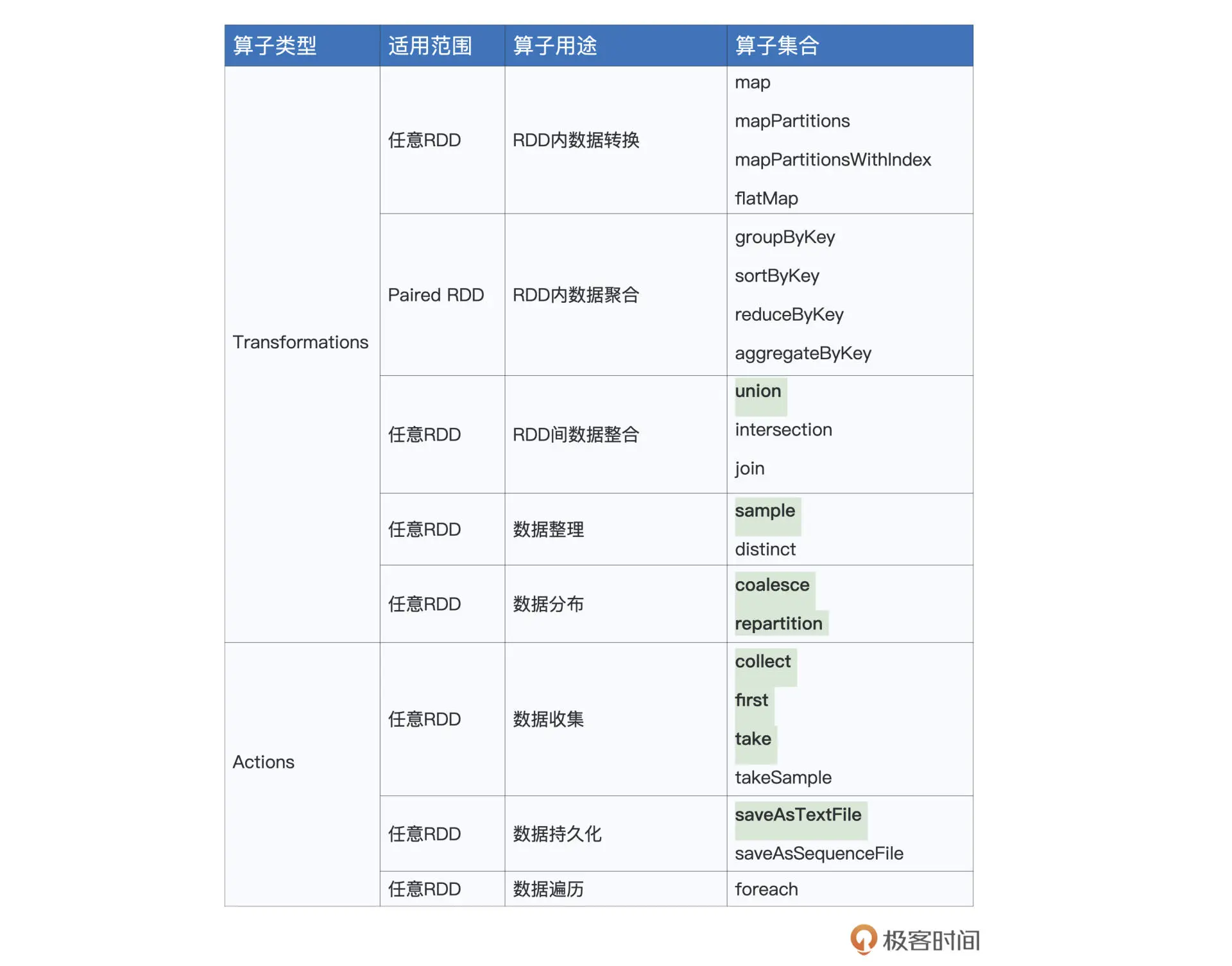
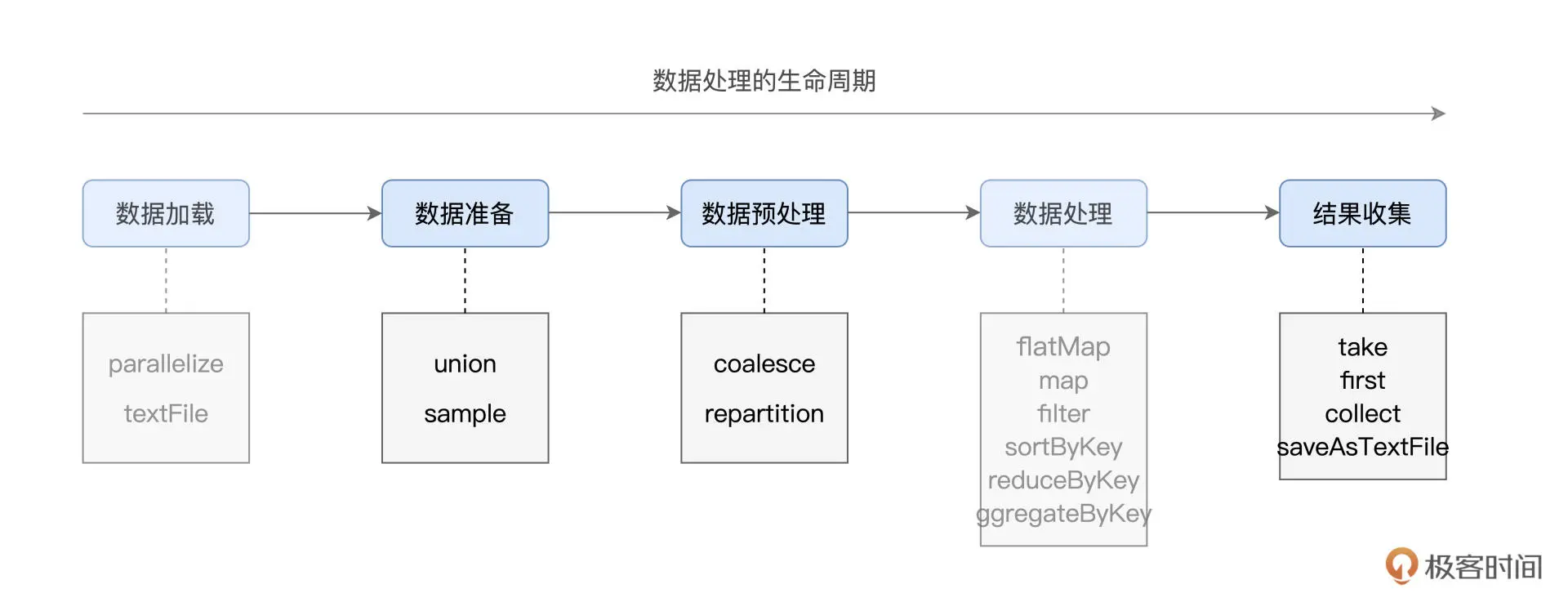
常用算子图表
union
// T:数据类型val rdd1: RDD[T] = _val rdd2: RDD[T] = _val rdd = rdd1.union(rdd2)// 或者rdd1 union rdd2// T:数据类型val rdd1: RDD[T] = _val rdd2: RDD[T] = _val rdd3: RDD[T] = _val rdd = (rdd1.union(rdd2)).union(rdd3)// 或者 val rdd = rdd1 union rdd2 union rdd3
给定两个RDD:rdd1和rdd2,其结果是两个RDD的并集
sample
sample(withReplacement, fraction, seed)
withReplacement: boolean 采样是否又放回,true:采样结果中可能包含重复的数据记录
fraction: Double,值域0-1,采样比例,结果集尺寸/原数据集尺寸
