Spark SQL 端到端的完整优化流程主要包括两个阶段:Catalyst优化器 和 Tungsten。其中Catalyst优化器又包含逻辑优化和物理优化两个阶段。
Catalyst
逻辑计划解析:Unresolved Logical Plan -> Analyzed Logical Plan
逻辑计划优化:Analyzed Logical Plan -> Optimized Logical Plan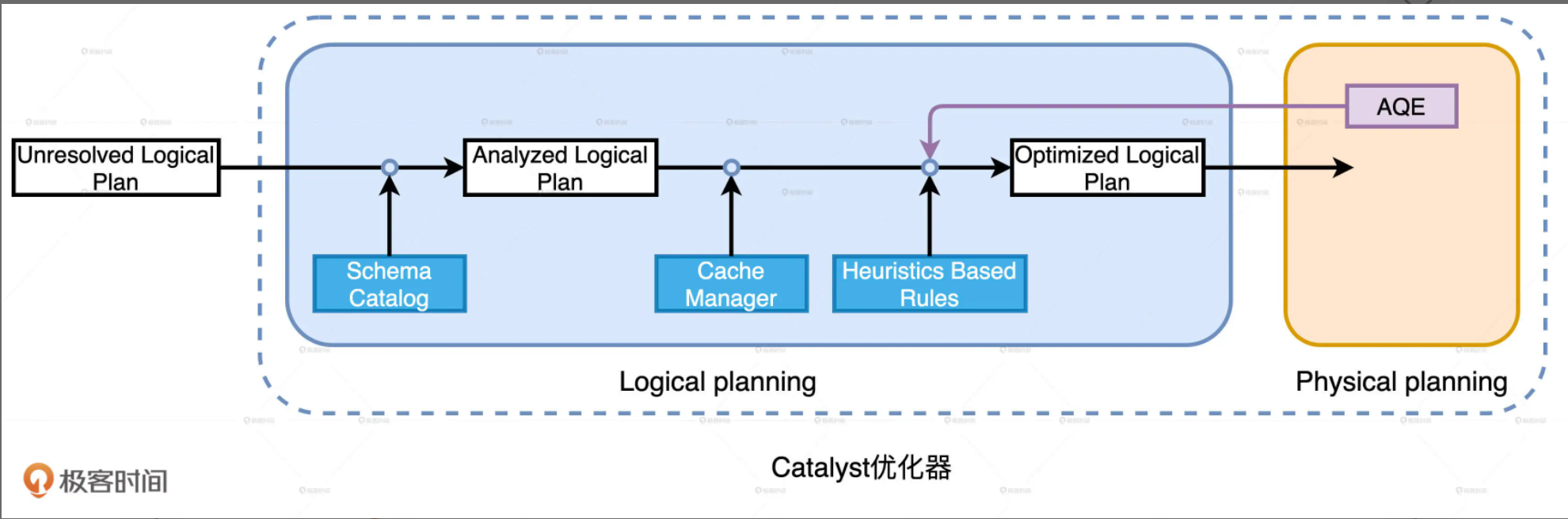
val result = txDF.select("price", "volume", "userId").join(users, Seq("userId"), "inner").groupBy(col("name"), col("age")).agg(sum(col("price") * col("volume")).alias("revenue"))
Unresolved Logical Plan -> Analyzed Logical Plan

