Cache工作原理
存储级别
最常用的:MEMORY_ONLY和MEMORY_AND_DISK
存储介质:内存还是磁盘,或者两者都有
存储形式:对象值还是序列化的字节数组,带SER或不带SER
副本数量:MEMORY_AND_DISCK_SER_2, 不带数字默认为1份副本
在RDD和DataFrame上调用.cache,Spark默认采用MEMORY_ONLY和MEMORY_AND_DISK
缓存的计算过程
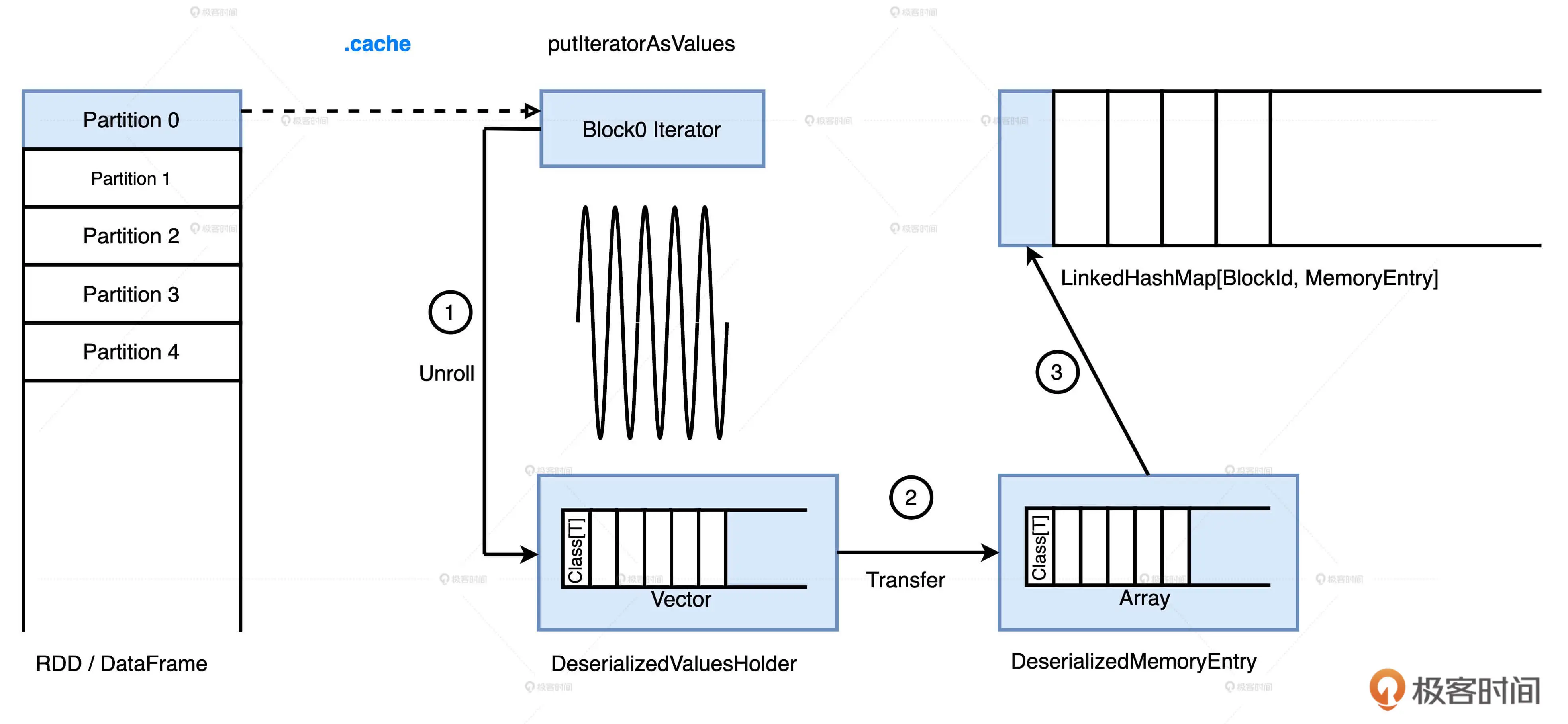
无论是RDD还是DataFrame,他们的数据分片都是以迭代器Iterator的形式存储的。
Unroll-把迭代器展开成实实在在的数据值。展开的对象暂存在一个叫做ValuesHolder的数据结构里,Transfer-然后转换为MemoryEntry,转换的实现方式是toArray,因此它不产生额外的内存开销。
最终,MemoryEntry和与之对应的BlockId,以Key,Value的形式存储在LinkedHashMap中
缓存的销毁过程-Eviction
Spark使用LinkedHashMap来存储BlockId和MemoryEntry键值对,来支持LRU算法销毁缓存
LinkedHashMap 使用两个数据结构来维护数据,一个是传统的 HashMap,另一个是双向链表。HashMap 的用途在于快速访问,根据指定的 BlockId,HashMap 以 O(1) 的效率返回 MemoryEntry。双向链表则不同,它主要用于维护元素(也就是 BlockId 和 MemoryEntry 键值对)的访问顺序。凡是被访问过的元素,无论是插入、读取还是更新都会被放置到链表的尾部。因此,链表头部保存的刚好都是“最近最少访问”的元素
在清除的过程中,同属于一个RDD的MemoryEntry会被跳过
Cache滥用,退化为MapReduce
相比MEMORYONLY,MEMORY_AND_DISK模式能够保证数据集100%地物化到存储介质。对于计算链条较长的RDD或是DataFrame来说,把数据物化到磁盘也是值得的。但,如果cache滥用,内存计算将退化为Hadoop MapReduce根据磁盘的计算模式:
比如说,你用 DataFrame API 开发应用,计算过程涉及 10 次 DataFrame 之间的转换,每个 DataFrame 都调用.cache进行缓存。由于 Storage Memory 内存空间受限,MemoryStore 最多只能容纳两个 DataFrame 的数据量。因此,MemoryStore 会有 8 次以 DataFrame 为粒度的换进换出。最终,MemoryStore 存储的是访问频次最高的 DataFrame 数据分片,其他的数据分片全部被驱逐到了磁盘上。也就是说,平均下来,至少有 8 次 DataFrame 的转换都会将计算结果落盘,这不就是 Hadoop 的 MapReduce 计算模式吗?_
何时启用Cache
- 如果RDD/DataFrame/DataSet在应用中的引用次数为1,坚决不使用Cache
- 如果引用次数大于1,且运行成本占比超过30%,应当考虑启用Cache
运行成本占比:计算某个分布式数据集所消耗的总时间与作业执行时间的比值
假设我们有个数据分析的应用,端到端执行时间为1小时。应用中有个DataFrame被引用了2次,从读取数据源,经过一系列计算,到生成这个DataFrame需要花费12分钟,那么这个DataFrame的运行成本占比为:12 * 2 / 60 = 40%
