资源规划
| 组件 | bigdata-node1 | bigdata-node2 | bigdata-node3 |
|---|---|---|---|
| OS | centos7.6 | centos7.6 | centos7.6 |
| JDK | jvm | jvm | jvm |
| Zookeeper | QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
| MySQL | N.A | N.A | MySQL Server |
| Solr | solr-core/solrcloud | solr-core/solrcloud | solr-core/solrcloud |
安装介质
版本:solr-7.7.2.tgz
下载:https://archive.apache.org/dist/lucene/solr
官网:http://lucene.apache.org/solr
GitHub:https://github.com/apache/lucene-solr
说明
Solr5以前版本,solr的启动都以Tomcat作为容器,从Solr5+之后版本,内部集成Jetty服务器,可以通过bin目录中相关脚本直接启动。
环境准备
安装JDK
参考:《 CentOS7.6-安装JDK-1.8.221 》
安装ZooKeeper
参考:《[CentOS7.6-安装ZooKeeper-3.4.10](https://www.yuque.com/polaris-docs/test/centos-setup-zookeeper)》
安装MySQL
安装Solr
准备工作
# 查看防火墙状态firewall-cmd --state# 停止firewallsystemctl stop firewalld.service# 禁止firewall开机启动systemctl disable firewalld.service# 开放solr端口(未关闭防火墙状态下)firewall-cmd --zone=public --add-port=8983/tcp --permanentfirewall-cmd --reload# 查看端口开放情况iptables -L -n# 安装lsof(列出当前系统打开文件的工具)yum -y install lsof# 设置系统文件打开数vi /etc/sysctl.conffs.file-max = 6553560vi /etc/security/limits.conf* soft nproc 65535* hard nproc 65535* soft nofile 65535* hard nofile 65535
单机模式
解压缩
cd /sharewget https://archive.apache.org/dist/lucene/solr/7.7.2/solr-7.7.2.tgztar -xvf solr-7.7.2.tgz -C /usr/local/rm solr-7.7.2.tgz
启动
cd /usr/local/solr-7.7.2/bin./solr start -force./solr restart -force./solr status./solr stop -V
验证
lsof -i:8983netstat -tlnp
WebUI:http://bigdata-node1:8983/solr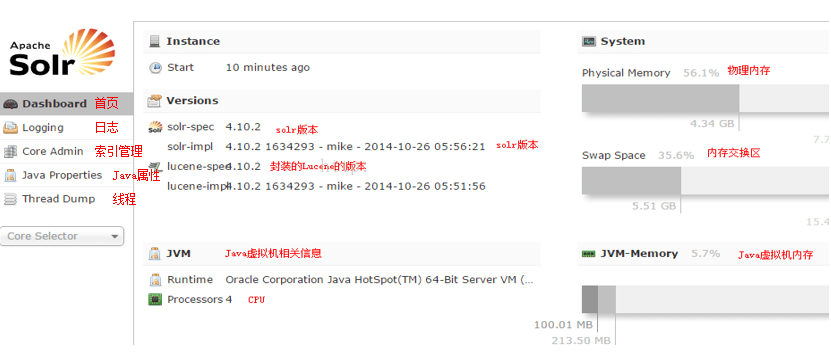
Solr Core操作
创建Solr Core
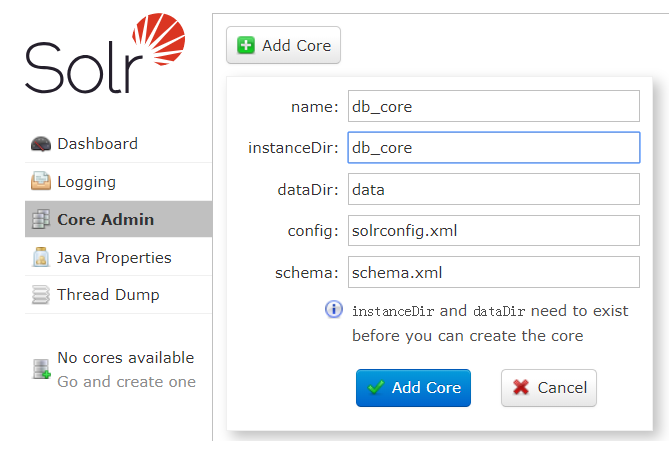
方式1(控制台)
cd /usr/local/solr-7.7.2/server/solrmkdir db_corecp -r configsets/_default/conf db_core/
“Core Admin”>“Add Core”,如图:
方式2(命令行-推荐)
cd /usr/local/solr-7.7.2/bin./solr create_core -c db2_core -forcels /usr/local/solr-7.7.2/server/solr
迁移
# 示例:将LTSR008上的core迁移至本机cd /usr/local/solr-7.7.2/server/solrscp -r root@LTSR008:/usr/local/solr-7.7.2/server/solr/test_core .