Unresolved Logical Plan携带的信息有限,它只包含查询语句从DSL语法变为AST语法的信息。例如,在计划的最底层,Relation节点告诉Catalyst:你需要扫描一张表,这张表有4个字段,分别是ABCD,文件格式是Parquet。但除了这些信息,我们还需要知道这张表的Scheme是啥,字段的类型都有什么,字段名是否真实存在,数据表中的字段名与计划中的字段名是一致的吗,这些问题在Unresolved Logical Plan -> Analyzed Logical Plan的过程中,结合Schema信息来完成确认。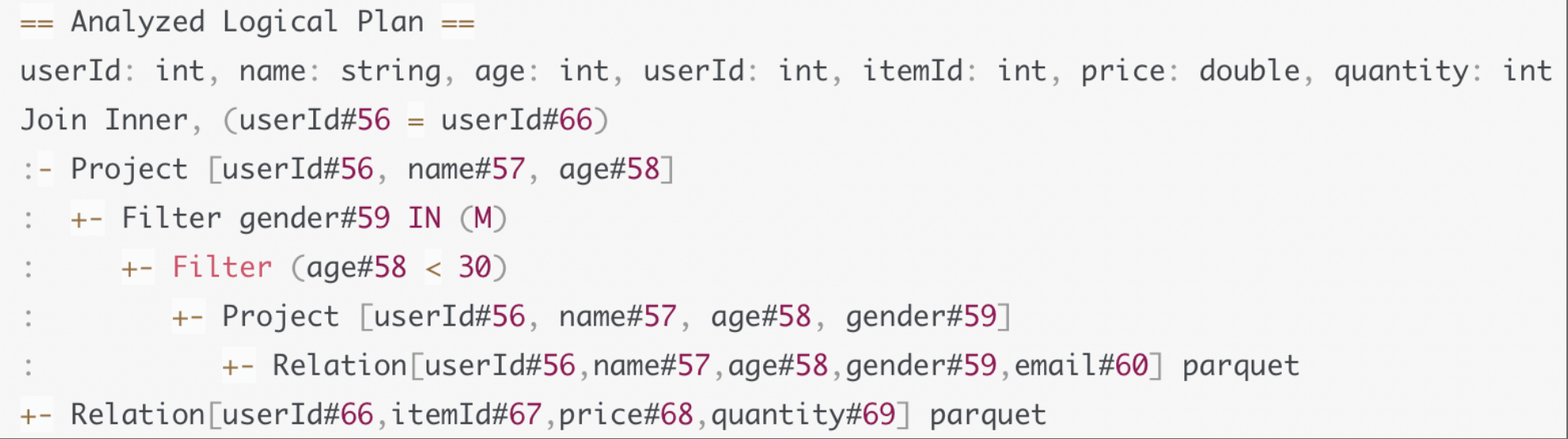
Analyzed Logical Plan -> Optimized Logical Plan
按照不同的顺序对算子做排列组合,我们可以演化出不同的实现方式。遵循,能省则省,能拖则拖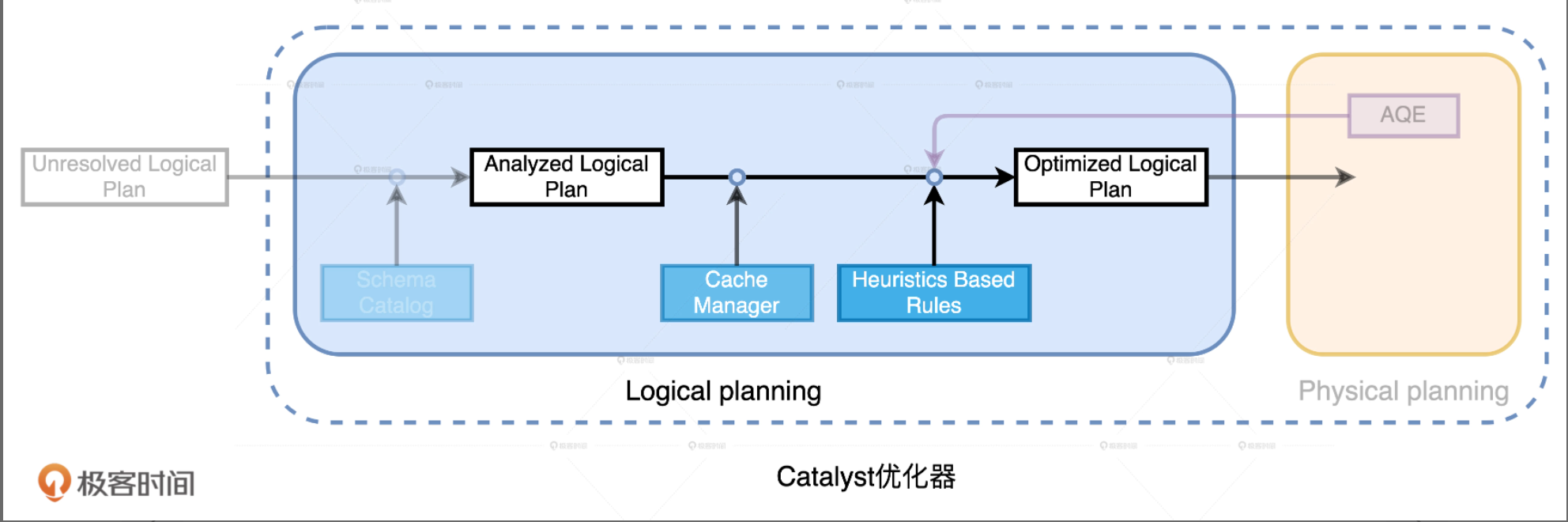
Spark 3.0中,Catalyst总共有81条优化规则(Rules),这81条规则会分成27组(Batches),有些规则会被收纳到多个分组里。规则可以归纳为3个范畴:
