1. 概述
1. 为什么需要工作流调度系统?
一个完整的数据分析系统通常都是由大量任务单元组成:shell脚本程序,java程序,mapreduce程序、hive脚本等。各任务单元之间存在时间先后及前后依赖关系。为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行。
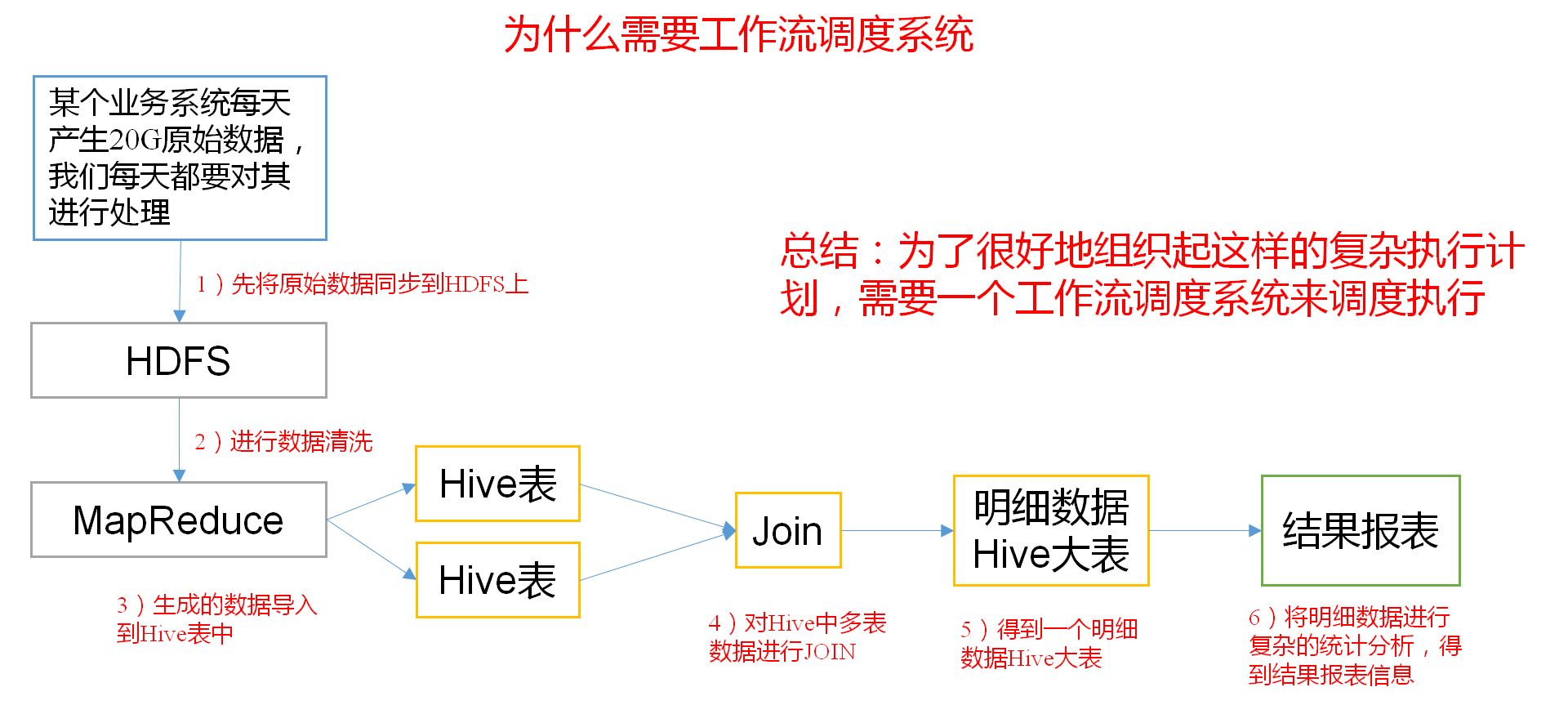
例如,我们可能有这样一个需求,某个业务系统每天产生20G原始数据,我们每天都要对其进行处理,处理步骤如下所示:
- 通过Hadoop先将原始数据上传到HDFS上(HDFS的操作);
- 使用MapReduce对原始数据进行清洗(MapReduce的操作);
- 将清洗后的数据导入到Hive表中(Hive的导入操作);
- 对Hive中多个表的数据进行JOIN处理,得到一张Hive的明细表(创建中间表);
- 通过对明细表的统计和分析,得到结果报表信息(Hive的查询操作);
2. Azkaban的适用场景
以上业务场景,传统方式下,整个的执行过程都需要人工参加,并且得盯着各任务的进度。但是我们的很多任务都是在深更半夜执行的,通过写脚本设置crontab执行。其实,整个过程类似于一个有向无环图(DAG)。每个子任务相当于大任务中的一个节点,也就是,我们需要的就是一个工作流的调度器,而Azkaban就是能解决上述问题的一个调度器。
3. 什么是Azkaban?
