RDD Cache
import org.apache.spark.rdd.RDDval rootPath: String = _val file: String = s"${rootPath}/wikiOfSpark.txt"// 读取文件内容val lineRDD: RDD[String] = spark.sparkContext.textFile(file)// 以行为单位做分词val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))// 把RDD元素转换为(Key,Value)的形式val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))// 按照单词做分组计数val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)wordCounts.cache// 使用cache算子告知Spark对wordCounts加缓存wordCounts.count// 触发wordCounts的计算,并将wordCounts缓存到内存// 打印词频最高的5个词汇wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)// 将分组计数结果落盘到文件val targetPath: String = _wordCounts.saveAsTextFile(targetPath)take和saveAsTextFile这两个操作执行的都很慢。cache函数并不会立即触发RDD在内存中的物化,因此还需要调用count算子来触发这一执行过程。cache函数实际上会进一步调用persisit来为其添加缓存,因此.cache与.persist(MEMORY_ONLY)是等价的
https://time.geekbang.org/column/article/418079
https://time.geekbang.org/column/article/421566
https://time.geekbang.org/column/article/423131
常用算子图表
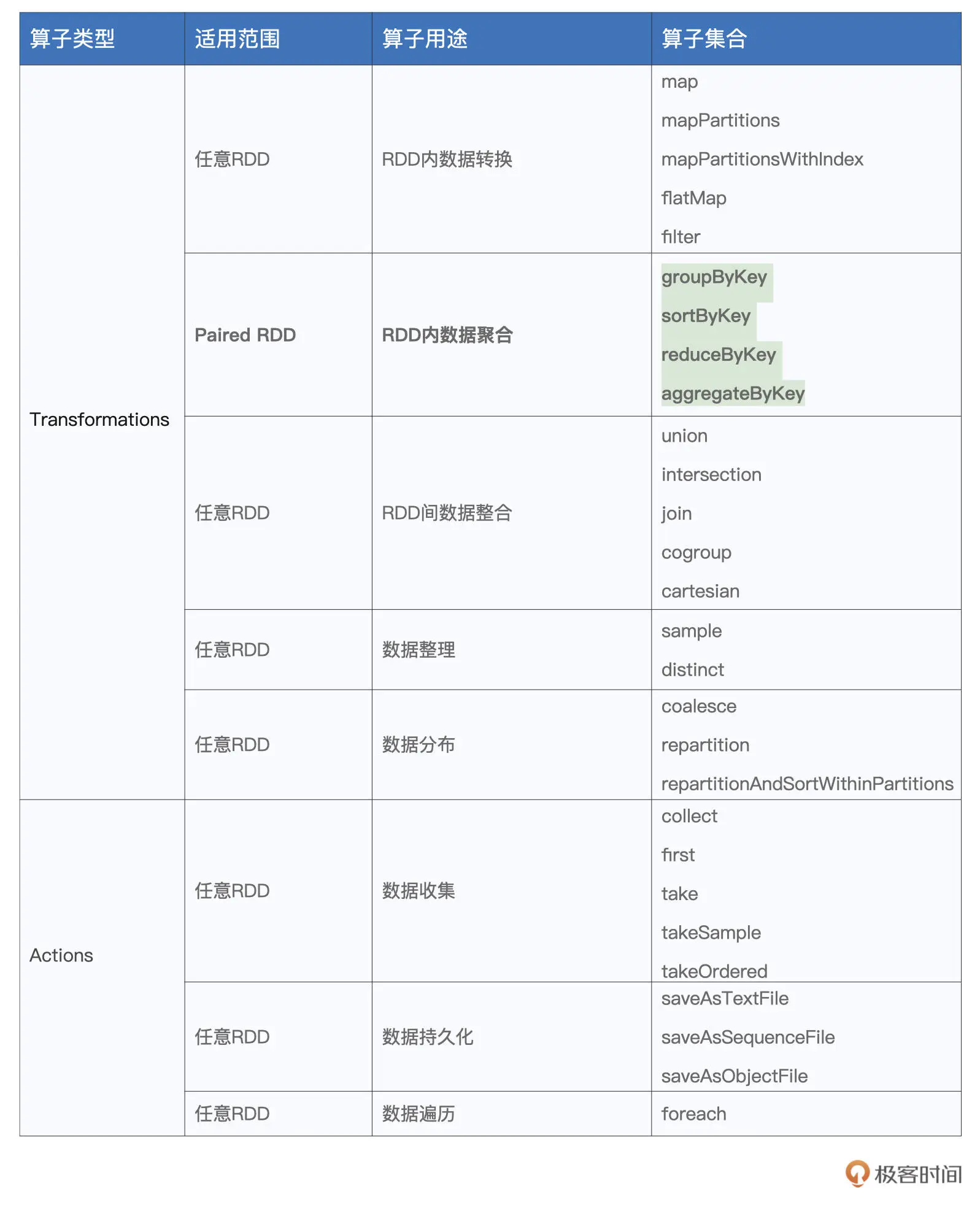
Transformations
map