集群模式(SolrCloud)
解压缩
cd /sharewget https://archive.apache.org/dist/lucene/solr/7.7.2/solr-7.7.2.tgzmkdir -p /home/vagrant/datas/solrcloudtar -xvf solr-7.7.2.tgz -C /home/vagrant/datas/solrcloud
配置修改
vi /home/vagrant/datas/solrcloud/solr-7.7.2/bin/solr.in.sh
内容如下:
ZK_HOST="192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181"ZK_CLIENT_TIMEOUT="15000"# 以下为推荐配置(可选)# SOLR_HOST="bigdata-node1"SOLR_WAIT_FOR_ZK="300"# 时区+8小时,东八区(北京时间)SOLR_TIMEZONE="UTC+8"
分发
scp -r /home/vagrant/datas/solrcloud root@bigdata-node2:/home/vagrant/datas/scp -r /home/vagrant/datas/solrcloud root@bigdata-node3:/home/vagrant/datas/
启动
# 所有节点执行(需要先确保zookeeper已启动)cd /home/vagrant/datas/solrcloud/solr-7.7.2/bin./solr restart -cloud -force./solr start -cloud -force# 指定端口./solr start -cloud -p 8983 -force# 指定zk./solr start -cloud -z 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 -p 8983 -force./solr status./solr stop -V
WebUI:http://bigdata-node1:8983/solr、http://bigdata-node2:8983/solr、http://bigdata-node3:8983/solr
config操作
准备配置文件
cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/solrmkdir db_cloudcp -r configsets/_default/conf db_cloud/
上传配置到zk
cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/scripts/cloud-scripts./zkcli.sh -zkhost 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 -cmd upconfig -confdir /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_cloud/conf -confname db_cloud
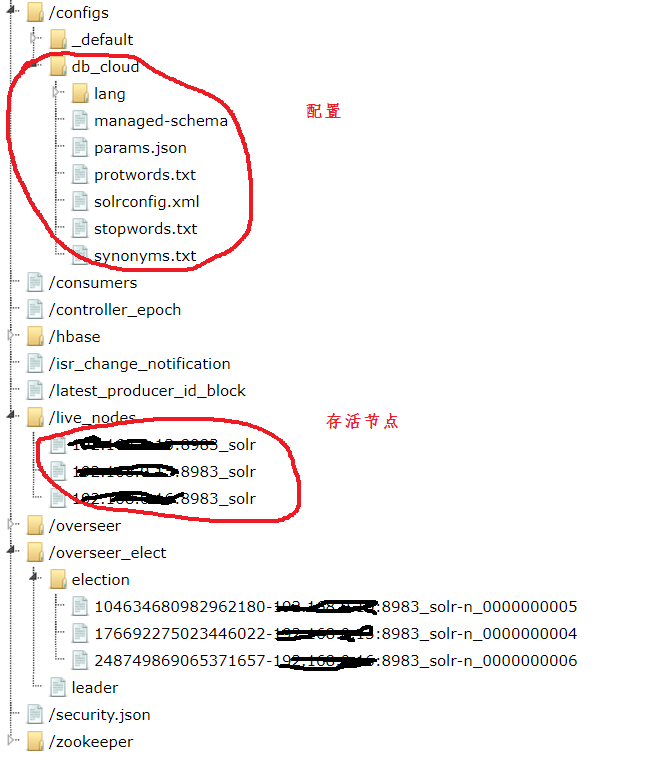
删除zk信息
cd /home/vagrant/modules/zookeeper-3.4.10/binbash zkCli.shls /configsrmr /configs/db_cloud
collection操作
创建collection
方式1(http)
http://bigdata-node1:8983/solr/admin/collections?action=CREATE&name=db_cloud&numShards=3&replicationFactor=2&maxShardsPerNode=3&collection.configName=db_cloud

方式2(命令行)
# 命令行方式(会同时生成configs和collections子节点,而http方式不会生成configs子节点)cd /home/vagrant/datas/solrcloud/solr-7.7.2/bin./solr create_collection -c test2 -shards 3 -replicationFactor 2 -n test2 -force
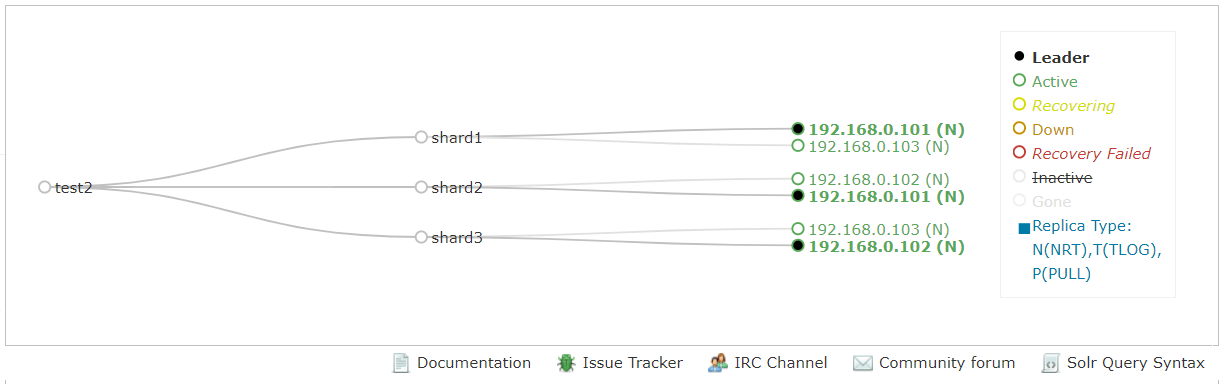
方式3(控制台)

重新加载collection
http://bigdata-node1:8983/solr/admin/collections?action=RELOAD&name=test2
删除collection
http://bigdata-node1:8983/solr/admin/collections?action=DELETE&name=test2
存储配置HDFS
前提条件
请确认Hadoop使用的是2.x以上版本,且hdfs-site.xml配置了如下内容:
# bigdata-node1:vagrantexport HADOOP_HOME=/home/vagrant/modules/hadoop-2.7.2vi ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
配置如下:
<property><name>dfs.webhdfs.enabled</name><value>true</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property>
分发:
# vagrant用户cd ~/modules/hadoop-2.7.2/etc/hadoop/scp -r hdfs-site.xml vagrant@bigdata-node2:~/modules/hadoop-2.7.2/etc/hadoop/scp -r hdfs-site.xml vagrant@bigdata-node3:~/modules/hadoop-2.7.2/etc/hadoop/# 重启HDFS集群
Solr支持将其索引和事务日志文件写入和读取到HDFS分布式文件系统,只需要通过简单地配置几个参数即可实现,Solr为我们提供了3种方式来实现。