谓词下推(Predicate Pushdown),列剪枝(Column Pruning),常量替换(Constant Folding)
谓词下推
谓词:age < 30 这样的过滤条件
下推:把这些谓词沿着执行计划向下,推到离数据源最近的地方,从而在源头减少数据扫描量
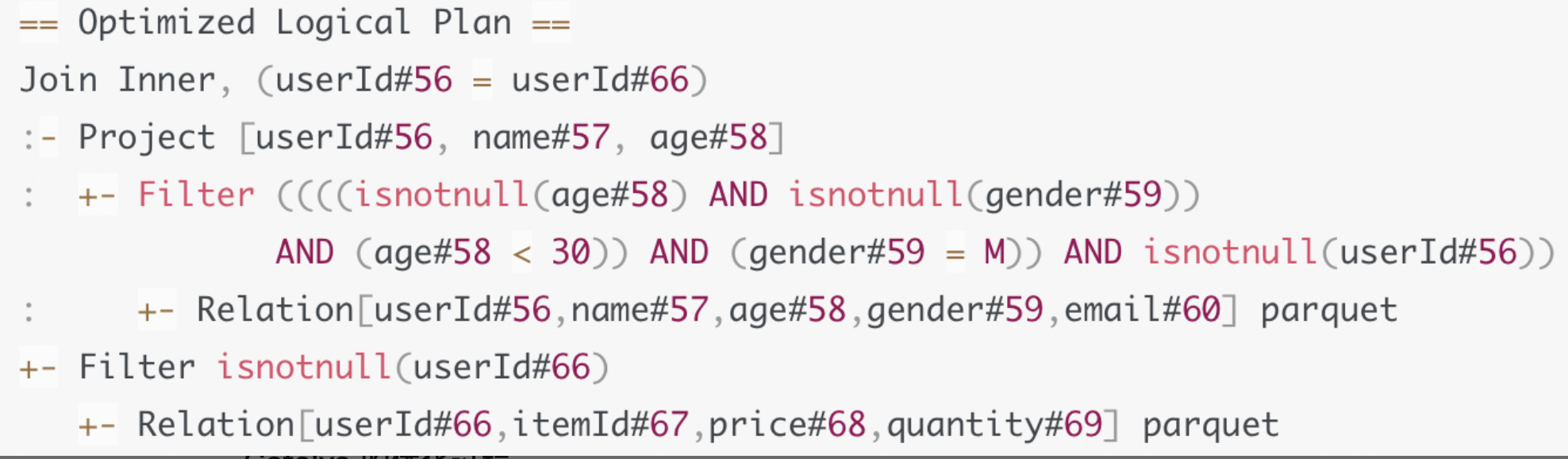
在谓词下推之前,Catalyst还会做另一些优化,比如OptimizeIn规则,把gender in M 优化成 gender = M,做in等值替换。再比如,把age < 30和gender = M捏合成一个谓词,age != null and gender != null and age < 30 and gender = M
列剪枝
扫描数据源时,只读取那些与查询相关的字段。(列存的时候,有效减少文件读取量)
常量替换
age < 12 + 18 -> age < 30。(当数据量巨大,对每一行都做一次计算的开销可以被减掉)