Azkaban是由Linkedin公司推出的批量工作流任务调度器,主要用于在一个工作流内以特定的顺序运行一组工作和流程,它的配置是通过简单的key:value对的方式,通过配置中的dependencies来设置依赖关系。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
2. Azkaban特点
- 兼容任何版本的Hadoop。
- 易于使用的Web用户界面。
- 简单的工作流的上传。
- 方便设置任务之间的关系。
- 调度工作流。
- 模块化和可插拔的插件机制。
- 认证/授权(权限的工作)。
- 能够杀死并重新启动工作流。
-
3. 常见工作流调度系统
简单的任务调度:直接使用crontab实现;
- 复杂的任务调度:开发调度平台或使用现成的开源调度系统,比如Azkaban、AirFlow、Oozie、Zeus、Rundeck、Conductor等;
- Ooize和Azkaban特性对比
下面的表格对上述四种Hadoop工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在显著的区别,在做技术选型的时候,可以提供参考。
| 特性 | Oozie | Azkaban |
|---|---|---|
| 工作流描述语言 | XML | text file with key/value pairs |
| 是否要web容器 | Yes | Yes |
| 进度跟踪 | web page | web page |
| Hadoop job调度支持 | yes | yes |
| 运行模式 | daemon | daemon |
| 事件通知 | no | Yes |
| 需要安装 | yes | yes |
| 支持的hadoop版本 | 0.20+ | currently unknown |
| 重试支持 | workflownode evel | yes |
| 运行任意命令 | yes | yes |
4. Azkaban的架构
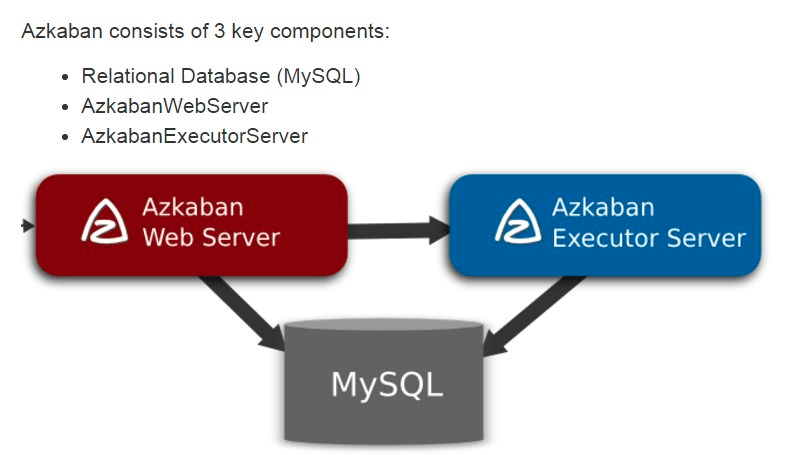
Azkaban由三个关键组件构成:
- AzkabanWebServer:AzkabanWebServer是整个Azkaban工作流系统的主要管理者,它用户登录认证、负责project管理、定时执行工作流、跟踪工作流执行进度等一系列任务。
- AzkabanExecutorServer:负责具体的工作流的提交、执行,它们通过mysql数据库来协调任务的执行。
