbc:mysql://localhost:3306/demo"val username = "root"val password = "****"connection = DriverManager.getConnection(url,username,password)varl sql = "select pid,pname from dim_product"val statement = connection.prepareStatement(sql)try{// 执行查询,缓存维表数据var resultSet = statement.excuteQuery()while(resultSet.next()){var pid = resultSet.getInt("pid")var pname = resultSet.getString("pname")dim += (pid -> pname)}} catch {case e: Exception => println(e.getMessage)}connection.close()
}
override def flatMap(in: (Int,String),out: Collector[(Int,String,String)]): Unit = {
val probeId = in._1if(dim.contains(probeId)){out.collect((in._1,in._2,dim.get(probeID).toString))}
}
}
<a name="4Sb70"></a>### 方案2.2:启动预加载分区维表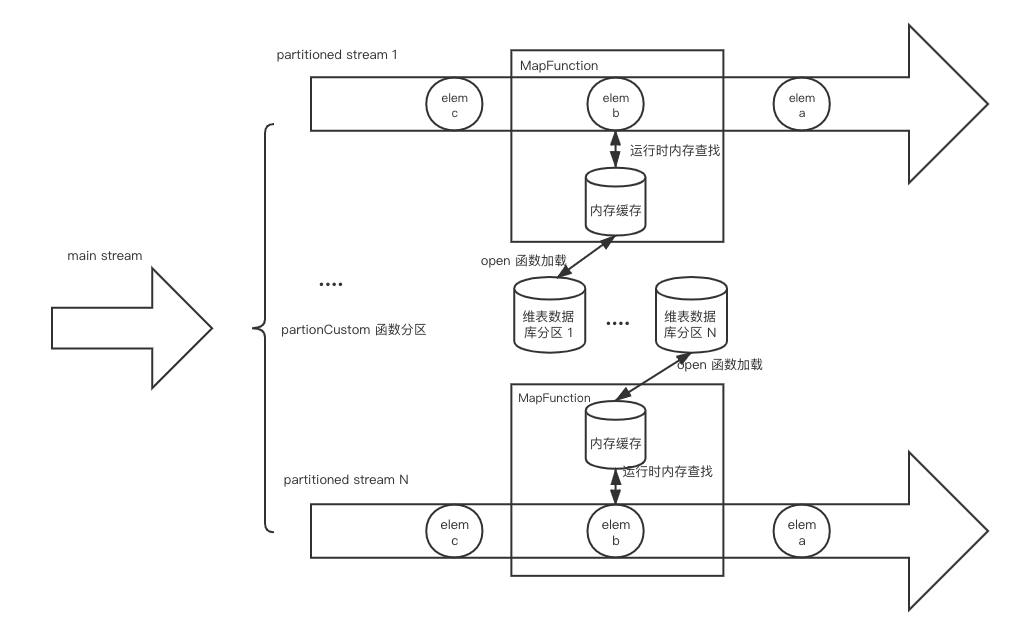- **实现方式**对于维表比较大的情况,可以启动预加载维表基础之上增加分区功能。简单来说就是将数据流按字段进行分区,然后每个subtask只需要加在对应分区范围的维表数据。(_**注意:这里的分区方式并不是用keyby这种通用的hash分区,而是需要根据业务数据定制化分区策略,然后调用DataStream#partitionCustom**_)如:按照userId等区间划分,0-999划分到subtask 1,1000-1999划分到subtask 2,以此类推。而在open()方法中,我们再根据subtask的id和总并行度来计算应该加载的维表数据范围。- **优点**维表的大小上限理论上可以线性拓展,解决了维表大小受限于单个 TaskManager 内存的问题(现在是取决于所有 TaskManager 的内存总量)。- **缺点**设计和维护分区策略具有一定的复杂性。- **适用场景**适合维表比较大而变更实时性要求不高的场景,如:用户点击数据关联用户所在地。- **代码示例**```java// TODO
方案2.3:启动预加载维表并定时刷新