Logical Plan -> Spark Plan
逻辑优化仅仅从逻辑上表明Spark SQL需要做什么,并没有从执行层面说明具体该怎么做。如:在Optimized Logical Plan里,出现了Join Inner字样,明确这步要做内关联,但是,怎么做内关联,使用哪种Join策略来进行关联,Catalyst并没有交代,因此逻辑计划本身不具备可操作性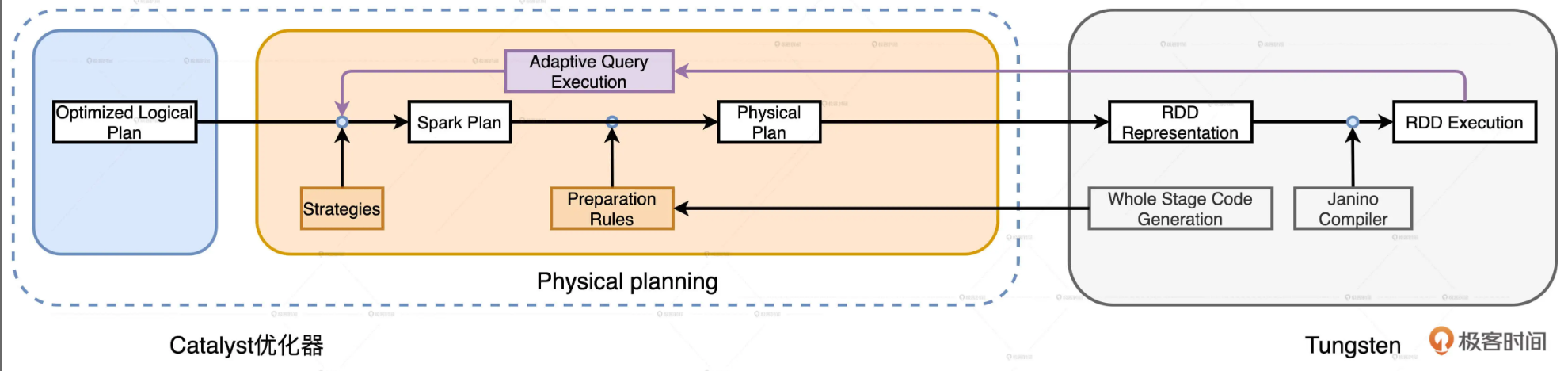
Physical Planning可分为两个环节:优化Spark Plan和生成Physical Plan
优化Spark Plan:Catalyst基于既定的优化策略,把逻辑计划中的关系操作符,一一映射成物理操作符,生成Spark Plan
生成Physical Plan:Catalyst基于事先定义的Preparation Rules,对Spark Plan做进一步的完善,生成可执行的Physical Plan
Catalyst Join策略