1. 启动Solr时设定
单机模式
对于独立的Solr实例,应在启动Solr之前修改一些参数。可以在solrconfig.xml中设置它们,或者bin/solr在启动时将其传递给脚本。
cd /home/vagrant/datas/solrcloud/solr-7.7.2bin/solr start -Dsolr.directoryFactory=HdfsDirectoryFactory \-Dsolr.lock.type=hdfs \-Dsolr.data.dir=hdfs://bigdata-node1:9000/solr \-Dsolr.updatelog=hdfs://bigdata-node1:9000/solr \-force
- 集群模式
在SolrCloud模式下,最好保留数据并更新日志目录,这是Solr随附的默认值,而只需指定即可solr.hdfs.home。所有动态创建的集合都会在solr.hdfs.home根目录下自动创建适当的目录。
cd /home/vagrant/datas/solrcloud/solr-7.7.2bin/solr start -c -Dsolr.directoryFactory=HdfsDirectoryFactory \-Dsolr.lock.type=hdfs \-Dsolr.hdfs.home=hdfs://bigdata-node1:9000/solr \-force
2. solr.in.sh文件中设定
solr.in.sh文件里面可以设定Solr的很多环境变量,所以我们也可以在这里面设定索引存放路径的相关配置:
vi /home/vagrant/datas/solrcloud/solr-7.7.2/bin/solr.in.sh
内容如下:
SOLR_OPTS="$SOLR_OPTS -Dsolr.directoryFactory=HdfsDirectoryFactory -Dsolr.lock.type=hdfs -Dsolr.hdfs.home=hdfs://bigdata-node1:9000/solr"
分发:
scp -r /home/vagrant/datas/solrcloud/solr-7.7.2/bin/solr.in.sh root@bigdata-node2:/home/vagrant/datas/solrcloud/solr-7.7.2/bin/scp -r /home/vagrant/datas/solrcloud/solr-7.7.2/bin/solr.in.sh root@bigdata-node3:/home/vagrant/datas/solrcloud/solr-7.7.2/bin/
3. solrconfig.xml文件中设定
如果solr索引数据存放在hadoop hdfs中的话,创建的collection的solrconfig.xml文件要做3处改动:
# 若配置文件是放在zk上的,则需要先从zk下载配置,修改完成后覆盖cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/scripts/cloud-scripts./zkcli.sh -zkhost 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 -cmd getfile /configs/db_cloud/solrconfig.xml solrconfig.xmlvi solrconfig.xml
修改第1处:
<dataDir>${solr.data.dir:hdfs://bigdata-node1:9000/solr/db_cloud}</dataDir>
修改第2处:
<directoryFactory name="DirectoryFactory" class="solr.HdfsDirectoryFactory"><str name="solr.hdfs.home">hdfs://bigdata-node1:9000/solr</str><str name="solr.hdfs.confdir">/home/vagrant/modules/hadoop-2.7.2/etc/hadoop</str><str name="solr.lock.type">hdfs</str></directoryFactory>
修改第3处:
<lockType>${solr.lock.type:hdfs}</lockType>
solrconfig.xml中这三处默认值是:
<dataDir>${solr.data.dir:}</dataDir><directoryFactory name="DirectoryFactory"class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}"/><lockType>${solr.lock.type:native}</lockType>
上传配置到ZooKeeper
cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/scripts/cloud-scripts./zkcli.sh -zkhost 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 -cmd putfile /configs/db_cloud/solrconfig.xml solrconfig.xml
测试
http://bigdata-node1:8983/solr/admin/collections?action=CREATE&name=t111&numShards=3&replicationFactor=2&maxShardsPerNode=3&collection.configName=db_cloudhttp://bigdata-node1:8983/solr/admin/collections?action=RELOAD&name=db_cloud
数据库同步数据
1. 创建collection