给定映射函数f,map(f)以元素为粒度对RDD做数据转换。其中f可以是带有明确签名的带名函数,也可以是匿名函数,它的型参类型必须与RDD的元素类型保持一致
// 把普通RDD转换为Paired RDD// 匿名函数val cleanWordRDD: RDD[String] = _ // 省略完整代码val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))// 带名函数def f(word: String): (String, Int) = {return (word, 1)}val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(f)
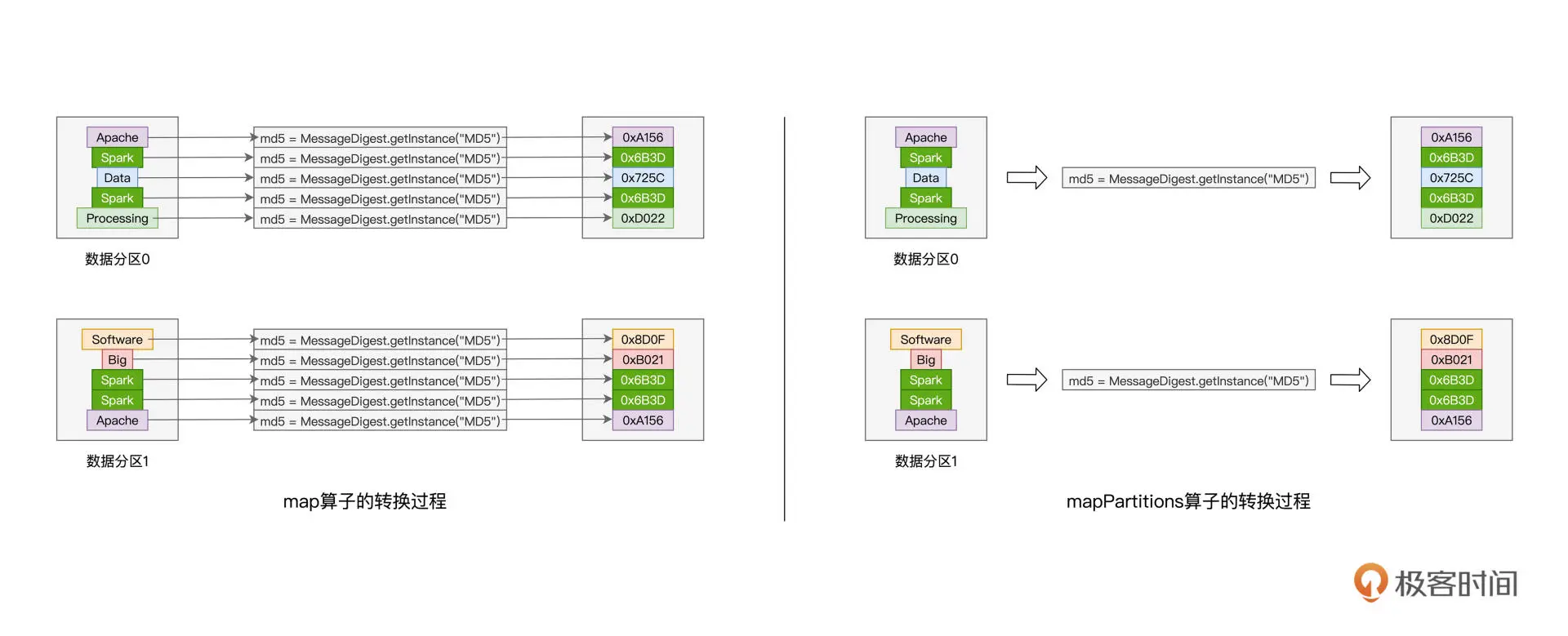
map的性能考虑
// 把普通RDD转换为Paired RDDimport java.security.MessageDigestval cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码val kvRDD: RDD[(String, Int)] = cleanWordRDD.map{ word =>// 获取MD5对象实例val md5 = MessageDigest.getInstance("MD5")// 使用MD5计算哈希值val hash = md5.digest(word.getBytes).mkString// 返回哈希值与数字1的Pair(hash, 1)}
对于RDD中的每一条数据记录,我们都需要实力化一个MessageDigest对象来计算这个元素的哈希值。如果RDD有上百万甚至上亿级别的数据记录,实力化对象的开销就会聚成沙。因此,可以用mapPartitions和mapPartitionsWithIndex来解决类似的问题
mapPartitions
以数据分区为粒度的数据转换
// 把普通RDD转换为Paired RDDimport java.security.MessageDigestval cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码val kvRDD: RDD[(String, Int)] = cleanWordRDD.mapPartitions( partition => {// 注意!