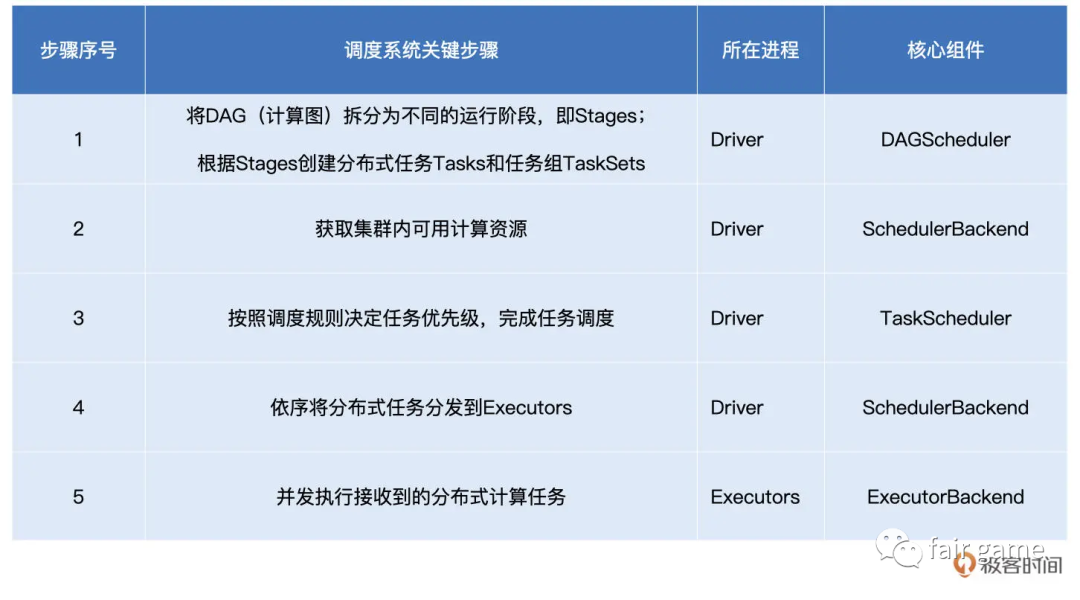
任务调度
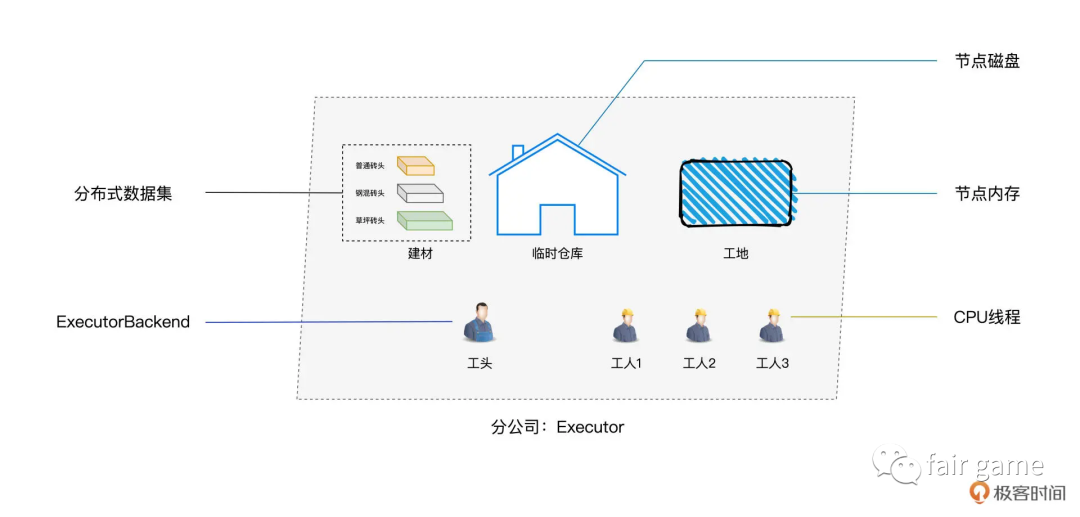
Driver和Executor
Driver:合理有序的拆解并安排任务
1.构建DAG
2.拆解分布式任务
3.将分布式任务分发到Executors中去。
如包工头负责由设计图纸,拆解任务,把二维平面图,细化成打地基,砌墙,浇筑钢筋混凝土等任务,再把任务派给手下的工人
Executor:调用内部线程池,结合事先分配好的数据分片,并发的执行代码。
核心组件:DAGScheduler, SchedulerBackend, TaskScheduler
DAGScheduler:拿到DAG,产出TaskSets
Stages(程序维度)
1.以Actions算子为起点,以shuffle为边界,把逻辑上的计算图DAG,转化成一个又一个的stages
2.Spark从后向前,以递归的方式(若Stage1的父Stage-Stage0未执行,则Stage1先被压入栈,Stage0被先提请执行),一次提请执行所有的Stages
3.基于Stages创建TaskSets,并将TaskSets提交给TaskScheduler请求调度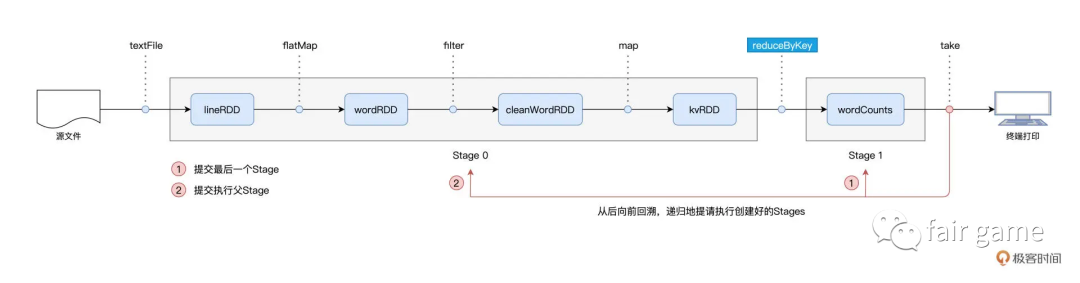
TaskSet - Task(数据维度)
DAGScheduler根据Stage内RDD的partitions创建分布式任务集合TaskSet,partitions可以理解为RDD的一个个数据分区,即RDD有多少数据分区,TaskSet就包含多少个Task
Task的属性描述了Task应该在哪里,为哪个数据分区,执行什么任务代码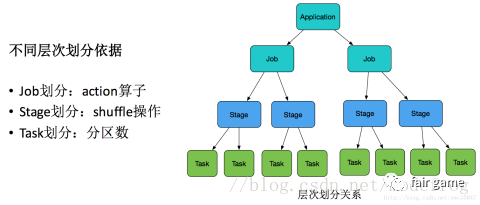
Application就是用户submit提交的整体代码,代码中又有很多action操作,action算子把Application划分为多个job,job根据宽依赖(Shuffle)划分为不同Stage,Stage内划分为许多(数量由分区决定,一个分区的数据由一个task计算)功能相同的task,然后这些task提交给Executor进行计算执行,把结果返回给Driver汇总或存储。
SchedulerBackend
