https://www.jianshu.com/p/608872377546
Join的基本实现
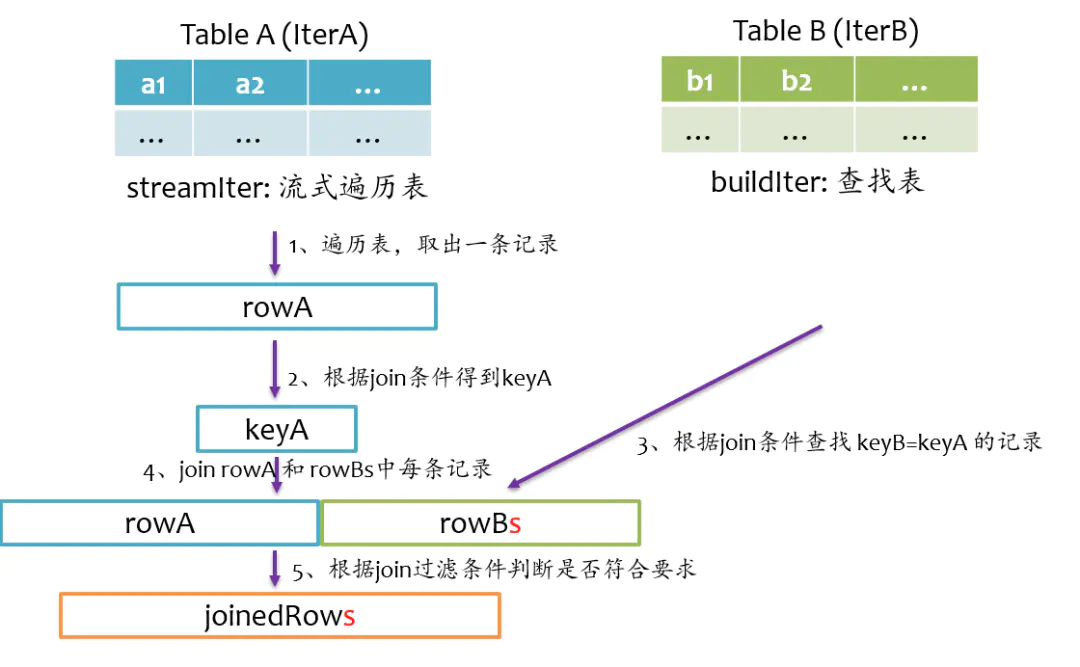
通常streamlter为大表,用于遍历;buildlter为小表,用于查询。spark根据join语句自动判定
等值连接Join
Broadcast Join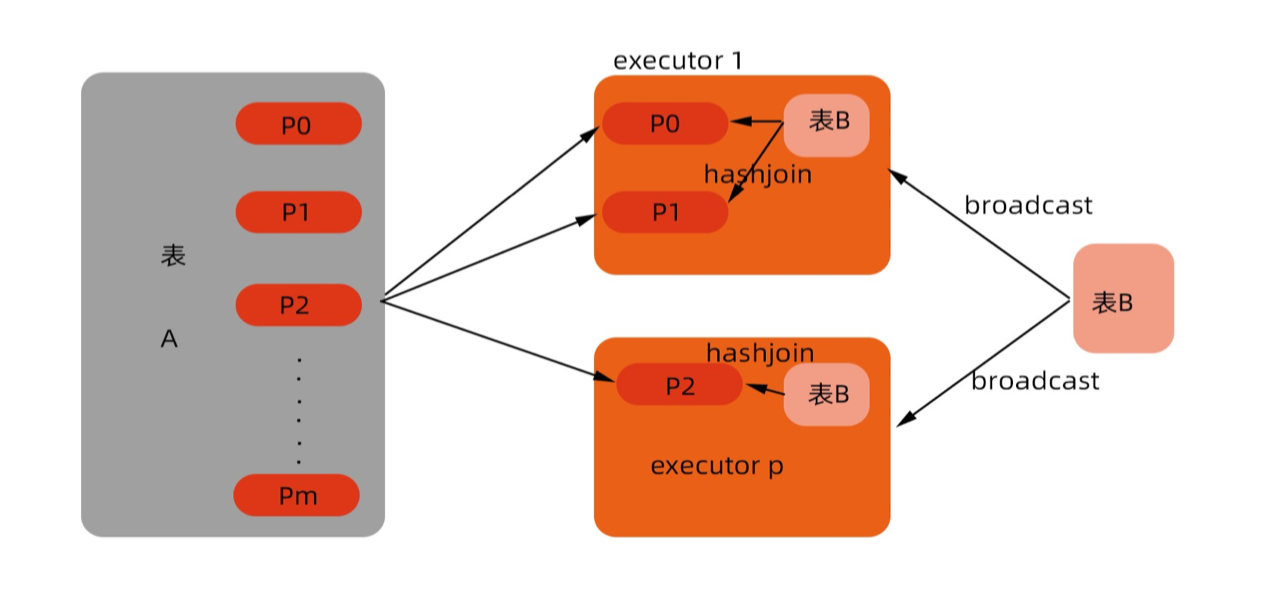
如果buildtler是非常小的表,不必shuffle,直接broadcast,将这个表分发到每个计算节点中,再将buildtler放入hash表
Shuffle Hash Join
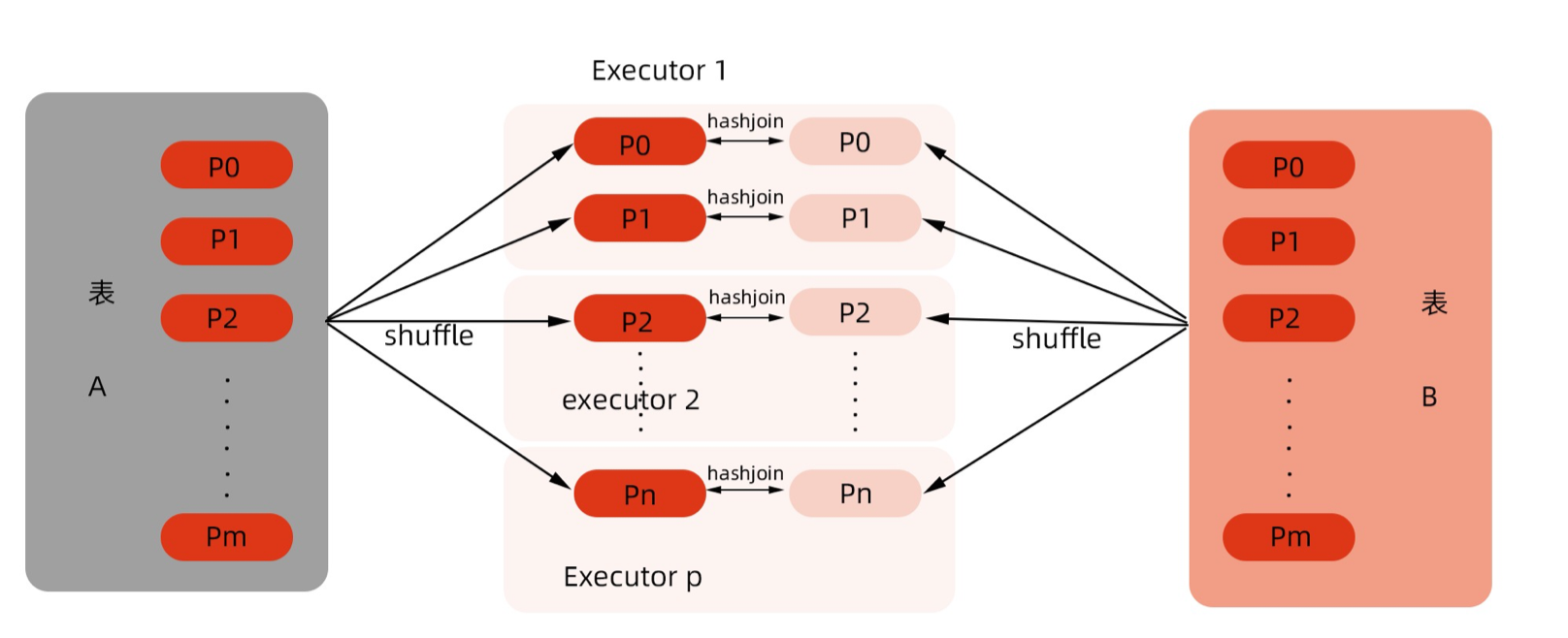
shuffle read阶段不对记录排序,反正来自量表的具有相同key的记录会在一个分区,将来自buildtler的记录放入hash表中
Sort Merge Join
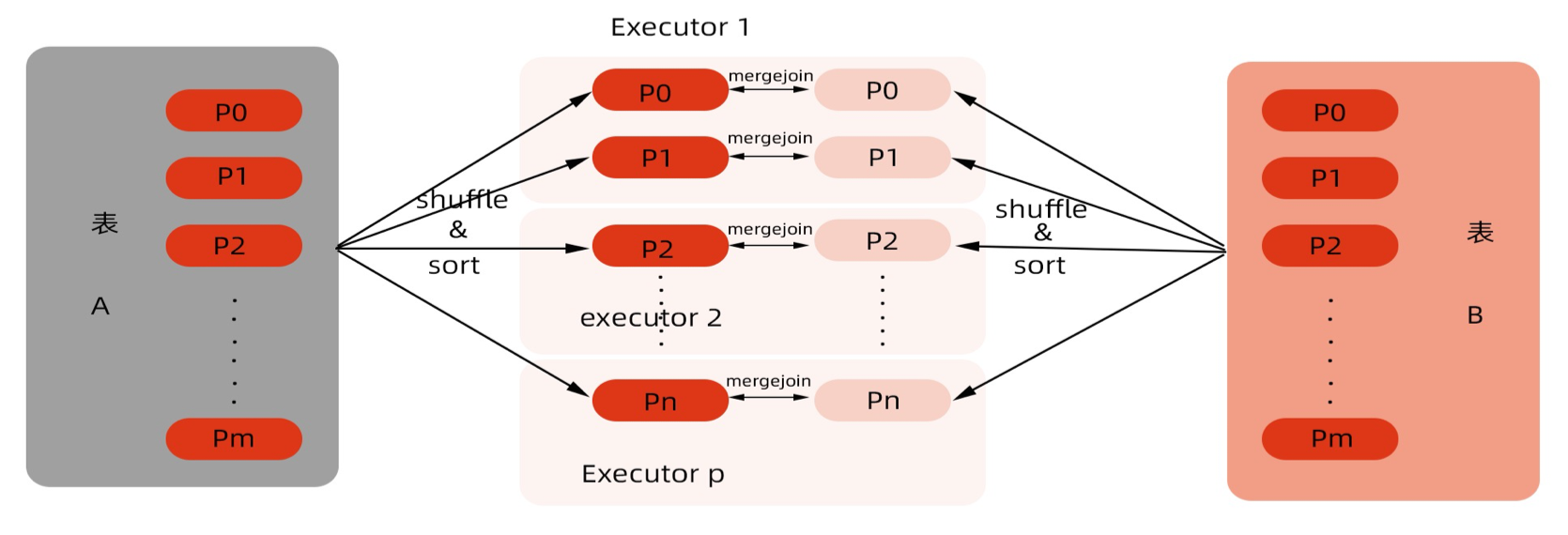
通常来说,需要做一次shuffle,mapper根据join条件确定每条记录的key,基于该key做shuffle write,将可能join到一起的记录分到同一个分区中。