- MySQL:存储大部分执行流状态,AzkabanWebServer和AzkabanExecutorServer都需要访问数据库。
5. Azkaban原生支持作业类型
| 作业类型 | Type参数 | 描述 | | —- | —- | —- | | command | type=command | Linux shell命令行任务 | | gobblin | type=java | 通用数据采集工具 | | hadoopJava | type=hadoopJava | 运行hadoopMR任务 | | java | type=javaprocess | 原生java任务 | | hive | type=hive | 支持执行hiveSQL | | pig | type=pig | pig脚本任务 | | spark | type=spark | Spark任务 | | hdfsToTeradata | type=? | 把数据从hdfs导入Teradata | | teradataToHdfs | type=? | 把数据从Teradata导入hdfs |
6. Azkaban安装部署
参考:《基于CentOS7安装Azkaban-3.47.0》《基于Ubuntu16.0.4安装Azkaban-3.47.0》。
7. Job配置简介
1. Command类型
type=commandcommand=echo "This is azkaban cmd ... "command.1=whoami# 依赖前一个jobdependencies=cmd1
2. Java类型
type=javaprocessclasspath=./lib/*,${azkaban.home}/lib/*java.class=com.dataeye.java.MyJavaJob
3. HadoopJava类型
type=hadoopJavajob.extend=falsejob.class=azkaban.jobtype.examples.java.WordCountclasspath=./lib/*,${azkaban.home}/lib/*force.output.overwrite=trueinput.path=/data/yann/inputoutput.path=/data/yann/output
4. Hive类型