# 准备配置文件cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/solrmkdir db_synccp -r configsets/_default/conf db_sync/# 上传配置cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/scripts/cloud-scripts./zkcli.sh -zkhost 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 -cmd upconfig -confdir /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf -confname db_sync# 创建collectionhttp://bigdata-node1:8983/solr/admin/collections?action=CREATE&name=db_sync&numShards=1&replicationFactor=1&maxShardsPerNode=1&collection.configName=db_sync
2. 创建data-config.xml
cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf# 创建一个文件data-config.xml,与solrconfig.xml同级touch data-config.xml
3. 修改solrconfig.xml
vi /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/solrconfig.xml
在“
”上方增加以下这段配置: <requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"><lst name="defaults"><str name="config">data-config.xml</str></lst></requestHandler>
如果配置了HDFS存储需要配置如下内容:
<!-- 修改 --><dataDir>${solr.data.dir:hdfs://bigdata-node1:9000/solr/db_sync}</dataDir><!-- 修改 --><directoryFactory name="DirectoryFactory" class="solr.HdfsDirectoryFactory"><str name="solr.hdfs.home">hdfs://bigdata-node1:9000/solr</str><str name="solr.hdfs.confdir">/home/vagrant/modules/hadoop-2.7.2/etc/hadoop</str><str name="solr.lock.type">hdfs</str></directoryFactory><!-- 修改 --><lockType>${solr.lock.type:hdfs}</lockType>
4. 配置data-config.xml
vi /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/data-config.xml
配置如下:
<?xml version="1.0" encoding="UTF-8"?><dataConfig><dataSource name="source1" type="JdbcDataSource"driver="com.mysql.jdbc.Driver"url="jdbc:mysql://192.168.0.103:3306/eagle"user="root"password="123456"batchSize="-1" /><document><entity name="user" dataSource="source1"query="SELECT id,rtxno,username,password,email,realname FROM ke_users"><field column='id' name='myid' /><field column='rtxno' name='rtxno' /><field column='username' name='username' /><field column='password' name='password' /><field column='email' name='email' /><field column='realname' name='realname' /></entity></document></dataConfig>
配置说明:
dataSource:url是你要访问的数据库路径(host请使用IP)。user是用户名,password是你的数据库密码。
- query:是一个sql语句,表示需要导入哪张表的哪些字段。然后<field>标签中的column属性是SQL语句中查询的字段,跟数据库中对应;name属性是你给它起的一个别名,应该是必须指定的。有多个查询字段就需要有多个<field>标签,每一个<field>标签对应一个字段。
- document:配置数据库查询语句与managed_schema域的对应关系。目的是在core导入数据的时候,通过该配置信息链接到数据库,通过查询语句把数据查询出来,通过数据库字段与managed_schema域关联关系创建索引。
5. 修改managed-schema
添加内容如下: ```xmlvi /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/managed-schema