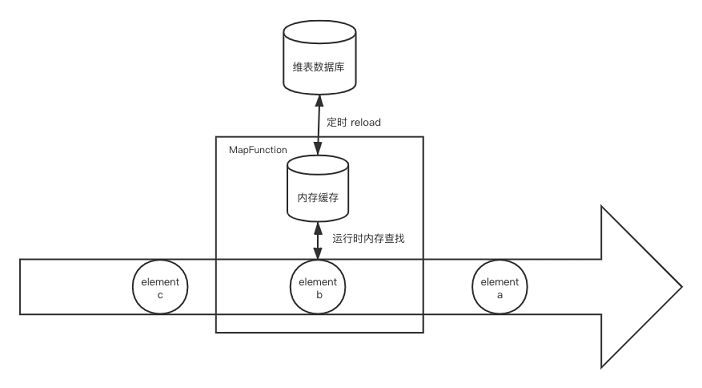
- 实现方式
除了维表大小的限制,启动预加载维表的另一个主要问题在于维度数据的更新,我们可以通过引入定时刷新机制的办法来缓解这个问题。定时刷新可以通过Flink ProcessFucntion提供的Timer或者直接在open()初始化一个线程(池)来做这件事。不过Timer要求KeyedStream,而上述的DataStream#partitionCustom并不会返回一个KeyedStream,因此两者并不兼容。而如果使用额外线程定时刷新的办法则不受这个限制。
- 优点
比起基础的启动预加载维表 ,这种方式在于引入比较小复杂性的情况下大大缓解了的维度表更新问题。
- 缺点
给维表数据库带来更多压力,因为每次reload的时候都是一次请求高峰。
- 适用场景
适合维表变更实时性要求不是特别高的场景。取决于定时刷新的频率和数据库的性能,这种方式可以满足大部分关联维表的业务。
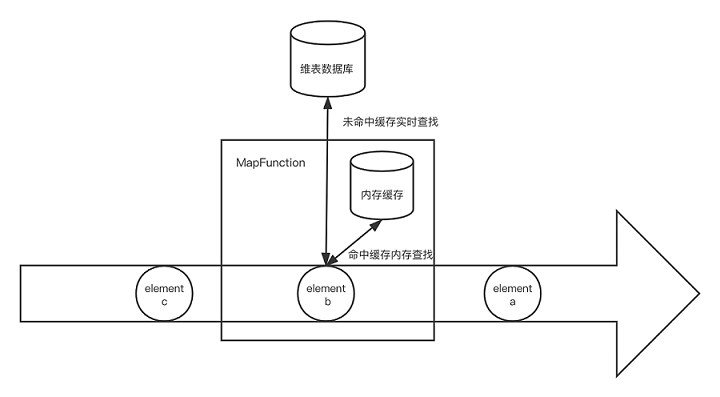
启动预加载维表还可以和实时数据库查找混合使用,即将预加载的维表作为缓存给实时关联时使用,若未命中则回退到数据库查找。
- 优点
这种方式实际是带缓存的数据库查找关联的衍生,相比冷启动时未命中缓存导致的多次实时数据库访问,该方式直接批量拉取整个维表效率更高。
- 缺点
有可能拉取到不会访问到的多余数据
- 适用场景
适合流量比较低,且对维表数据实时性要求不太高或维表更新比较少的业务场景。
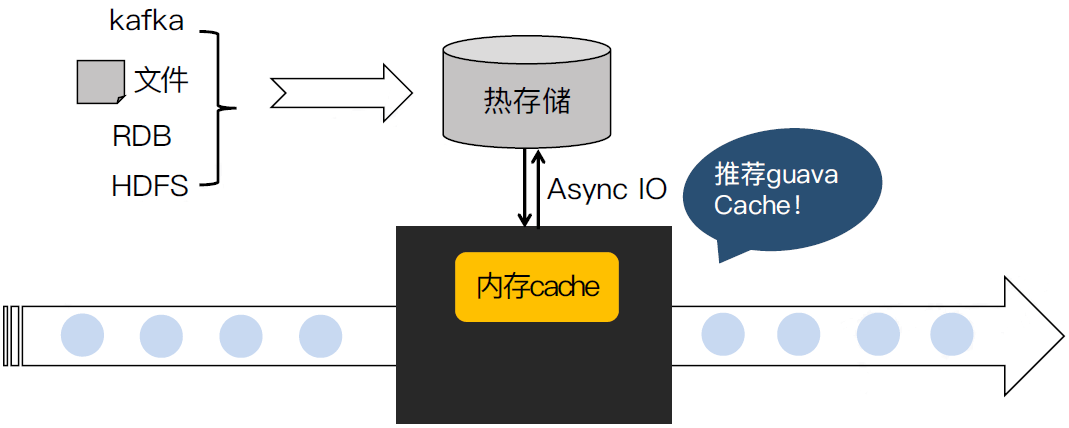
将维度数据导入热存储(Redis/Tair/HBase/ES),通过异步IO查询热存储,利用cache机制将维度数据缓存在内存。
- 优点
维度数据不受限于内存,支持较多维度数据。
- 缺点
需要热存储资源,维度更新反馈到结果有延迟(热存储导入cache)。
- 适用场景
维度数据量大,可接受维度更新有一定延迟。
代码示例
// TODO
参考:
Flink通过异步IO实现redis维表join
https://zhuanlan.zhihu.com/p/99430246Φ 方案4:分布式缓存
通过Distributed Cache分发本地维度文件到task manager后加载到内存关联。
实现方式
- 通过env.registerCachedFile注册文件
- 实现RichFunction,在open()中通过RuntimeContext获取cache文件
- 解析和使用文件数据
- 优点
不需要外部数据库。
- 缺点
支持的维表数据量小,更新需要改文件并重启作业。
- 适用场景
维度数据是文件形式、数据量小、更新频率极低。如:静态码表、配置文件。(不适合生产环境使用,不利于元数据管理)
- 将维度数据发送到kafka作为广播原始流(S1)。
