广播变量
用法
val list: List[String] = List("Apache", "Spark")// sc为SparkContext实例val bc = sc.broadcast(list)
解决的问题
import org.apache.spark.rdd.RDDval rootPath: String = _val file: String = s"${rootPath}/wikiOfSpark.txt"// 读取文件内容val lineRDD: RDD[String] = spark.sparkContext.textFile(file)// 以行为单位做分词val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))// 创建单词列表listval list: List[String] = List("Apache", "Spark")// 使用list列表对RDD进行过滤val cleanWordRDD: RDD[String] = wordRDD.filter(word => list.contains(word))// 把RDD元素转换为(Key,Value)的形式val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))// 按照单词做分组计数val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)// 获取计算结果wordCounts.collect// Array[(String, Int)] = Array((Apache,34), (Spark,63))
单词列表list是在driver端创建的,因此,Spark需要把list变量分发给每一个分布式任务,也就是说,系统中有多少个task,变量就会在网络中分发多少次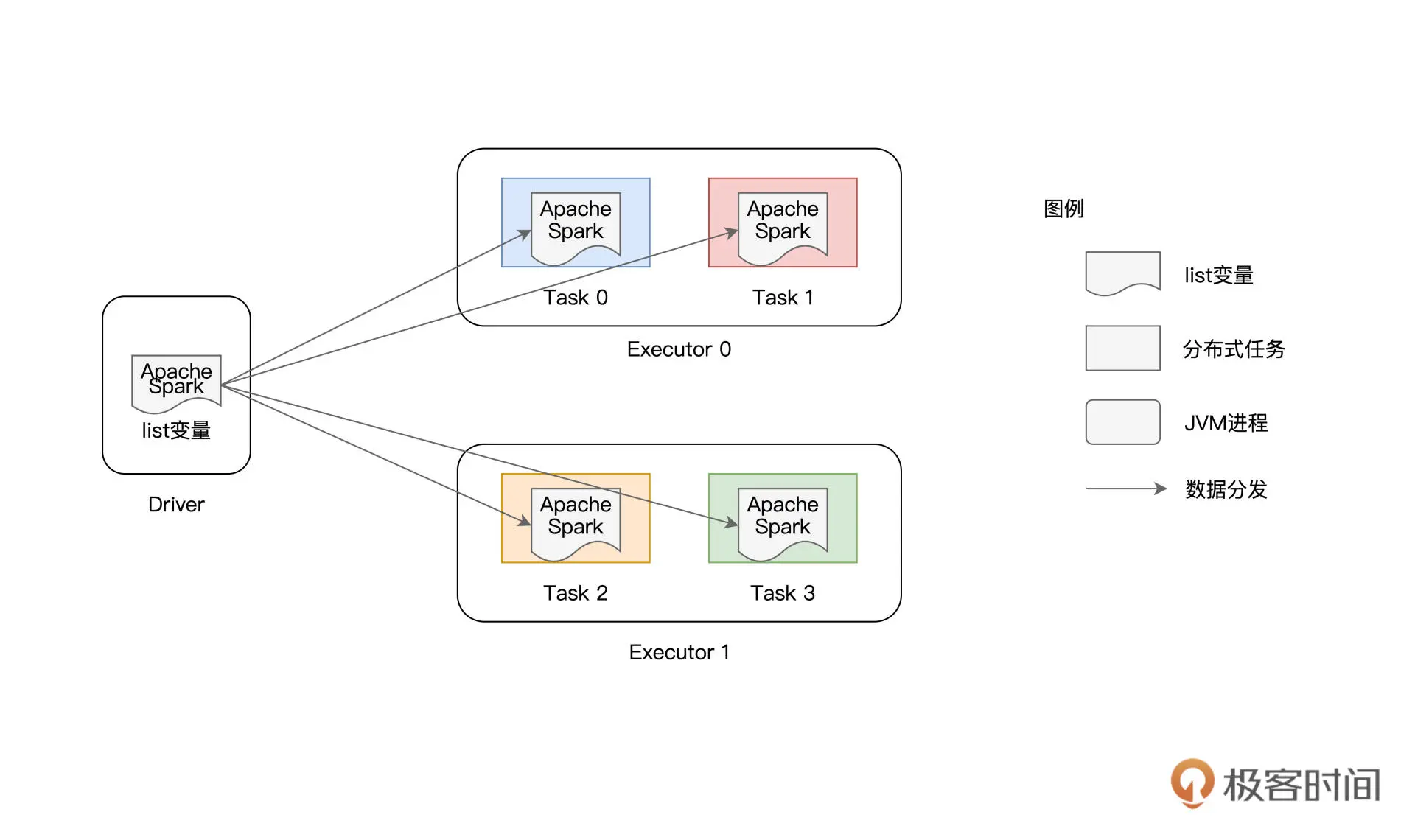
广播变量的分发,是以Executor为粒度的,同一个Executor内多个不同的Tasks只需访问一份数据拷贝即可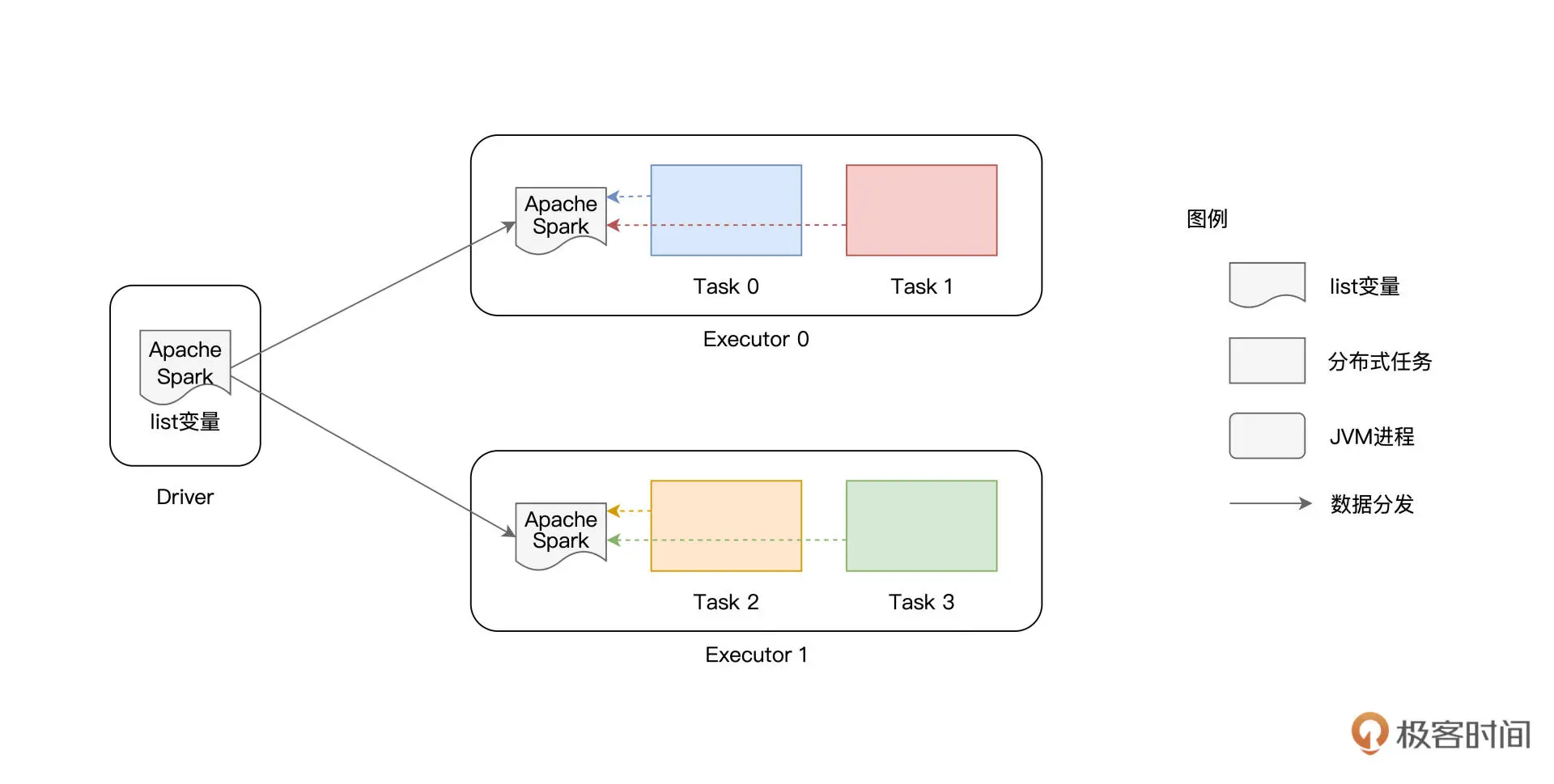
累加器
工作原理
主要作用是全局计数,与单机系统不同,在分布式系统中,我们不能依赖简单的普通变量来完成全局计数
与广播变量类似,累加器也是在Driver端定义的,但它的更新是通过在RDD算子中调用add函数完成的。在应用执行完毕之后,开发者在Driver端调用累加器的value函数,就能获取全局计数结果
import org.apache.spark.rdd.RDDval rootPath: String = _val file: String = s"${rootPath}/wikiOfSpark.txt"// 读取文件内容val lineRDD: RDD[String] = spark.sparkContext.textFile(file)// 以行为单位做分词val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))// 定义Long类型的累加器val ac = sc.longAccumulator("Empty string")// 定义filter算子的判定函数f,注意,f的返回类型必须是Booleandef f(x: String): Boolean = {if(x.equals("")) {// 当遇到空字符串时,累加器加1ac.add(1)return false} else {return true}}// 使用f对RDD进行过滤val cleanWordRDD: RDD[String] = wordRDD.filter(f)// 把RDD元素转换为(Key,Value)的形式val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))// 按照单词做分组计数val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)// 收集计数结果wordCounts.collect// 作业执行完毕,通过调用value获取累加器结果ac.value// Long = 79

若有收获,就点个赞吧
0 人点赞