**参数说明**:- **name**:是这个域的名称,在整个managed_schema文件里面需要唯一,不能重复,这里定义成跟数据库表字段的名称,方便使用。当然,也可以定义成其他名字。- **type**:是表示这个字段的类型是什么,string是字符串类型,int是整形数据类型,date是时间类型,相当于数据库里面的timestamp。(_**solr-8.x和 solr-7.x,****凡是基本数据类型都要加p**** ,如:pint、plong**_)- **indexed**:表示是否索引,索引的话就能查询到,否则,搜索的时候,不会出现。- **stored**:表示是否存储到索引库里面。- **required**:是否必须。- **multiValued**:是否多值,比如商品信息中,一个商品有多张图片,一个Field想存储多个值的话,必须将multiValued设置为true。<a name="KS9et"></a>### 6. 导入依赖jar包需要依赖以下jar包(下载地址:[http://mvnrepository.com/](http://mvnrepository.com/)):```bashcd /sharewget https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.47/mysql-connector-java-5.1.47.jarwget https://repo1.maven.org/maven2/org/apache/solr/solr-dataimporthandler/7.7.2/solr-dataimporthandler-7.7.2.jarwget https://repo1.maven.org/maven2/org/apache/solr/solr-dataimporthandler-extras/7.7.2/solr-dataimporthandler-extras-7.7.2.jarcp mysql-connector-java-5.1.47.jar /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib/cp solr-dataimporthandler-7.7.2.jar /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib/cp solr-dataimporthandler-extras-7.7.2.jar /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib/
分发:
cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/libscp -r mysql-connector-java-5.1.47.jar root@bigdata-node2:/home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib/scp -r mysql-connector-java-5.1.47.jar root@bigdata-node3:/home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib/scp -r solr-dataimporthandler-7.7.2.jar root@bigdata-node2:/home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib/scp -r solr-dataimporthandler-7.7.2.jar root@bigdata-node3:/home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib/scp -r solr-dataimporthandler-extras-7.7.2.jar root@bigdata-node2:/home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib/scp -r solr-dataimporthandler-extras-7.7.2.jar root@bigdata-node3:/home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib/
然后配置solrconfig.xml,引用上面的jar包。
vi /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/solrconfig.xml
配置如下:
<lib dir="${solr.install.dir:../../../..}/dist/" regex="mysql-connector-java-.*\.jar" /><lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" />
7. 上传配置至zk
cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/scripts/cloud-scripts./zkcli.sh -zkhost 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 -cmd upconfig -confdir /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf -confname db_sync
重启Solr集群:
cd /home/vagrant/datas/solrcloud/solr-7.7.2/bin./solr restart -cloud -force
8. 数据准备
# bigdata-node3mysql -uroot -p123456
脚本如下:
create database IF not EXISTS eagle;DROP TABLE IF EXISTS `ke_users`;CREATE TABLE `ke_users` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`rtxno` int(11) NOT NULL,`username` varchar(64) NOT NULL,`password` varchar(128) NOT NULL,`email` varchar(64) NOT NULL,`realname` varchar(128) NOT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4;INSERT INTO `ke_users` VALUES ('1', '1001', 'admin1', '123456', 'admin1@email.com', 'Administrator1');INSERT INTO `ke_users` VALUES ('2', '1002', 'admin2', '123456', 