- 定义状态描述符MapStateDescriptor。调用S1.broadcast(),获得broadCastSteam(S2)。
- 调用非广播流(S3),S3.connect(S2),得到BroadcastConnectedStream(S4)。
- 在keyedBroadcastProcessFunction/BroadcastProcessFunction实现关联处理逻辑,并作为参数调用S4.process()。
- 优点
维度变更可即时更新到结果。
- 缺点
数据保存在内存中,支持的维表数量较小。
- 适用场景
需要实时感知维度变更,维度数据可转换为实时流。
- 代码示例
广播流(pageStream):(pageid,pageName)
非广播流:{“did”:”DKALNFGE”,”pageid”:”a1”,”time”:”1580753900011L”}
// 定义广播状态描述符val broadcastStateDesc = new MapStateDescriptor("broadcast_state",classOf[String] /* KeyClass */,classOf[String] /* ValueClass */)// 生成broadCastStreamvar broadCastStream = pageStream.broadcast(broadcastStateDesc)inputStream.connect(broadCastStream).process(new BroadcastProcessFuntion[String,(String,String),String]() {// 处理非广播流,关联维度,配置数据override def processElement(value: String,ctx: BroadcastProcessFuntion[String,(String,String),String]#ReadOnlyCOntext,out: Collector[String]): Unit = {val state = ctx.getBroadcastState(broadcastStateDesc)val jsonObject = JSON.parseObject(value)val pageid = jsonObject.getString("pageid")if(null != pageid && state.contains(pageid)) {jsonObject.put("pageid",state.get("pageid"))}out.collect(jsonObject.toString)}})
Φ 方案6:维表变更日志关联