type=hiveuser.to.proxy=azkabanclasspath=./lib/*,${azkaban.home}/lib/*azk.hive.action=execute.queryhive.script=res/hive.sql
5. Spark类型
type=sparkmaster=yarn-clusterexecution-jar=lib/spark-template-1.0-SNAPSHOT.jarclass=com.dataeye.template.spark.WordCountparams=hdfs://de-hdfs/data/yann/info.txt paramtest
8. Azkaban实战
1. 单一job案例
创建job描述文件。
vim first.job
内容如下:
# first.jobtype=commandcommand=echo 'this is my first job'
将job资源文件打包成zip文件。
zip first.zip first.job
注意:目前,**Azkaban上传的工作流文件只支持xxx.zip文件。zip应包含xxx.job运行作业所需的文件和任何文件(文件名后缀必须以.job**结尾,否则无法识别)。作业名称在项目中必须是唯一的。
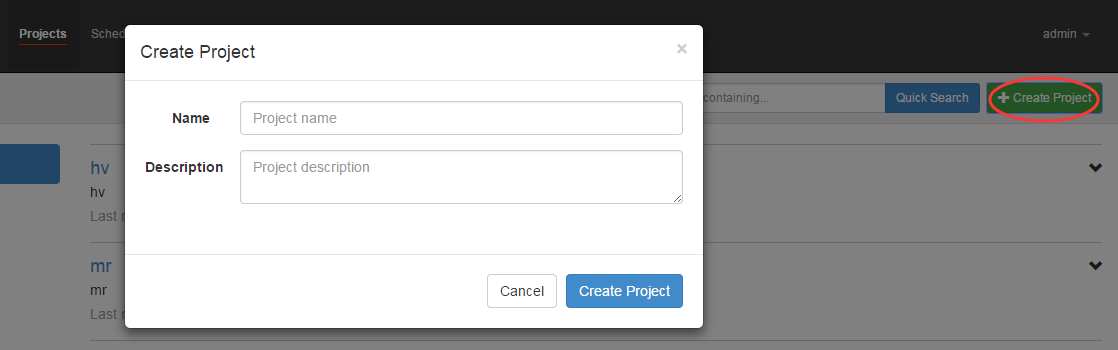
通过Azkaban的Web管理平台创建project并上传job的zip包。
- 首先创建project
- 上传zip包

- 启动执行该job。

点击执行工作流: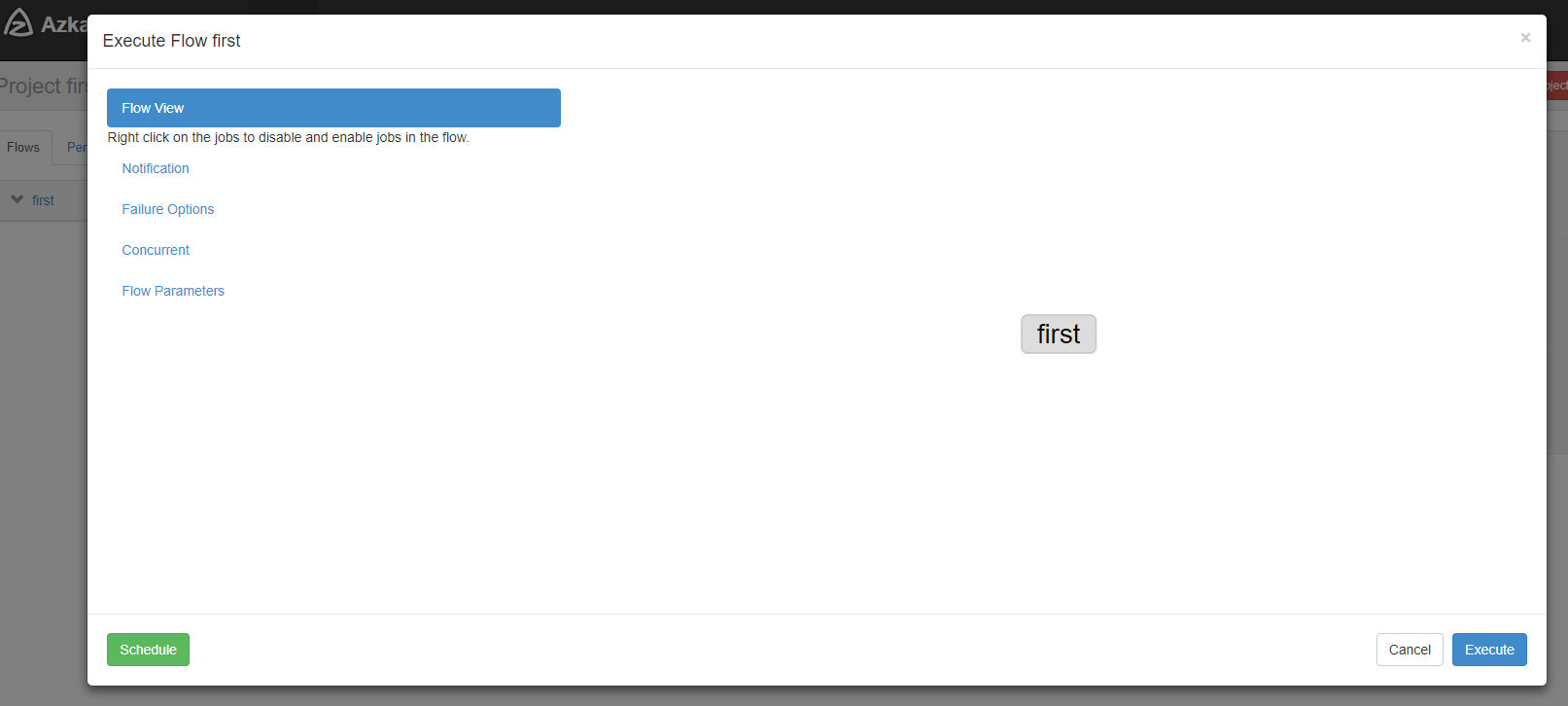
点击继续:
- Job执行成功。

- 点击查看job日志。

2. 多job工作流案例
- 创建有依赖关系的多个job描述。
第一个job(start.job)
vim start.job
内容如下:
# start.jobtype=commandcommand=touch /opt/module/kangkang.txt
第二个job(step1.job依赖start.job)
vim step1.job
内容如下:
# step1.jobtype=commanddependencies=startcommand=echo "this is step1 job"
第三个job(step2.job依赖start.job)
vim step2.job
内容如下:
# step2.jobtype=commanddependencies=startcommand=echo "this is step2 job"
第四个job(finish.job依赖step1.job和step2.job)