DataFrame的运行时间,可以用Noop来计算:假设 df 是那个被引用 2 次的 DataFrame,我们就可以把 df 依赖的所有代码拷贝成一个新的作业,然后在 df 上调用 Noop 去触发计算。Noop 的作用很巧妙,它只触发计算,而不涉及落盘与数据存储,因此,新作业的执行时间刚好就是 DataFrame 的运行时间
Cache注意事项
- .cache是惰性操作,因此需要Action算子,才能出发缓存物化。但是,只有count才回触发缓存的完全物化,first, take, show这3个算子只会把涉及的数据物化
- 哪种cache方式才能触发物化? ```scala // 如果给定包含数十列的 DataFrame df 和后续的数据分析
val filePath: String = _ val df: DataFrame = spark.read.parquet(filePath)
//Cache方式一 val cachedDF = df.cache //数据分析 cachedDF.filter(col2 > 0).select(col1, col2) cachedDF.select(col1, col2).filter(col2 > 100)
//Cache方式二 df.select(col1, col2).filter(col2 > 0).cache //数据分析 df.filter(col2 > 0).select(col1, col2) df.select(col1, col2).filter(col2 > 100)
//Cache方式三
val cachedDF = df.select(col1, col2).cache
//数据分析
cachedDF.filter(col2 > 0).select(col1, col2)
cachedDF.select(col1, col2).filter(col2 > 100)
```
第一种.cache应遵循,最小公共子集原则-开发者仅缓存后续操作必须的那些数据列,因此,1排除
第二种.这两条语句都会跳过缓存,分别去读磁盘上读取parquet源文件,然后从头计算投影和过滤的逻辑-因为Cache Manager要求两个查询的Analyzed Logical Plan必须完全一致,才能对DataFrame的缓存进行复用
Analyzed Logical Plan 是比较初级的逻辑计划,主要负责 AST 查询语法树的语义检查,确保查询中引用的表、列等元信息的有效性。像谓词下推、列剪枝这些比较智能的推理,要等到制定 Optimized Logical Plan 才会生效。因此,即使是同一个查询语句,仅仅是调换了select和filter的顺序,在 Analyzed Logical Plan 阶段也会被判定为不同的逻辑计划
第三种.把想要缓存的数据赋值给一个变量,凡是在这个变量之上的分析操作,都会完全复用缓存数据
清除缓存
.unpersist是.cache的逆操作。unpersist支持同步,异步两种模式:
- 异步调用:unpersist(), unpersist(False)
- 同步调用:unpersist(True)
异步下,Driver清理缓存的请求发送给各个executors之后,立刻返回,处理余下逻辑
同步下,Driver要等到最后一个executor返回,才继续执行driver侧代码

若有收获,就点个赞吧
0 人点赞
