Q1: 为 Spark SQL 添加一条自定义命令
SqlBase.g4






通过antlr4生成代码

转换成Unresolved Logical Plan
- 在SparkSqlParser.scala下,重载 visitShowVersion 方法。入参:ShowVersionContext是antlr生成的代码 ```scala visitShowVersion(ctx: ShowVersionContext): LogicalPlan = withOrigin(ctx) { ShowVersionCommand() }
case class ShowVersionCommand() extends LeafRunnableCommand {
override val output: Seq[Attribute] = Seq(AttributeReference(“version”, StringType)())
override def run(sparkSession: SparkSession): Seq[Row] = { val sparkVersion = sparkSession.version val javaVersion = System.getProperty(“java.version”) val output = “Spark Version: %s, Java Version: %s”.format(sparkVersion, javaVersion); Seq(Row(output)) }
}
编译:build/mvn clean package -DskipTests<br />后可通过Spark shell 执行 SHOW VERSION<a name="Cet12"></a>### Q2.1: 构建 一条SQL同时满足满足优化规则:- **CombineFilters**:合并filter- **CollapseProject**:该规则主要针对SELECT操作(对应Project逻辑计划)进行合并- **BooleanSimplification**:简化boolean表达式。如:去掉1=1;简化 x + 1 < y + 1 为 x < y;合并相同的表达式;去除not```scala// combineFilters: 合并a11 > 1 & a1 > 10// 谓词下推:将a11 > 1 and 1 = 1 下推到 子查询,与 a1 > 10 平齐// collapseProject: 将 select a1 + 1 as a11, a2; select a11, a2 + 1 as a21// 简化为 select a1 + 1 as a11, a2 + 1 as a12// booleanSimplification: 1 = 1 去掉SELECT a11, (a2 + 1) AS a21FROM (SELECT (a1 + 1) AS a11, a2 FROM t1 WHERE a1 > 10) WHERE a11 > 1 AND 1 = 1;
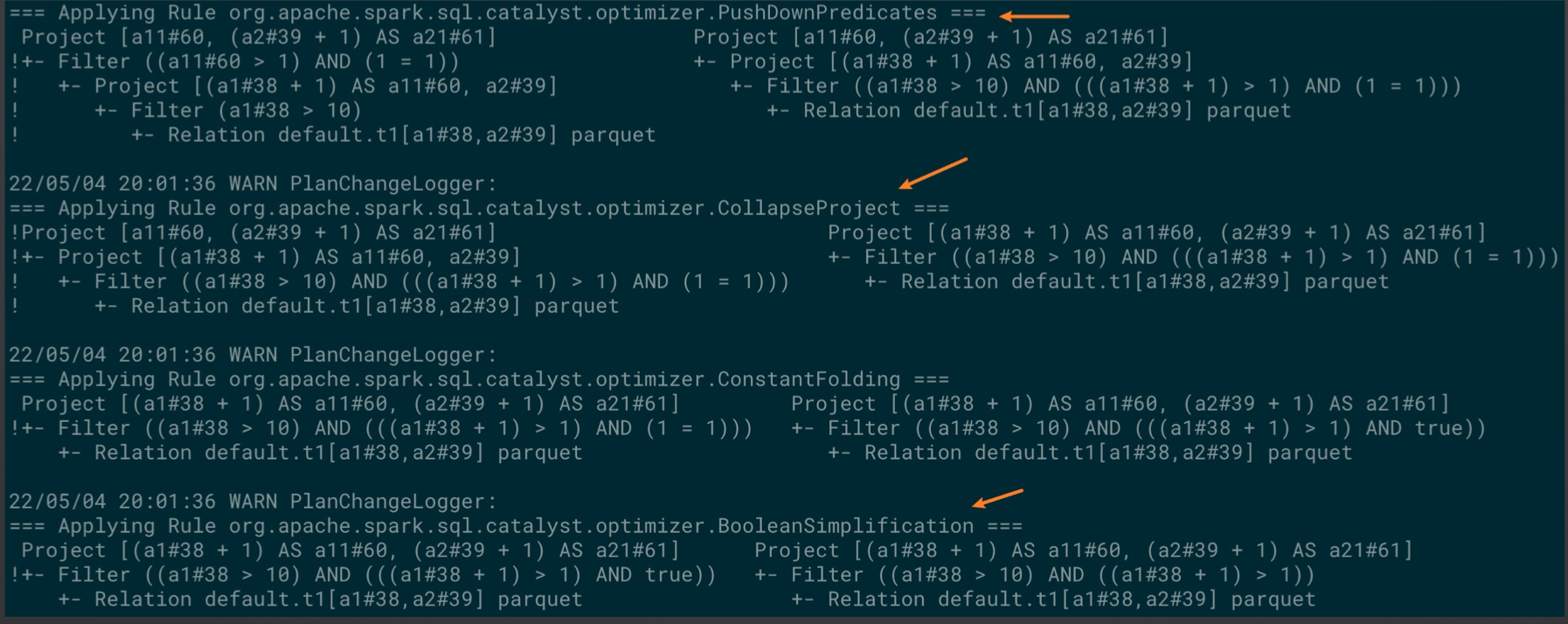
Q2.2: 构建 一条SQL同时满足满足优化规则:
- ConstantFolding:SELECT 1+1 ===> SELECT 2
- PushDownPredicates: 谓词下推,将Predicates下推到离数据源最近的地方
- ReplaceDistinctWithAggregate:
SELECT DISTINCT f1, f2 FROM t ===> SELECT f1, f2 FROM t GROUP BY f1, f2
- ReplaceExceptWithAntiJoin:
SELECT a1, a2 FROM Tab1 EXCEPT SELECT b1, b2 FROM Tab2
===>
SELECT DISTINCT a1, a2 FROM Tab1 LEFT ANTI JOIN Tab2 ON a1 <=> b1 AND a2 <=> b2
