AQE
在3.0之前的版本中,Spark仅仅在编译时基于规则和策略遍历AST查询语法树,来优化逻辑计划,一旦基于最佳逻辑计划选定物理执行计划,Spark就会严格遵照物理计划的步骤去机械的执行计算
而AQE可以让Spark在运行时的不同阶段,结合实时的运行时状态,周期性的动态调整前面的逻辑,然后根据再优化的逻辑计划,重新选定最优的物理计划,从而调整运行时后续阶段的执行方式
优化1.自动分区:分布式数据集过滤之后,难免有些数据分片内容所剩无几
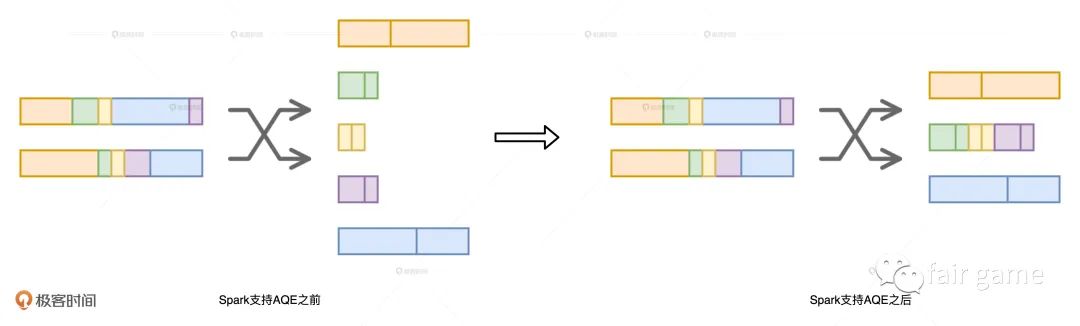
优化2.数据倾斜:如果AQE发现某张表存在倾斜的数据分片,就会自动对它做加盐处理,也就是强行给倾斜的Key添加随机前缀,然后把Key打散
优化3.Join策略调整:当两个有序表要进行数据关联的时候,Spark SQL在优化过程中会选择Sort Merge Join的实现方式。但有一种情况,其中一个表要在排序前先过滤,过滤到足够小以后由广播变量容纳,这个时候Broadcast Join则效率更高。AQE会根据运行时候的统计数据,动态调整Join策略
怎么利用这些优势?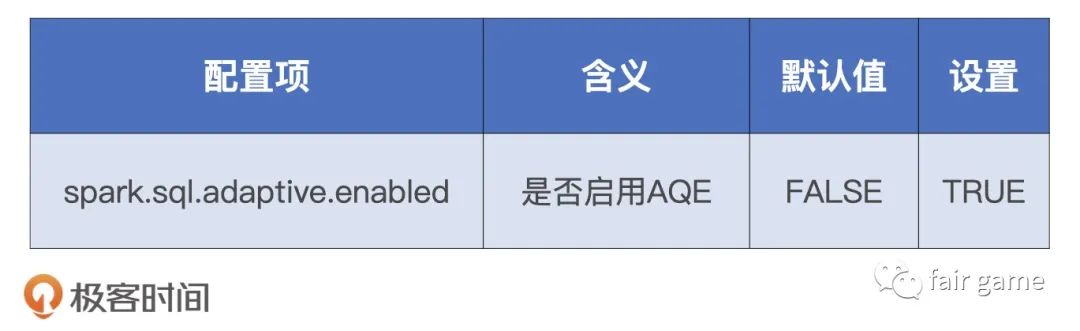

若有收获,就点个赞吧
0 人点赞
