简介
在Flink1.9中Hive集成发布为预览分支。Flink1.9版本允许用户使用SQL DDL持久化Flink-specific元数据 (e.g. Kafka tables) 到Hive元数据库,调用在Hive中定义的UDFs,和使用Flink读和写Hive表,Flink1.10通过进一步的发展完善了这项工作,将与生产就绪的Hive集成到Flink,并与大多数Hive版本完全兼容。
资源规划
| 组件 | bigdata-node1 | bigdata-node2 | bigdata-node3 |
|---|---|---|---|
| OS | centos7.6 | centos7.6 | centos7.6 |
| JDK | jvm | jvm | jvm |
| HDFS | NameNode/SecondaryNameNode/DataNode/JobHistoryServer/ApplicationHistoryServer | DataNode | DataNode |
| YARN | ResourceManager | NodeManager | NodeManager |
| Hive | HiveServer2/Metastore/CLI/Beeline | CLI/Beeline | CLI/Beeline |
| MySQL | N.A | N.A | MySQL Server |
| Maven | mvn | N.A | N.A |
| Flink | StandaloneSessionClusterEntrypoint | TaskManagerRunner | TaskManagerRunner |
安装介质
版本:flink-1.10.0-src.tgz
下载:https://archive.apache.org/dist/flink
环境准备
安装JDK
安装Hadoop
安装Hive
安装Maven
根据Flink官方推荐此处选择Maven-3.2.5,详情查阅:https://ci.apache.org/projects/flink/flink-docs-release-1.10/zh/flinkDev/building.html。Maven的安装请参考:《CentOS7.6-安装Maven-3.2.5》
编译Flink
(1).源码获取
cd /sharecurl -o flink-1.10.0-src.tgz https://archive.apache.org/dist/flink/flink-1.10.0/flink-1.10.0-src.tgz
(2).解压
cd /sharetar -zxvf flink-1.10.0-src.tgz -C ~/modules/cd ~/modulesmv flink-1.10.0 flink-1.10.0-srcvi ~/modules/flink-1.10.0-src/flink-runtime-web/pom.xml
修改flink-runtime-web的pom.xml配置,以提高NPM包下载速度,避免由于网络原因造成延时而编译失败。
(3).编译flink-shaded
直接编译flink不行吗,为啥还要编译shaded这个玩意?通过官网描述知道,直接编译hadoop版的flink仅支持hdp的2.4.1、2.6.5、 2.7.5、2.8.3,对于shaded版本也仅仅支持到10.0,如果你想用shaded11那么也需要自己单独编译。所以如果想使用hdp其他版本,以及hadoop相关的发行版(如cdh和hortonwork)也需要单独编译shaded。Flink1.10.0对应的flink-shaded版本为9.0,可以从https://github.com/apache/flink-shaded/releases获得。
cd /shareunzip flink-shaded-release-9.0.zip
修改flink-shaded-9.0/flink-shaded-hadoop-2-uber/pom.xml。
<dependency><groupId>commons-cli</groupId><artifactId>commons-cli</artifactId><version>1.3.1</version></dependency>
编译(编译时长大概5-10分钟):
cd /share/flink-shaded-release-9.0mvn clean install -DskipTests -Dhadoop.version=2.7.2
(4).编译flink
cd ~/modules/flink-1.10.0-srcmvn clean install -DskipTests -Dfast -Pinclude-hadoop -Dhadoop.version=2.7.2
Flink编译后直接生成在${FLINK_BUILD_HOME}/flink-dist/target目录(编译时长大概80分钟),此时可以打tar包以便于后续安装。
