spark简要介绍🐶
Spark是一种快速、通用、可扩展的大数据分析引擎,是一种基于内存的大数据并行计算框架。
是MapReduce的替代方案,兼容HDFS和hive,可融入Hadoop的生态系统,以弥补MapReduce的不足
MapReduce的劣势
1.模型的抽象层次低,大量的底层逻辑需要开发者完成
2.很多现实的数据处理场景,并不适合用这个模型来描述:如两个数据集的Join,在MapReduce的世界里,需要对这两个数据集做一次Map和Reduce才能得到结果
3.在Hadoop中,对于多个Job相互依赖情况,每一个Job的计算结果都会存储在HDFS文件存储系统中,所以每一步计算都要进行硬盘的读取和写入,大大增加了系统的延迟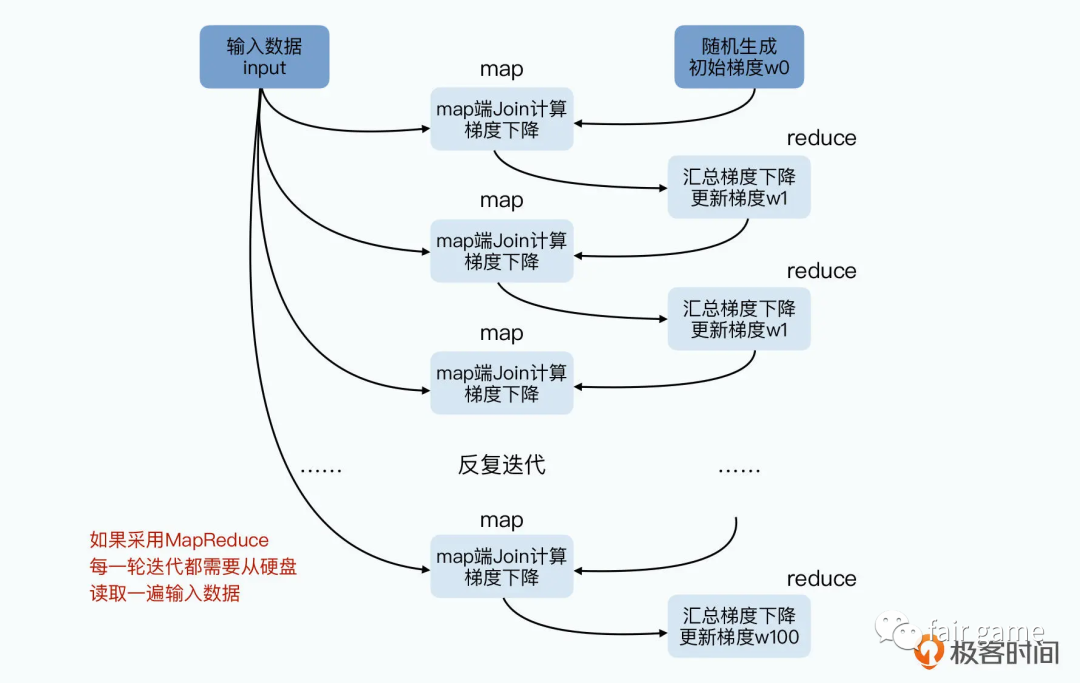
梯度下降法的基本思想可以类比为一个下山的过程。
假设这样一个场景:一个人被困在山上,需要从山上下来(找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低;因此,下山的路径就无法确定,必须利用自己周围的信息一步一步地找到下山的路。