Solr简介
■ 定义
Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。Solr可以独立运行,运行在 Jetty、Tomcat等这些 Servlet 容器中,Solr索引的实现方法很简单,用POST方法向Solr服务器发送一个描述Field及其内容的XML文档,Solr根据xml文档添加、删除、更新索引 。Solr搜索只需要发送HTTP GET请求,然后对Solr返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene。Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。Solr类似WebService,调用接口,实现增加,修改,删除,查询索引库。
■ 工作方式
文档通过Http利用XML 加到一个搜索集合中。查询该集合也是通过http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
■ 企业站内搜索技术选型
在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。
1. 单独使用Lucene实现
单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
2. 使用Google或Baidu接口
通过第三方搜索引擎提供的接口实现,这样和第三方引擎系统依赖紧密,不方便扩展,不建议采用。
3. 使用Solr实现
基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为Solr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
Solr特性
- 高级的全文搜索功能;
- 专为高通量的网络流量进行的优化;
- 基于开放接口(xml和http)的标准;
- 综合的html管理界面;
- 可伸缩性(能够有效地复制到另外一个Solr搜索服务器);
- 使用xml配置达到灵活性和适配性;
- 可扩展的插件体系;
Solr架构
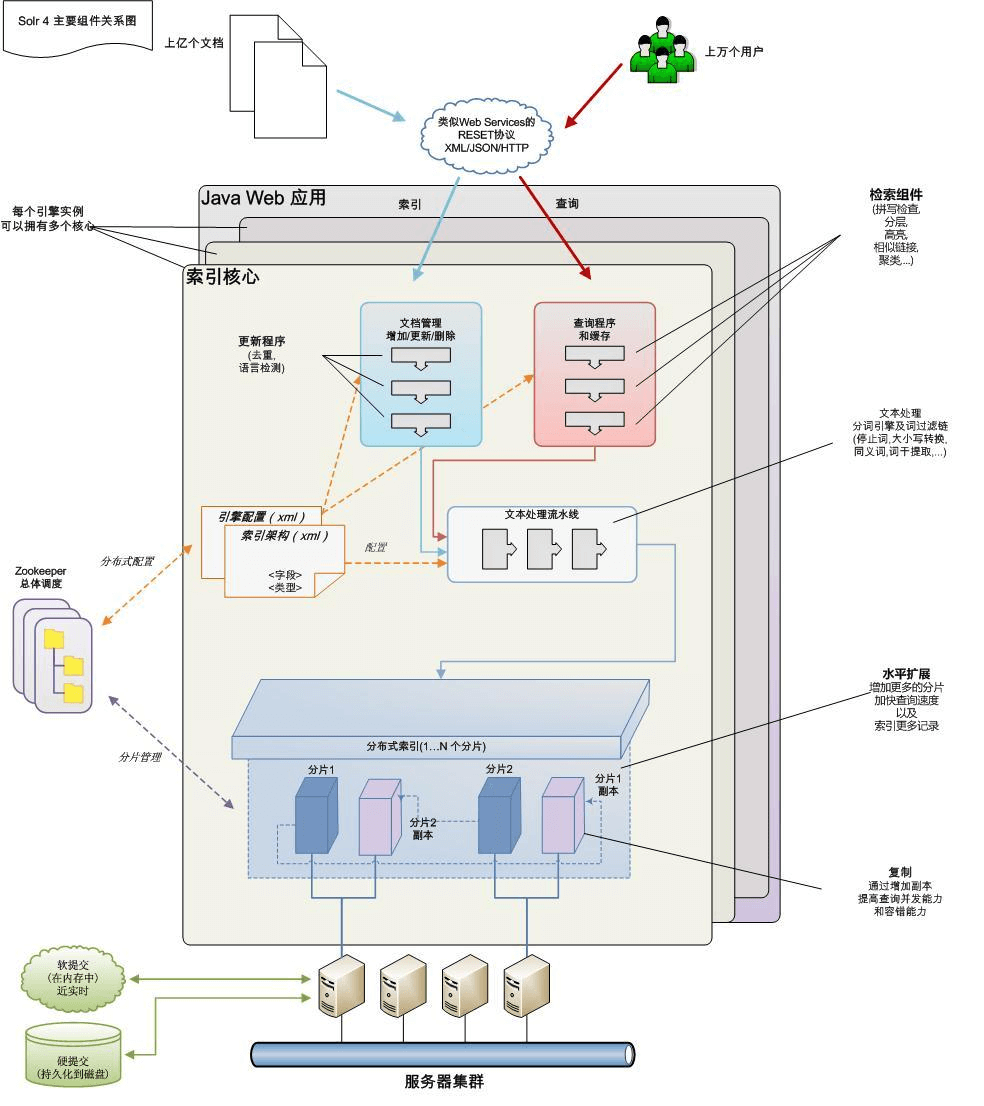
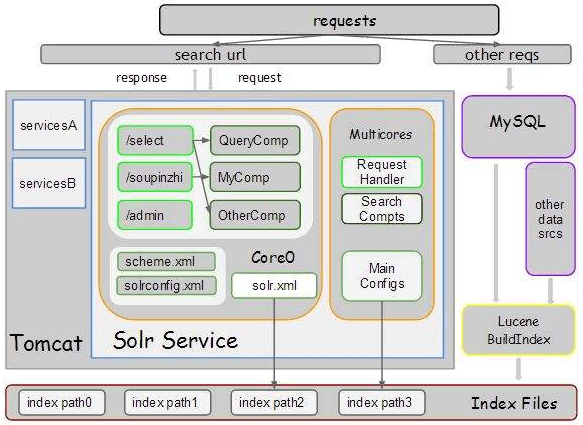
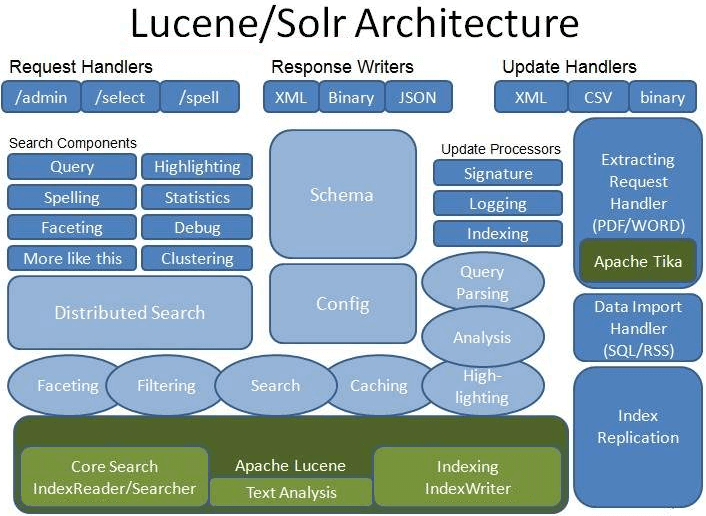
