嵌入式处理器的一个守恒定律,也即 功耗-价格-性能 不可兼得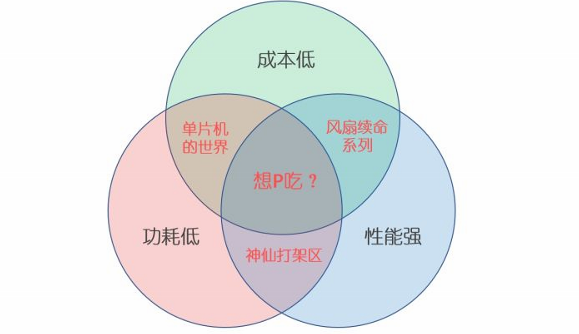
由于物理定律限制我们可以认为:在其他条件一定的情况下,性能和功耗肯定成正比,更强的性能意味着更大的功耗也就会产生更多的热量;而要想提升性能的同时还能保证功耗不变甚至更低的话,就只能改进芯片的架构或者改进制程工艺,这又会带来成本的提高。因而根据不同应用方向,我们可以选择兼顾其中两者的一些硬件平台:
- 成本低,性能弱,功耗也低:代表是各种单片机如STM32/AVR等。
- 成本低,性能强,但制程不高易发热:代表是各种低端SoC比如全志的H系列。
- 性能强,制程先进,但价格十分不友好,有钱还不一定给卖系列:代表是现在智能手机上使用的各种旗舰SoC,比如高通骁龙/海思麒麟/苹果A系。
K210参数
在AI计算方面,K210的算力其实是相当可观的。根据嘉楠官方的描述,K210的KPU算力有0.8TFLOPS ,作为对比,拥有128个CUDA单元GPU的英伟达Jetson Nano的算力是0.47TFLOPS ;而最新的树莓派4只有不到0.1TFLOPS 。
当然了,这个性能跟某些旗舰级别的SoC还是有差距的:A76级别的CPU本身就已经很变态,更何况旗舰SoC上面都会搭载用于AI加速的硬件用于异构运算,比如高通的Hexagon DSP、苹果的Neural Engine、华为的达芬奇架构NPU等等,这些NPU在某些应用下甚至能达到与数百W功耗的桌面级GPU接近的算力(顺便提一下GTX1080Ti的双精度浮点算力是11.3 TFLOPS ),可以说是丧心病狂了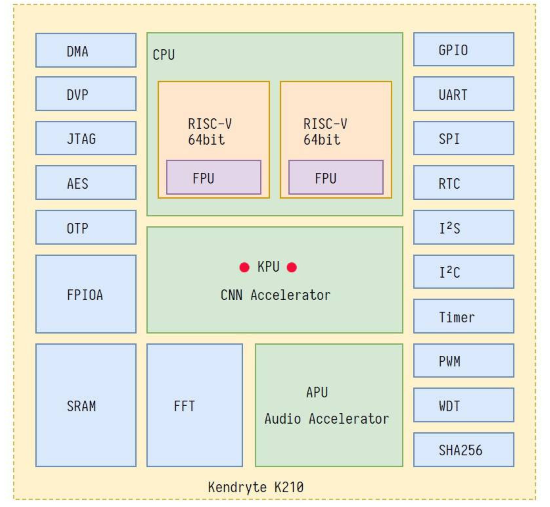
KPU
KPU,Knowledge Processing Unit是通用的神经网络处理器,它可以在低功耗的情况下实现卷积神经网络计算,时时获取被检测目标的大小、坐标和种类,对人脸或者物体进行检测和分类。
那么KPU是如何处理AI算法的呢?
首先,目前(2019Q1)所谓的AI算法, 主要是基于 神经网络 算法衍生的各种结构的神经网络模型,如VGG,ResNet,Inception, Xception, SeqeezeNet,MobileNet, etc.
那为什么不使用普通CPU/MCU进行神经网络算法的计算呢?