这个时候,便可利用梯度下降算法来帮助自己下山。首先以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着下降方向走一步,然后又继续以当前位置为基准,再找最陡峭的地方,再走直到最后到达最低处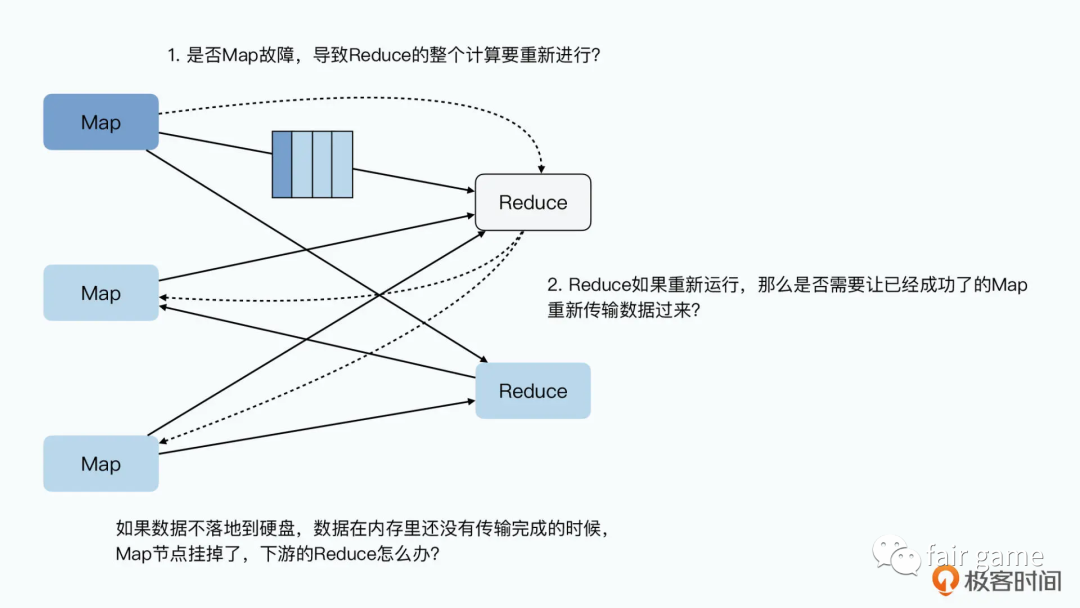
如果不存硬盘,Map或者Reduce节点出现故障了怎么办?任何一个Map节点故障,意味着Reduce只收到了部分数据,而且它还不知道是哪一部分。那么Reduce节点只能失败掉,然后等Map节点重新来过。而且,Reduce的失败,还会导致其他的Map节点计算的数据也要重新来一遍,引起连锁反应
Spark的优势
1.用有向无环图DAG来抽象表达数据处理的多个步骤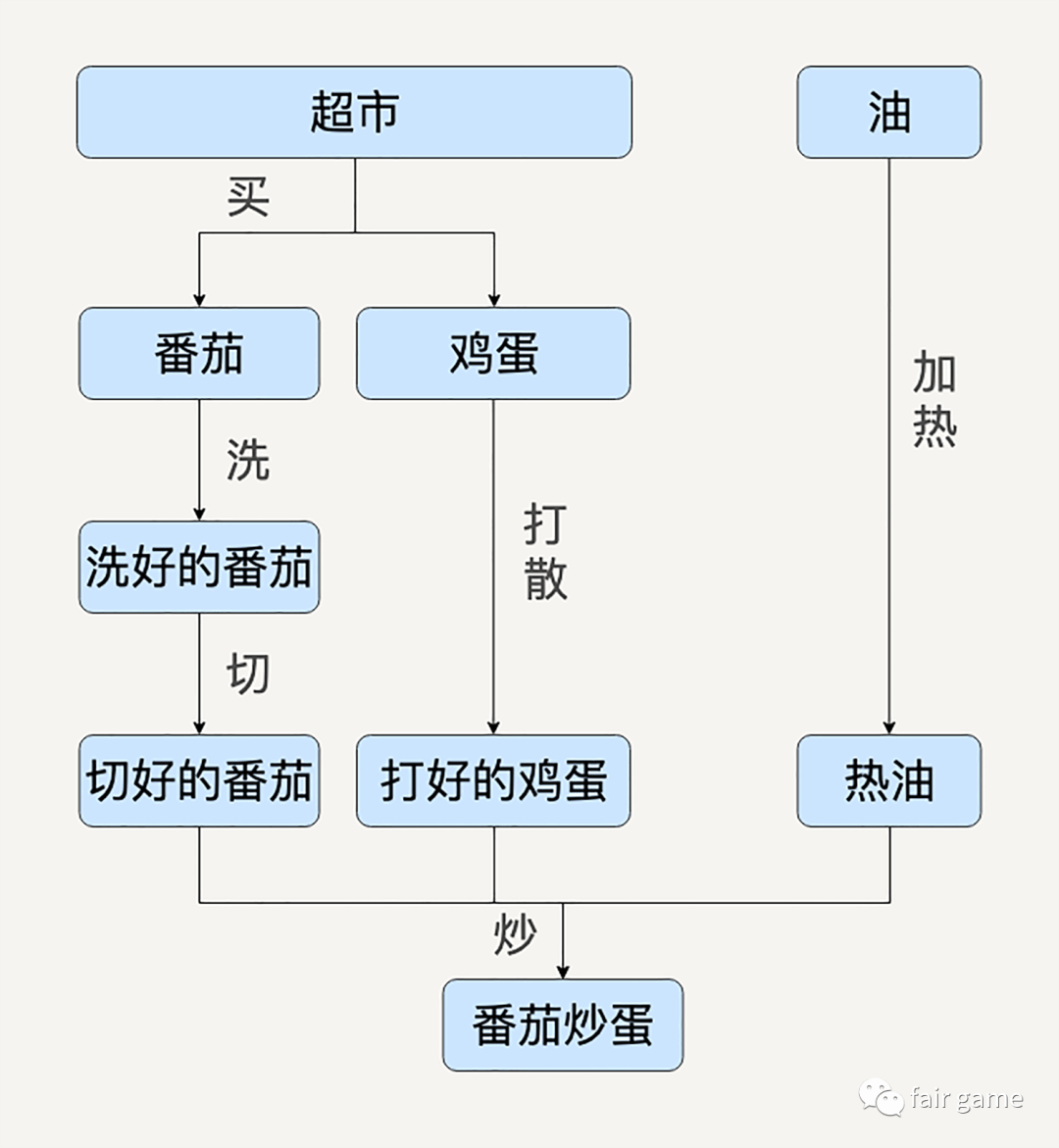
每一个箭头都会是一个独立的Map或Reduce,即一种数据变换