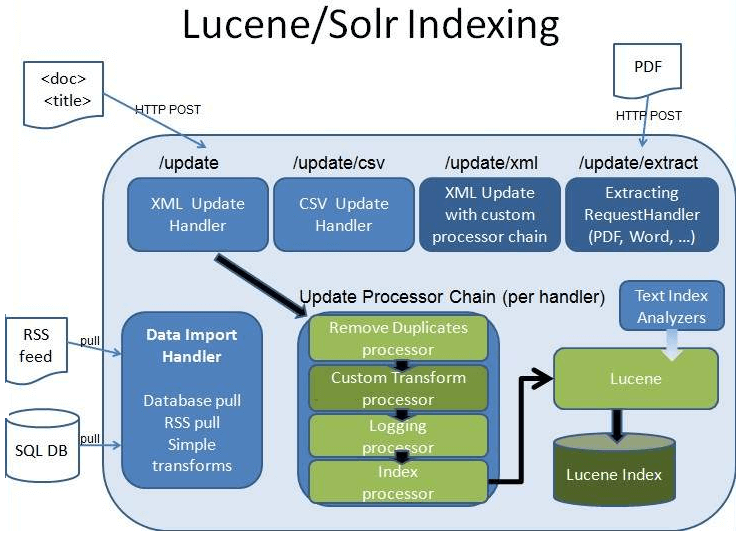
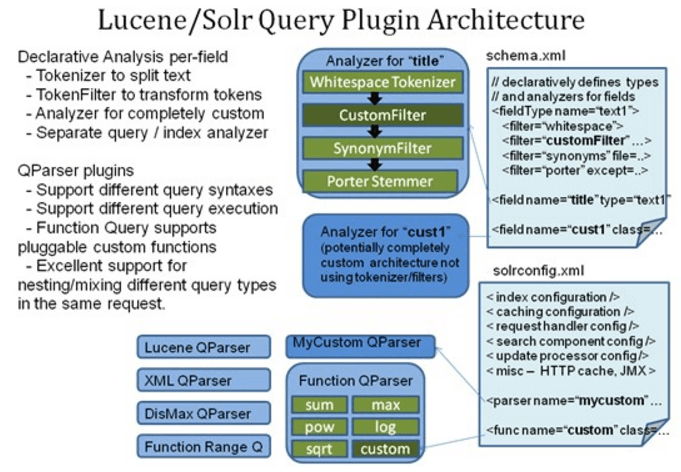
Solr的索引机制
1. 正排索引(正向索引)
正排索引是以文档的ID为关键字,索引文档中每个字的位置信息,查找时扫描索引中每个文档中字的信息直到找出所有包含查询关键字的文档。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。尽管正排索引的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。
正排索引从文档编号找词过程如下: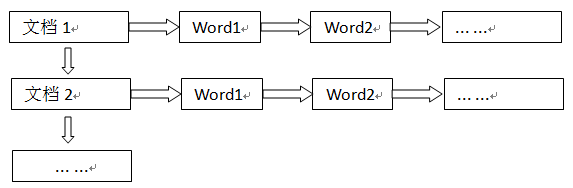
2. 倒排索引(反向索引)
对数据进行分析,抽取出数据中的词条,以词条作为key,对应数据的存储位置作为value,实现索引的存储。这种索引称为倒排索引。当Solr存储文档时,Solr会首先对文档数据进行分词,创建索引库和文档数据库。所谓的分词是指:将一段字符文本按照一定的规则分成若干个单词。
倒排索引从文档编号找词过程如下: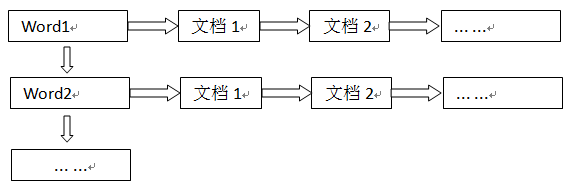
Solr与Lucene的区别
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。Elasticsearch和Solr对比

这两个搜索引擎都是流行的,先进的的开源搜索引擎。它们都是围绕核心底层搜索库 - Lucene构建的 - 但它们又是不同的。像所有东西一样,每个都有其优点和缺点,根据您的需求和期望,每个都可能更好或更差。Solr和Elasticsearch都在快速发展。
| 特征 | Solr/SolrCloud | Elasticsearch |
|---|---|---|
| 社区和开发者 | Apache 软件基金和社区支持 | 单一商业实体及其员工 |
| 节点发现 | Apache Zookeeper,在大量项目中成熟且经过实战测试 | Zen内置于Elasticsearch本身,需要专用的主节点才能进行分裂脑保护 |
| 碎片放置 | 本质上是静态,需要手动工作来迁移分片,从Solr 7开始 - Autoscaling API允许一些动态操作 | 动态,可以根据群集状态按需移动分片 |
| 高速缓存 | 全局,每个段更改无效 | 每段,更适合动态更改数据 |