- FoldablePropagation:
SELECT 1.0 x, ‘abc’ y, Now() z ORDER BY x, y, 3
===>
SELECT 1.0 x, ‘abc’ y, Now() z ORDER BY 1.0, ‘abc’, Now()
// pushDownPredicates:// 将a2 = 10 AND 1 = 1 推到子查询外,与 a1 > 5 AND 1 = 1 平齐// BooleanSimplification:// 将 1 = 1去掉// ReplaceExceptWithAntiJoin:// 将EXCEPT换成DISTINCT a1, a2 .. LEFT ANTI JOIN .. ON ..// ReplaceDistinceWithAggregate:// 将DISTINCT a1, a2 换为 GROUP BY a1, a2, a3// foldablePropagation:// 将 GROUP BY a1, a2, a3 换成 GROUP BY a1, a2, 'custom'SELECT DISTINCT a1, a2, 'custom' a3FROM (SELECT * FROM t1 WHERE a2 = 10 AND 1 = 1) WHERE a1 > 5 AND 1 = 1EXCEPT SELECT b1, b2, 1.0 b3 FROM t2 WHERE b2 = 10;
Q3: 实现自定义Catalyst优化规则(静默规则)
import org.apache.spark.sql.{SparkSession, SparkSessionExtensions}import org.apache.spark.sql.catalyst.plans.logical.LogicalPlanimport org.apache.spark.sql.catalyst.rules.Ruleimport org.apache.spark.sql.catalyst.expressions._case class MultiplyOptimizationRule(spark: SparkSession) extends Rule[LogicalPlan] {def apply(plan: LogicalPlan): LogicalPlan = plan transformAllExpressions {case Multiply(left, right, failOnError)if right.isInstanceOf[Literal] && right.asInstanceOf[Literal].value.asInstanceOf[Int] == 1=> leftcase Multiply(left, right, failOnError)if left.isInstanceOf[Literal] && left.asInstanceOf[Literal].value.asInstanceOf[Int] == 1=> right}}class MultiplyOptimization extends (SparkSessionExtensions => Unit) {override def apply(extensions: SparkSessionExtensions): Unit = {extensions.injectOptimizerRule { session =>MultiplyOptimizationRule(session)}}}// 通过spark.sql.extensions 提交,将jar包放入spark的classPath// bin/spark-sql --jars bigdata-camp.jar --conf spark.sql.extensions=MultiplyOptimizationRule

若有收获,就点个赞吧
0 人点赞