对于buildlter一定要是查找性能较优的数据结构,通常就是hash表,但对于一张很大的表来说,不可能将所有记录全部放到hash表中,这个时候可以对buildltr先做排序,查找时按顺序查找。由于buildlter和streamlter都是排序好的,每次处理完streamlter的一条记录后,只需从buildlter中上次查找结束的位置开始,总体性能还是较优的
- broadcast hash join 效率最高,根据broadcast hint来判断,其次是广播阈值
- hash join 次之,
- spark.sql.join.preferSortMergeJoin 配置项为 false
- 右表能够作为build table,构建本地hashMap,先右后左
- 右比左小很多(3倍)
- sort merge join
非等值Join
如果Join条件为a.id > b.id,则只能使用nest loop join(即二重循环扫描 + 比对)
Join优化
Dataset<Row> shipItems = getSpark().sql("select " +"ship.*, item.* " +"from ship left join item " +"on ship.asin = item.item_asin").drop("item_asin");shipItems.createOrReplaceTempView("ship_items");
问题:
由于spark将表A load进内存时,需要5G,而将表B load进内存时,需要500G,当把整个集群的内存加到600G的时候,这个错误仍然无法解决,猜测内存600G的集群仍无法join表A和表B,可能是因为在join的过程中生成了多份数据而超过了表A和表B原来的大小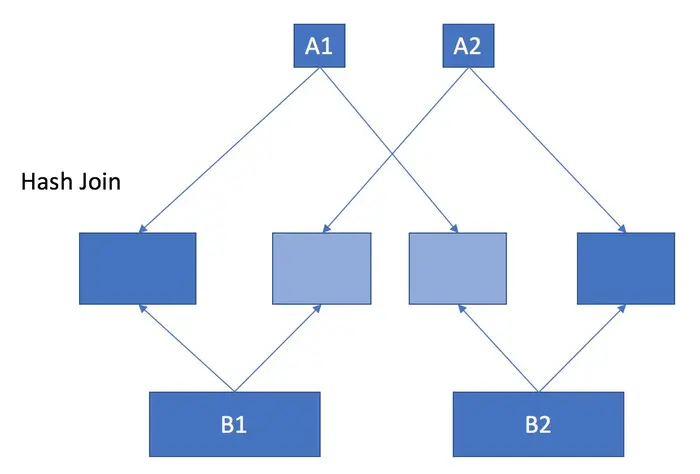
蓝色代表已经存在于集群中内存中的数据,浅蓝色代表正在生成中的数据,那么此时整个集群所需要的内存为两倍于表A和表B大小
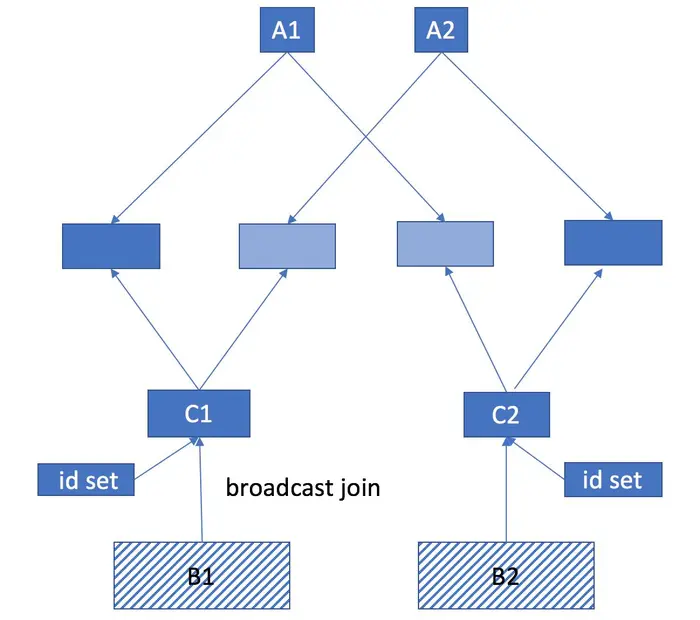
因为我们表A left join 表B 之后的结果和表A的大小是一样的,所以实际上大部分表B的数据是没有用的,那么我们可不可以先将一部分表B的数据去掉呢?我们可以确定的是只有存在于表A中物品才会出现在结果中,所以我们可以将表A中的所有商品ID取出来做成一个集合,这个集合的大小为 20 * 10^7/1000/1000 = 200 M,然后将这个集合broadcast到每一个slave节点进行filter,这样可以得到一个大大缩减版的表B。更重要的是,我们得到缩减版的表B之后,原来那个巨大的表B就可以从内存中删除了,这样可以大大减少内存的使用,最终使得程序成功运行
Dataset<Row> distinctAsin = getSpark().sql("select distinct asin from ship").persist(StorageLevel.DISK_ONLY())//only keep items appeared in shipmentsDataset<Row> filteredItems = getSpark().sql("select * from item").withColumnRenamed("asin", "item_asin").join(functions.broadcast(distinctAsin),functions.col("item_asin").equalTo(functions.c("asin")), "leftsemi").persist(StorageLevel.DISK_ONLY());filteredItems.createOrReplaceTempView("filter_item");Dataset<Row> shipItems = getSpark().sql("select " +"ship.*, filter_item.* " +"from ship left join filter_item " +"on ship.asin = filter_item.item_asin").drop("item_asin");shipItems.createOrReplaceTempView("ship_items");

若有收获,就点个赞吧
0 人点赞