每一个节点都可以被抽象的表达成一种通用的数据集
pros1:这样,为了协调所有Map和Reduce,就可以较为清晰的得到某种数据形态是由哪个上游转换而来,从而更易于维护
pros2:自动性能优化
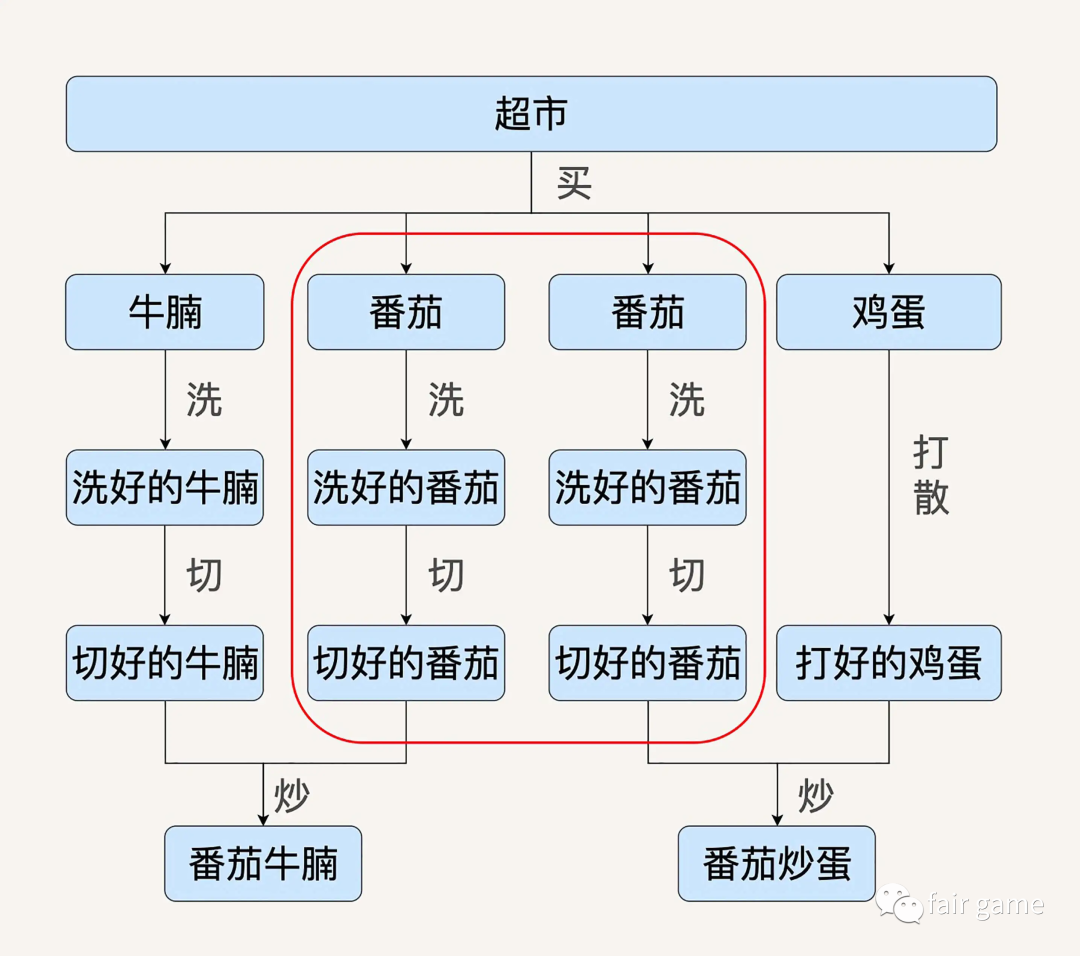
计算引擎自动发现红框中的两条数据处理流程是重复的,需要把这两条数据处理过程合并
pros3:数据处理的描述语言,与背后的运行引擎解藕,类似前后端分离,客户端可以用任何语言描述计算图,运行时引擎可以在任何地方具体运行,双方对DAG协商一致
2.Spark将数据抽象成弹性分布式数据集Resilient Distributed Dataset-RDD,它代表一个可以被分区的只读数据集。Spark定义了很多对RDD的操作(相较于MapReduce的两种操作),对RDD的任何操作都可以像函数式编程中操作内存中的集合一样直观。
3.Spark会把中间数据缓存在内存中,减少延迟

若有收获,就点个赞吧
0 人点赞
