Spark存储
包括Shuffle中间文件(磁盘),RDD Cache(内存或磁盘)以及广播变量(内存)
Spark内存区域划分
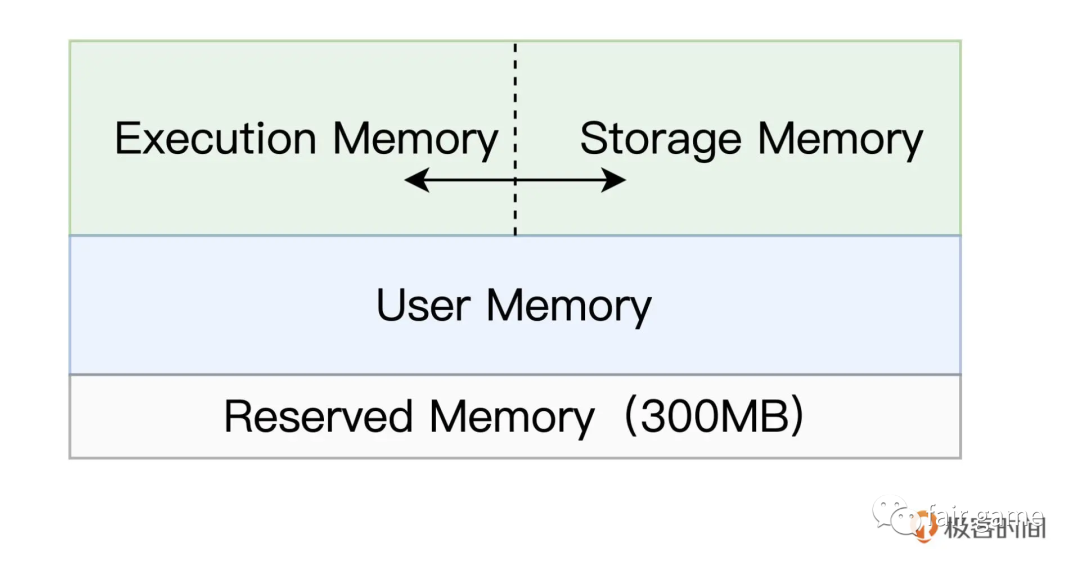
Reserved Memory: 固定为300M,不受开发者控制,是Spark预留的,用来存储各种Spark内部对象的内存区域
User Memory: 存储开发者自定义的数据结构,例如RDD算子中引用的数组,列表,映射
Execution Memory: 用来执行分布式任务,包括数据的转换,过滤,映射,排序,聚合的内存消耗
Storage Memory: 缓存分布式数据集,如RDD Cache(RDD物化到内存中的副本),广播变量等
内存区域的相互转化:如若没有缓存任何RDD或广播变量,将未使用的Storage Memory转化成Execution Memory
1.如果对方的内存空间有空闲,双方可以互相抢占;
2.对于 Storage Memory 抢占的 Execution Memory 部分,当分布式任务有计算需要时,Storage Memory 必须立即归还抢占的内存,涉及的缓存数据要么落盘、要么清除;
3.对于 Execution Memory 抢占的 Storage Memory 部分,即便 Storage Memory 有收回内存的需要,也必须要等到分布式任务执行完毕才能释放。
内存管理
Driver进程的BlockManagerMaster
Executor进程的BlockManager,MemoryStore,DiskStore
“一言堂”,BlockManager想要获得其他BlockManager的信息,必须要通过BlockManagerMaster得到