vim finish.job
内容如下:
# finish.jobtype=commanddependencies=step1,step2command=echo "this is finish job"
将所有job资源文件打到一个zip包中。
zip jobs.zip start.job step1.job step2.job finish.job
在Azkaban的Web管理界面创建工程并上传zip包。
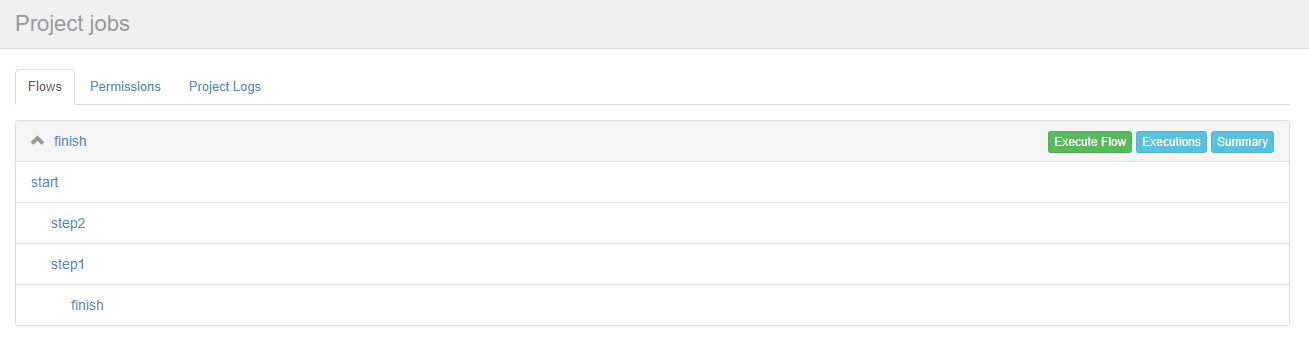
- 启动工作流flow。
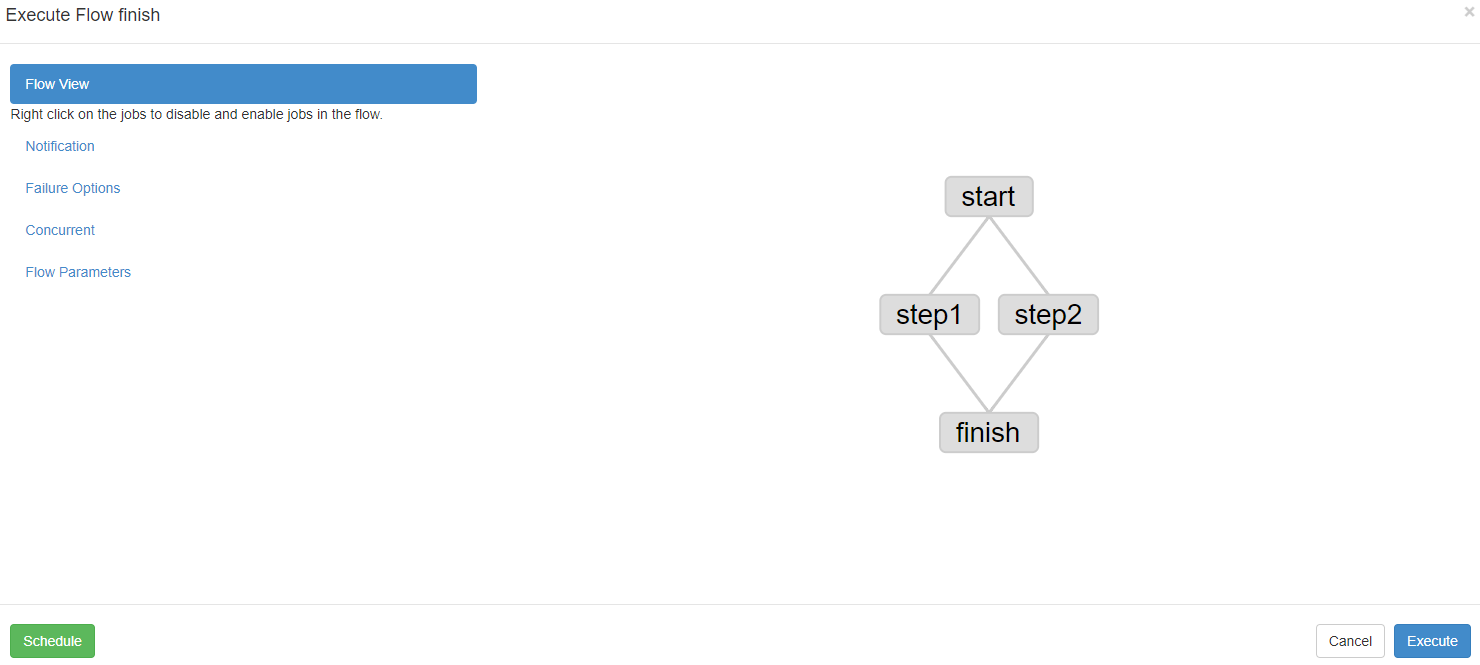 5. 查看结果。
5. 查看结果。
 3. java操作任务
3. java操作任务
- 编写java程序。 ```java import java.io.IOException;
public class AzkabanTest {
public void run() throws IOException { // 根据需求编写具体代码 FileOutputStream fos = new FileOutputStream(“/opt/module/azkaban/output.txt”); fos.write(“this is a java progress”.getBytes()); fos.close(); }
public static void main(String[] args) throws IOException { AzkabanTest azkabanTest = new AzkabanTest(); azkabanTest.run(); }
}
2. 将java程序打成jar包,创建lib目录,将jar放入lib内。```bashmkdir -p /opt/module/azkaban/lib
编写job文件。
vi azkabanJava.job
内容如下:
# azkabanJava.jobtype=javaprocessjava.class=com.atguigu.azkaban.AzkabanTestclasspath=/opt/module/azkaban/lib/*
将job文件打成zip包。
zip azkabanJava.zip azkabanJava.job
通过azkaban的web管理平台创建project并上传job压缩包,启动执行该job。