cd ~/modules/flink-1.10.0-src/flink-dist/target/flink-1.10.0-bintar -cvf flink-1.10.0-bin-hadoop-2.7.2.tar flink-1.10.0mv flink-1.10.0-bin-hadoop-2.7.2.tar /share/
编译成功后的jar包列表:
flink-dist_2.11-1.10.0.jarflink-shaded-hadoop-2-uber-2.7.2-9.0.jarflink-table_2.11-1.10.0.jarflink-table-blink_2.11-1.10.0.jarlog4j-1.2.17.jarslf4j-log4j12-1.7.15.jar
安装Flink
在节点bigdata-node1上安装Flink,之后再分发给其他节点。
(1).解压
tar -xvf /share/flink-1.10.0-bin-hadoop-2.7.2.tar -C ~/modules
(2).配置
rm -rf ~/modules/flink-1.10.0/conf/flink-conf.yamlvi ~/modules/flink-1.10.0/conf/flink-conf.yaml
flink-conf.yaml直接替换成以下配置 (注意key跟value之间的空格)。
jobmanager.rpc.address: bigdata-node1jobmanager.rpc.port: 6123jobmanager.heap.size: 1024mtaskmanager.heap.size: 1024mtaskmanager.numberOfTaskSlots: 10taskmanager.memory.preallocate: falseparallelism.default: 1jobmanager.web.port: 8381rest.port: 8381env.java.opts: -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -server -XX:+HeapDumpOnOutOfMemoryErrorenv.java.home: /home/vagrant/modules/jdk1.8.0_221classloader.resolve-order: parent-first
配置主节点:
vi ~/modules/flink-1.10.0/conf/masters
配置如下:
bigdata-node1:8381
配置从节点:
vi ~/modules/flink-1.10.0/conf/slaves
配置如下:
bigdata-node2bigdata-node3
(3).环境变量配置
vi ~/.bashrc
配置如下:
export FLINK_HOME=/home/vagrant/modules/flink-1.10.0export PATH=$FLINK_HOME/bin:$PATH
(4).分发
scp -r ~/modules/flink-1.10.0 vagrant@bigdata-node2:~/modules/scp -r ~/modules/flink-1.10.0 vagrant@bigdata-node3:~/modules/scp -r ~/.bashrc vagrant@bigdata-node2:~/scp -r ~/.bashrc vagrant@bigdata-node3:~/source ~/.bashrc # 各节点分别执行
启动Flink集群
# master节点上启动集群cd ~/modules/flink-1.10.0./bin/start-cluster.sh./bin/stop-cluster.sh# 查看job列表(--all:查看所有任务,包括已经取消和停止的)./bin/flink list --all# 停止job./bin/flink cancel ${JobID}
访问入口(谷歌浏览器) :http://bigdata-node1:8381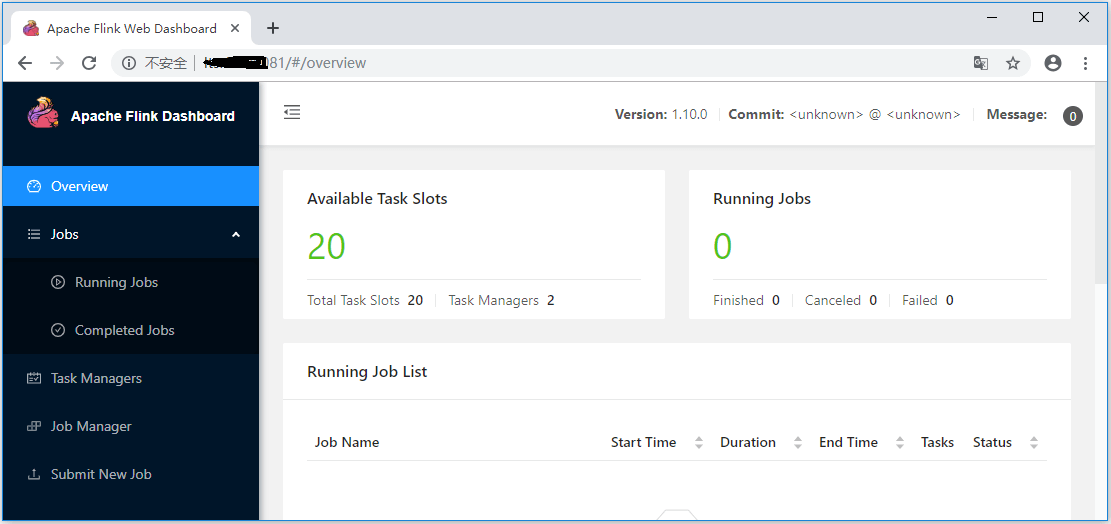
验证
(1).批量WordCoun示例
cd ~/modules/flink-1.10.0./bin/flink run examples/batch/WordCount.jar
(2).实时WordCoun示例
# bigdata-node2节点添加监听端口# sudo yum install -y ncnc -l 9000# 在bigdata-node1节点运行flink自带的”单词计数”示例cd ~/modules/flink-1.10.0./bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname bigdata-node2 --port 9000
在Running Jobs界面可以看到相应的任务生成。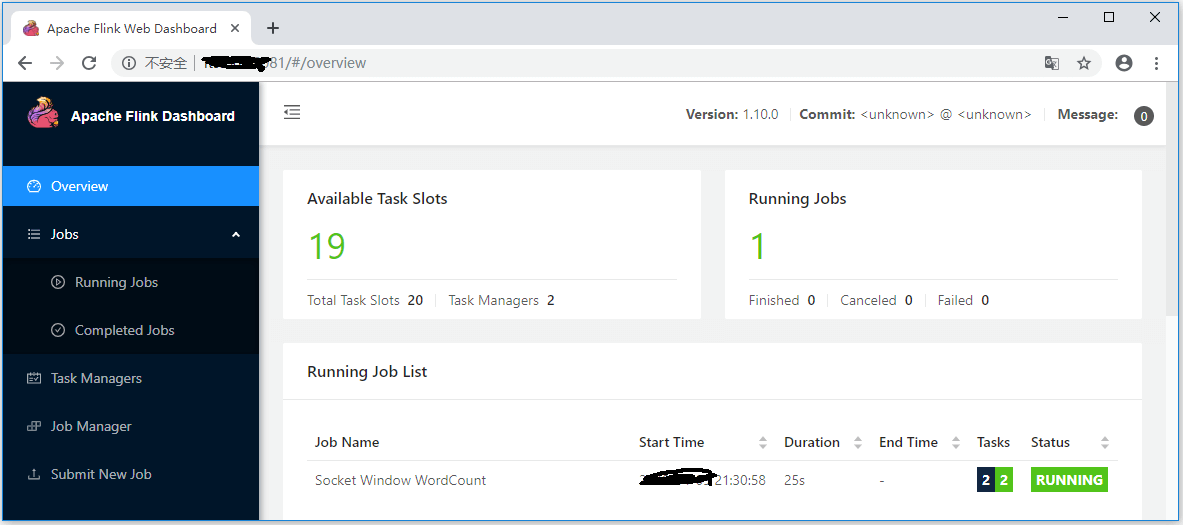
在监听端口输入一些单词后回车,回到task Managers页签下,从task的Stdout可以看到单词数量统计结果。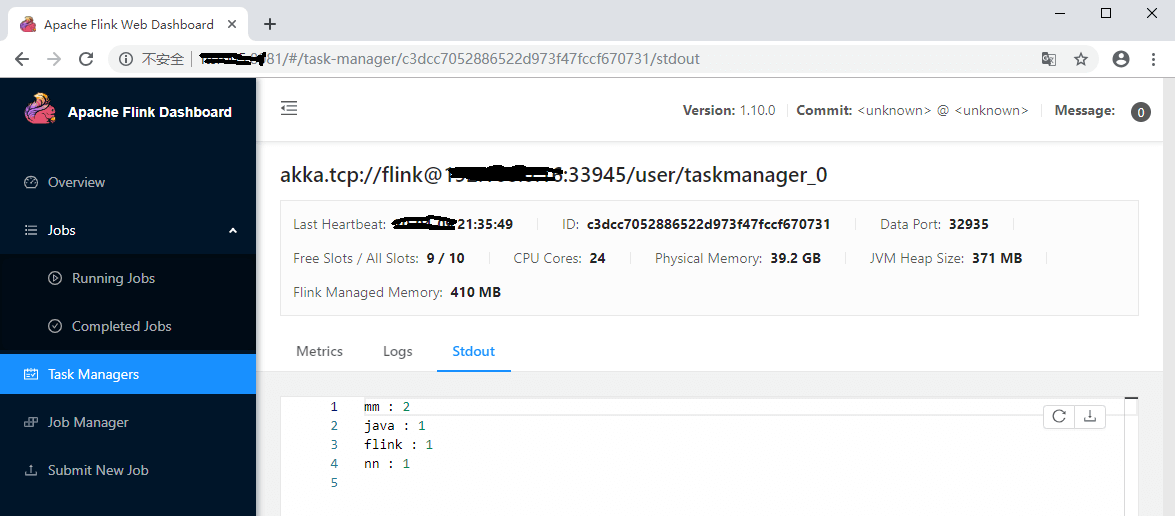
