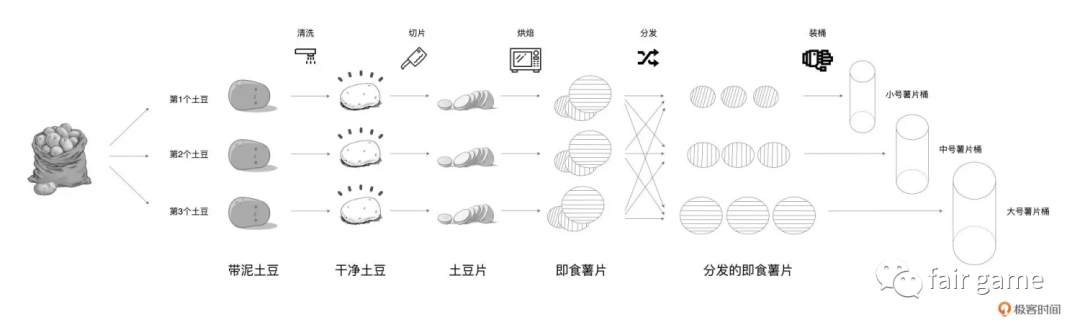
概览
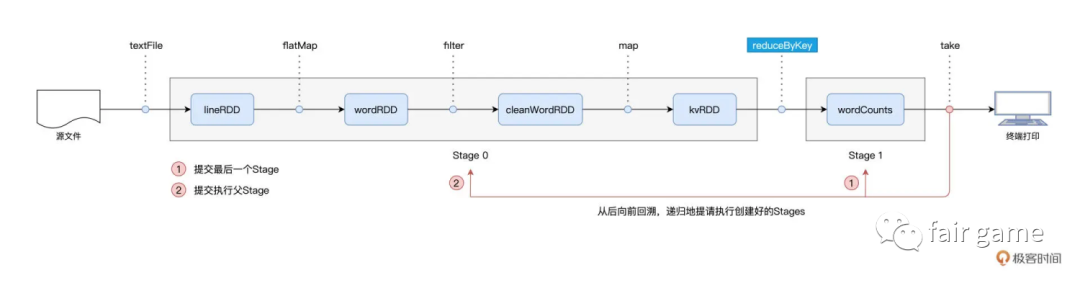
集群范围内跨节点,跨进程的数据分发。是分布式数据集在集群内的分发,会引入大量的磁盘I/O与网络I/O。是一次Map阶段与Reduce阶段的数据交换,是下一个Stage向上一个Stage要数据的过程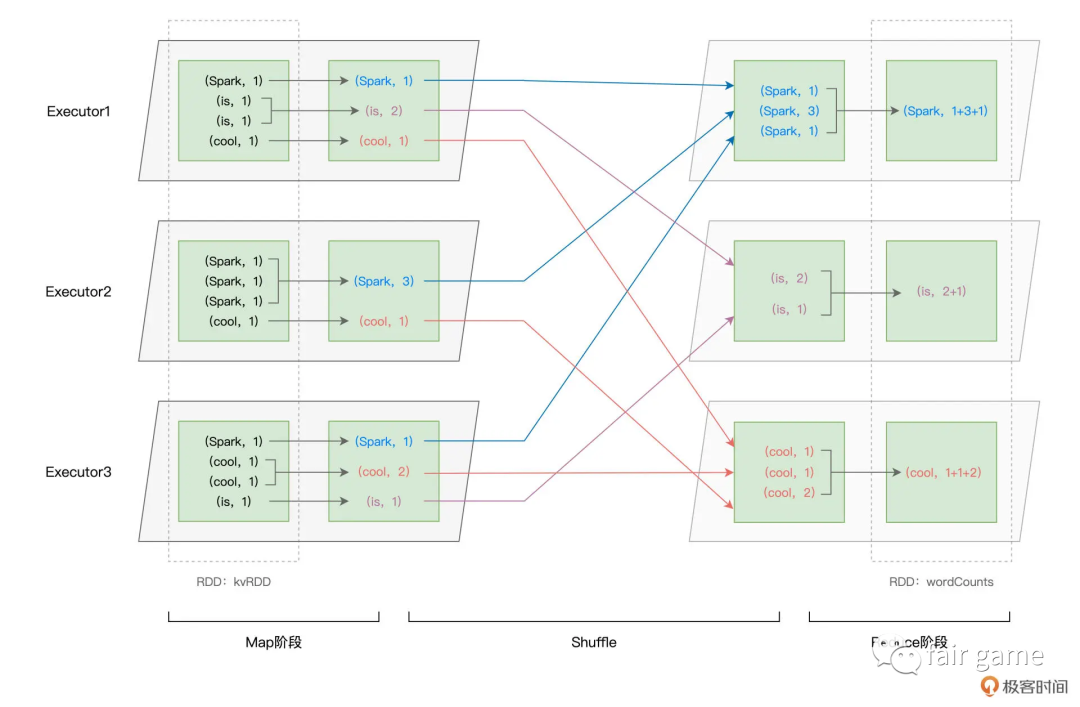
以 Shuffle 为边界,reduceByKey 的计算被切割为两个执行阶段。约定俗成地,我们把 Shuffle 之前的 Stage 叫作 Map 阶段,而把 Shuffle 之后的 Stage 称作 Reduce 阶段。在 Map 阶段,每个 Executors 先把自己负责的数据分区做初步聚合(又叫 Map 端聚合、局部聚合);在 Shuffle 环节,不同的单词被分发到不同节点的 Executors 中;最后的 Reduce 阶段,Executors 以单词为 Key 做第二次聚合(又叫全局聚合),从而完成统计计数的任务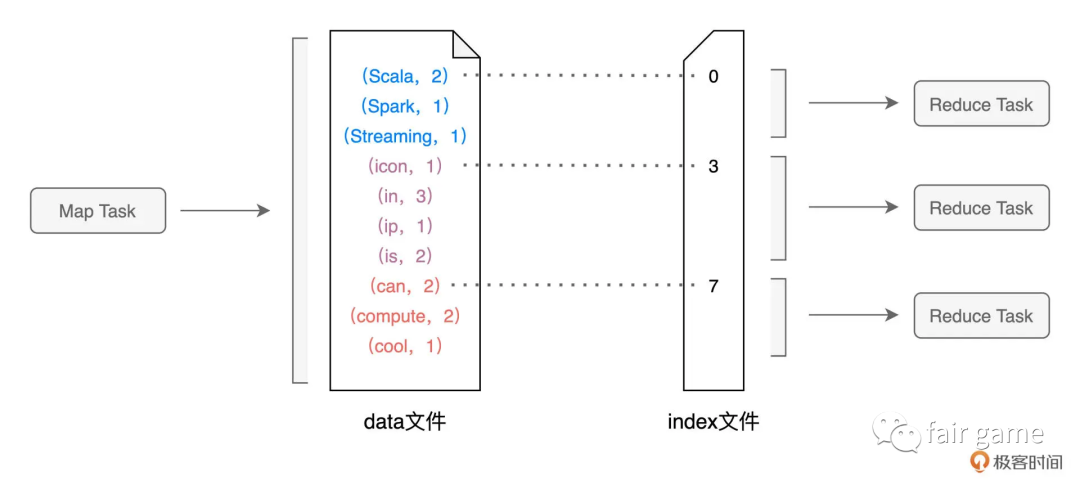