 4. HDFS操作任务
4. HDFS操作任务创建job描述文件。
vi fs.job
内容如下:
# hdfs jobtype=commandcommand=/opt/module/hadoop-2.7.2/bin/hadoop fs -mkdir /azkaban
将job资源文件打包成zip文件。
zip fs.zip fs.job
通过Azkaban的Web管理平台创建project并上传job压缩包。
- 启动执行该job。
- 查看结果。

5. MapReduce任务
创建job描述文件,及mr程序jar包。
vi mapreduce.job
内容如下:
# mapreduce jobtype=commandcommand=/opt/module/hadoop-2.7.2/bin/hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wordcount/input /wordcount/output
将所有job资源文件打到一个zip包中。
zip mapreduce.zip mapreduce.job
在Azkaban的Web管理界面创建工程并上传zip包。
- 启动job。
- 查看结果。

6. Hive脚本任务
- 创建job描述文件和Hive脚本。
Hive脚本(student.sql)
vi student.sql
内容如下:
use default;drop table student;create table student(id int, name string)row format delimited fields terminated by '\t';load data local inpath '/opt/module/datas/student.txt' into table student;insert overwrite local directory '/opt/module/datas/student'row format delimited fields terminated by '\t'select * from student;
Job描述文件(hive.job)
vi hive.job
内容如下:
# Hive jobtype=commandcommand=/opt/module/hive/bin/hive -f /opt/module/azkaban/jobs/student.sql
将所有job资源文件打到一个zip包中。