Broadcast Hash Join, Shuffle Sort Merge Join, Shuffle Hash Join, Broadcast Nested Loop Join, Shuffle Cartesian Product Join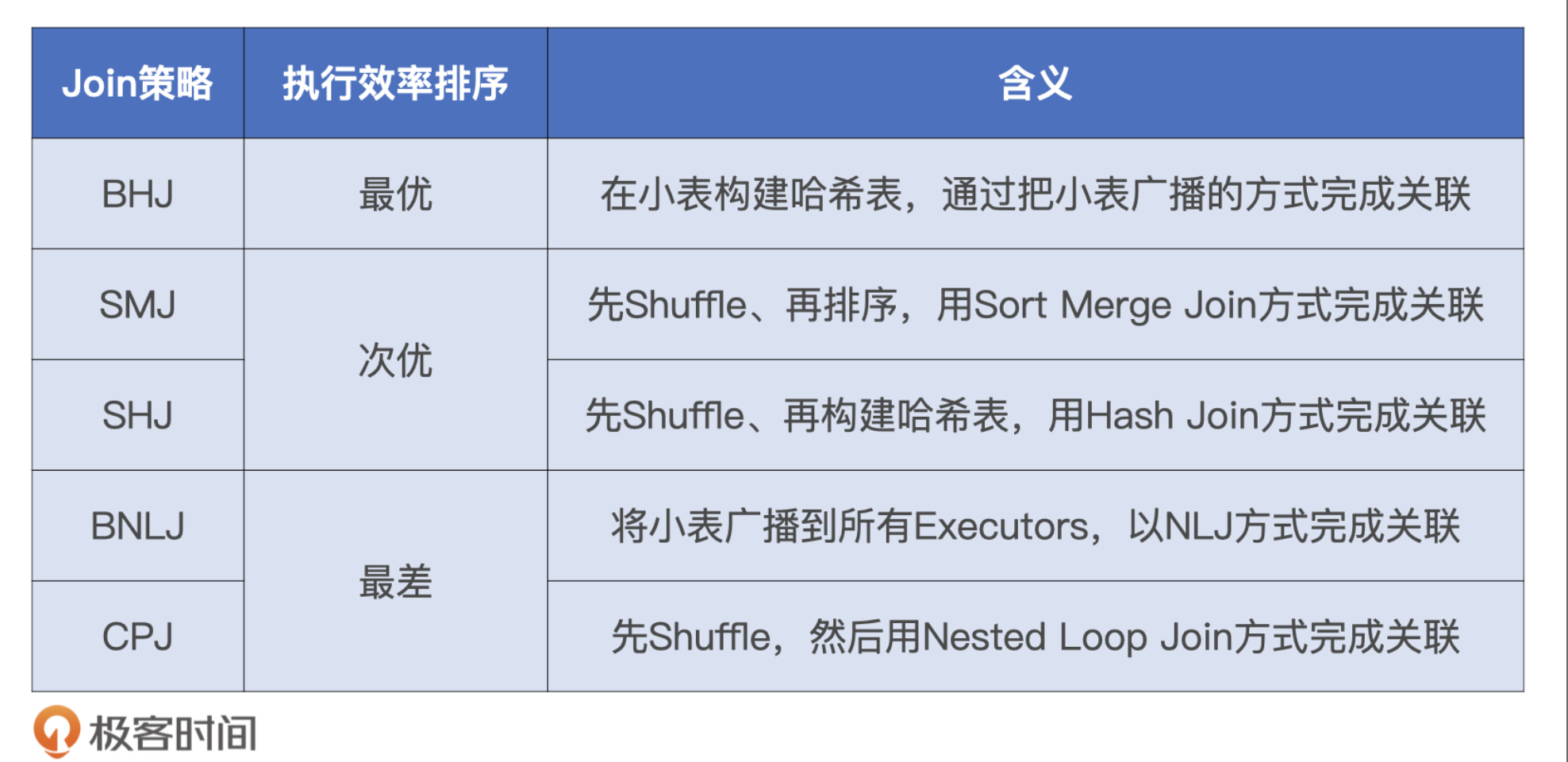
JoinSelection如何决定选择哪一种Join策略?
Catalyst会尝试优先选择执行效率最高的策略。在做决策的时候,还需要依赖的信息:
1.条件型:1.Join类型-是否等值,连接形式,来源于查询语句本身。2.内表尺寸-可以是hive标上的ANALYZE TABLE语句,也可以是Spark对于Parquet,ORC,CSV等源文件的尺寸预估,甚至是来自AQE的动态统计信息
2.指令型:开发者提供的Join Hints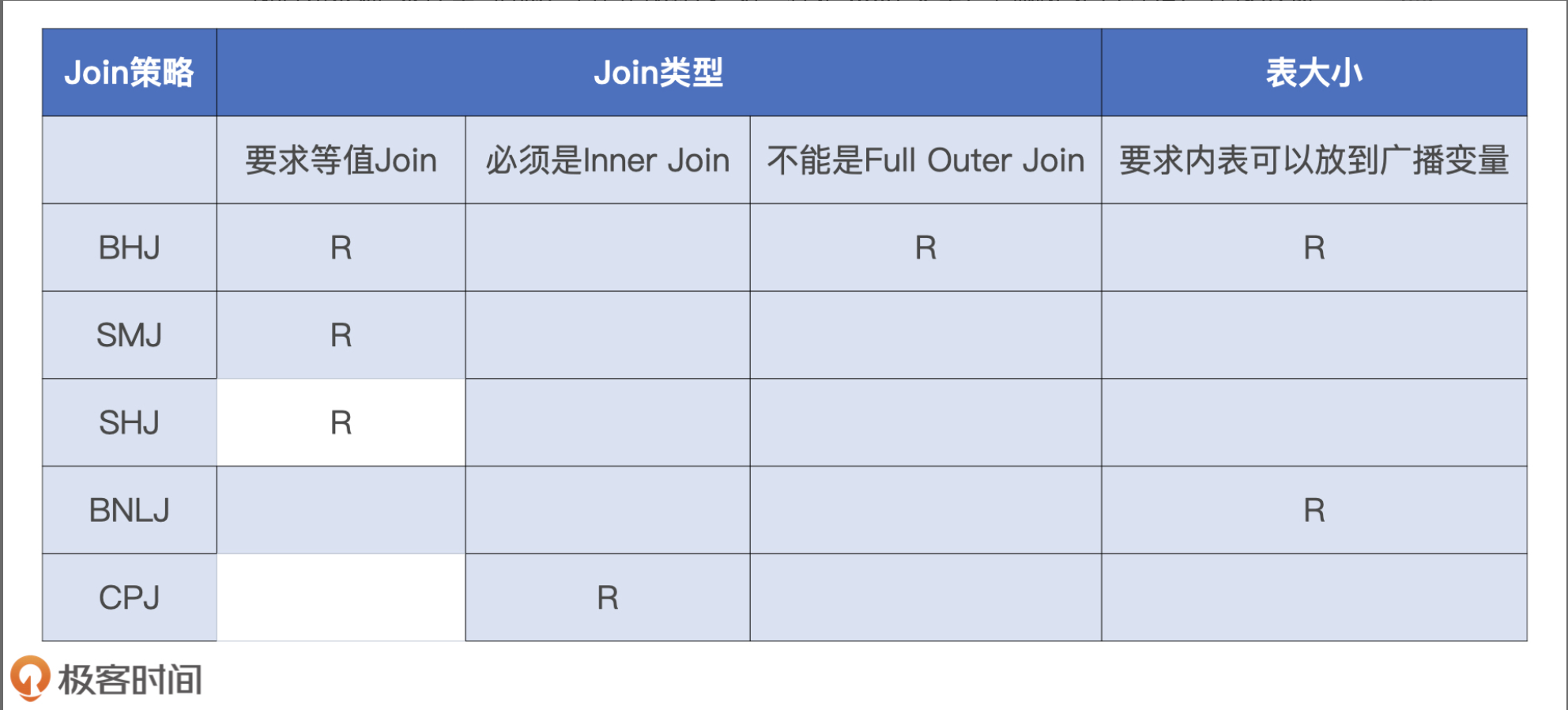
SMJ Join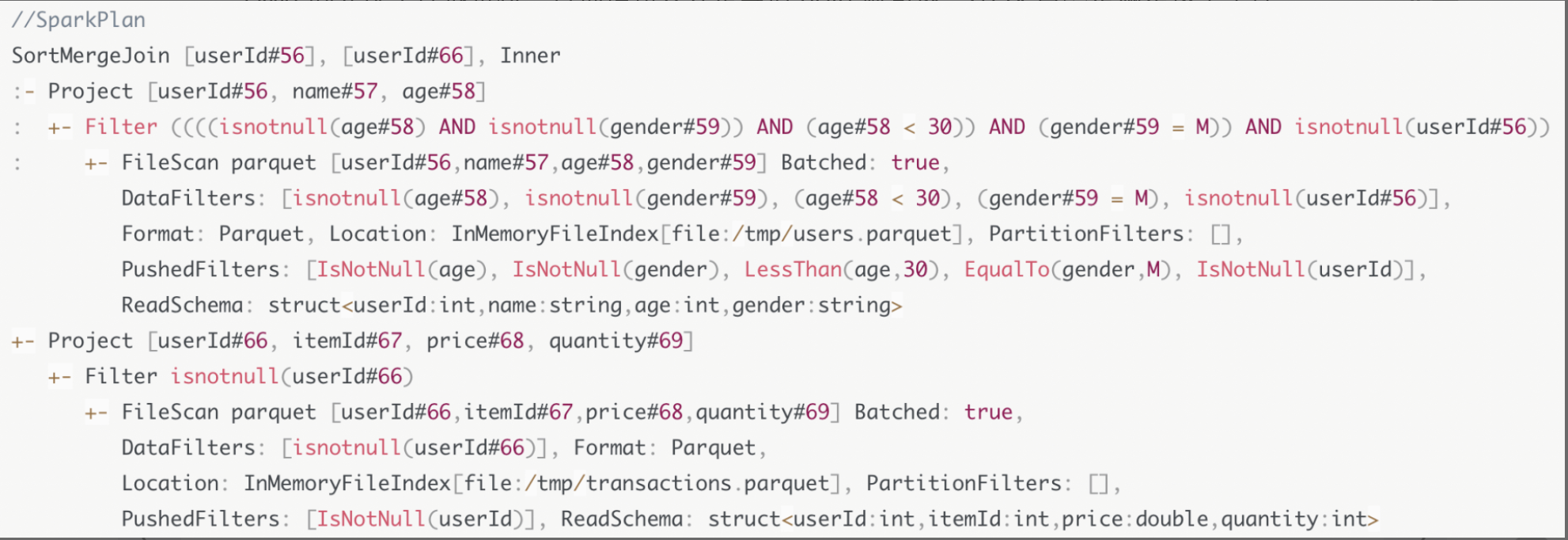
为什么Spark Plan还是做不到把这样的查询计划转化成可执行的分布式任务呢?
