原因
- 80%的流量来自20%的任务,遵循二八原则
- 大多数大数据引擎默认的哈希分区算法,都无法使数据分散均匀
- 某些记录存在异常,如null
- 真正决定作业执行快慢的是最长的任务
解决思路
- Map端聚合
例如:将groupByKey改为reduceByKey
不可根治,但可适量减少
- 聚合多个列
例如:select * from … group by city_id, street_id, area_id
可帮助散列均匀
- 增加reduce个数
比较大的reducer里,key模100比模10更散
- Map Join
若表一大一小,则可以将小表broadcast,从而完全避免shuffle
- 获取倾斜的记录进行两轮join
a. 单个或几个key倾斜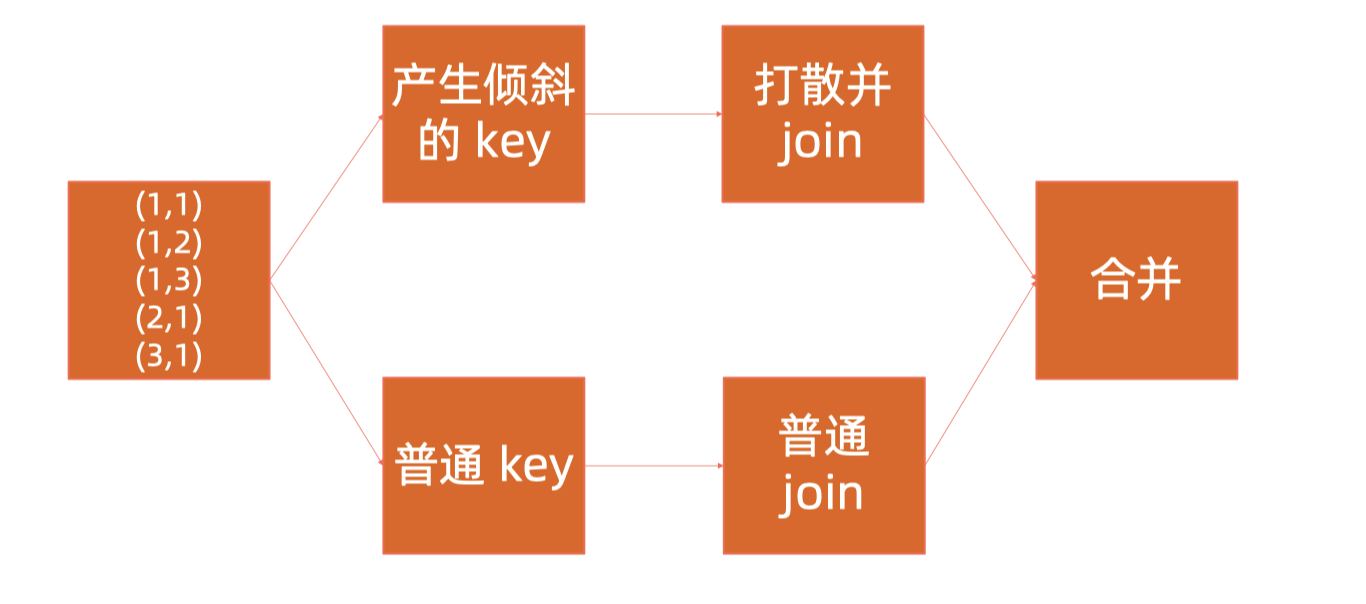
b. 多个key倾斜,或未知key倾斜
对倾斜的key打上随机数,right side需要与随机数对应起来(replica/reproduce)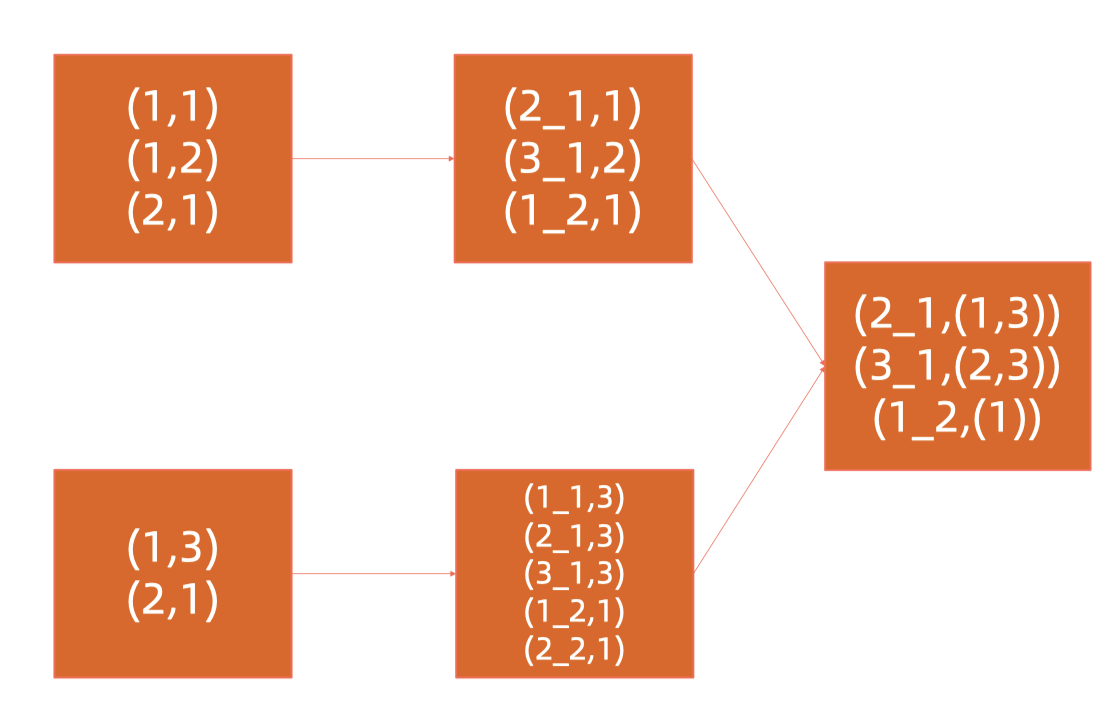
Spark解决数据倾斜的方法
对倾斜端进行切割,对right side进行replica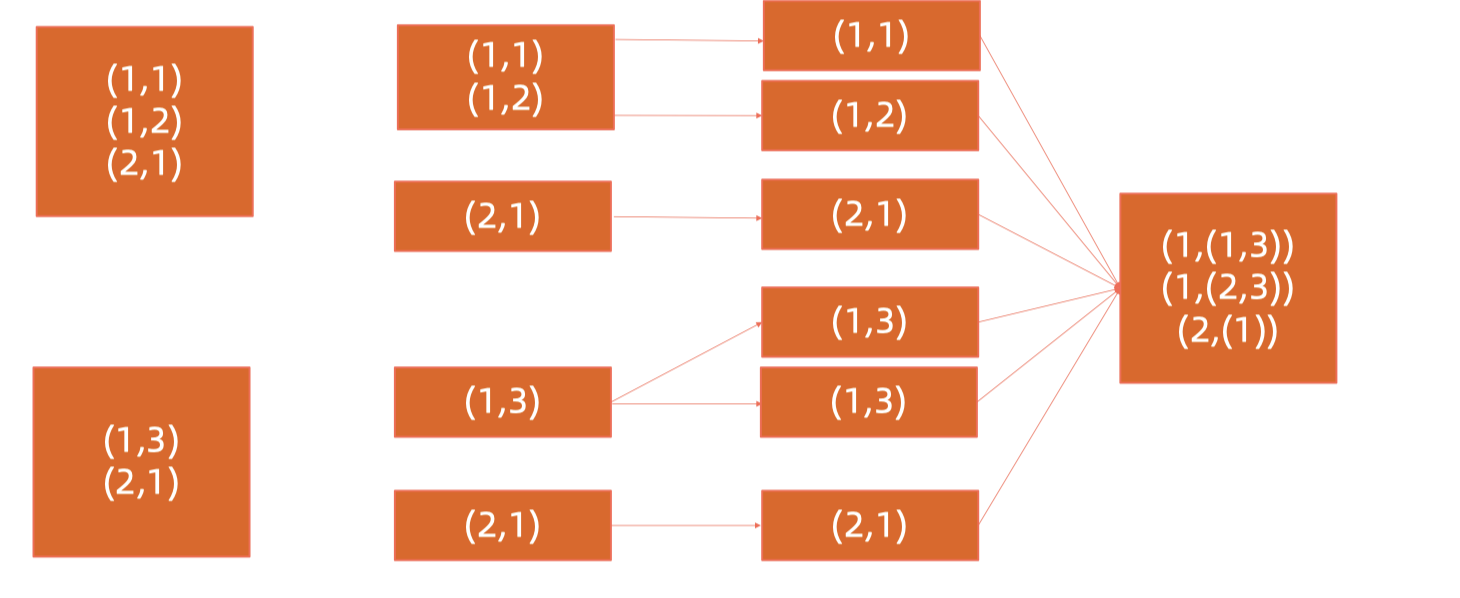

若有收获,就点个赞吧
0 人点赞
