配置项3类:
硬件资源,Shuffle类和Spark SQL大类
并行度:
出发点是数据,明确了数据划分的粒度。并行度越高,数据的粒度越细,数据分片越多,数据越分散
并行度设置:
spark.default.parallelism:
new SparkConf().set("spark.default.parallelism", "10")// rdd2的分区数是10,rdd1的分区数不受这个参数的影响val rdd2 = rdd1.reduceByKey(_+_)
spark.default.parallelism与spark.sql.shuffle.partitions区别
spark.default.parallelism只有在处理RDD时才会起作用,对Spark SQL的无效。
spark.sql.shuffle.partitions则是对sparks SQL专用的设置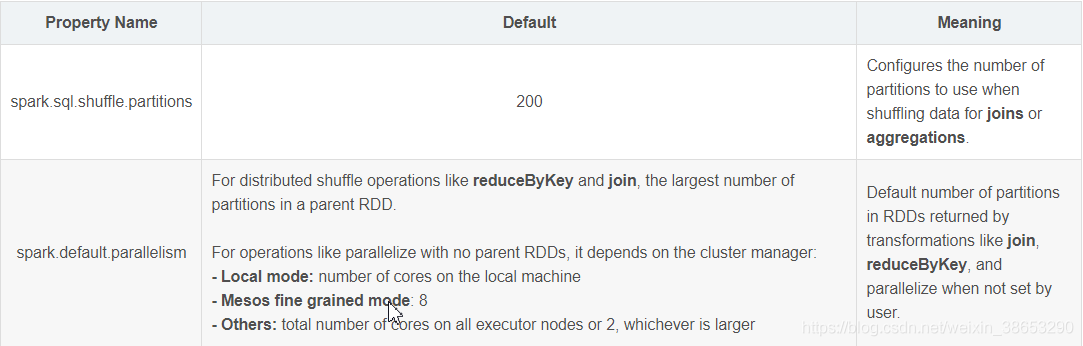
textFile(), 传入第二个参数,指定partition数量(比较少用)
官网推荐:spark-submit脚本中
指定app总共要启动多少个executor,100个;
每个executor多少个cpu core,2~3个;
即总共app有cpu core 200个。根据总cpu core数量,设置spark.default.parallelism参数,指定为cpu core总数的2~3倍,即400~600个并行度;
并行度设置生效问题:
如果没有使用Spark SQL(DataFrame),那么整个app默认所有stage并行度都是设置的值(除非使用coalesce或repartition缩减过partition的数量)
如果使用了spark SQL,那么spark SQL的并行度没法自己指定,spark SQL会默认根据hive表对应的hdfs文件的block,自动设置spark SQL查询所在的那个stage的并行度。这种情况,用spark SQL这一步的并行度和task数量是没发改变的,但可以通过repartition算子,将spark SQL查询出来的RDD,进行重新分区
并行计算任务:
任一时刻整个集群能够同时计算的任务数量,出发点是计算任务,是CPU。Executor并行计算任务上限是Executor-tasks = spark.executor.cores spark.task.cpus(默认为1)。则整个集群并行计算任务上限是Executor-tasks Executor数量
就Executor的线程池来说,尽管线程本身可以复用,但每个线程在同一时间只能计算一个任务,每个任务负责处理一个数据分片。因此,在运行时,一个线程对应一个任务,一个任务对应一个数据分片
并行度决定数据粒度,数据力度决定分区大小,分区大小决定每个计算任务的内存消耗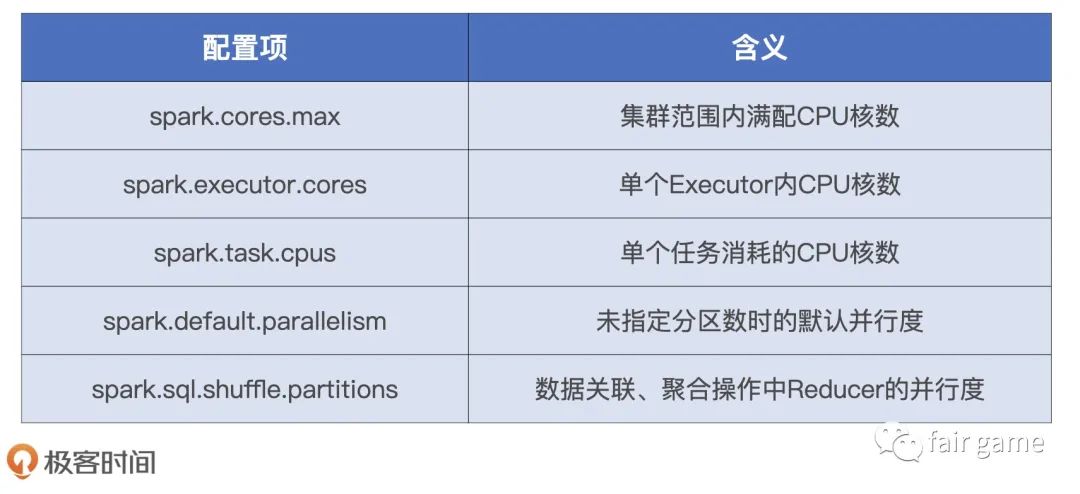
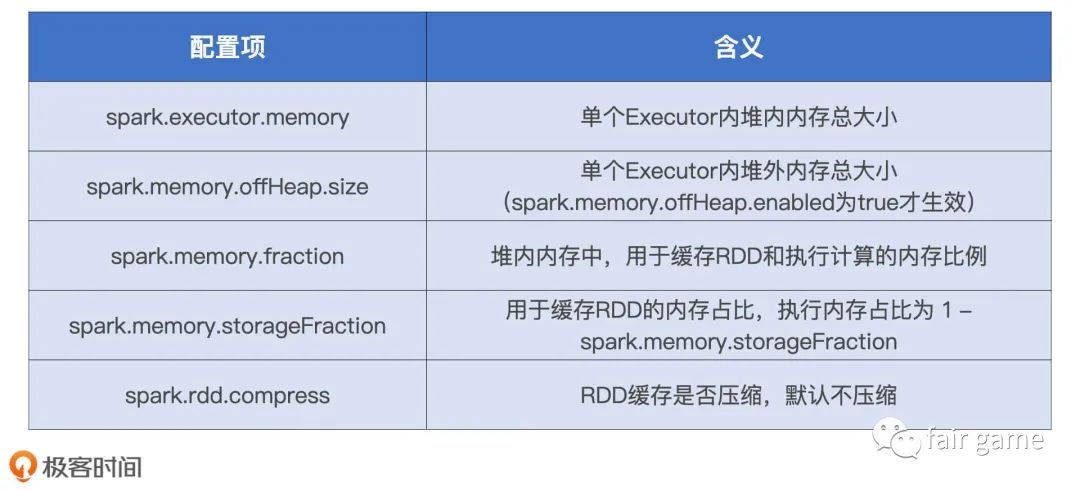
内存设置:Execution Memory和Storage Memory
要想要启用堆外内存,我们得先把参数 spark.memory.offHeap.enabled 置为 true,然后用 spark.memory.offHeap.size 指定堆外内存大小。
对于需要处理的数据集,如果数据模式比较扁平,而且字段多是定长数据类型,则使用堆外内存。相反,如果数据模式很复杂,嵌套结构或变长字段很多,就采用JVM堆内内存
userMemory & spark可用内存
spark.memory.fraction明确Spark可支配内存占比,1-spark.memory.fraction则是User memory在堆内内存的占比
spark.memory.fraction默认值是0.6,也就是JVM堆内空间的60%会划拨给Spark支配,剩下的40%划拨给user memory
Execution Memory & Storage Memory
统一内存管理模式下,spark.memory.storageFraction就无关紧要,因为执行任务会抢占缓存内存。但如果是缓存密集型任务,则可以调节这个参数来保证全量缓存。默认为占据Executor60%的内存
但在这个过程中,要注意引起full GC从而影响执行效率(如果storageMemory设置太大,导致executionMemory太小,会引起full GC;而storageMemory设置太小,会导致数据无法缓存,而写磁盘);
为了提升RDD cache访问效率,则以对象值的方式存储,从而避免序列化和反序列化,但是full GC更易引发。如果该用序列化的方式存储,则设置spark.rdd.compress
数据分片平均大小在 (M/N/2, M/N)之间
M为execution memory总量