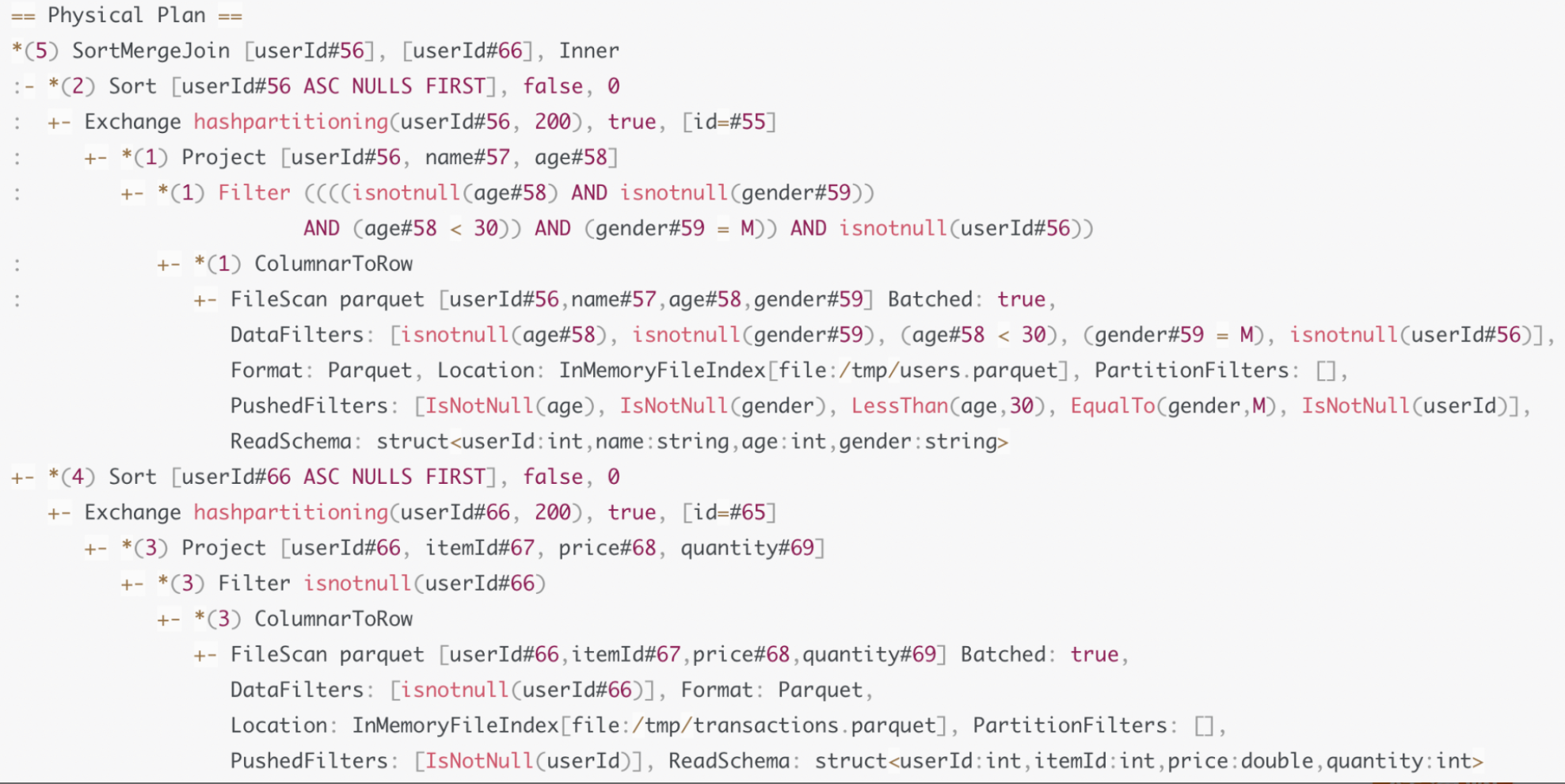
因为Shuffle Sort Merge Join的计算需要两个先决条件:Shuffle和排序。而Spark Plan中并没有明确指定以哪个字段为基准进行Shuffle,以及按照哪个字段去做排序。因此,Catalyst需要对Spark Plan做进一步的转换,生成可操作,可执行的Physical Plan。
Spark Plan -> Physical Plan
从Spark Plan到Physical Plan,需要几组叫做Preparation Rules的规则,这些规则作用到Spark Plan之上,就会生成Physical Plan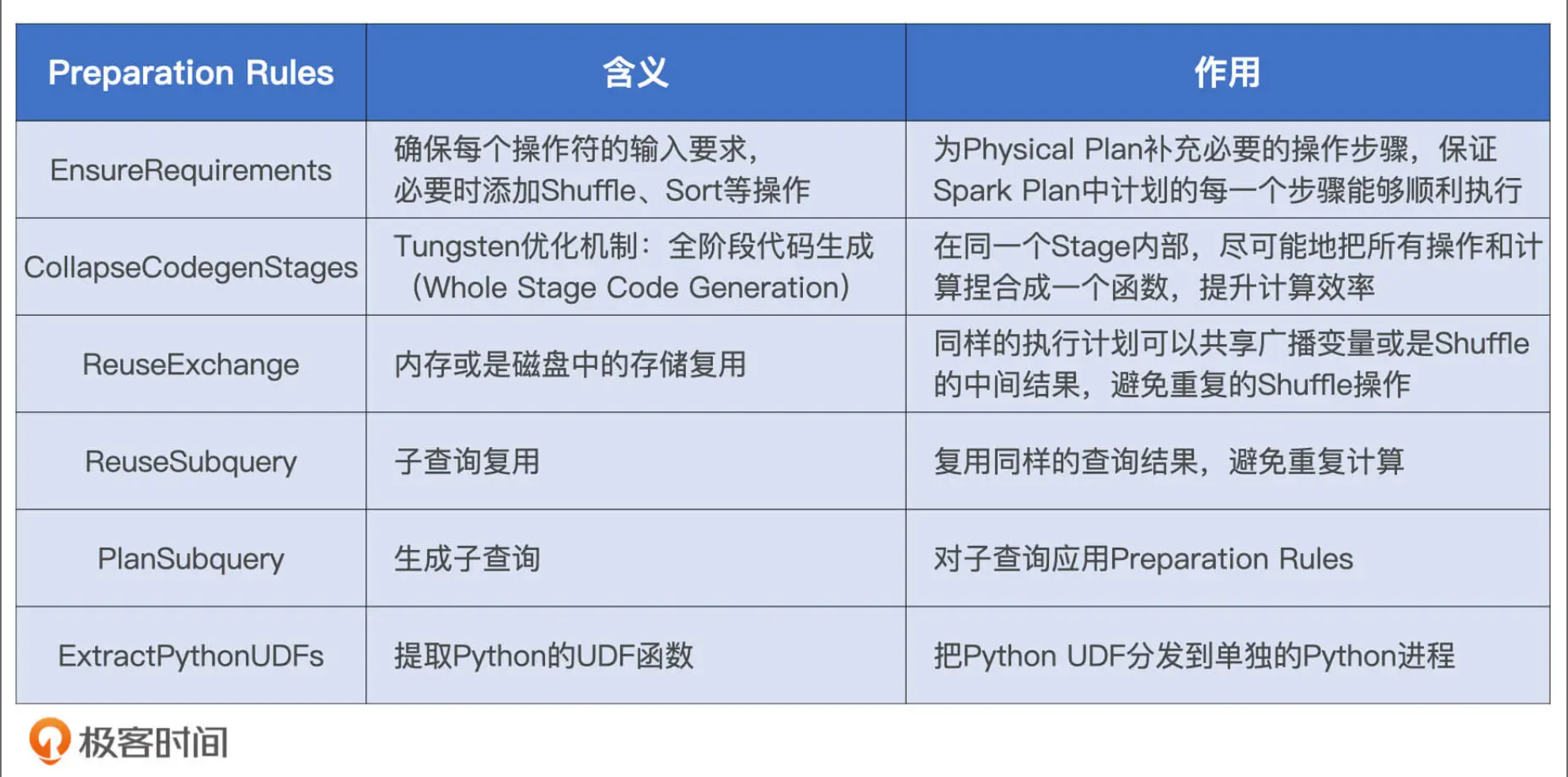
EnsureRequirements
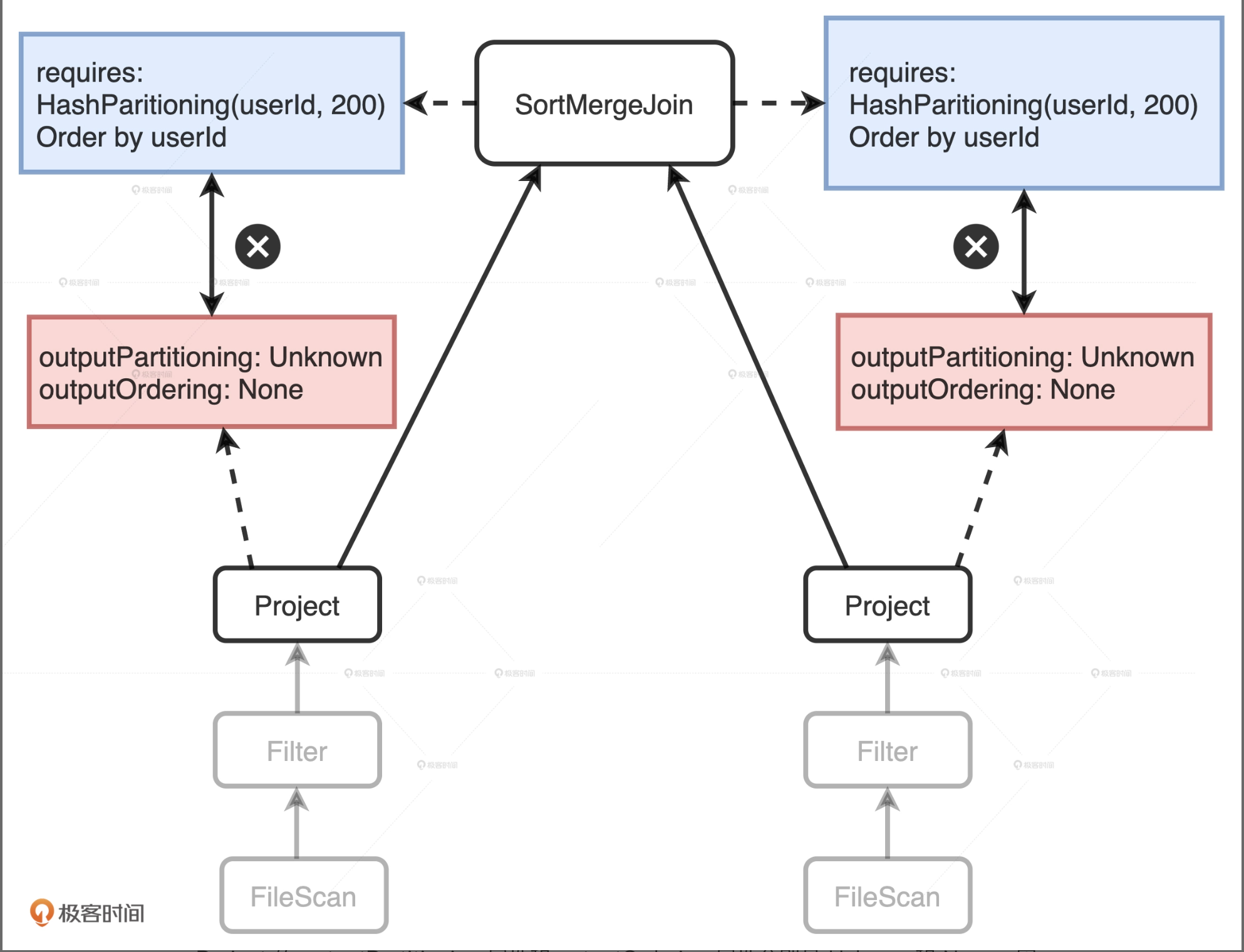