维表变更日志关联(Reference Data Change Stream),不同于上述两者将维表作为静态表关联的方式,维表变更日志关联将维表以changelog数据流的方式表示,从而将维表关联转变为两个数据流的join。这里的changelog 数据流类似于MySQL的binlog,通常需要维表数据库端以push的方式将日志写到Kafka等消息队列中。Changelog 数据流称为build数据流,另外待关联的主要数据流成为probe数据流。维表变更日志关联的好处在于可以获取某个key数据变化的时间,从而使得我们能在关联中使用Event Time(当然也可以使用Processing Time)。
方案6.1:Processing Time维表变更日志关联
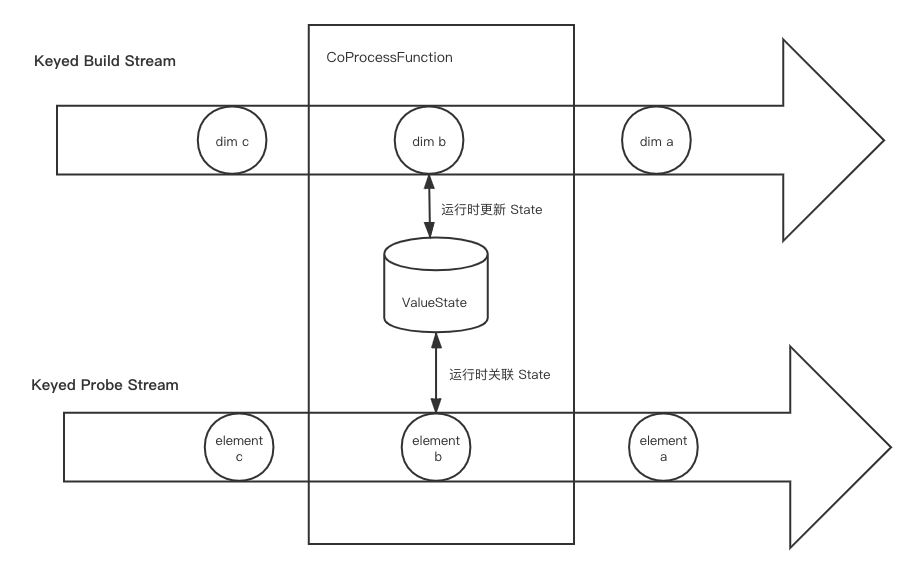
- 实现方式
如果基于Processing Time做关联,可以利用keyby将两个数据流中关联字段值相同的数据划分到KeyedCoProcessFunction的同一个分区,然后用ValueState或者MapState将维表数据保存下来。在普通数据流的一条记录进到函数时,到State中查找有无符合条件的join对象,若有则关联输出结果,若无则根据join的类型决定是直接丢弃还是与空值关联。这里要注意的是,State的大小要尽量控制好。首先是只保存每个key最新的维度数据值,其次是要给State设置好TTL,让Flink可以自动清理。
- 优点
基于Processing Time的维表变更日志关联优点是不需要直接请求数据库,不会对数据库造成压力;值得注意的是,我们可以利用Flink提供的RocksDB StateBackend,将大部分的维表数据存在磁盘而不是内存中,所以并不会占用很高的内存。不过基于Processing Time的这种关联对两个数据流的延迟要求比较高,否则如果其中一个数据流出现lag时,关联得到的结果可能并不是我们想要的,比如可能会关联到未来时间点的维表数据。
- 缺点
比较复杂,相当于使用changelog在Flink应用端重新构建一个维表,会占用一定的CPU和比较多的内存和磁盘资源。
- 适用场景
比较适用于不便直接访问数据的场景(比如维表数据库是业务线上数据库,出于安全和负载的原因不能直接访问),或者对维表的变更实时性要求比较高的场景(但因为数据准确性的关系,一般用下文的Event Time关联会更好)。
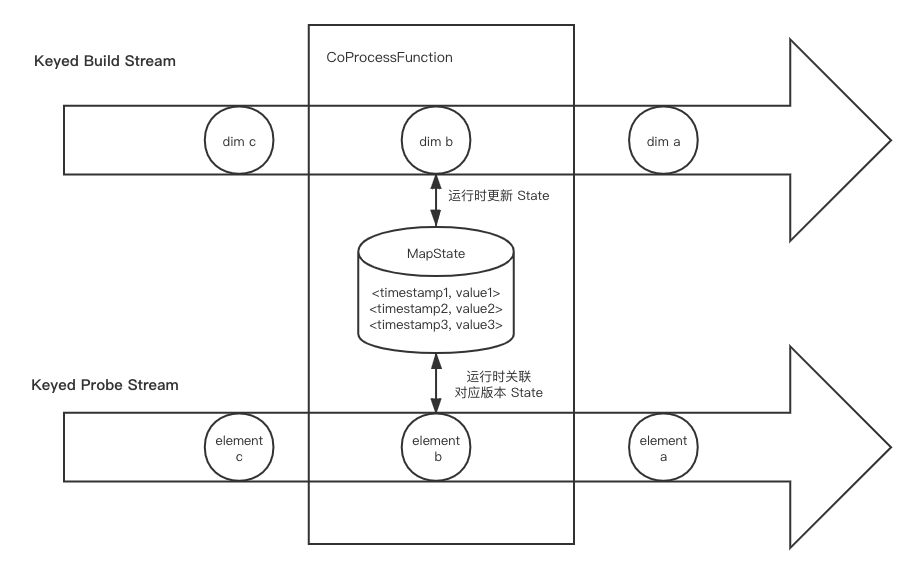
基于Event Time的维表关联实际上和基于Processing Time的十分相似,不同之处在于将维表changelog的多个时间版本都记录下来,然后每当一条记录进来,我们会找到对应时间版本的维表数据来和它关联,而不是总用最新版本,因此延迟数据的关联准确性大大提高。不过因为目前State并没有提供Event Time的 TTL,因此我们需要自己设计和实现State的清理策略,比如直接设置一个Event Time Timer(但要注意 Timer 不能太多导致性能问题),再比如对于单个key只保存最近的10个版本,当有更新版本的维表数据到达时,要清理掉最老版本的数据。