这里是以数据分区为粒度,获取MD5对象实例val md5 = MessageDigest.getInstance("MD5")val newPartition = partition.map( word => {// 在处理每一条数据记录的时候,可以复用同一个Partition内的MD5对象(md5.digest(word.getBytes()).mkString,1)})newPartition})
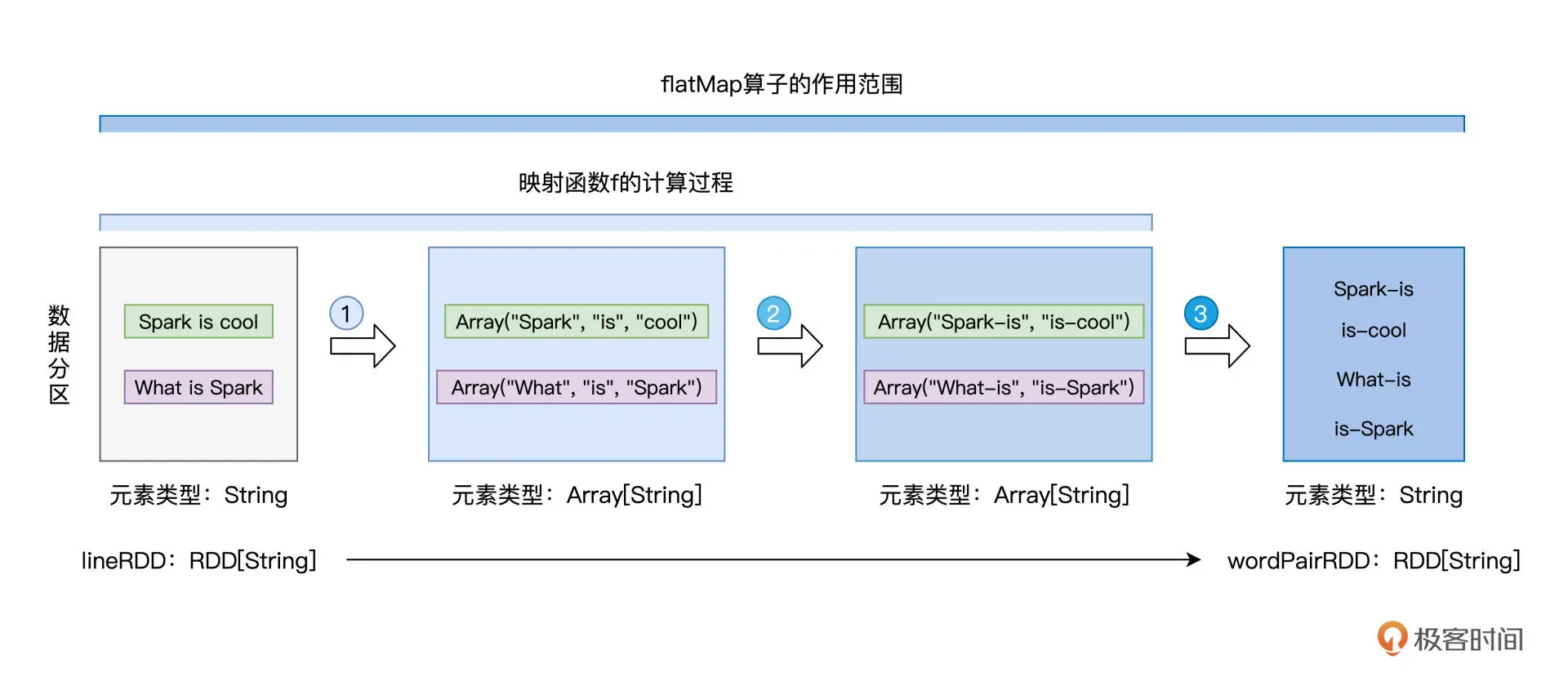
flatMap
从元素到集合,再从集合到元素
// 读取文件内容val lineRDD: RDD[String] = _ // 请参考第一讲获取完整代码// 以行为单位提取相邻单词val wordPairRDD: RDD[String] = lineRDD.flatMap( line => {// 将行转换为单词数组val words: Array[String] = line.split(" ")// 将单个单词数组,转换为相邻单词数组for (i <- 0 until words.length - 1) yield words(i) + "-" + words(i+1)})
filter
// 定义特殊字符列表val list: List[String] = List("&", "|", "#", "^", "@")// 定义判定函数fdef f(s: String): Boolean = {val words: Array[String] = s.split("-")val b1: Boolean = list.contains(words(0))val b2: Boolean = list.contains(words(1))return !b1 && !b2 // 返回不在特殊字符列表中的词汇对}// 使用filter(f)对RDD进行过滤val cleanedPairRDD: RDD[String] = wordPairRDD.filter(f)
Actions
1.将分布式计算结果直接落盘的操作,如DataFrame的write, RDD的saveAsTextFile
2.将分布式结果收集到Driver端的操作,如first, take, collect

若有收获,就点个赞吧
0 人点赞