N为线程总数:spark.executor.coresspark.task.cpusexecutor数量
在这里用的是N~,含义是executor内当前的并发度,也就是executor中当前并行执行的任务数,N~<N(excutor中有N个CPU线程,但这N个线程不一定都在干活。在Spark任务调度的过程中,这N个线程不见的同时拿到分布式任务,后拿到任务的线程甚至连一寸内存都申请不到。而每个线程能够申请到多大的内存,取决于每个task需要处理的数据分片的大小。 如果分布式数据集的并行度设置得当,因任务调度滞后而导致的线程挂起问题就会得到缓解。但数据分片越多,数据越分散,调度开销也会增加)
M-下限是Execution Memory初始值:
堆内执行内存的初始值由很多参数共同决定,具体的计算公式是:spark.executor.memory spark.memory.fraction (1 - spark.memory.storageFraction)。相比之下,堆外执行内存的计算稍微简单一些:spark.memory.offHeap.size (1 - spark.memory.storageFraction)
M-上限是spark.executor.memory spark.memory.fraction
预估内存占用
首先,我们来说内存占用的预估,主要分为三步。
第一步,计算 User Memory 的内存消耗。
#User = #size * Executor线程池大小
#size 应用中包含的自定义数据结构
第二步,计算 Storage Memory 的内存消耗。
#bc 广播变量
#cache 分布式数据集缓存
#E Executor总数
#Storage = #bc + #cache / #E
第三步,计算User Memory的消耗。
#threads Executor线程池大小
#dataset 数据集尺寸
#N 并行度
#Execution = #threads * #dataset / #N
其次,调整内存配置项
(spark.executor.memory - 300MB)spark.memory.fractionspark.memory.storageFraction
spark.memory.fraction = (#Storage + #Execution) / (#User + #Storage + #Execution)
spark.memory.storagetFraction = (#Storage) / (#Storage + #Execution)
对于Executor堆内内存总大小spark.executor.memory的设置,要考虑4个内存区域的总消耗:300MB + #User + #Storage + #Execution
运行资源优化配置
-num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
-executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors * executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同事的作业无法运行。
-executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同事的作业运行。
-driver-memory
参数说明:该参数用于设置Driver进程的内存。
参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理(或者是用map side join操作),那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
-spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量,也可以认为是分区数。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多人常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
-spark.storage.memoryFraction
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。
参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
-spark.shuffle.memoryFraction
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。
参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。

若有收获,就点个赞吧
0 人点赞