- 优点
基于Event Time的维表变更日志关联相对基于Processing Time的方式来说是一个改进,虽然多个维表版本导致空间资源要求更大,但确保准确性对于大多数场景来说都是十分重要的。相比Processing Time对两个数据的延迟都有要求,Event Time要求build数据流的延迟低,否则可能一条数据到达时关联不到对应维表数据或者关联了一个过时版本的维表数据,
- 缺点
使用复杂度较高。
- 适用场景
比较适合于维表变更比较多且对变更实时性要求较高的场景,同时也适合于不便直接访问数据库的场景。
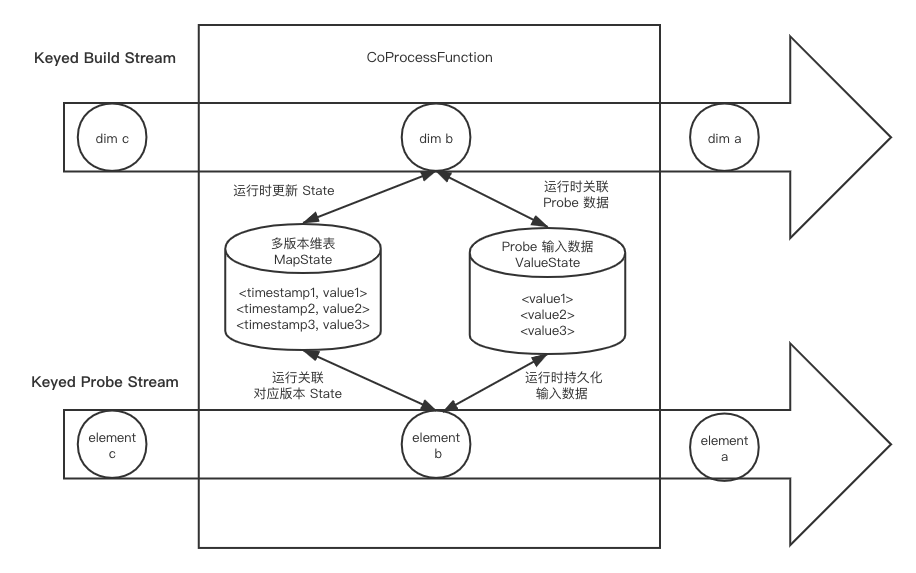
Temporal Table Join是Flink SQL/Table API的原生支持,它对两个数据流的输入都进行了缓存,因此比起上述的基于Event Time的维表变更日志关联,它可以容忍任意数据流的延迟,数据准确性更好。Temporal Table Join 在SQL/Table API使用时是十分简单的,但如果想在DataStream API中使用,则需要自己实现对应的逻辑。
总体思路是使用一个CoProcessFunction,将build数据流以时间版本为key保存在MapState中(与基于Event Time 的维表变更日志关联相同),再将probe数据流和输出结果也用State缓存起来(同样以Event Time为 key),一直等到Watermark提升到它们对应的Event Time,才把结果输出和将两个数据流的输入清理掉。这个Watermark触发很自然地是用Event Time Timer来实现,但要注意不要为每条数据都设置一遍Timer,因为一旦Watermark提升会触发很多个Timer导致性能急剧下降。比较好的实践是为每个key只注册一个Timer。实现上可以记录当前未处理的最早一个Event Time,并用来注册Timer。当前Watermark。每当Watermark触发Timer时,我们检查处理掉未处理的最早Event Time到当前Event Time的所有数据,并将未处理的最早Event Time更新为当前时间。
- 优点
Temporal Table Join的好处在于对于两边数据流的延迟的容忍度较大,但作为代价会引入一定的输出结果的延迟,这也是基于Watermark机制的计算的常见问题,或者说,妥协。另外因为吞吐量较大的probe数据流也需要缓存,Flink应用对空间资源的需求会大很多。最好,要注意的是如果维表变更太慢,导致Watermark提升太慢,会导致probe数据流被大量缓存,所以最好要确保build数据流尽量实时,同时给Source设置一个比较短的idle timeout(空闲时间)。