用一个ExecutorDataMap记录每一个计算节点中Executors的资源状态,Executor字符串->ExecutorData(记录RPC地址,主机地址,可用CPU核数和满配CPU核数等),以WorkerOffer(记录Executor ID,主机地址和CPU核数)为粒度,提供计算资源,即给予Executor使用硬件资源的机会。
SchedulerBackend又与ExecutorBackend保持周期性通信,通过LaunchedExecutor, RemoveExecutor, StatusUpdate等不断更新ExecutorDataMap
TaskScheduler
从SchedulerBackend那里拿到所有的WorkerOffer,挑选出TaskSet中适合调度的Tasks
如何挑最“适合”,什么是最“适合”:
首先,在DAGScheduler创建TaskSets的时候,会根据数据分区的物理地址,来为Task设置locs属性(记录数据分区所在的计算节点/Executor进程ID)。如在TaskScheduler要调度Task0这个任务的时候,根据Task0的属性,得出Task0需要处理的数据分区在节点node0, node1, node2上存有副本,因此,如果WorkerOffer是来自这3个节点的计算资源,那对Task0来说就是投其所好,因为每个任务都是自带本地倾向性的。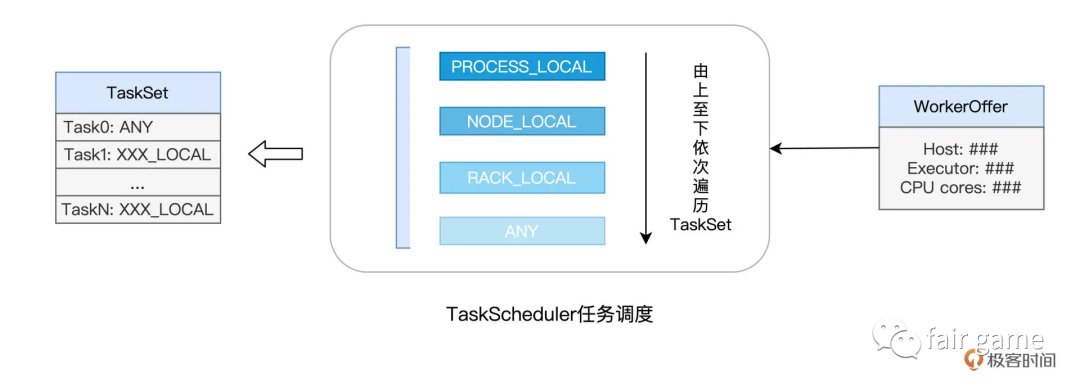
像上面这种定向到计算节点粒度的本地性倾向,Spark 中的术语叫做 NODE_LOCAL。除了定向到节点,Task 还可以定向到进程(Executor)、机架、任意地址,它们对应的术语分别是 PROCESS_LOCAL、RACK_LOCAL 和 ANY。对于倾向 PROCESS_LOCAL 的 Task 来说,它要求对应的数据分区在某个进程(Executor)中存有副本;而对于倾向 RACK_LOCAL 的 Task 来说,它仅要求相应的数据分区存在于同一机架即可。ANY 则等同于无定向,也就是 Task 对于分发的目的地没有倾向性,被调度到哪里都可以。
分发的是Task,而不是数据。让数据保持不动,把计算任务调度,分发到数据所在的地方,从而消除数据分发引入的性能隐患。
ExecutorBackend


若有收获,就点个赞吧
0 人点赞
