Spark核心概念😺 RDD弹性分布式数据集
什么是RDD?
RDD是一种对于分布式数据集的抽象,它用于囊括所有内存中和磁盘中的分布式数据实体
三个特性:分片,并行,不可变
分片:partitioner分片规则 和 partitions数据分片:可以认为RDD是一个大的数组,数组中的每一个元素代表一个分区,每个分区指向一个存放在内存或者硬盘中的数据块,这些数据块相互独立,可以被存放在系统的不同节点中。在各个节点上的数据块会尽可能的存放在内存中,只有当内存没有空间时才会存入硬盘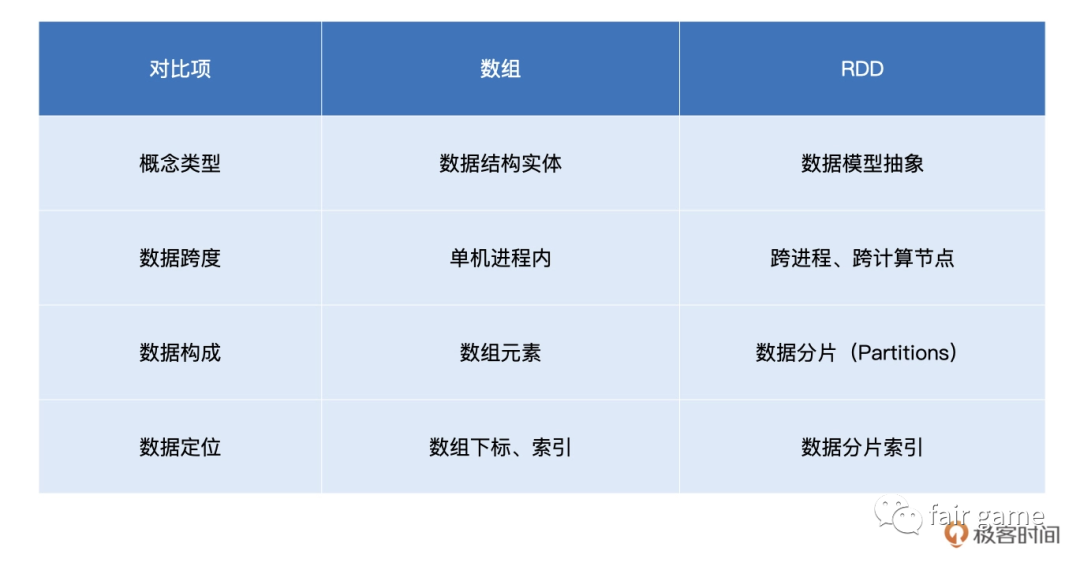
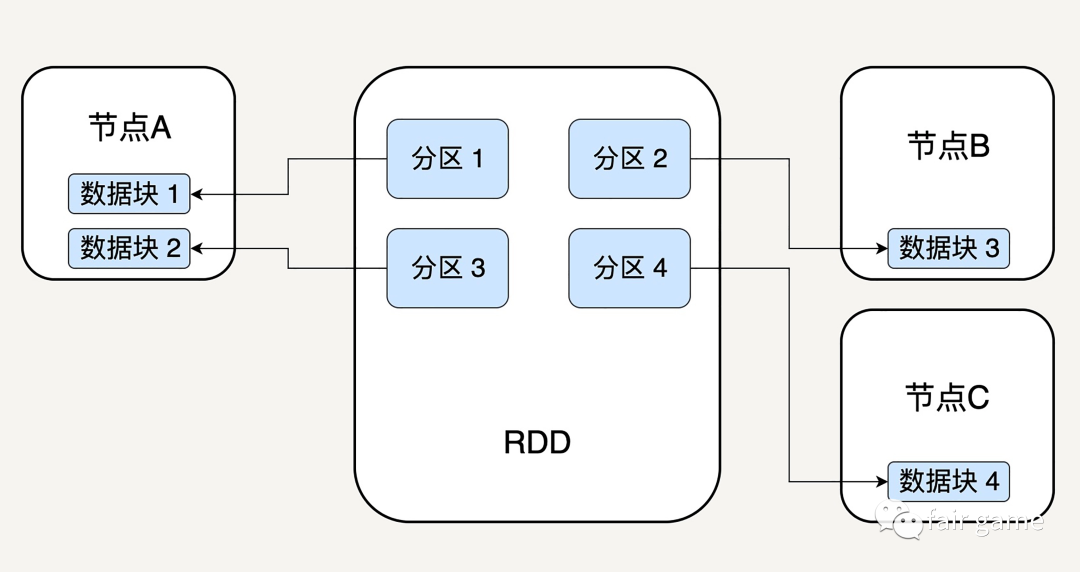
为了充分利用每一颗土豆、降低生产成本,工坊使用 3 条流水线来同时生产 3 种不同尺寸的桶装薯片。3 条流水线可以同时加工 3 颗土豆,每条流水线的作业流程都是一样的,分别是清洗、切片、烘焙、分发和装桶。
这里的每一种食材形态,带泥土豆,干净土豆等,都可以看成是一个个的RDD。薯片的制作过程,可以看作不同食材形态的转换过程
1.食材按照什么规则被分配到哪条流水线,带泥土豆是随机拿取,而分发的即食薯片是按大,中,小号做分发的。即分发的即食薯片的partitioner属性,重新定义了这个RDD数据分片的切割规则
目前有两种主流的分区方式:Hash partitioner对数据的Key进行散列分区,和Range partitioner按照Key的排序进行均匀分区。还可以创建自定义partitioner
2.同一种食材在不同流水线上的产物,如麻袋里的那一个颗颗带泥土豆,即是一个数据分片
并行:分区特性使得天然支持并行,不同节点上的数据可以被分别处理
不可变性:RDD所包含的分区信息不可被改变,只能对现有的RDD进行转换,得到新的RDD作为中间计算结果。因此,我们只需要去记录它通过哪个RDD进行哪些转换而来,不用立刻去具体存储计算出的数据本身。这样,一旦第N步RDD的节点发生故障,数据丢失,我们可以从N-1步的RDD出发,无需重复整个N步计算
dependenciesRDD依赖:每一种食材形态都会依赖上一种形态
依赖分为窄依赖和宽依赖:
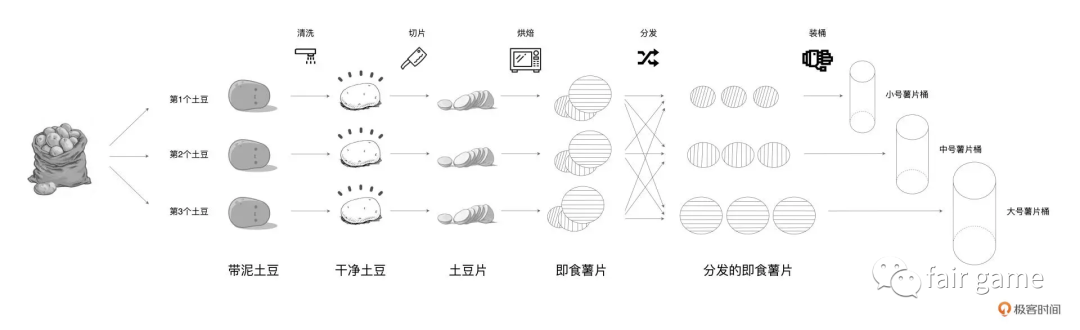
窄依赖允许子RDD的每个分区可以被并行处理,而宽依赖则必须等父RDD的所有分区被计算好之后才能开始处理
如果一个RDD的一个分区,只会影响到下游的一个节点—-窄依赖
如果一个RDD的一个分区,会影响到下游的多个节点—-宽依赖,有Shuffle,父分区数据经过shuflle,如土豆的分发,如GroupByKey, reduceByKey, join等
为什么要区分窄依赖和宽依赖:
1.窄依赖可以支持在同一个节点上链式执行多条命令,例如map后用filter。宽依赖需要所有的父分区都是可用的,可能还需要跨节点传递
2.窄依赖失败恢复更有效,即只需要重新计算父分区即可。宽依赖涉及到RDD各级的多个父分区
宽依赖的故障恢复-检查点机制
在计算过程中,对于一些计算过程比较耗时的RDD,我们可以将它缓存至硬盘或HDFS(相较于HDFS,Spark可以随时把算好的RDD缓存在内存中),标记这个RDD有被检查点处理过,并且清空它的依赖关系。同时给他新建一个依赖于CheckpointRDD的依赖关系,这样,当某个RDD需要错误恢复时,就可以直接去硬盘中读取这个RDD,无需向前回溯计算。
迭代函数:1.判断缓存中是否有需要计算的RDD;2.查找想要计算的RDD是否被检查点处理过;3.调用计算函数向上递归
Spark提供了三种数据处理API:RDD,DataSet, DataFrame;其中DataSet和DataFrame是优化版的RDD,但无论是哪种API或是哪种开发语言,内部都会最终转化为RDD之上的分布式计算。
创建RDD:
1.用parallelize函数封装内部数据
import org.apache.spark.rdd.RDDval words: Array[String] = Array("Spark", "is", "cool")val rdd: RDD[String] = spark.sparkContext.parallelize(words)
该方法创建数据集完全由driver端创建,且创建完成后,需要在全网范围内跨节点,跨进程地分发到其他Executors,所以不适合超大的数据集。若数据体量较大,需要使用外部数据创建RDD。
2.由外部数据创建
import org.apache.spark.rdd.RDDval rootPath: String = _val file: String = s"${rootPath}/wikiOfSpark.txt"// 读取文件内容val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
在Spark应用内定义体量超大的数据集,是不太适合的,因为数据集完全由Driver创建,且创建完成后,还要在全网范围内跨节点,跨进程地分发到其他Executors,会带来性能问题。因此,parallelize API多数用于“小数据”上创建RDD
如果想要在大体量数据上创建RDD,则通过外部数据创建较优
转换Transformation和动作Action 以及 RDD的延迟计算
Word Count代码实现:
// 读取文件内容val// sparkSession是SparkSession的实例,SparkSession在spark-shell中由系统自动创建// spark 2.0版本开始,SparkSession成为统一的开发入口lineRDD: RDD[String] = sparkSession.sparkContext.textFile(file)// 以行为单位做分词val// RDD[String]可以看成是一个数组,RDD[Array[String]]可以看成一个二位数组// flatMap可以分为两个步骤:映射和展平wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))// 过滤掉空字符串valcleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))// 把RDD元素转换为(Key,Value)的形式valkvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))// 按照单词做分组计数val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)// 始终未计算,直到...// 打印词频最高的5个词汇wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)
我们的任何一个数据集,进行一次转换就是一个新的RDD,但是这个RDD并不需要实际输出到硬盘上,也不会作为一个完整的数据集缓存在内存中,而只是一个RDD的抽象概念
RDD算子类型1-Transformations: 每一个RDD都代表着分布式数据形态,wordCount的实现过程,也就是不同的RDD之间数据形态上的转化过程。Transformations类算子,是在运用有向无环图DAG定义并描述数据形态的转换过程
RDD算子类型2-Actions: 以回溯的方式去触发Transformations类算子构建的有向无环图DAG
也就是说,在调用各类Transformations算子的时候,并不立即执行计算,当且仅当开发者调用Actions算子时,之前调用的转换算子才会付诸执行,然后将结果传递给driver—-延迟计算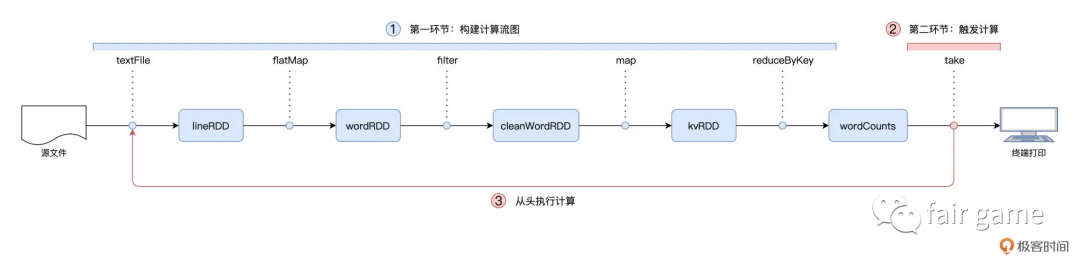
为什么需要延迟计算?
假如,你要从一个很大的文本文件中筛选出包含某个词语的行,然后返回第一个这样的文本行。你需要先读取textFile()生成rdd1,然后使用filter()生成rdd2,最后是一个Action()操作first(),返回第一个元素
读取文件的时候,会把所有的行都存储起来,但我们马上就要筛选出只具有特定词组的行了,等筛选出来以后,又要输出第一个,这样不是太浪费存储空间了?所以实际上,Spark在Action操作first()的时候才开始真正的运算:只扫描第一个匹配的行,不需要读取整个文件。

若有收获,就点个赞吧
0 人点赞