在Map执行阶段,每个Task都会生成包含data文件与index文件的shuffle中间文件。data文件则是记录了(Key, Value)键值对。index文件则是标记data文件中的哪些记录,应该由下游Reduce阶段中的哪些Task消费(数据交换规则:即Reduce阶段的数据分区规则,假设Reduce阶段有N个Task,这N个Task则对应N个数据分区。对于任意一条数据记录,Spark先按照既定的哈希算法,计算记录主键的哈希值,然后把哈希值对N取模,计算得到的结果数字,就是这条记录在Reduce阶段的数据分区编号P,即P = Hash(Record Key) % N)
Shuffle分为2个阶段
Shuffle Write阶段:
任务个数根据RDD的分区数决定
假设从HDFS读取数据,那么RDD分区个数由该数据集的block数决定,也就是一个split对应生成RDD的一个partition
write阶段会将状态以及Shuffle文件的位置等信息封装到MapStatue对象中,然后发送给Driver
(HashShuffle)Shuffle write阶段,每个task根据记录的key进行哈希取模操作,相同结果的记录会写到同一个磁盘中(会先讲数据写入内存缓冲区,当缓冲填满后,才会splill到磁盘)
Shuffle Read阶段:
任务个数可以通过配置 spark.sql.shuffle.partitions决定
read阶段会从Driver拉取MapStatue,解析后开始执行reduce操作
(HashShuffle)Shuffle Read阶段,从各个节点上通过网络拉取到reduce任务所在的节点,然后进行key的聚合或链接等操作。
一般来说,拉取 Shuffle 中间结果的过程是一边拉取一边聚合的。每个 shuffle read task 都会有一个自己的 buffer 缓冲区,每次只能拉取与 buffer 缓冲区相同大小的数据,然 后在内存中进行聚合。聚合完一批数据后,再拉取下一批数据,直到最后将所有数据到拉取完,得 到最终的结果。