Flink集成Hive
添加依赖jar包
依赖jar包准备,将jar包直接复制到$FLINK_HOME/lib目录下:
| 依赖包 | 下载站点 |
|---|---|
| flink-connector-hive_2.11-1.10.0.jar | https://repo1.maven.org/maven2/org/apache/flink/flink-connector-hive_2.11/1.10.0/flink-connector-hive_2.11-1.10.0.jar |
| flink-json-1.10.0.jar | ${M2_HOME}/org/apache/flink/flink-json/1.10.0/flink-json-1.10.0.jar |
| flink-jdbc_2.11-1.10.0.jar | ${M2_HOME}/org/apache/flink/flink-json/1.10.0/flink-jdbc_2.11-1.10.0.jar |
另外,有部分jar包从${HIVE_HOME}/lib下获取:
export HIVE_HOME=/home/vagrant/modules/apache-hive-2.3.4-bincp ${HIVE_HOME}/lib/hive-exec-2.3.4.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/datanucleus-api-jdo-4.2.4.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/datanucleus-core-4.1.17.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/datanucleus-rdbms-4.1.19.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/mysql-connector-java-5.1.47.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/hive-common-2.3.4.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/hive-metastore-2.3.4.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/hive-shims-common-2.3.4.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/antlr-runtime-3.5.2.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/javax.jdo-3.2.0-m3.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/libfb303-0.9.3.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/commons-pool-1.5.4.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/commons-dbcp-1.4.jar ~/modules/flink-1.10.0/lib/cp ${HIVE_HOME}/lib/bonecp-0.8.0.RELEASE.jar ~/modules/flink-1.10.0/lib/
注意:分发jar包到所有集群节点上。
scp -r ~/modules/flink-1.10.0/lib vagrant@bigdata-node2:~/modules/flink-1.10.0/scp -r ~/modules/flink-1.10.0/lib vagrant@bigdata-node3:~/modules/flink-1.10.0/
Flink SQL Client
vi ~/modules/flink-1.10.0/conf/sql-client-hive.yaml
配置如下:
tables: []functions: []catalogs:- name: myhivetype: hivehive-conf-dir: /home/vagrant/modules/apache-hive-2.3.4-bin/confhive-version: 2.3.4default-database: flinkhivedbexecution:planner: blinktype: batchtime-characteristic: event-timeperiodic-watermarks-interval: 200result-mode: tablemax-table-result-rows: 1000000parallelism: 1max-parallelism: 128min-idle-state-retention: 0max-idle-state-retention: 0current-catalog: default_catalogcurrent-database: default_databaserestart-strategy:type: fallbackdeployment:response-timeout: 5000gateway-address: ""gateway-port: 0