因为对多数应用场景来说,神经网络的运算量太大:
例如640×480像素的RGB图片分析,假设第一层网络每颜色通道有16个3×3卷积核,那么仅第一层就要进行640×480×3×16=15M次卷积运算,而一次3×3矩阵的计算时间,就是9次乘加的时间,加载两个操作数到寄存器,各需要3周期,乘法一个周期,加法一个周期,比较是否到9一个周期,跳转一个周期,那么大致需要9x(3+3+1+1+1+1)=90周期
所以计算一层网络就用时15M*90=1.35G个周期!
我们去掉零头,1G个周期,那么100MHz主频运行的STM32就要10s计算一层,1GHz主频运行的Cortex-A7需要1s计算一层!
而通常情况下,一个实用的神经网络模型需要10层以上的计算!那对于没有优化的CPU就需要秒级甚至分钟级的时间去运算!
所以,一般来说,CPU/MCU来计算神经网络是非常耗时,不具有实用性的。
而神经网络运算的应用场景,又分为训练侧 与 推断侧。
对于训练模型所需要的高运算力,我们已经有了NVIDIA的各种高性能显卡来加速运算。
对于模型推断,通常是在消费电子/工业电子终端上,也即AIoT,对于体积,能耗会有要求,所以,我们必须引入专用的加速模块来加速模型推断运算,这时候KPU就应运而生了!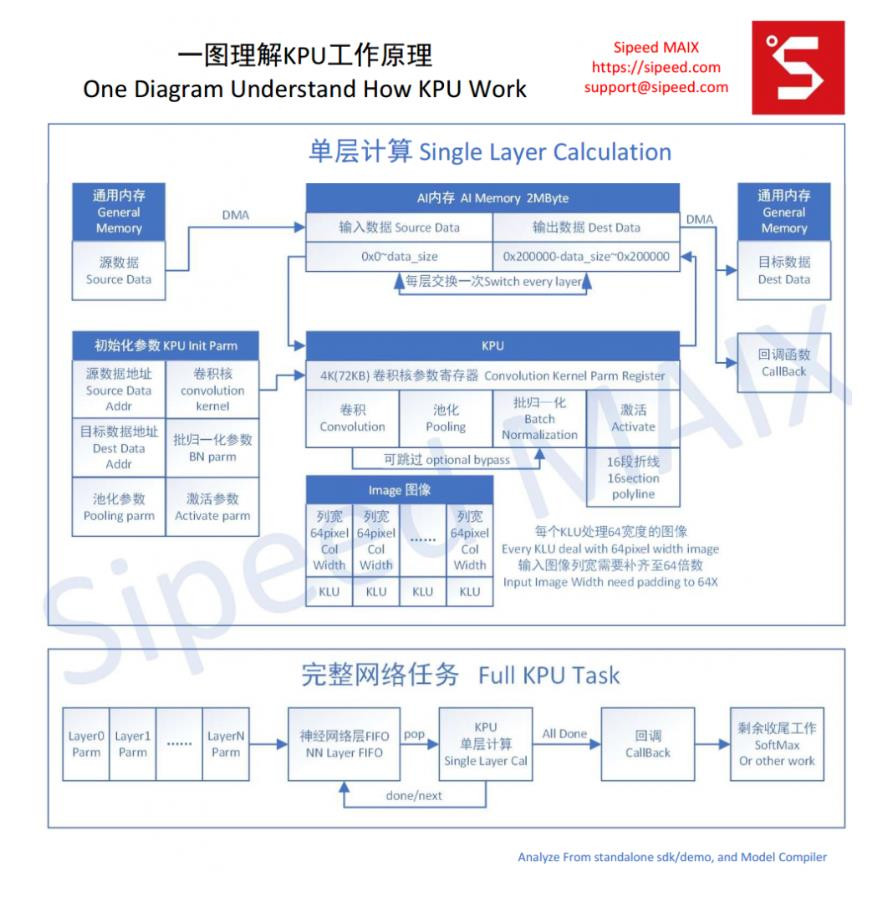

若有收获,就点个赞吧
0 人点赞