seed:Long,控制每次采样的结果是否一致
// 生成0到99的整型数组val arr = (0 until 100).toArray// 使用parallelize生成RDDval rdd = sc.parallelize(arr)// 不带seed,每次采样结果都不同rdd.sample(false, 0.1).collect// 结果集:Array(11, 13, 14, 39, 43, 63, 73, 78, 83, 88, 89, 90)rdd.sample(false, 0.1).collect// 结果集:Array(6, 9, 10, 11, 17, 36, 44, 53, 73, 74, 79, 97, 99)// 带seed,每次采样结果都一样rdd.sample(false, 0.1, 123).collect// 结果集:Array(3, 11, 26, 59, 82, 89, 96, 99)rdd.sample(false, 0.1, 123).collect// 结果集:Array(3, 11, 26, 59, 82, 89, 96, 99)// 有放回采样,采样结果可能包含重复值rdd.sample(true, 0.1, 456).collect// 结果集:Array(7, 11, 11, 23, 26, 26, 33, 41, 57, 74, 96)rdd.sample(true, 0.1, 456).collect// 结果集:Array(7, 11, 11, 23, 26, 26, 33, 41, 57, 74, 96)
repartition
repartition(n)
用于调整RDD的并行度
RDD的并行度很大程度上决定了分布式系统中CPU的使用效率,进而会影响分布式系统并行计算的执行效率
把并行度调整为可用CPU的2~3倍(Executors数量为N,每个Executor配置的CPU个数为C,那么推荐并行度坐落在NC2到NC3这个范围)是个不错的开始,但真正合理的并行度,取决于系统可用资源,分布式数据集大小,以及执行内存
尽管repartition非常灵活,但一定会引入shuffle。如果你想增加并行度,那么repartition是不二之选;但如果你想降低并行度,那么coalesce可以在不引入shuffle的情况下进行
coalesce
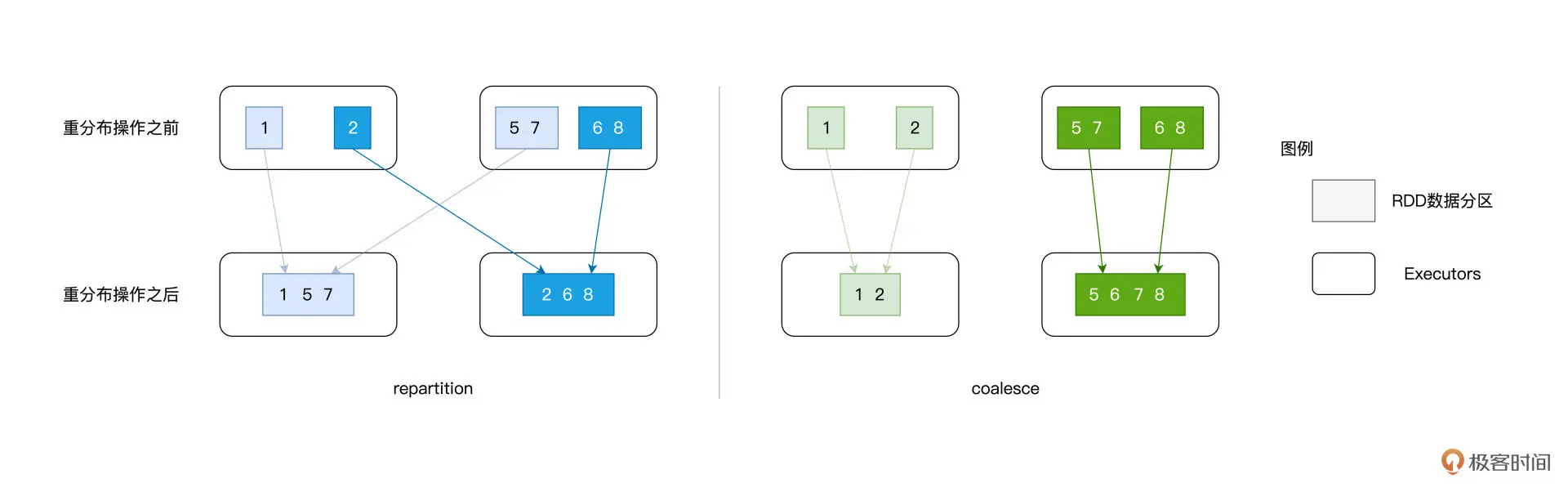