- 缺点
输出结果有一定的延迟。
- 适用场景
Temporal Table Join这种方式最为复杂,但数据准确性最好,适合一些对数据准确性要求高且可以容忍一定延迟(一般分钟级别)的关键业务。
- 代码示例
// TODO
实战案例
案例:基于Flink的实时超时统计场景
https://www.yuque.com/polaris-docs/bigdata/realtime_overtime_statistics参考
博文:Flink实战—双流join之原理解析
https://blog.csdn.net/aA518189/article/details/88823983
博文:Flink流流关联( Interval Join)总结
https://www.jianshu.com/p/11b482394c73
博文:一文看懂MySQL 两种join连接算法—NLJ和BNL
https://www.pythonf.cn/read/94214
博文:Nested Loop Join(MySQL join算法原理)
https://www.jianshu.com/p/741a6d4efc44
博文:SparkSQL – 有必要坐下来聊聊Join
http://hbasefly.com/2017/03/19/sparksql-basic-join
博文:MySQL8的Hash join算法
https://mysqlserverteam.com/hash-join-in-mysql-8
https://zhuanlan.zhihu.com/p/94065716
博文:Flink DataStream 关联维表实战
http://www.whitewood.me/categories/Flink/
实战:Flink SQL双流join demo
https://www.cnblogs.com/Springmoon-venn/p/12719320.html
视频:【Apache Flink Community China】如何join两个流(Ververica,Piotr Nowojski)
https://cloud.tencent.com/developer/article/1449541
https://www.bilibili.com/video/BV1S4411576L?from=search&seid=12045991999314303743
视频:【Apache Flink Community China】利用Flink实现实时超时统计场景
https://www.bilibili.com/video/av95428038
视频:【Apache Flink Community China】基于Flink的典型ETL场景实现
https://www.bilibili.com/video/av92215954

若有收获,就点个赞吧
0 人点赞