Shuffle write
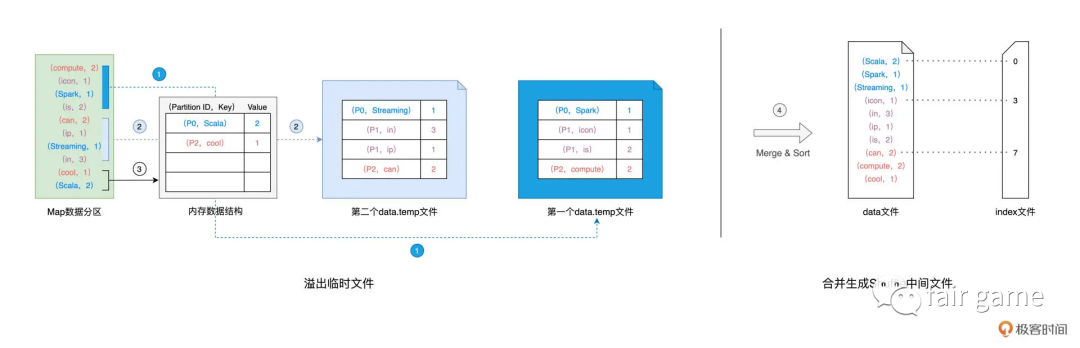
分为hash shuffle和sort based shuffle,以hash shuffle为例
1.对于数据分区中的数据记录,逐一计算其目标分区(一般用既定的hash算法,根据reduceTask数量取模,#reduceTask = #分区),然后填充内存中的Map数据结构(Reduce Task Partition ID, Record Key):ReduceTask需要拉取的数据位置和大小
2.当Map填满后,如果分区中还有未处理的数据记录,就对结构中的数据记录按(目标分区ID,key)排序,讲所有数据溢出到临时文件,同时清空Map
3.直到分区中所有的数据记录都被处理完,所有临时文件和Map中剩余的数据记录做归并排序,生成data文件和index文件
Shuffle read