'admin2@email.com', 'Administrator2');INSERT INTO `ke_users` VALUES ('3', '1003', 'admin3', '123456', 'admin3@email.com', 'Administrator3');INSERT INTO `ke_users` VALUES ('4', '1004', 'admin4', '123456', 'admin4@email.com', 'Administrator4');INSERT INTO `ke_users` VALUES ('5', '1005', 'admin5', '123456', 'admin5@email.com', 'Administrator5');INSERT INTO `ke_users` VALUES ('6', '1006', 'admin6', '123456', 'admin6@email.com', 'Administrator6');INSERT INTO `ke_users` VALUES ('7', '1007', 'admin7', '123456', 'admin7@email.com', 'Administrator7');INSERT INTO `ke_users` VALUES ('8', '1008', 'admin8', '123456', 'admin8@email.com', 'Administrator8');INSERT INTO `ke_users` VALUES ('9', '1009', 'admin9', '123456', 'admin9@email.com', 'Administrator9');
9. 导入数据
进入Solr控制台,选择部署好的“db_sync”逻辑库,点击“Dataimport”,再选择“full-import”(全部导入),点击“Execute”,出现下面的页面,证明这张表的数据已经导入进来了。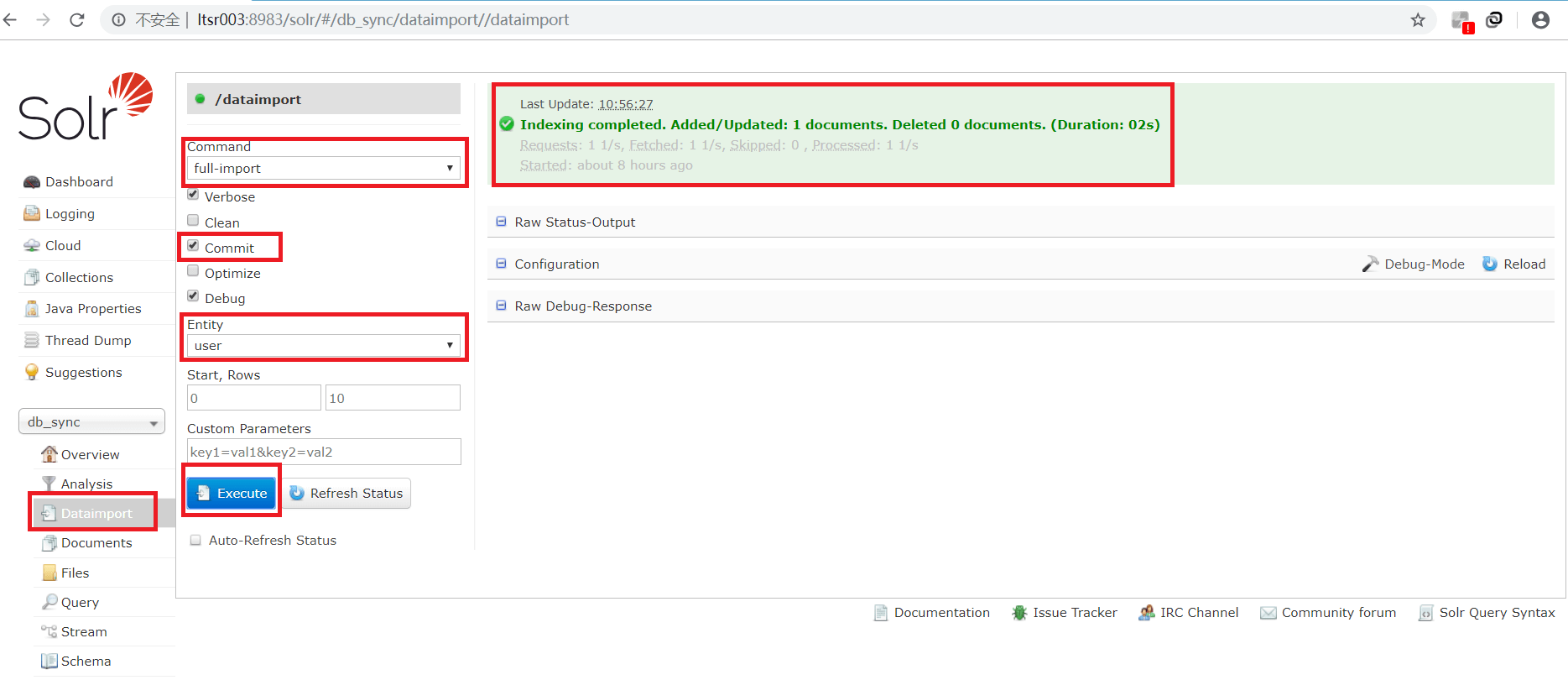
中文分词
首先,Solr有自己基本的类型,string、int/pint、date、long/plong等等。对于string类型,比如在你的core/conf/manage-schema文件中,配置一个字段类型为string类型,如果查询符合“我是中国人”的数据,它就认为“我是中国人”是一个词语。但是如果你将该字段设置成了分词,即配置成了text_ik类型,就可能匹配“我”、“中国人”、“中国”、“中”、“人”带有这些字的该字段数据都可能被查询到。这就是分词带来的结果。具体要按照各自的业务来配置是否分词,分词对于大文本字段设置是合理的,但是对于小字段,设置分词是没必要的,甚至有相反的结果。比如你的某一个叫姓名的字段设置了分词,还不如设置string,查询时模糊匹配效果最好,(模糊匹配就是查询条件两边加上),当然也要看自己业务需求是什么。
*中文分词在solr里面是没有默认开启的,需要自己配置一个中文分词器。
目前可用的分词器有smartcn、IK、Jeasy、jieba、ictclas4j、庖丁。其实主要是两种,一种是基于中科院ICTCLAS的隐式马尔科夫HMM算法的中文分词器,如smartcn、ictclas4j,优点是分词准确度高,缺点是不能使用用户自定义词库;另一种是基于最大匹配的分词器,如IK、Jeasy、庖丁,优点是可以自定义词库,增加新词,缺点是分出来的垃圾词较多。各有优缺点。主流还是ik,可以扩展自己的词库,非常方便,加入一些热搜词,主题词,对于搜索而言,非常方便。
IK Analyzer简介
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了 4 个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始,IK发展为面向 Java的公用分词组件,独立于Lucene项目,同时提供了对 Lucene的默认优化实现。在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。
IK Analyzer下载
wget https://search.maven.org/remotecontent?filepath=com/github/magese/ik-analyzer-solr7/7.x/ik-analyzer-solr7-7.x.jarwget https://repo1.maven.org/maven2/com/github/magese/ik-analyzer-solr7/7.x/ik-analyzer-solr7-7.x.jarwget http://files.cnblogs.com/files/zhangweizhong/ikanalyzer-solr5.zip# 百度网盘地址# https://pan.baidu.com/s/1smOxPhF (6.5)# 链接: https://pan.baidu.com/s/1eYF99KcqaT81weTUGFFFiQ 提取码: ezt8 (2012)https://code.google.com/archive/p/ik-analyzer/downloads# 7.x、8.xhttps://search.maven.org/search?q=com.github.magesehttps://github.com/magese/ik-analyzer-solr/releases
下载文件说明:
| 文件名 | 描述 |
|---|---|
| ext.dic | 自定义词 ,如:“沙雕”,在汉语里面不是一个词 ,它只是一个网络用语,可以配置让它成为一个词 |
| stopword.dic | 停止字典,如:“啊”、“吧”、“唉 ”等不作分词 |
| IKAnalyzer.cfg.xml | 配置ik的配置文件,不用改 |
| *.jar | ik分词依赖jar包,如:ik-analyzer-solr5-5.x.jar、solr-analyzer-ik-5.1.0.jar |
| ik.conf | 动态加载扩展词字典表关键配置。 1. files为动态词典列表,可以设置多个词典表,用逗号进行分隔,默认动态词典表为dynamicdic.txt; 1. lastupdate默认值为0,每次对动态词典表修改后请+1,不然不会将词典表中新的词语添加到内存中。 |
