Driver是运行用户编写Application main() 方法的地方,具体负责DAG的构建,任务的划分,task的生成和调度等
在集群模式下,由executor执行输出写入的是executor的stdout,而不是driver上的stdout。要想在driver端打印所有元素,可以使用collect()方法先将RDD数据带到driver节点,然后再调用foreach
// driver端resultRdd.map{ _._1 }.collect.toSet
所有对RDD具体数据的操作都是在executor上执行,所有对rdd自身的操作都是在driver上执行。比如,foreach,foreachPartition都是针对rdd内部数据进行处理的,所以他们都执行于executor端;而foreachRDD(开启对任务的启动,当执行到算子的时候开始任务的执行),transform则是对RDD本身进行操作,他的函数是执行于driver端的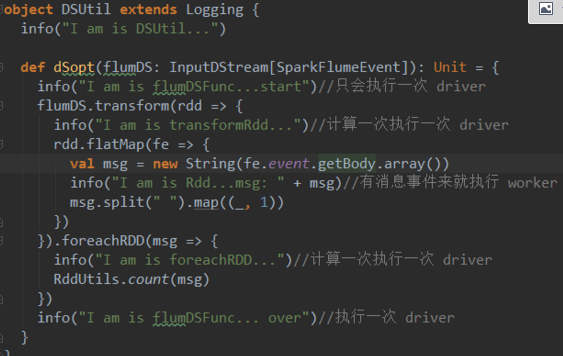
在SparkStreaming中引入了DStream,DStream的action方法中的代码只有在处理rdd时才会在worker端执行,其他对dstream进行的操作就运行在driver节点
常见在Driver端执行
parallelize, createDataFrame等API创建数据集
take, show, collect等算子把结果收集到Driver端

若有收获,就点个赞吧
0 人点赞