对于每一个Map阶段的Task生成的中间文件,其目标分区数量是由Reduce阶段的任务数量(即并行度)决定的。而index文件,则标记了目标分区所属数据记录的起始索引。Reduce Task通过网络从不同节点的硬盘中下载并拉取属于自己的数据内容
HashShuffle
每个shuffleMapTask(数量由数据分区决定)产生一个buffer
共需要 #mapTask * #reduceTask 个文件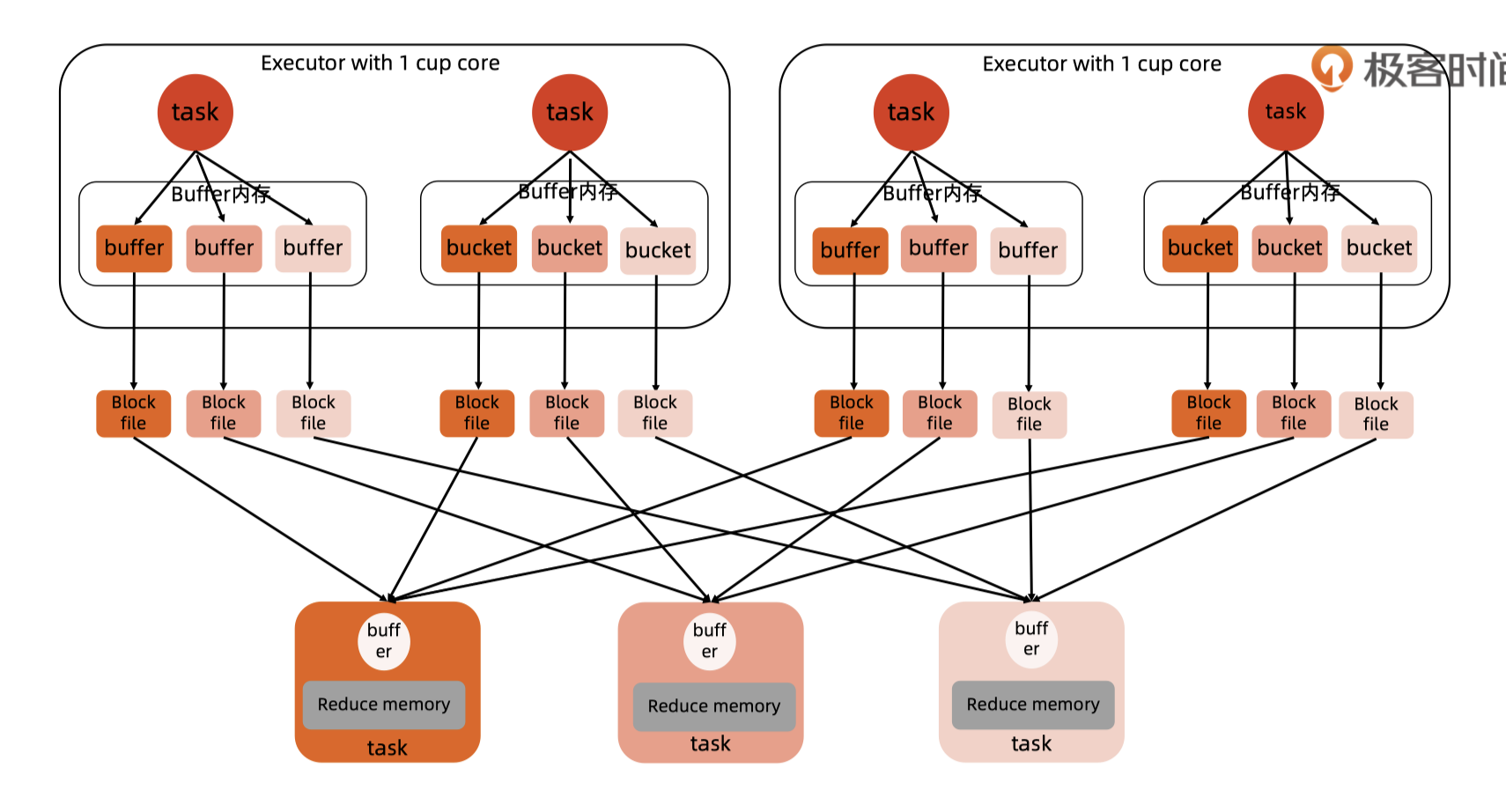
优化后:
每个core会有一个逻辑上的shuffleFileGroup,每个group产生一个buffer
共需要 #mapTask #reduceTask #core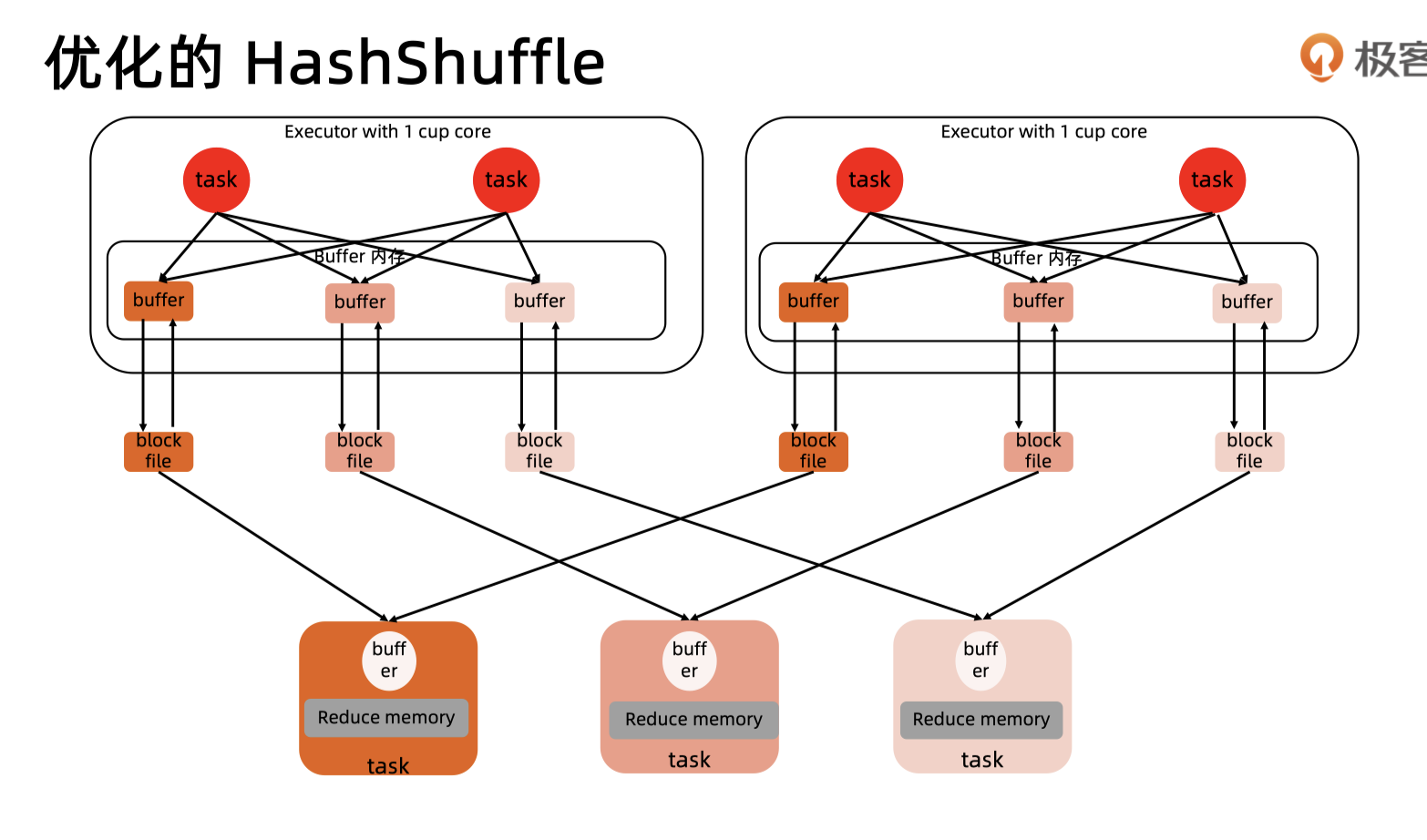
Sort-Based Shuffle
HashShuffle写数据的时候,内存有一个bucket缓冲区,同时在本地磁盘有对应的本地文件,如果有本地文件,那么在内存应该也有文件句柄,这也是要消耗内存的。比如:mapper粉片数量为1000, reducer分片数量为1000,那么总共就要1000000个小文件,这就会有很多内存消耗。