| dynamicdic.txt | 动态加载扩展词字典表关键配置。 在此文件配置的词语不需重启服务即可加载进内存中。 以#开头的词语视为注释,将不会加载到内存中。 |
IKAnalyzer.cfg.xml配置文件说明:
| 名称 | 类型 | 描述 | 默认 |
|---|---|---|---|
| use_main_dict | boolean | 是否使用默认主词典 | true |
| ext_dict | String | 扩展词典文件名称,多个用分号隔开 | ext.dic; |
| ext_stopwords | String | 停用词典文件名称,多个用分号隔开 | stopword.dic; |
IK Analyzer配置
Maven仓库地址
<!-- https://mvnrepository.com/artifact/com.github.magese/ik-analyzer --><dependency><groupId>com.github.magese</groupId><artifactId>ik-analyzer</artifactId><version>7.7.1</version></dependency>
单机版Solr
参考:https://github.com/magese/ik-analyzer-solr/blob/v7.7.1/README.md
- 将jar包(如:ik-analyzer-solr-7.x.jar)放入Solr服务的Jetty或Tomcat的webapp/WEB-INF/lib/目录下;
将resources目录下的5个配置文件放入solr服务的Jetty或Tomcat的webapp/WEB-INF/classes/目录下;
① IKAnalyzer.cfg.xml② ext.dic③ stopword.dic④ ik.conf⑤ dynamicdic.txt
配置Solr的managed-schema,添加ik分词器,示例如下;
<!-- ik分词器 --><fieldType name="text_ik" class="solr.TextField"><analyzer type="index"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer></fieldType>
ik.conf文件说明;
files=dynamicdic.txtlastupdate=0
Tips:
- files为动态词典列表,可以设置多个词典表,用逗号进行分隔,默认动态词典表为dynamicdic.txt;
- lastupdate默认值为0,每次对动态词典表修改后请+1,不然不会将词典表中新的词语添加到内存中。
- dynamicdic.txt为动态词典;
在此文件配置的词语不需重启服务即可加载进内存中。 以#开头的词语视为注释,将不会加载到内存中。 - 自定义分词字段;
需要用ik分词的field type属性改成text_ik即可,例如:
<field name="userName" type="text_ik" indexed="true" stored="true"/>
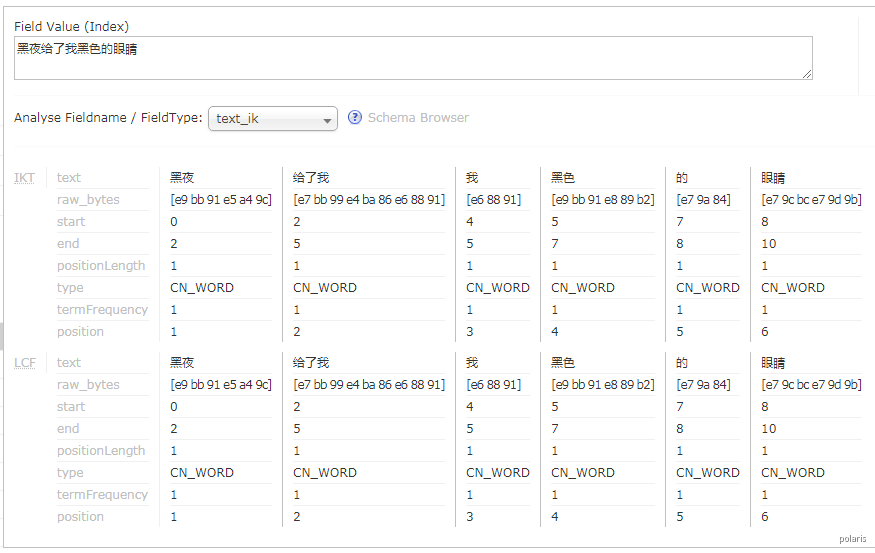
- 启动Solr服务测试分词;
- 扩展词
使用Ik的扩展配置在Solr目录下创建IKAnalyzer.cfg.xml,配置如下:
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">ext.dic;my-ext.dic;</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">stopword.dic;my-stopword.dic;</entry></properties>
Tips:
my-ext.dic即为扩展分词库,分词库可以为多个,以分号隔开即可,停止词库一样。新增“my-ext.dic”和“my-stopword.dic”文件。文件格式必需是:无BOM的UTF-8格式。
集群版SolrCloud
参考:https://github.com/magese/ik-analyzer-solr/blob/v7.7.1/README-CLOUD.md
因为Solr-Cloud中的配置文件是交由zookeeper进行管理的, 所以为了方便更新动态词典, 所以也要将动态词典文件上传至zookeeper中,目录与solr的配置文件目录一致。
注意:因为zookeeper中的配置文件大小不能超过1m,当词典列表过多时,需将词典文件切分成多个。
将jar包(如:ik-analyzer-solr-7.x.jar)放入每台服务器的Solr服务的Jetty或Tomcat的webapp/WEB-INF/lib/目录下;
cp /share/ik-analyzer-solr-7.x.jar /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib/
将resources目录下的IKAnalyzer.cfg.xml、ext.dic、stopword.dic放入solr服务的Jetty或Tomcat的webapp/WEB-INF/classes/目录下;
① IKAnalyzer.cfg.xml (IK默认的配置文件,用于配置自带的扩展词典及停用词典)② ext.dic (默认的扩展词典)③ stopword.dic (默认的停词词典)
mkdir -p /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/classescp /share/IKAnalyzer.cfg.xml /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/classes/cp /share/ext.dic /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/classes/cp /share/stopword.dic /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/classes/
注意:与单机版不同,ik.conf及dynamicdic.txt请不要放在classes目录下!