SortMergeJoin对于输入数据的要求很明确:按照userId分成200个分区且排好序,而这两个Project子节点的输出显然并没有满足父节点SortMergeJoin的要求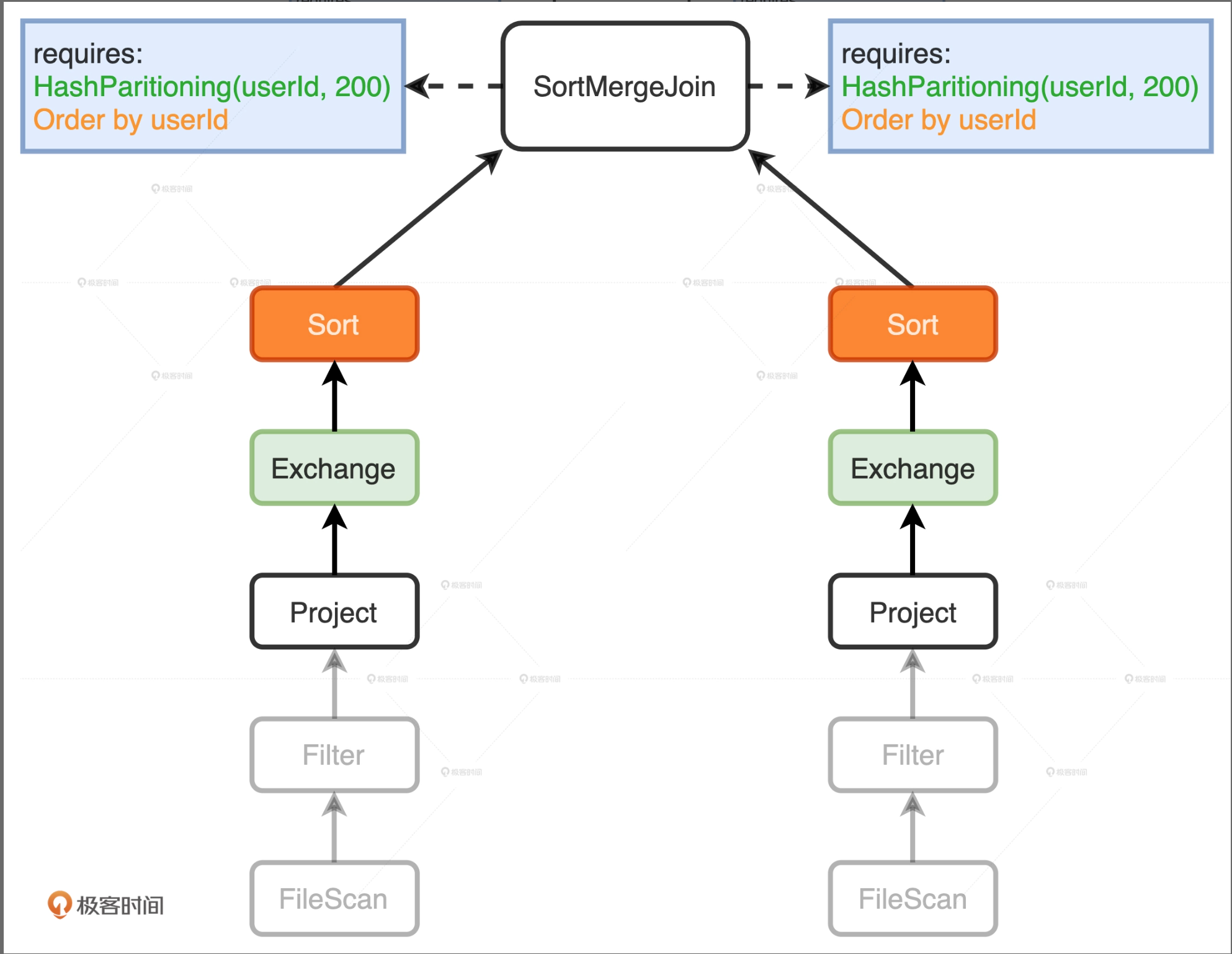
在两个Project节点之后,EnsureRequirements规则分别添加了Exchange和Sort节点。其中Exchange节点代表Shuffle操作,用来满足SortMergeJoin对于数据分布的要求;Sort表示排序,用于满足SortMergeJoin对于数据有序的要求。
添加了必须的节点之后,Spark可以通过调用Physical Plan的do Execute方法,把结构化查询的计算结果,转换成RDD[InternalRow],InternalRow就是Tungsten设计的定制化二进制数据结构,通过调用RDD[InternalRow]之上的Action算子,Spark就可以触发Physical Plan从头至尾依序执行
Catalyst 优化过程
不管是逻辑计划,还是物理计划,都继承自QueryPlan
QueryPlan有个父类是TreeNode,TreeNode就是语法树中对节点的抽象。TreeNode定义了一个高阶函数叫做transformDown方法,transformDown的形参,正式Catalyst定义的各种优化规则,方法的返回类型还是TreeNode。另外,transformDown是个递归函数,参数的优化规则会先作用于当前节点,然后依次作用于children中的子节点,直到整棵树的叶子节点。
总的来说,从Analyzed Logical Plan到Optimized Logical Plan的转换,就是从一个TreeNode生成另一个TreeNode的过程。

若有收获,就点个赞吧
0 人点赞