而reducer区读时,需要打开很多网络通道,很容易造成reducer(下一个stage)通过driver去拉取上一个stage数据的时候,说文件找不到,其实是程序未响应,因为正在GC
为了缓解shuffle过程中产生文件数量过多和writer缓存开销过大的问题,spark引入了类似于hadoop map-reduce的shuffle机制。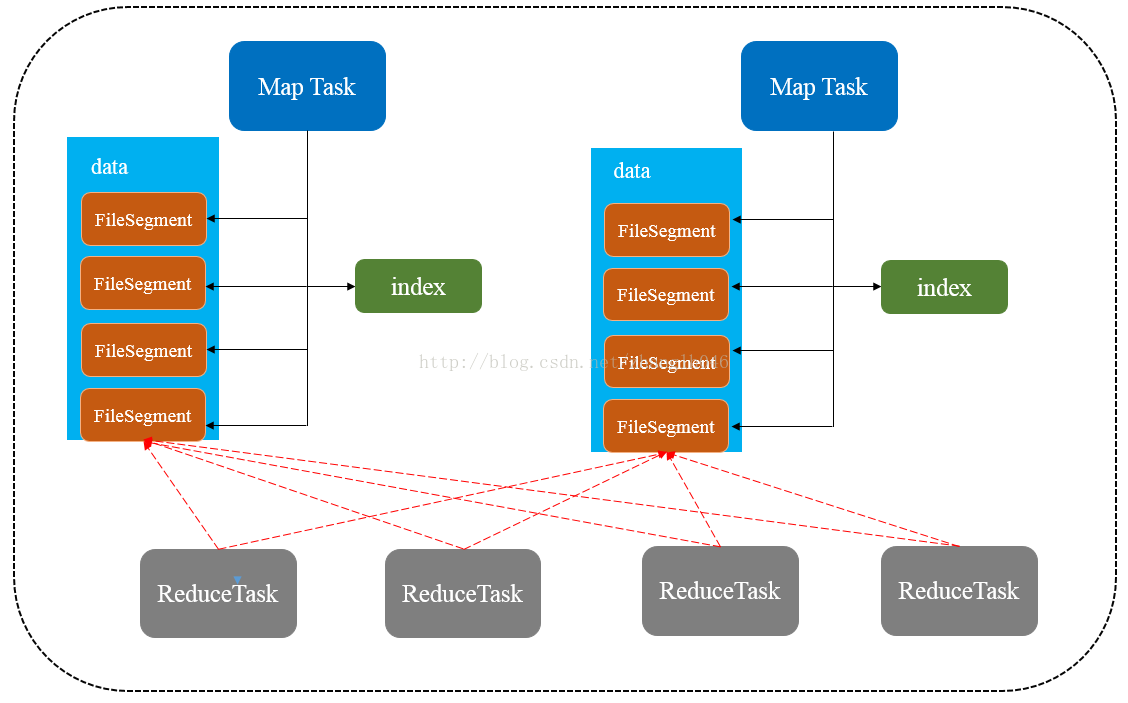
shuffleMapTask不会为shuffleReduceTask创建单独的文件,而是会将所有的Task结果写入同一个文件,并且对应只生成一个索引文件。最后Mapper对每段数据做排序,Reducer对每段数据做归并
- 在数据量很大或集群规模很大时,用SortShufflerWriter
- 在reducer任务数量比较少,且mapper端不需要排序和聚合时,用BypassMergeSortShuffleWriter

若有收获,就点个赞吧
0 人点赞