zip hive.zip hive.job
在Azkaban的Web管理界面创建工程并上传zip包。
- 启动job。
查看结果。
cat /opt/module/datas/student/000000_0
9. FAQ
上传的sh,Azkaban报错找不到。

因为sh文件的格式不对,不是unix格式。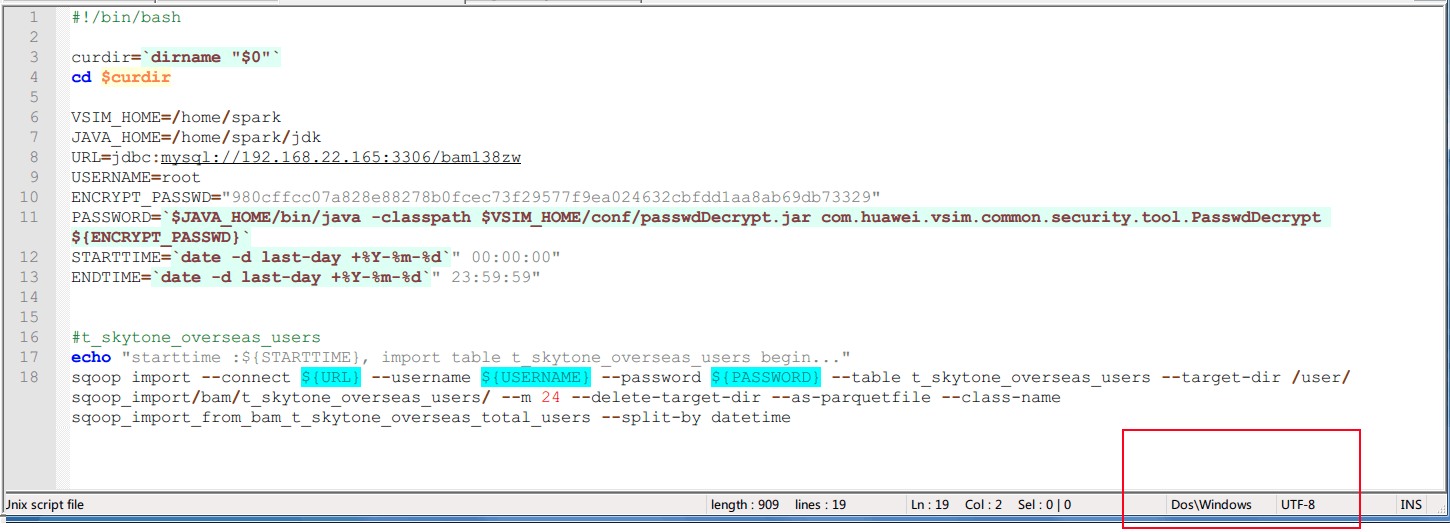 2. 调用任务报错。
2. 调用任务报错。
“java.lang.Exception: Cannot request memory (Xms 0 kb, Xmx 0 kb) from system for job hello
at azkaban.jobExecutor.ProcessJob.run(ProcessJob.java:63)
at azkaban.execapp.JobRunner.runJob(JobRunner.java:590)
at azkaban.execapp.JobRunner.run(JobRunner.java:443)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)”
解决方案:
参考:https://github.com/azkaban/azkaban/issues/481
If you don’t need 3GB free memory for some simple shell commands, you can also disable the memory check by setting memCheck.enabled=false in plugins/jobtypes/commonprivate.properties.
- 随机性的sqoop import job跑死。
解决方案:通过azkanban的配置参数,错误重跑retry解决。
retries=2retry.backoff=5000
- 多个sqoop export shell 脚本job任务并行在一台slave1上,引起CPU过高。
解决方案:通过ssh slave2 ‘sh *.sh’ 在其他slave上远程调度解决。
- 配置任务失败发邮件。
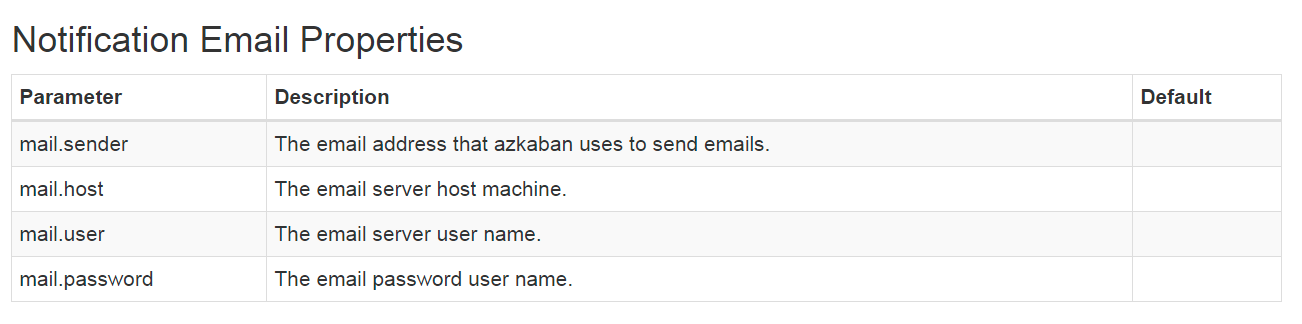
参考
简书:Azkaban各种类型的Job编写
https://www.jianshu.com/p/f2310a5c38c6

若有收获,就点个赞吧
0 人点赞