分发配置文件,并重启Flink集群。
scp -r ~/modules/flink-1.10.0/conf/sql-client-hive.yaml vagrant@bigdata-node2:~/modules/flink-1.10.0/conf/scp -r ~/modules/flink-1.10.0/conf/sql-client-hive.yaml vagrant@bigdata-node3:~/modules/flink-1.10.0/conf/
启动Flink SQL Cli。
cd ~/modules/flink-1.10.0bin/sql-client.sh embedded -d conf/sql-client-hive.yaml
基本操作如下:
-- 命令行帮助Flink SQL> help-- 查看当前会话的catalog,其中myhive为自己配置的,default_catalog为默认的Flink SQL> show catalogs;default_catalogmyhive-- 使用catalogFlink SQL> use catalog myhive;-- 查看当前catalog的数据库Flink SQL> show databases;-- 创建数据库Flink SQL> create database testdb;-- 删除数据库Flink SQL> drop database testdb;-- 进入数据库Flink SQL> use testdb;-- 创建表Flink SQL> create table code_city(id int,city string,province string,event_time string);-- 查看当前catalog的库表Flink SQL> show tables;-- 查看库表描述Flink SQL> describe code_city;-- 删除表Flink SQL> drop table code_city;-- 查询表Flink SQL> select * from code_city;-- 插入数据(需要在hive端建表才能插入记录)Flink SQL> INSERT into code_city values(101,'南京1','江苏1','');Flink SQL> INSERT INTO code_city SELECT 102,'南京2','江苏2','';Flink SQL> insert overwrite code_city select id+1,city,province,event_time from code_city;
注意:Flink SQL Client仅能用于内嵌模式(embedded),无法远程操作。
Flink SQL Gateway
Flink SQL Gateway是一项服务,允许其他应用程序通过REST API轻松与Flink群集进行交互。应用程序(例如Java/Python/Shell程序,Postman)可以使用REST API提交查询,取消作业,检索结果等。Flink JDBC Driver使JDBC客户端可以基于REST API连接到Flink SQL Gateway。
获取源码及构建:
cd ~/modules/git clone https://github.com/ververica/flink-sql-gateway.gitcd ~/modules/flink-sql-gatewaymvn clean install -DskipTests -Dfastvi ~/modules/flink-sql-gateway/conf/sql-gateway-defaults.yaml
配置如下:
server:bind-address: 192.168.0.101address: 192.168.0.101port: 8083jvm_args: "-Xmx2018m -Xms1024m"catalogs:- name: myhivetype: hivehive-conf-dir: /home/vagrant/modules/apache-hive-2.3.4-bin/confhive-version: 2.3.4default-database: flinkhivedb
启动Flink SQL Gateway:
cd ~/modules/flink-sql-gateway/build-target/bin./sql-gateway.sh -d ~/modules/flink-sql-gateway/conf/sql-gateway-defaults.yaml -p 8083