元数据本身是由driver的blockManageMaster来管理,当每个excutor创建的时候也会创建相对应的数据集管理服务blockManagerSlave,当使用某一些block时候,slave端会创建block并向master端去注册block,同理删除某些block时候,master向slave端发出申请,再有slave来删除对应的block数据。由此可见,实际上物理数据都excutor上,数据的关系管理由driver端来管理。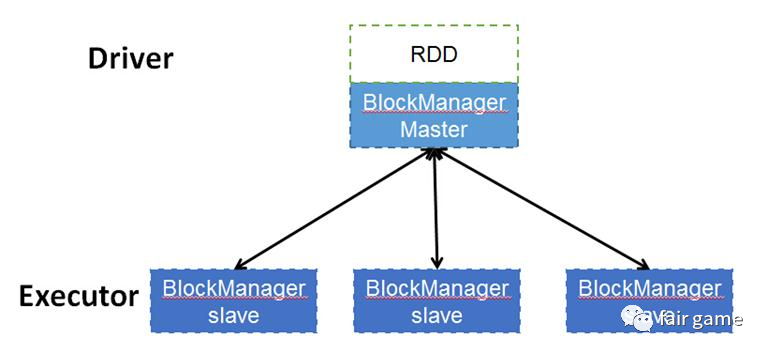
BlockManager的核心职责,在于管理数据块的元数据Meta data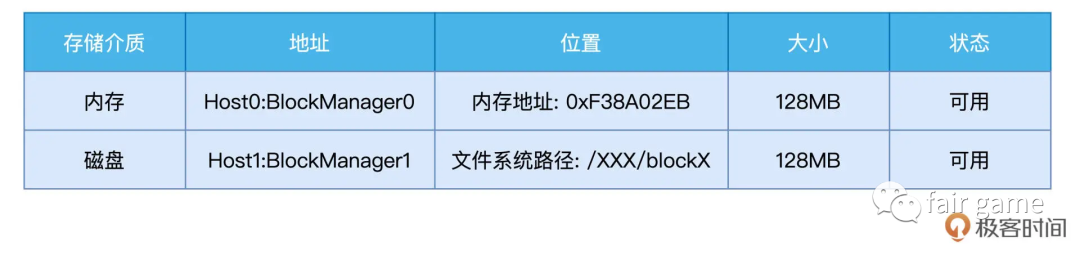
MemoryStore内存数据访问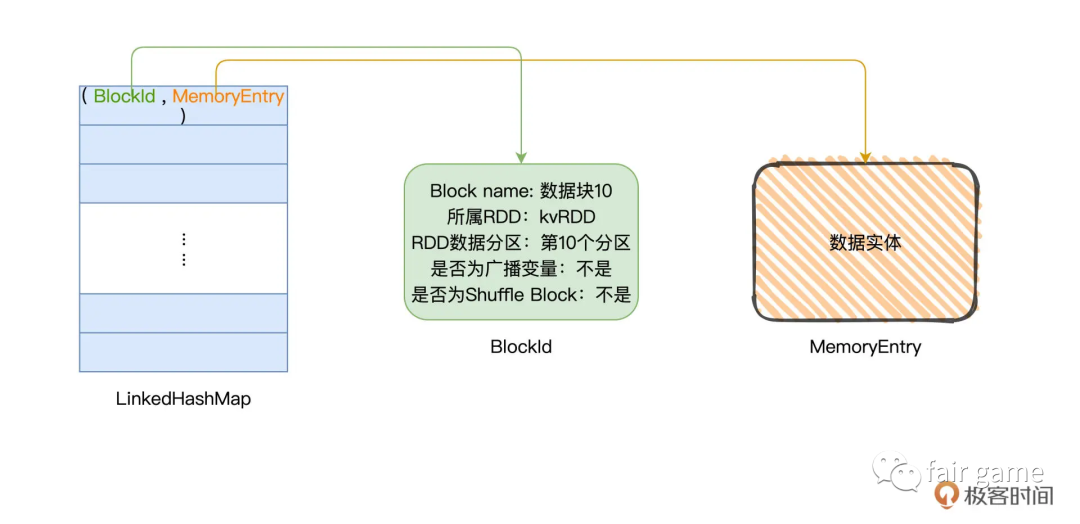
BlockId不仅仅是一个ID字符,而是一种记录Block原数据的数据结构
MemoryEntry是对象,通往数据实体的地址,承载数据实体,这个数据实体可以是某个RDD的数据分区,或是广播变量
以RDD Cache为例:
1.以数据分区为粒度,计算RDD执行结果,生成对应的数据块
2.将数据块封装到MemoryEntry,同时创建数据块元数据BlockId
3.将(BlockId, MemoryEntry)键值对添加到LinkedHashMap中
DiskStore磁盘数据访问:通过DiskBlockManager类对象,getFile方法以BlockId为参数,返回磁盘文件
以Shuffle为例: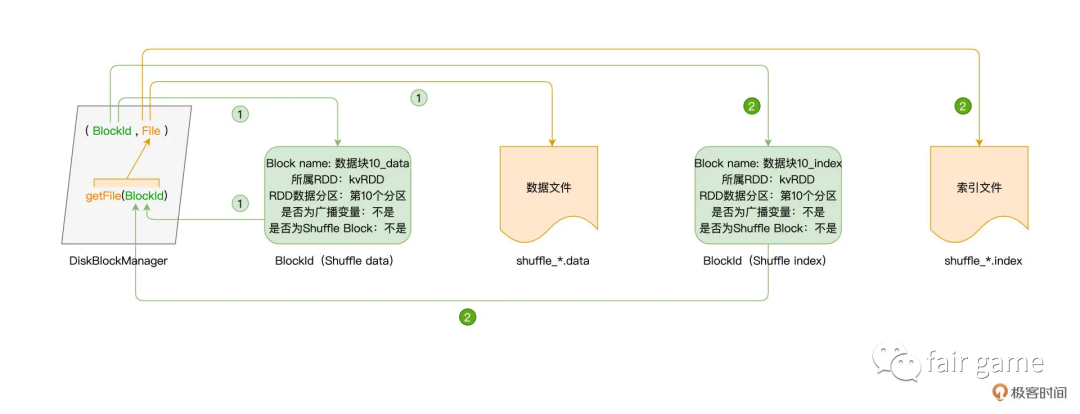

若有收获,就点个赞吧
0 人点赞