具体来说,给定任意一条数据记录,repartition 的计算过程都是先哈希、再取模,得到的结果便是该条数据的目标分区索引。对于绝大多数的数据记录,目标分区往往坐落在另一个 Executor、甚至是另一个节点之上,因此 Shuffle 自然也就不可避免。coalesce 则不然,在降低并行度的计算中,它采取的思路是把同一个 Executor 内的不同数据分区进行合并,如此一来,数据并不需要跨 Executors、跨节点进行分发,因而自然不会引入 Shuffle。
first, take和collect
first 用于收集RDD数据集中的一条数据
take(n: Int) 用于收集多条记录
collect 拿到全量数据,把RDD的计算结果全量的收集到Driver端
collect两处性能隐患:拉取数据过程中的网络开销 + Driver的OOM,因此,如果想收集全量数据,可用saveAsTextFile
saveAsTextFile
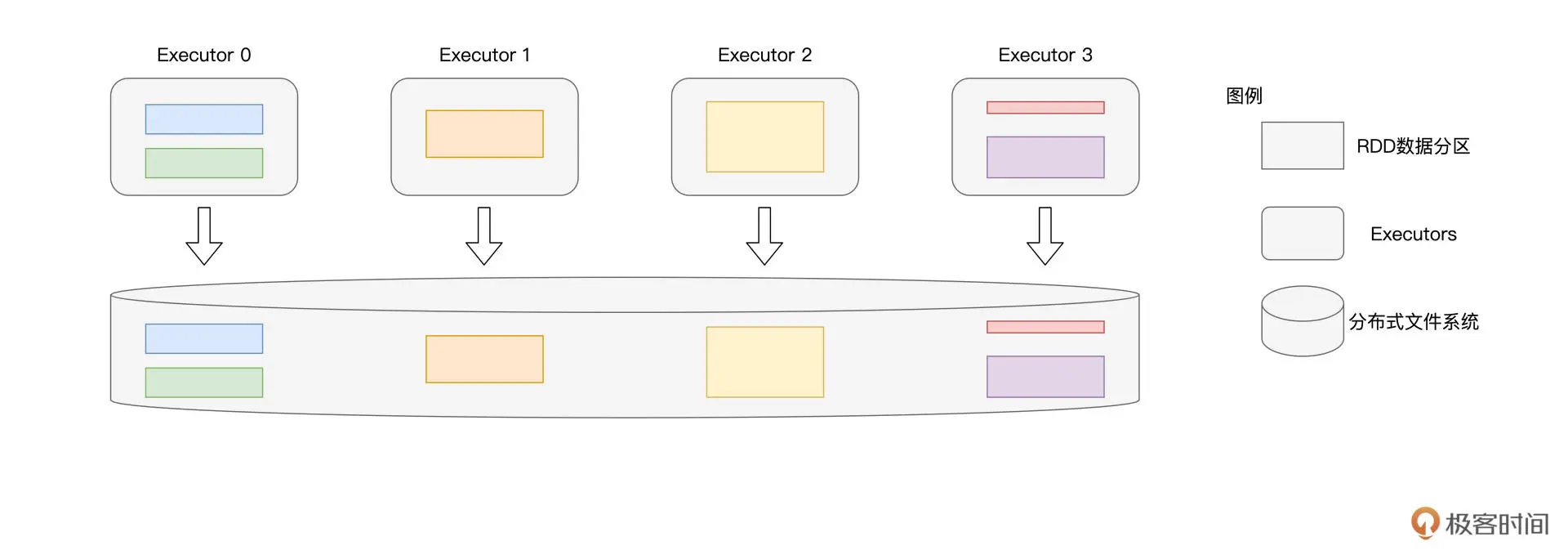
直接通过Executors将RDD数据分区物化到文件系统,这个过程并不涉及与Driver端的任何交互

若有收获,就点个赞吧
0 人点赞