Flink JDBC Driver
Flink JDBC Driver是一个Java库,用于通过连接到作为JDBC服务器的Flink SQL Gateway来访问和操作Apache Flink集群。
cd ~/modules/git clone https://github.com/ververica/flink-jdbc-driver.gitcd ~/modules/flink-jdbc-drivermvn clean install -DskipTests -Dfast
将编译后的jar包拷贝至${HIVE_HOME}/lib下:
cp -rf ~/modules/flink-jdbc-driver/target/flink-jdbc-driver-*.jar ~/modules/apache-hive-2.3.4-bin/lib
启动beeline:
# 提前开启metastore,hiveserver2cd ~/modules/apache-hive-2.3.4-bin# 方式1bin/beeline$beeline>> !connect jdbc:flink://192.168.0.101:8083?planner=blink# 方式2bin/beeline -u jdbc:flink://192.168.0.101:8083?planner=blink# 方式3bin/beeline -u jdbc:flink://192.168.0.101:8083?planner=blink -f run.sql
run.sql内容如下:
use catalog myhive;use flinkhivedb;INSERT into flinkhivedb.code_city values(109,'test flink jdbc driver','beijin-1','2020-12-31 12:12:12');
验证:
CREATE TABLE T(a INT,b VARCHAR(10)) WITH ('connector.type' = 'filesystem','connector.path' = 'file:///home/vagrant/datas/T.csv','format.type' = 'csv','format.derive-schema' = 'true');INSERT INTO T VALUES (1, 'Hi'), (2, 'Hello');SELECT * FROM T;
Flink集成Kafka
(1).添加依赖jar包
依赖jar包准备,将jar包直接复制到$FLINK_HOME/lib目录下:
| 依赖包 | 下载站点 |
|---|---|
| flink-sql-connector-kafka_2.11-1.10.0.jar | https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.11/1.10.0/flink-sql-connector-kafka_2.11-1.10.0.jar |
| kafka-clients-0.11.0.3.jar | https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/0.11.0.3/kafka-clients-0.11.0.3.jar |
| flink-json-1.10.0.jar | ${M2_HOME}/org/apache/flink/flink-json/1.10.0/flink-json-1.10.0.jar |
(2).创建topic
cd ~/modules/kafka_2.11-0.11.0.3/bin/kafka-topics.sh --zookeeper 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 --create --topic user_transactions --replication-factor 1 --partitions 3
(3).Flink SQL Client
vi ~/modules/flink-1.10.0/conf/sql-client-streaming.yaml
配置如下:
tables: []functions: []execution:planner: blinktype: streamingtime-characteristic: event-timeperiodic-watermarks-interval: 200result-mode: tablemax-table-result-rows: 1000000parallelism: 1max-parallelism: 128min-idle-state-retention: 0max-idle-state-retention: 0current-catalog: default_catalogcurrent-database: default_databaserestart-strategy:type: fallbackdeployment:response-timeout: 5000gateway-address: ""gateway-port: 0