| 分析引擎性能 | 非常适合精确计算的静态数据 | 结果的准确性取决于数据放置 |
| 全文搜索功能 | 基于Lucene的语言分析,多建议,拼写检查,丰富的高亮显示支持 | 基于Lucene的语言分析,单一建议API实现,高亮显示重新计算 |
| 查询速度 | 对已有数据检索较快,实时索引会阻塞导致查询速度变慢 | 实时索引时速度比solr快 |
| DevOps支持 | 尚未完全,但即将到来 | 非常好的API |
| 非平面数据处理 | 嵌套文档和父-子支持 | 嵌套和对象类型的自然支持允许几乎无限的嵌套和父-子支持 |
| 查询DSL | JSON(有限),XML(有限)或URL参数,Word等 | 仅Json,通过插件(Ingest-Attachment)支持Word等格式 |
| 索引/收集领导控制 | 领导者安置控制和领导者重新平衡甚至可以节点上的负载 | 不可能 |
| 机器学习 | 内置 - 在流聚合之上,专注于逻辑回归和学习排名贡献模块 | 商业功能,专注于异常和异常值以及时间序列数据 |
近几年的流行趋势
我们查看一下这两种产品的Google搜索趋势。谷歌趋势表明,与Solr相比,Elasticsearch具有很大的吸引力,但这并不意味着Apache Solr已经死亡。虽然有些人可能不这么认为,但Solr仍然是最受欢迎的搜索引擎之一,拥有强大的社区和开源支持。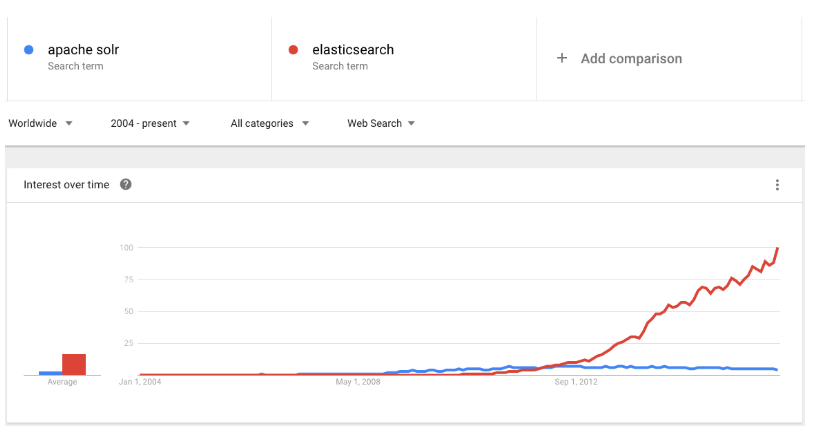
参考
官方:Solr指南(Tutorial)
https://lucene.apache.org/solr/resources.html#tutorials
官方:最新的pdf版本
https://www.apache.org/dyn/closer.cgi/lucene/solr/ref-guide/
官方:所有过去的pdf版本
http://archive.apache.org/dist/lucene/solr/ref-guide/
官方:在线API
https://lucene.apache.org/solr/guide
官方:已发布的Solr书籍
https://lucene.apache.org/solr/resources.html#solr-version-control
维基:Solr社区
https://cwiki.apache.org/confluence/display/solr

若有收获,就点个赞吧
0 人点赞