将resources目录下的ik.conf及dynamicdic.txt放入solr配置文件夹中,与solr的managed-schema文件同目录中;
① ik.conf (动态词典配置文件)files (动态词典列表,可以设置多个词典表,用逗号进行分隔,默认动态词典表为dynamicdic.txt)lastupdate (默认值为0,每次对动态词典表修改后请修改该值,必须大于上次的值,不然不会将词典表中新的词语添加到内存中。)② dynamicdic.txt (默认的动态词典,在此文件配置的词语不需重启服务即可加载进内存中。以#开头的词语视为注释,将不会加载到内存中。)
cp /share/ik.conf /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/cp /share/dynamicdic.txt /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/
配置Solr的managed-schema,添加ik分词器,示例如下;
vi /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/managed-schema
配置如下:
<!-- ik分词器 --><fieldType name="text_ik" class="solr.TextField"><analyzer type="index"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer></fieldType>
将配置文件上传至zookeeper中,首次使用请重启服务或reload Collection;
cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/scripts/cloud-scripts./zkcli.sh -zkhost 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 -cmd upconfig -confdir /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf -confname db_sync
-
扩展词动态加载(热更新)
通过IK添加动态加载词典表功能,在不需要重启solr服务的情况下加载新增的词典。
| 分词工具 | 词库中词的数量 | 最后更新时间 |
|---|---|---|
| ik | 27.5万 | 2012年 |
| mmseg | 15.7万 | 2017年 |
| word | 64.2万 | 2014年 |
| jieba | 58.4万 | 2012年 |
| jcesg | 16.6万 | 2018年 |
| sougou词库 | 115.2万 | 2019年 |
单机版Solr
参考:https://www.freesion.com/article/1488136294
修改dynamicdic.txt,添加扩展词;
vi /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/classes/dynamicdic.txt
修改ik.conf,更新版本(lastupdate+1,确保比之前的数组大即可);
vi /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr-webapp/webapp/WEB-INF/classes/ik.conf
-
集群版SolrCloud
参考:https://github.com/magese/ik-analyzer-solr/blob/v7.7.1/README-CLOUD.md
修改dynamicdic.txt,添加扩展词,并将配置上传至zk;
# 示例cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/scripts/cloud-scripts./zkcli.sh -zkhost 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 -cmd getfile /configs/db_sync/dynamicdic.txt /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/dynamicdic.txtvi /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/dynamicdic.txt./zkcli.sh -zkhost 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 -cmd putfile /configs/db_sync/dynamicdic.txt /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/dynamicdic.txt
修改ik.conf,更新版本(lastupdate+1,确保比之前的数组大即可),并将配置上传至zk;
# 示例cd /home/vagrant/datas/solrcloud/solr-7.7.2/server/scripts/cloud-scripts./zkcli.sh -zkhost 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 -cmd getfile /configs/db_sync/ik.conf /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/ik.confvi /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/ik.conf./zkcli.sh -zkhost 192.168.0.101:2181,192.168.0.102:2181,192.168.0.103:2181 -cmd putfile /configs/db_sync/ik.conf /home/vagrant/datas/solrcloud/solr-7.7.2/server/solr/db_sync/conf/ik.conf
-
参考
CSDN:Centos7上搭建solrcloud(solr7.3.1+内置jetty+zookeeper3.4.12)
https://blog.csdn.net/wudinaniya/article/details/81180336
CSDN:Centos7上安装solr7.3.1(用jetty部署-单机模式)
https://blog.csdn.net/wudinaniya/article/details/81163931
简书:CentOS7.3搭建solr7.2
https://www.jianshu.com/p/43885d4de846
OSCHINA:Centos7安装Solr7.2.1
https://my.oschina.net/liangguoqiang/blog/1622396
博客园:CentOS7搭建solr7.2
https://www.cnblogs.com/nshgo/p/8670835.html
CSDN:基于Centos7安装Solr7.4,并导入数据教程
https://blog.csdn.net/u013160017/article/details/81037279

若有收获,就点个赞吧
0 人点赞