进入Flink SQL Client终端:
cd ~/modules/flink-1.10.0bin/sql-client.sh embedded -d conf/sql-client-streaming.yaml
读取kafka数据:
use catalog default_catalog;DROP TABLE IF EXISTS user_transactions_source;CREATE TABLE user_transactions_source (cus_no STRING,card_no STRING,card_name STRING,card_type STRING,tranc_no STRING,txn_dte STRING,txn_tme STRING,record_tag STRING,trade_type STRING,dbt_cdt_cde STRING,amt DOUBLE,ts TIMESTAMP(3)) WITH ('connector.type' = 'kafka','connector.version' = 'universal','connector.topic' = 'user_transactions','connector.startup-mode' = 'earliest-offset','connector.properties.0.key' = 'zookeeper.connect','connector.properties.0.value' = '192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181','connector.properties.1.key' = 'bootstrap.servers','connector.properties.1.value' = '192.168.0.101:9092,192.168.0.102:9092,192.168.0.103:9092','update-mode' = 'append','format.type' = 'json');select * from user_transactions_source;
发送测试数据:
# kafka生产消息echo -e '{"cus_no": "011560773924", "card_no":"110009085001000000001", "card_name": "**0001", "card_type": "02", "tranc_no": "160908504921155120200401090850", "txn_dte": "20200401", "txn_tme": "090850", "record_tag": "1", "trade_type": "102", "dbt_cdt_cde": "0", "amt": "99.88", "ts": "2020-04-01T09:08:50Z"}' | ssh vagrant@bigdata-node1 "/home/vagrant/modules/kafka_2.11-0.11.0.3/bin/kafka-console-producer.sh --broker-list 192.168.0.101:9092,192.168.0.102:9092,192.168.0.103:9092 --topic user_transactions"# kafka消费消息cd ~/modules/kafka_2.11-0.11.0.3/bin/kafka-console-consumer.sh --zookeeper 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 --topic user_transactions --from-beginning
补充
数据准备
tee /home/vagrant/datas/flinkhivedb-stu.txt <<-'EOF'1|polaris2|lisi3|wangwu4|zhaoliuEOF
库表准备
-- 开启本地模式set hive.exec.mode.local.auto=true;CREATE DATABASE IF NOT EXISTS flinkhivedb;drop table if exists flinkhivedb.stu;create table if not exists flinkhivedb.stu(id int, name string)row format delimited fields terminated by '|';-- 注意:此处文件位于Hive服务器上load data local inpath '/home/vagrant/datas/flinkhivedb-stu.txt' into table flinkhivedb.stu;

若有收获,就点个赞吧
0 人点赞
